Vectorspace AI 데이터 세트와 Canvas를 이용한 알파 생성 및 시각화
요약
정보를 시각화하고 데이터의 힘과 가치를 자유롭게 활용할 수 있도록 Kibana에서 Elastic Stack과 Canvas를 사용해 Vectorspace 데이터 세트를 발생시키는 방법에 대한 이야기를 소개합니다.
배경
2002년에 로런스 버클리 국립연구소(Lawrence Berkeley National Laboratory)에서 Vectorspace는 자연어 이해(Natural Language Understanding, NLU)에 기반한 피처 벡터를 만들었습니다. 이것은 현재 단어 임베딩이라고도 알려져 있습니다. 피처 벡터는 상관 관계 매트릭스 데이터 세트를 생성하여 수명 연장, 유방암, 그리고 우주 방사선으로 인한 DNA 손상 복구와 관련된 유전자들 간의 숨겨진 관계를 분석하는 데 사용되었습니다.
데이터 소스에는 연구실 실험 결과, 미국 국립 의학 도서관(National Library of Medicine)의 과학 문헌, 온톨로지, 통제 어휘집, 백과사전, 사전 및 기타 게놈 연구 데이터베이스가 포함되었습니다.
그 당시, 이들은 또한 별을 분류하는 데 사용되는 베이즈 분류기인 AutoClass를 구현하여 유전자 발현 값을 포함하는 데이터 세트를 기반으로 유전자 그룹을 분류하는 데 사용했습니다. 단어 임베딩과 토픽 모델링으로 데이터 세트를 강화하자 손실은 최소화되었고 결과는 훨씬 더 유용해졌습니다. 그 때 목표는 인 실리코 방식으로 발견하기 전에 생의학 연구자가 바로잡을 수 있는 개념적 연결을 모방하는 것이었습니다. 이 작업의 일부는 선충의 수명 연장과 관련된 유전자들 간의 숨겨진 관계를 설명하는 출판 논문에 포함되었습니다. 2005년에, 미해군의 우주 및 해전 시스템사령부(SPAWAR)가 참여하게 되었고, 이로써 더 많은 리소스를 통해 금융 시장 같은 영역들로 연구를 확장할 수 있게 되었습니다.
데이터 세트 강화
시간이 지나면서, Vectorspace는 단어 임베딩으로 대표되는 피처 벡터를 확장하거나 결합시킴으로써 ‘데이터 세트의 성능을 강화하는’ 방법을 알게 되었고, 그 결과, 새로운 시각화, 해석, 가설 또는 발견을 생성하게 되었습니다. 이러한 종류의 피처 벡터로 금융 시장을 위한 시계열 데이터 세트를 확장하면 고유한 신호를 만들어내거나 알파를 생성할 수 있습니다. 이 모든 것은 아래에 예시된 대로 선택한 컨텍스트나 토픽에 최적화된 데이터 소스로 시작됩니다.
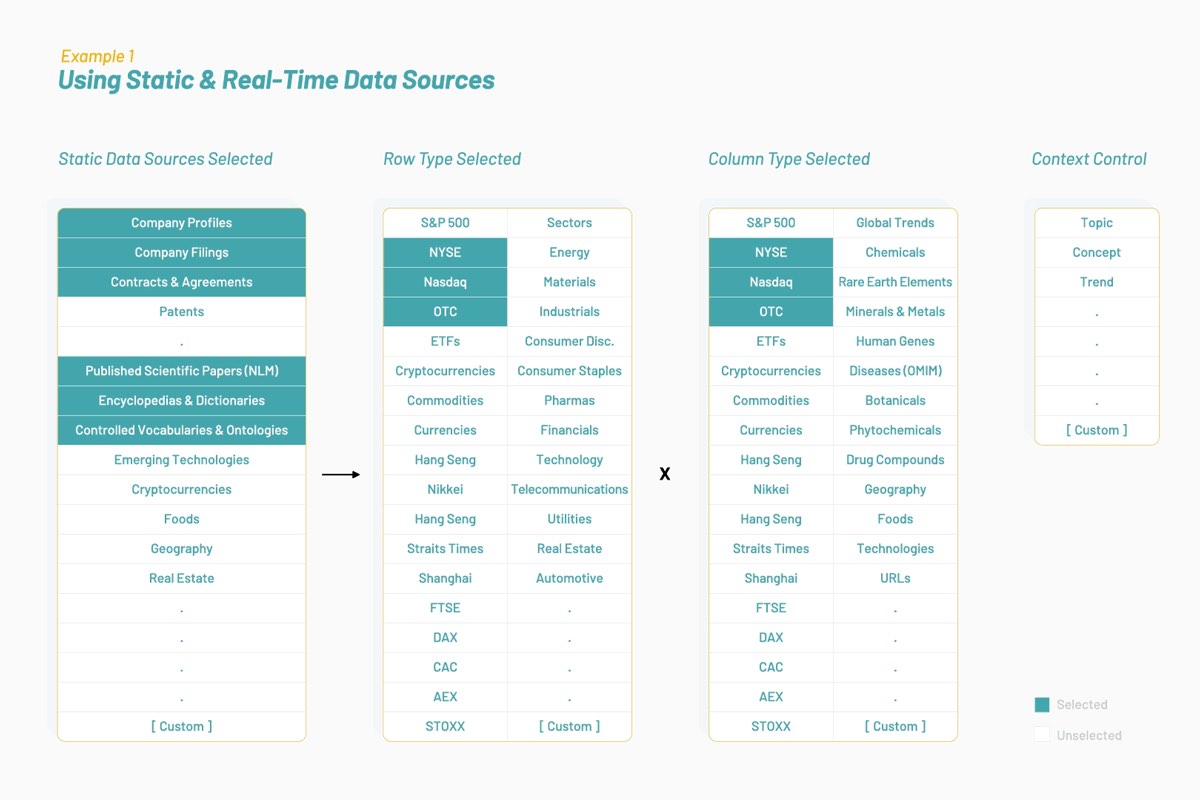
결과적으로 발생하는 데이터 세트는 뉴욕증권거래소(NYSE)와 나스닥(Nasdaq)에 상장된 기업들을 둘러싼 생의학 문헌과 인간 언어를 기반으로 하는 단어 임베딩인 피처 벡터들로 구성됩니다. 연구에 대한 학제간 접근 방식은 유전자와 주식이 상호 작용할 때 비슷한 속성과 행동을 공유하고 있는지 결정할 수 있습니다.
두 부분으로 구성된 목표 설정
첫 번째 부분: 유전자, 단백질, 약물, 질병들 간의 관찰된 상호 작용에 대한 지식을 어디에서 주식에 적용할지 결정합니다.
두 번째 부분: 금융 시장에서 알파를 생성하기 위해 확장된 데이터 세트를 사용함으로써 인간의 장기적인 우주 비행을 더 안전하게 만드는 것과 관련된 연구 기금을 조성하는 방법을 탐구합니다.
상승 이벤트 트리거
유전자들 간에 관찰되고 있는 상호 작용이 주식들 간의 상호 작용과 비슷했나요? 2004년 9월 20일에 부분적으로 그 답을 알려준 이벤트가 있었습니다. Merck(MRK)는 잠재적으로 심장 마비의 원인이 되는 자사 약인 바이옥스(Vioxx) 때문에 주가가 21%(아마도) 하락했습니다. 이것은 다른 상장 제약회사, 특히 Pfizer(PFE)의 주가에서 잠재적으로 이에 동조하는 움직임을 촉발한 이벤트였습니다. Vectorspace가 만든 데이터 세트 확장을 통해 Merck에서 생산하고 있던 약품인 바이옥스와의 연관성을 기반으로 PFE의 가격에서 지연 반응을 예측할 수 있었습니다. 이에 대한 자세한 내용은 아래에 나와 있습니다.
추가적인 연구는 The Journal of Finance 2001년 2월호에 “Contagious Speculation and a Cure for Cancer: A Non-Event that Made Stock Prices Soar(전염성 투기와 암의 치료: 주가가 치솟게 만든 비 이벤트)”라는 흥미로운 논문을 발표했습니다. 이 논문은 EntreMed(그 당시 심볼은 ENMD)라고 하는 회사와의 이벤트를 이렇게 설명했습니다.
“새로운 암 치료제의 잠재적인 개발에 대한 일요판 뉴욕타임즈 기사로 인해 EntreMed의 주가는 금요일 종가 12.063에서 월요일 시가 85로 올랐다가 월요일 종가는 거의 52였다. 그 다음 3주 동안 종가는 30 이상이었다. 이러한 열의는 다른 바이오테크놀로지 주식에까지 영향을 미쳤다. 그러나 암 연구의 잠재적인 혁신은 5개월도 더 전에 이미 Nature 저널에, 그리고 타임즈 등 여러 인기 신문에 이미 보고된 적이 있었다. 따라서, 진정한 새 정보가 발표되지 않았더라도 열의있는 대중의 관심은 주가의 영구적인 상승을 야기했다.” 연구자들이 이루어낸 수많은 통찰력있는 관찰 중에, 결론에서 눈에 띄는 한 가지는 이것이다. “[가격] 움직임은 어떤 것들을 공통적으로 갖는 주식에 집중될 수 있지만, 이것이 반드시 경제의 기초 여건 변수일 필요는 없다.” — (Huberman and Regev 387)
정량적 알고리즘 개발, 투자 은행, 상장 기업 운영 등과 관련된 영역에서 경력이 있는 팀들과 함께, 이들은 유전자와 주식 간의 유사성을 관찰하기 시작했습니다. 유전자처럼, 주식은 ‘발현 값’, 속성, 서로와의 숨겨진 관계, 그리고 외부 이벤트, 토픽, 또는 글로벌 트렌드와의 숨겨진 관계를 갖습니다. 이러한 관계는 그 어느 것보다도 인간의 언어에 포함되는 경향이 있는 지식의 형태입니다. 유전자처럼, 주식의 클러스터는 서로 동조하면서 상호 작용하고 움직일 수 있습니다. 이 데이터는 ‘잠재적인 얽힘’을 기반으로 주식들 간의 미래 가격 상호 작용을 예측하는 데 이용될 수 있습니다. 주식의 클러스터는 서로서로 그리고 외부 이벤트 가운데 알려진 관계와 숨겨진 관계를 공유하는 ‘바스켓’으로 간주될 수 있습니다. 클러스터 또는 바스켓은 컨텍스트로 제어될 수 있습니다.
밀물이 모든 배를 띄워올리지는 않는다
Vectorspace는 “채굴 가능한 정보 포켓”을 기반으로 금융 시장에서 비효율성을 활용하는 데 바탕을 둔 펀딩 방법을 창출할 기회를 파악했을 때 무엇이 관찰된 상관 관계의 원인이 되고 있는지 분석을 시작했습니다. 이들은 바깥 바다에서 파도가 일어나고 몇 분 후에 또는 몇 시간 후에 항구나 만에 물이 차서 배가 뜨는 것과 비슷한 주식들 간의 지연 반응을 관찰하기 시작했습니다. 항구에서 물이 오르는 것은 이벤트에 의해 촉발될 수 있으며, 그 이벤트는 그때 항구에 있는 배를 띄워올리는데, 이 경우에 그 배는 주식 같이 거래 가능한 자산의 클러스터로 간주될 수 있습니다. 금융 시장에서, 어떤 배들은 뜨고 어떤 배들은 뜨지 않습니다. 어느 자산이 이벤트와 상관 관계가 있는지 예측하는 것은 그 상관 관계의 강점 및 컨텍스트와 더불어 귀중한 신호를 제공할 수 있습니다. 시장을 앞서가기 위해 또는 자본을 투자할 때 자산 매입이나 자산 매도에서 위험을 줄이기 위해 사용될 수 있는 일종의 비대칭적인 정보를 갖는 것과 같습니다. 이것은 또한 시각화되거나 해석될 수 있는 ‘알파 생성’으로 알려질 수도 있습니다.
이 확률적인 배 띄워올리기 가설을 시험하기 위해, 20년 간의 데이터를 분석하여 시장의 이벤트를 기반으로 상장 기업의 주가들 간의 동조 움직임이나 잠재적인 얽힘 패턴을 찾아보았습니다. 그리고 EntreMed(ENMD) 1998, Merck(MRK) 2004, Celgene(CELG) 2019, 이 세 가지 이벤트를 포함한 충분한 이벤트가 발견되었습니다.
이벤트 1: EntreMed(ENMD) 주가 608% 상승(1998년 5월 4일)
EntreMed는 시장이 폐장한 후 금요일에 특정한 유형의 암을 치료했다는 뉴스를 발표했습니다. 그 주가는 금요일에 12달러에 거래되고 있었는데 월요일 시가는 85달러였습니다. 이에 동조하여, 암 치료와 관련된 단백질 과학을 둘러싼 인간 언어를 바탕으로 ENMD와 상관 관계를 갖는 주식 바스켓 또한 오르기 시작했습니다.
이 이벤트를 설명하는 논문에는 몇 가지 관련 발췌문이 포함되어 있습니다.
392페이지 4번째 문단 “이 중 세 개의 수익은 100퍼센트를 초과했다. 두 개의 수익은 50퍼센트에서 100퍼센트 사이였고, 또 다른 두 회사의 수익은 25퍼센트에서 50퍼센트 사이였다. 이러한 수익을 표 1에서 보고된 극단 수익 분포와 비교하면 이 7개의 바이오테크놀로지 주식의 수익이 얼마나 비정상적인 것이었는지를, 특히, 이 클러스터링이 얼마나 전례가 없는 것인지를 볼 수 있다.”
395페이지 1번째 문단 “암 연구에서의 혁신에 대한 뉴스가 직접적인 상용화 개발권이 있는 회사의 주식에만 영향을 준 것이 아님은 놀랄 일이 아니다. 시장은 잠재적인 여파 효과를 인식하여 이 혁신으로 다른 회사들도 혜택을 볼 수 있으리라는 추측을 할 수 있다.”
396페이지 3번째 문단 “움직임은 어떤 것들을 공통적으로 갖는 주식에 집중될 수 있지만, 이것이 반드시 경제의 기초 여건 변수일 필요는 없다.”
이벤트 2: Merck(MRK) 주가 25.8% 하락(2004년 9월 30일)
Merck는 25억 달러의 매출을 기록한 약품인 바이옥스(Vioxx)를 시장에서 철수했습니다. COX-2 억제제를 기반으로 뇌졸중과 심장 발작을 일으키고 있었기 때문입니다. 이 상관 관계에는 원인이 있었습니다. MRK는 그 전날 종가가 45.07달러였다가 9월 30일 시가가 33.40달러였습니다. 피처 벡터로 간주되는 단어 임베딩으로 실험하는 동안, 유사한 피처 벡터를 기반으로 Pfizer(PFE)가 Merck와 가장 밀접한 관련이 있는 회사라는 것이 발견되었습니다. 당시에 COX-2 억제제를 기반으로 하는 유사한 약물 화합물에 대해 작업을 하고 있었기 때문입니다. 몇 주 후에 PFE 주가는 현저하게 하락했습니다.
“2004년 12월 17일, Pfizer와 미국 국립암센터(US National Cancer Institute)는 심혈관 이벤트의 증가하는 위험 때문에 대장 용종 예방에 대한 사용을 조사하는 지속적인 임상 시험에서 cyclooxygenase-2(COX-2) 억제제인 쎄레브렉스(celecoxib) 투여를 중단했다고 발표했다. Merck의 또 다른 COX-2 억제제인 로페콕시브(Vioxx)는 심근 경색과 뇌졸중의 증가하는 위험 때문에 2004년 9월에 전 세계 시장에서 철수되었다.” - CMAJ.
PFE 주가는 그 전날 종가 28.98달러에서 그 날 21.99달러로 24% 하락했습니다.
이벤트 3: Celgene(CELG) 주가 31.8% 상승(2019년 1월 3일)
2019년 1월 3일, Bristol-Myers Squibb(BMY)은 740억 달러에 Celgene(CELG)을 인수했습니다. CELG 주가는 하룻밤 사이에 주당 66.64달러에서 87.86달러로 31.8%가 올랐습니다. 4일에 걸쳐 CELG과 관련된 주식 바스켓은 이 기업들을 둘러싼 인간 언어에서 발견된 관계를 기반으로 20%의 수익을 창출했습니다. 이러한 엔터티들 간의 연결을 가능하게 하는 데이터 소스에는 상장 기업 프로필의 리포지토리와 동료 검토를 마친 출판 과학 문헌이 포함됩니다.
이 프로세스의 Vectorspace 분석에서, 일부 NLU 상관 관계가 주식들 가운데 그리고 주식과 이벤트 간에 잠재적인 가격 기반 상관 관계의 원인이 될 수 있음이 발견되었습니다. 팀은 시장을 앞서가기 위해 또는 여러 형태의 정보 재정거래모형에 참여하기 위해 사용될 수 있는 위와 같은 수많은 사례들을 관찰했습니다.
알파 시각화
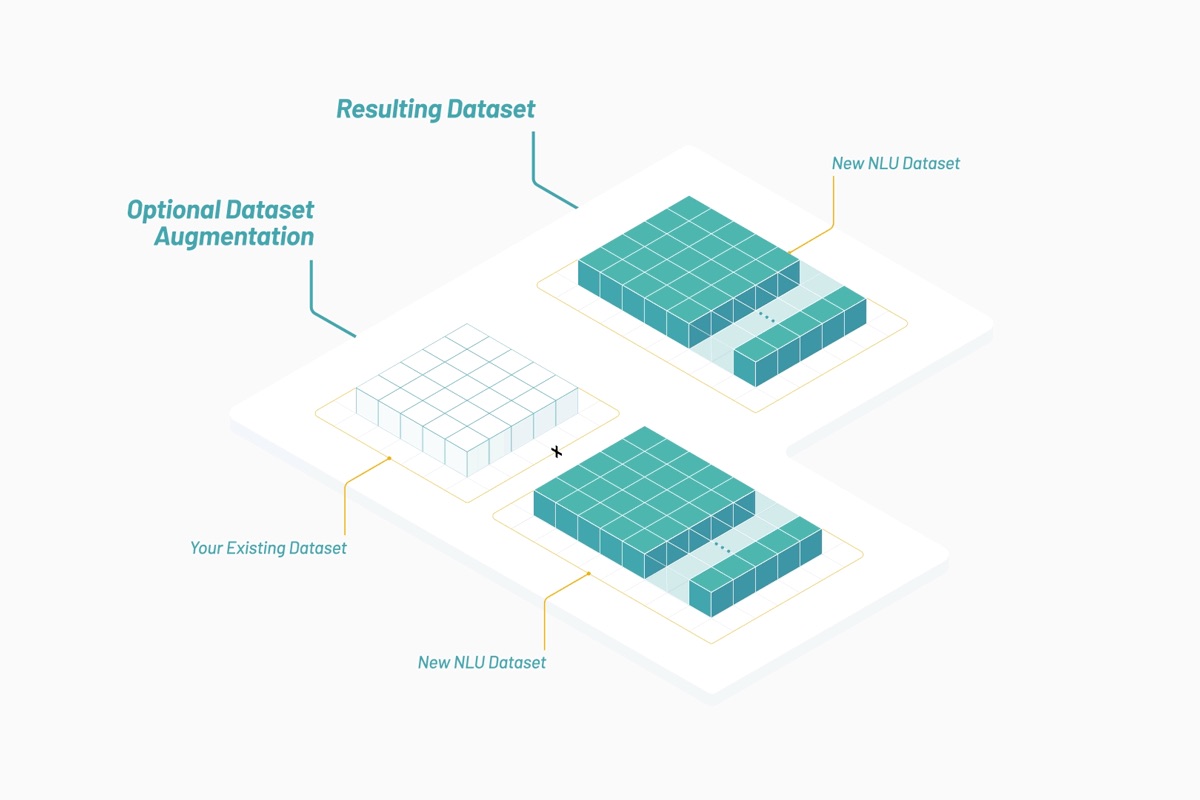
현재 Vectorspace AI에서 데이터 세트는 생명 과학에서 유전자, 단백질, 미생물, 약물, 질병 상호 작용 간에 또는 금융 시장에서 주식들 간에 숨겨진 관계의 네트워크를 탐색하기 위해 설계됩니다. 대부분의 시간을 우리 고객은 이러한 데이터 세트를 사용해 기존의 사내 데이터 세트를 확장합니다. 데이터 세트는 단어와 객체들의 벡터화를 기반으로 점수를 얻은 속성들로 구성되는 피처 벡터들의 조합을 사용해 생성됩니다. 데이터 세트는 거의 실시간으로 업데이트되며 유틸리티 토큰 크레딧을 사용해 API를 통해 액세스됩니다.
Elastic Stack과 Canvas를 활용함으로써, Vectorspace는 화이트 레이블의 완전히 구성 가능한 보기에서 거의 실시간 데이터 시각화와 해석을 고객에게 제공할 수 있습니다. 이것은 전체 프로세스에 중요합니다. 새로운 해석과 인사이트가 새로운 가설, 신호 또는 발견으로 이어질 수 있기 때문입니다.
자산운용사와 기관이 개인정보 보호를 위해 온-프레미스 데이터 엔지니어링 파이프라인 솔루션을 요청하는 것은 흔히 있는 일입니다. Elastic Cloud Enterprise를 사용하는 우리 데이터 엔지니어링 파이프라인 패키징으로 신호 생성을 위한 턴키 솔루션 제공이 가능해집니다.
금융 시장의 Vectorspace 고객은 신호대 잡음비 최적화, 알파 생성, 손실 함수의 최소화 또는 샤프 또는 소티노 비율 최대화를 목표로 합니다. 이것은 백 테스트 과적합을 제한하는 한편 거의 실시간의 데이터 세트 확장을 기반으로 백 테스트 전략의 결과를 시각화하고 해석하면서 이루어집니다.
데이터 세트 업데이트 빈도수는 기본이 되는 데이터 소스의 변동성에 따라 1분에서 한 달까지 다양할 수 있습니다. 요청되는 인기 있는 데이터 세트 패키지는 시계열 요금제 데이터 세트로 이루어지며, 그 행에는 피처 벡터로 확장된 상장 제약회사들이 포함됩니다. 피처 벡터는 NLU 기반 상관 관계 점수를 갖는 약물 화합물입니다. 어느 컨텍스트 내에서 운영할 것인지를 선택하는 것은 대단히 중요할 수 있습니다. 컨텍스트가 정의를 변경할 수 있는 것처럼, 올바른 컨텍스트에 따른 제약조건을 추가하면 시간이 지나면서 상관 관계 점수의 값에 있어서의 변화를 보여줄 수 있습니다. 컨텍스트는 또한 엔터티들 사이의 그리고 엔터티와 이벤트 간의 관계의 강점을 제어할 수 있습니다.
Canvas로 시각화
이제 이러한 데이터 세트 중 하나를 살펴보고 이를 사용해 Celgene(CELG)과 관련된 주식 바스켓을 생성하고 시각화해 봅시다. 아울러 그러한 주식의 일부에서 가격의 지연된 상승을 촉발하는 이벤트도 함께 살펴보겠습니다. Canvas에서 백 테스트의 결과와 거의 실시간 결과를 해석하는 동안 Vectorspace 고객이 이러한 데이터 세트를 이용하여 밟을 수 있는 전형적인 단계를 차근차근 짚어가게 됩니다. 첫째로, Celgene 바스켓이 체리 피킹되지 않았음을 확인하기 위해 전체 바스켓 그룹을 위한 최종 결과를 보게 됩니다.
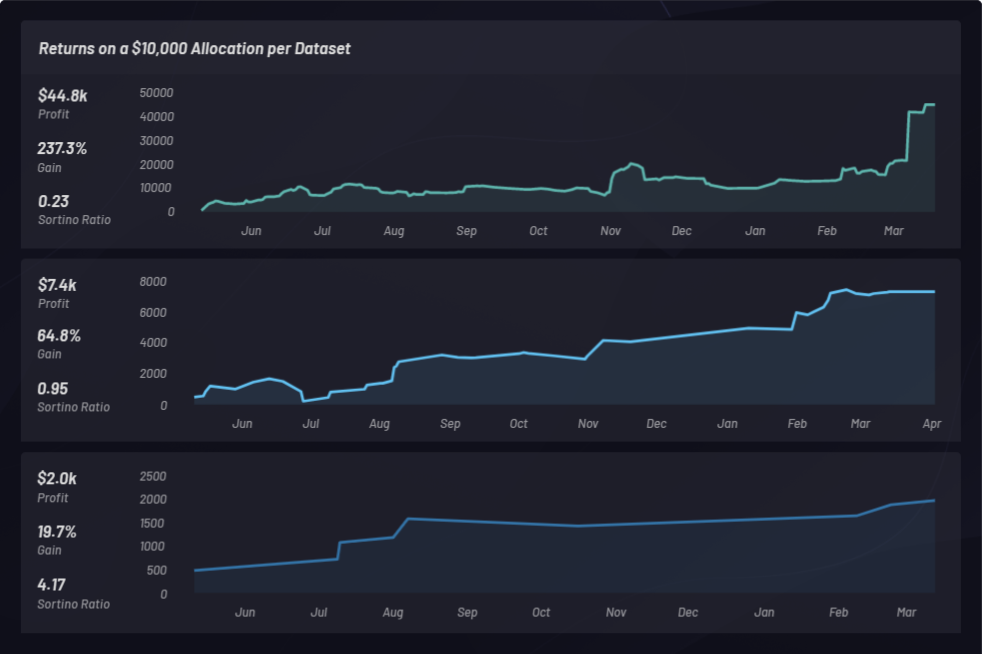
다음은 다른 매개 변수 설정으로 롱 포지션만의 바스켓을 사용하는 별개의 백 테스트 세 개입니다. 다음은 각각 10,000달러의 자본 배분을 가지며 소티노 비율별로 순위가 매겨집니다.
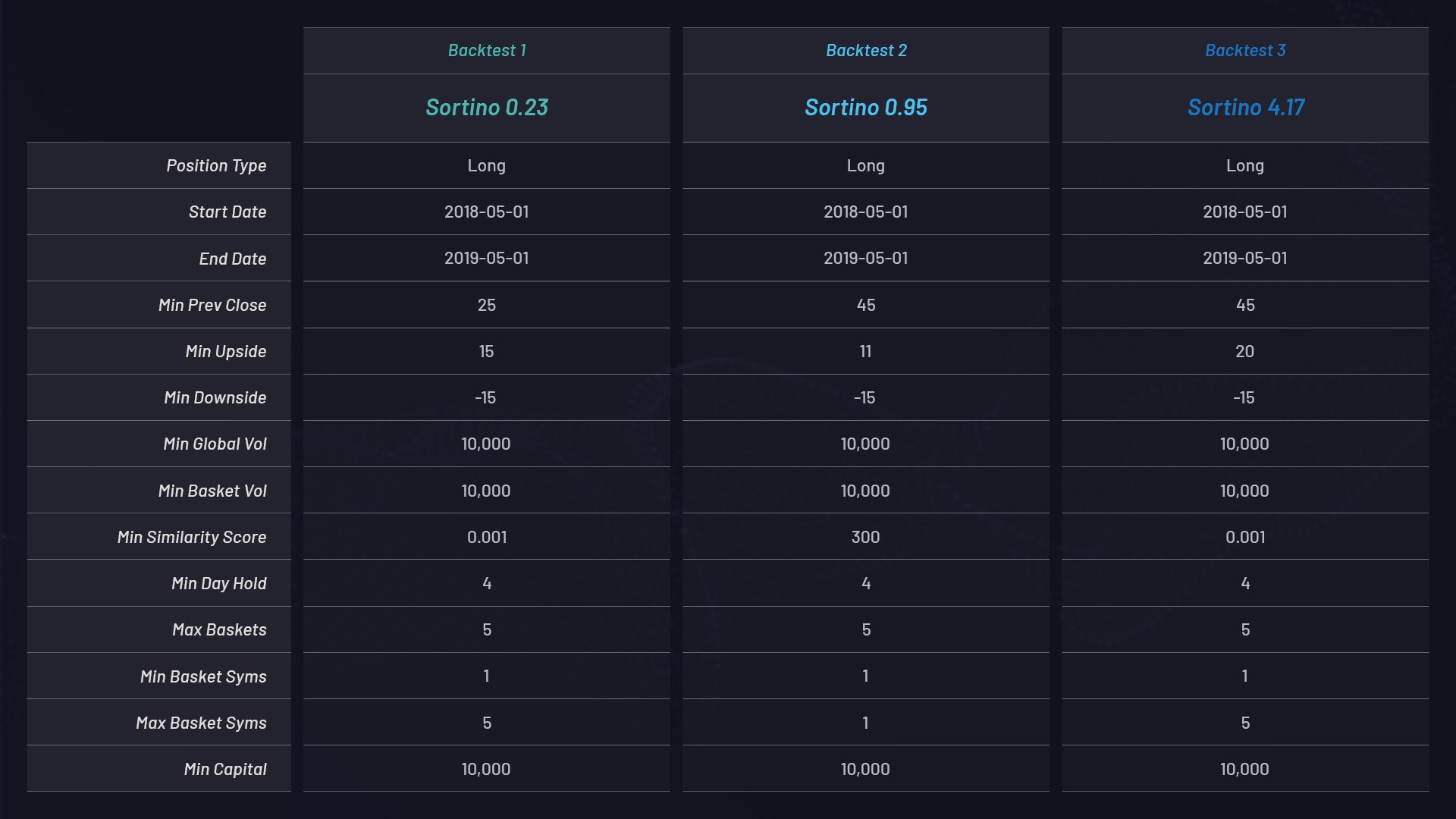
각 바스켓을 위한 매개 변수 설정:
아래에서는 백 테스트 결과가 Kibana에 로드되고 통계가 표시됩니다.
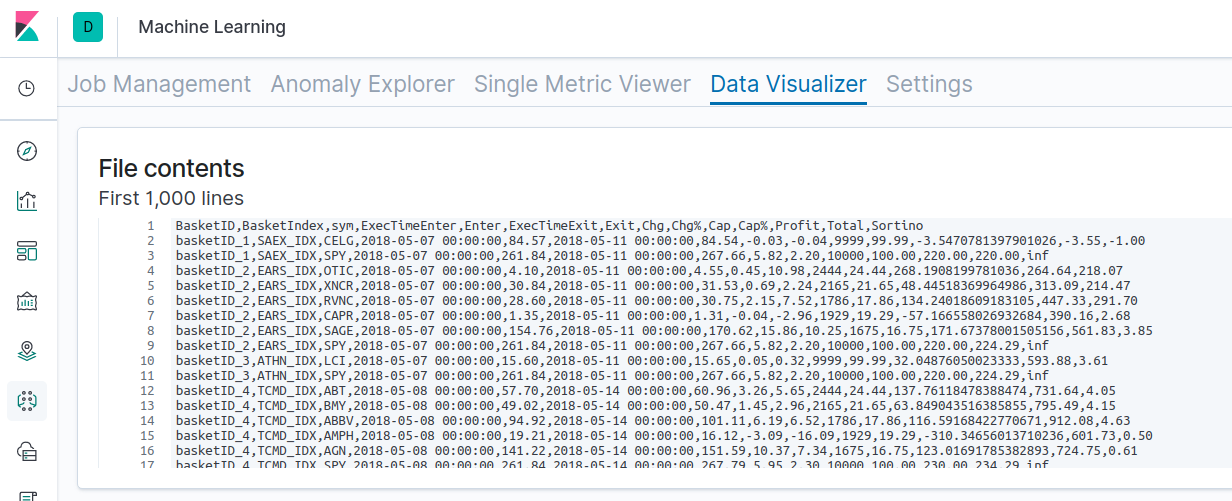
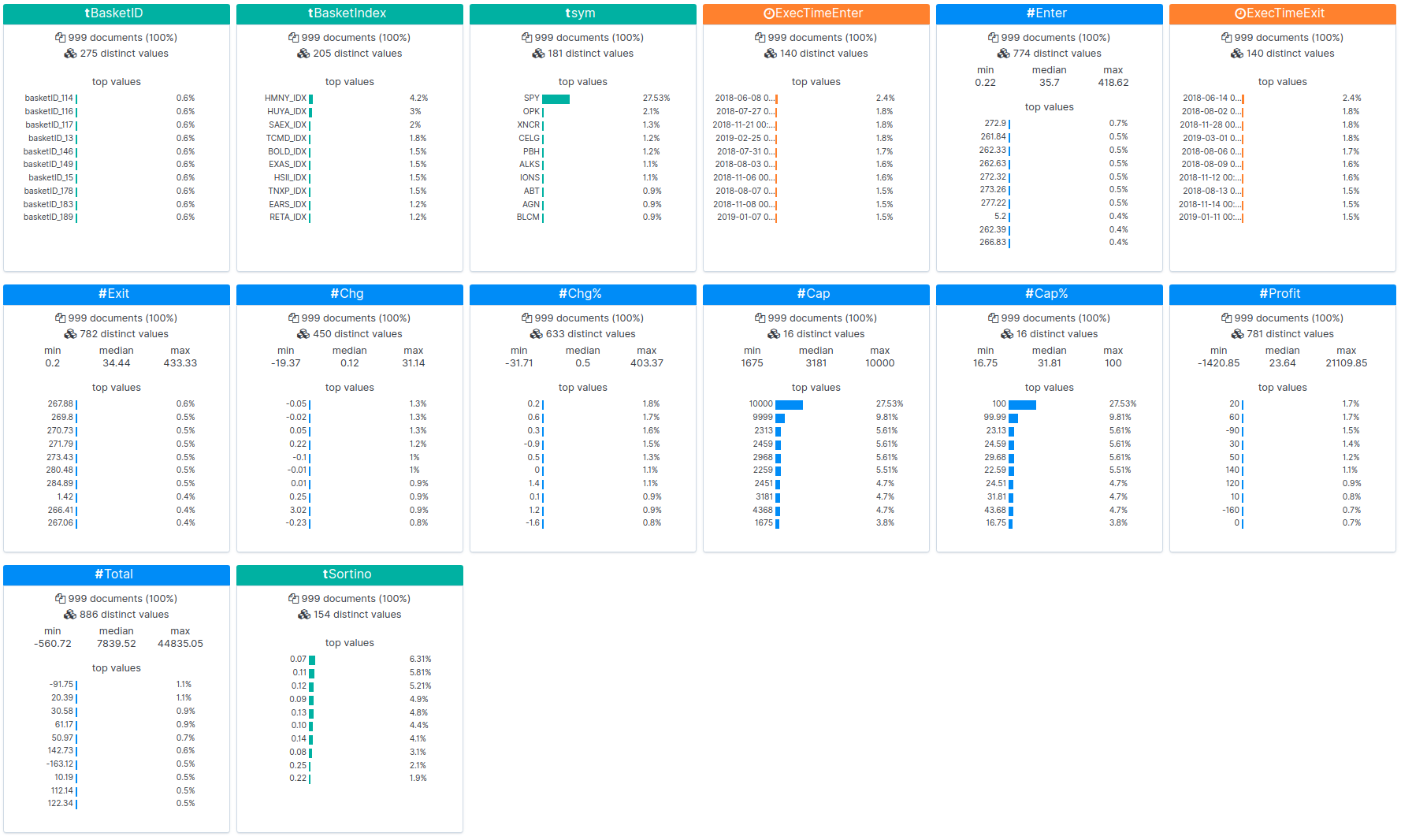
백 테스트 중 하나의 원시 결과를 여기에서 보실 수 있습니다. 백 테스트로 확장된 NLU 데이터 세트는 다음 단계를 이용해 수행될 수 있습니다. 우리는 이 단계를 사용해 위의 결과를 생성했습니다.
- 데이터 세트 API를 사용해 모든 뉴욕증권거래소(NYSE)와 나스닥(Nasdaq) 주식에 대해 피처 벡터로 간주되는 단어 임베딩이 생성됩니다.
- 주가의 급상승으로 정의되는 특별 이벤트 트리거를 스캔하기 위해 뉴욕증권거래소(NYSE)와 나스닥(Nasdaq) 주식에 대한 2018년 5월 1일부터 2019년 5월 1일까지 1년 간의 요금제 데이터 기록이 사용됩니다.
- 선택한 백분율 임계값, 예를 들어 +15%보다 더 크게 급상승하는 모든 주식에 대해서는, 그 데이터 세트를 사용해 관련 주식의 클러스터나 바스켓이 생성됩니다. 위의 표에서 MIN_UPSIDE 매개 변수를 참조하세요.
- 볼륨, 시장 총액, 플로트와 같은 필터링 매개 변수는 그때 바스켓을 다듬는 데 사용됩니다.
- 거래 진입과 퇴장 시간은 4일간 유지로 설정됩니다.
- 소티노 비율과 더불어 기준선 비교를 위해 S&P 500과 함께 롱 바스켓과 숏 바스켓에 대해 수익이 계산됩니다.
- Canvas를 통해 데이터 세트와 수익의 모니터링, 시각화, 해석이 이루어집니다.
백 테스트 수익
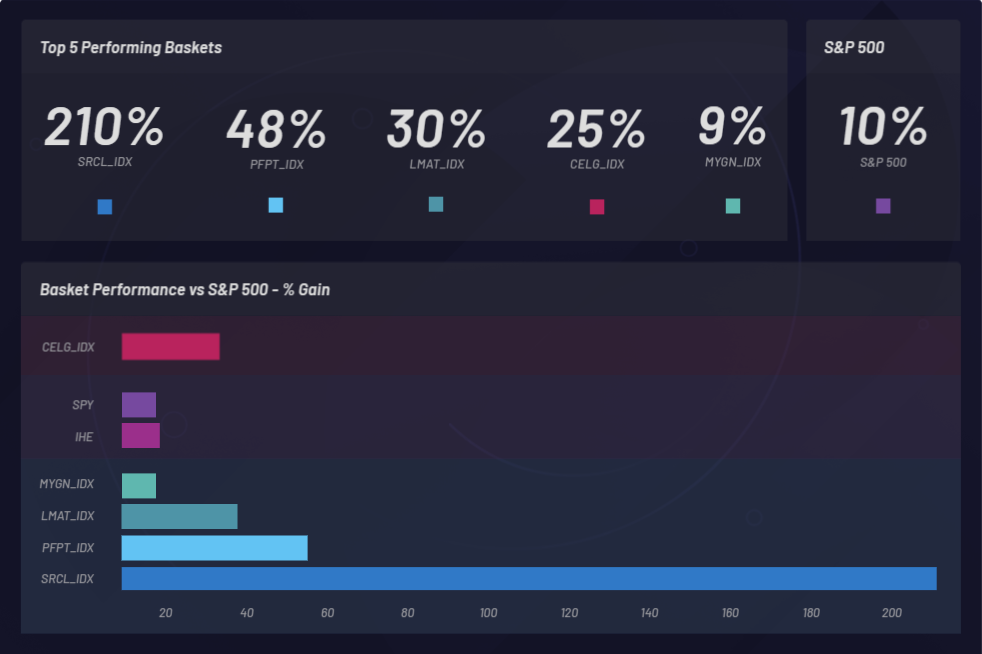
Canvas로 2018년 5월 1일부터 2019년 5월 1일까지 이 기간 동안 생성된 모든 바스켓의 실적을 기반으로 1년짜리 백 테스트 세 개의 전체적인 결과를 살펴보겠습니다.
백 테스트를 통해 Celgene 인수 후에 가치가 증가한 주가가 있는 상장 기업 탐색이 가능해졌습니다. 확장된 데이터 세트는 상관 관계가 관찰될 수 있는 곳에서 로드됩니다. 데이터 세트로부터 생성된 바스켓(클러스터) 또한 그 성능을 기반으로 볼 수 있습니다. 최소한 시장을 석권하고 있는지 확인하기 위해 바스켓은 S&P 500의 기준선 성과와 비교될 수 있습니다. S&P 500(SPY) 이상의 성과를 거두고 있는지 확인하기 위해 다음과 같이 개별 바스켓이 모니터링됩니다.
아래 그래픽은 이벤트와 그 이벤트의 결과로 나타나는 다른 주식의 잠재적인 동조 움직임의 모니터링을 보여줍니다. 이 사례에서는, CELG(Celgene)가 이벤트였고 EPZM(Epizyme)이 결과적인 바스켓 구성 요소로 선정되었습니다. NLU 기반의 상관 관계는 가격 기반의 상관 관계를 예측할 수 있습니다. 주식과 이벤트 간의 NLU 기반 상관 관계 업데이트를 포착하면 비대칭적인 정보 재정거래모형을 기반으로 하는 에지를 제공할 수 있습니다. 다음과 같이 여기에서 관찰될 수 있는 CELG과 EPZM 간의 모든 NLU 기반 상관 관계와는 반대로 가격 조치나 가격 상관 관계에서 지연 반응이 있는 경우에만 시장을 주도할 수 있습니다.
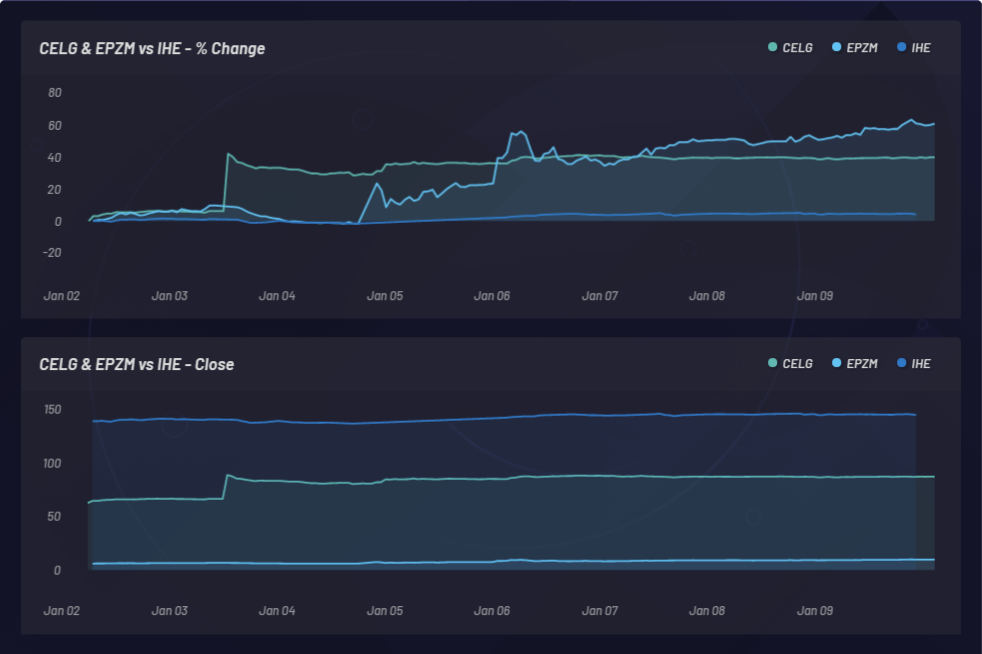
CELG(Celgene)과 AGIO(Agios Pharmaceuticals) 비교:
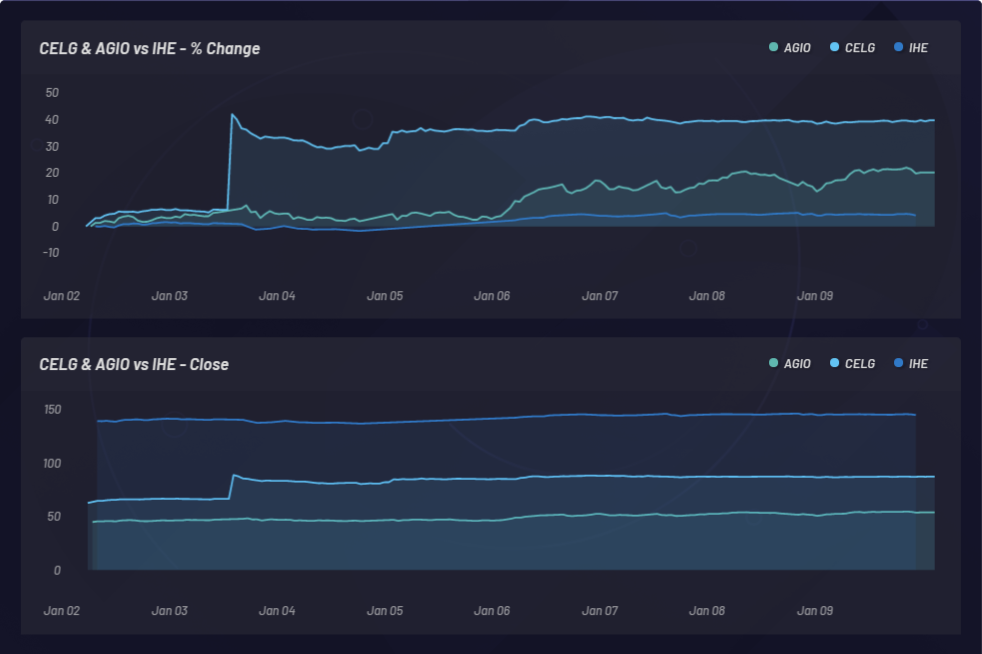
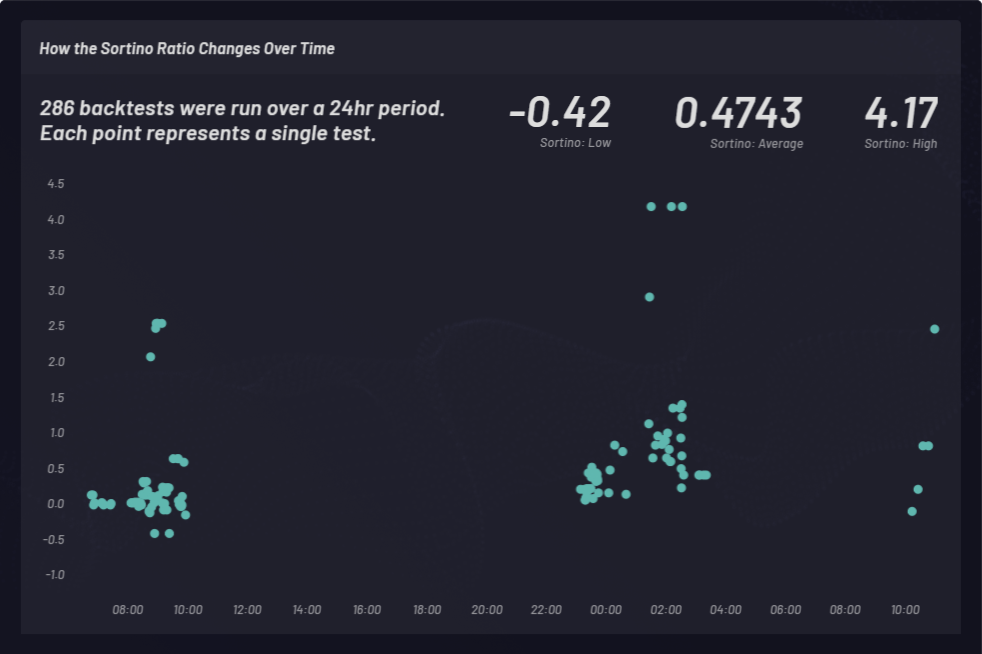
소티노 비율은 위험조정 수익률을 측정하기 위해 계산됩니다. 다음 사례에서는, 상방 변동성을 좀더 잘 알아보기 위해 샤프 비율보다 소티노 비율이 선택되었습니다. 소티노 비율은 시간에 따라 변화합니다. 백 테스트는 아래에 나와 있는 대로 24시간 동안 3개의 ekfms 시점에 롱 바스켓으로 실시되었습니다. 다양한 글로벌 매개 변수로 실행된 총 286개의 바스켓이 실시되었습니다. 아래 클러스터의 각 지점은 y축 상에서 해당 소티노 비율이 있는 단일 백 테스트를 나타냅니다.
변화하는 상관 관계 활용
국립 의학 도서관(National Library of Medicine)은 24시간마다 동료 검토를 마친 과학 논문을 약 1,500편 출판합니다. Vectorspace는 데이터 소스 중 하나로 NLM을 사용합니다.

유전자, 약물 화합물, 의약품 뉴스 및 상장 기업 간의 상관 관계는 시간이 지나면서 변하고, 때로는 몇 초 안에도 변합니다. 이것은 약품 용도 변경 및 재창출을 위한 후보인 화합물을 발견할 때 신호대 잡음비에 영향을 미칠 수 있습니다.
상장 제약회사와 유전자, 단백질, 약물 화합물, 미생물 또는 질병 간의 상관 관계 값이 변화하는 경우, 새로운 관계는 데이터 세트에 반영되며, Canvas로 거의 실시간으로 모니터링될 수 있습니다.

NLU 기반 데이터 세트의 생성에서 컨텍스트 제어를 사용하는 것은 결과적으로 새로운 종류의 상관 관계 점수를 얻을 수 있습니다. NLU 관계의 컨텍스트 제어는 새로운 인사이트를 얻는 데 있어 핵심적일 수 있습니다..
컨텍스트 제어를 추가함으로써, NLU 기반의 데이터 세트는 Canvas에서 답변이나 결과를 시각화하고 해석하는 강력한 방법을 제공하면서 “어느 의약품 주식이 최신 연구를 바탕으로 DNA 손상 복구 유전자라는 컨텍스트에서 이러한 약물 화합물과 상관 관계가 있는가?”라는 질문에 답하는 데 있어 연구자들을 지원할 수 있습니다.
24시간마다 약 1,500개의 동료 검토가 끝난 과학 논문들이 뉴스 및 기타 공개 신고와 더불어 출판되기 때문에, 상관 관계 점수에 변화가 발생하고, 이는 곧 예를 들어 상장 제약회사와 약물 화합물 간의 업데이트된 관계를 정의합니다. NLU 기반의 데이터 세트는 사내 데이터 소스와 결합하여 고유한 신호를 제공할 수 있습니다.
결론
자연어 프로세싱(NLP)과 NLU를 기반으로 하는 상관 관계는 새로운 인사이트, 가설 또는 발견을 생성하기 위한 경로를 활성화할 수 있습니다.
컨텍스트에 따른 상관 관계, 대안적인 데이터 소스, 피처 벡터, 시각화 및 해석과 관련해 생명 과학과 금융 시장에서 NLU 데이터 세트로 할 수 있는 일은 훨씬 더 많습니다. 아마도 나중에는 우리 팀이 거래가 가능한 다양한 자산을 위한 시계열 데이터 세트 확장 등 이러한 주제 중 일부에 대해 논의하게 될 것입니다. 개별 NLU 피처 벡터를 통해, 우리 팀은 Canvas와 Elastic Stack의 기타 도구들로 그래프 기반의 관계 네트워크나 렌더링된 전체 네트워크 클러스터를 구성하는 방법에 대해 설명할 수도 있습니다. 아울러, 오픈 마켓 주문 기록 장부와 결합된 유틸리티 토큰 API를 기반으로 선택된 손실 함수를 최소화하기 위해 머신이 서로서로 피처 벡터를 트랜잭션하도록 하는 방법을 설명할 수도 있습니다.
Vectorspace는 LET 방사선(우주 방사선)과 연관되는 염색체 손상 복구, 후생유전학, 인간의 우주 비행과 관련된 수명 분석에서 데이터 세트를 위한 관련 애플리케이션을 계속해서 구축하고 있습니다. 이 모든 것이 Canvas와 다른 도구들을 포함한 Elastic Stack을 이용하면 훨씬 더 창조적이고 유용하게 이루어집니다. 데이터 세트 확장이나 무료 유틸리티 토큰 API 크레딧을 얻는 방법에 대해 더 자세히 알아보려면, Vectorspace로 연락해주세요. 시작하는 데 필요한 데이터를 기꺼이 제공해드리겠습니다.
그리고 Elastic Stack을 시험적으로 사용해보시려면, Elasticsearch Service 14일 무료 체험판을 이용하시거나 기본 배포의 일부로 다운로드받으실 수도 있습니다.
Vectorspace는 Genentech, 로런스 버클리 국립연구소(Lawrence Berkeley National Laboratory), 미국 에너지부(DOE), 국방부(DOD), NASA의 우주 생물과학부, DARPA 및 SPAWAR(미해군 우주 및 해전 시스템사령부) 외 여러 기관을 위해 정보 재정거래모형과 과학적인 발견(높은 수준의 AI/NLP/ML)을 목적으로 인간의 인식을 모방하는 시스템과 데이터 세트를 발명합니다.
Shaun McGough는 Elastic의 제품 관리자로서 데이터 시각화와 대안 투자 분야에서 도메인 전문지식을 보유하고 있습니다.