Don’t drown in your data — Why you don’t need a data lake


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
As a leader in Security Analytics, we at Elastic® are often asked for our recommendations for architectures for long-term data analysis. And more often than not, the concept of Limitless Data is a novel idea. Other security analytics vendors, struggling to support long-term data retention and analysis, are perpetuating a myth that organizations have no option but to deploy a slow and unwieldy data lake (or swamp) to store data for long periods of time.
Let’s bust this myth. In Elastic, limitless data isn’t a pipedream — it’s a reality. Thousands of our customers are already benefiting from a unified data layer that maintains months and years of actionable data in an affordable and rapidly accessible way.

Why do organizations now need long-term actionable data?
The SolarWinds attack demonstrated the need to be able to quickly action archives that most organizations either siloed in slow data swamps or didn’t retain at all. Discovered in late December 2020, and affecting tens of thousands of firms, the real eye-opener was that the adversary began infiltrating networks 15 months earlier. In an instant, CISOs around the world needed to know, “Did we see signs of this attack over the past year?”
Thus many defenders began querying compliance and governance systems (lakes or swamps) that weren’t engineered to provide fast and reliable answers. Not only is this process of “guess . . . rehydrate . . . search . . . and start again” extremely slow — taking hours to bring information online and searchable — it’s also inaccurate. Analysts can make good assumptions about which timeframe to analyze but are often unable to provide full assurance across the stored information.
The SolarWinds attack, more than any other in recent memory, showed that practitioners defending an organization from an ongoing attack need a way to search historical data quickly and with complete assurance. Remember, determining if the attack happened isn’t enough. You also need to be able to establish the root cause and the full scope of the attack and develop remediation plans.
Analysts felt like they were drowning in these data lakes, unable to surface the information and assurances that their organizations were anxious to get. As the clock ticked, leaders lost confidence and began asking, “isn’t there a better way?”
Limitless data at Elastic
Elastic cannot overcome the laws of physics. However, we approach this problem as a decade-long leader in data analysis. We know that to enable analysis that runs quickly enough to stop damage and loss, the data platform must structure the data as it is stored. Our index-on-write approach is partially responsible for our leadership as the best open source data analysis platform.
And with this focus on structuring the data as it is stored in Elasticsearch®, it also allows for phenomenal search performance over inexpensive object stores. Unlike our competitors’ solutions, when Elastic searches for data in an object store, there is no need to rehydrate its entire contents. Only the index metadata is viewed, and if information is found in the index that can answer the user’s question, that information is retrieved from the object store. In our documentation, we call this capability frozen tier searchable snapshots.
Searchable snapshots allow previously impossible queries to be run across all the data in a system. But what about multiple systems, perhaps spanning cloud hyperscalers like Amazon AWS, Microsoft Azure, and Google Cloud, and on-premises deployments? Again, Elastic innovated with a distributed query capability called cross-cluster search. This capability allows analysts to simultaneously query all their deployments, leaving data where it is collected. To the user, this federated query is virtually invisible — the query itself is identical — looking for evidence of Sunburst? Write the query once, and point it at all your data. The Elastic solution knows where the data lives and distributes the query across systems accordingly. Now, analysts can search from one interface and access data across the globe. This capability massively reduces the cost of data transfer and data storage — only the query and matching results need to traverse the network while also helping maintain data sovereignty.
Now, combine these limitless data capabilities and you have unprecedented access to your data. The data can exist in Elastic deployments anywhere across the globe, even in a snapshot or object storage in cloud hyperscalers or on-premises systems, and can be accessed from a single interface.
And like everything at Elastic, limitless data was built with ludicrous speed in mind. As an example, let’s say you want to run an advanced correlation rule engineered by our Elastic Security Labs team. The hot tier of a typical Elastic Security deployment would return an answer across all your data in just 6 seconds. Applying that same query across frozen data (object storage in S3) would return answers in just 18 seconds.
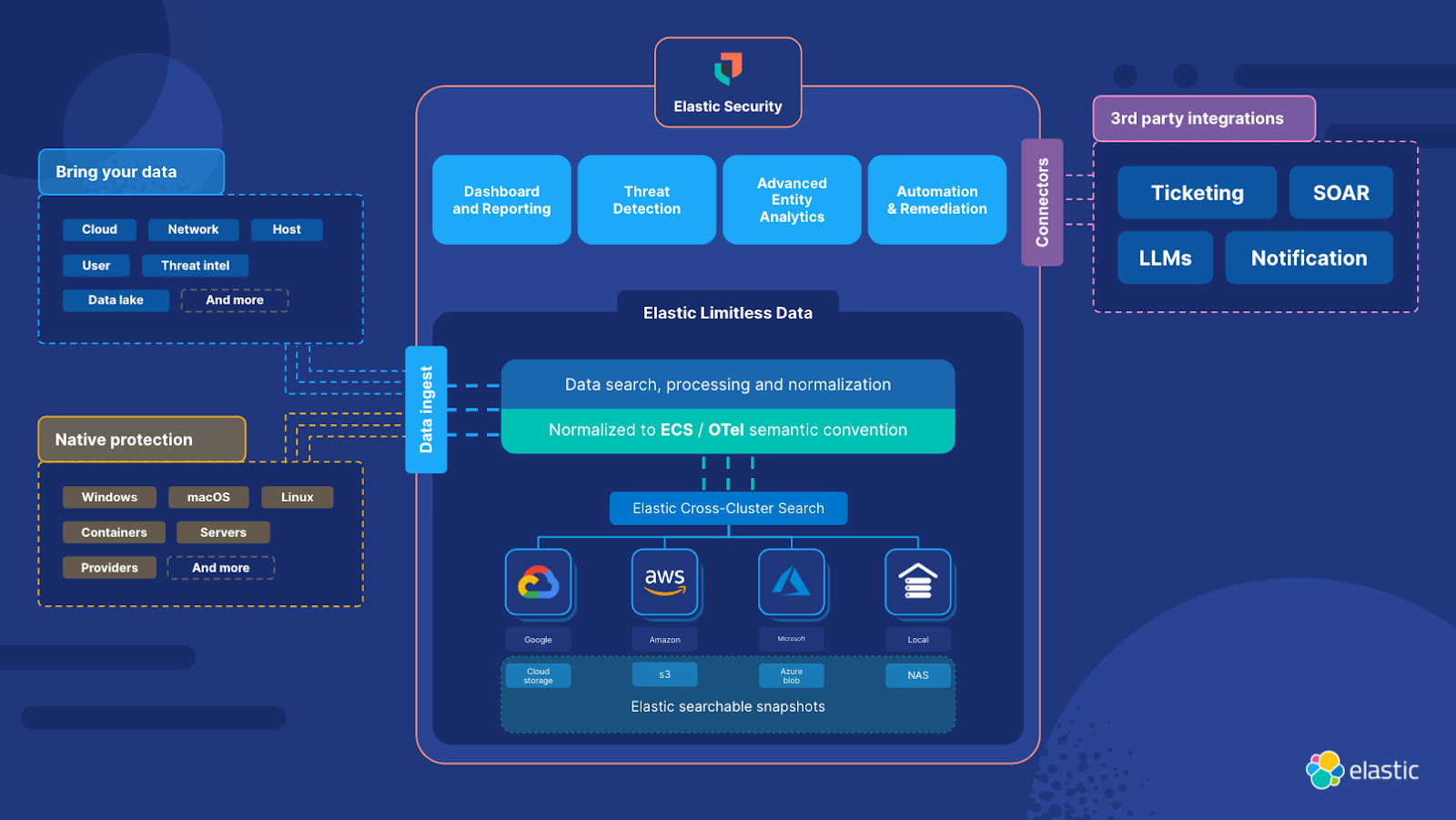
Elastic Security on limitless data
- Elastic Security unifies SIEM, security analytics, XDR, endpoint, and cloud security into a single unified solution, with a single user interface. Made possible by Elasticsearch, Elastic Security fully applies the power of limitless data. The ability to quickly and reliably analyze previously siloed data is helping our users succeed in new ways:
- Threat Detection: Elastic Security Labs delivers over one thousand prebuilt rules on numerous data domains like host, network, and user. While most SIEMs can run detections only against streamed data, in Elastic these rules are all simply search. And, unlike other vendors, our rules are entirely open in both the product and in an open GitHub repository. This means users can take any rule and easily run it across historical information by simply changing the rule lookback time to weeks, months, or even years.
- Advanced Entity Analytics: Beyond rules, our machine learning anomaly detection, supervised machine learning models, and included host and user risk scoring also can operate seamlessly over the limitless data infrastructure. This means our unsupervised models, in addition to performing near-real-time anomaly detections, can be run retrospectively on data spanning much longer time periods than other SIEM platforms typically can.
- Threat hunting and incident response: As the SolarWinds attack showed, threat hunting and incident response is where historical analysis at the speed of Elasticsearch really shines. Invisible to the analyst, Elastic’s investigative workspaces will federate a search over any attached remote system (cluster) and even over object storage to provide complete assurance to the question of “have we seen this before?”.
- Dashboards and other visualizations: Any data available in Elastic can also power our intuitive visualization tools, like Lens. Again, years of data at your fingertips to power dashboards and reports.

All this power — still less expensive than traditional data lakes
Maybe the greatest benefit of limitless data, beyond powering analyst workflows and detection technologies and providing complete business assurance, is that it is also extremely affordable. Customers worldwide are already utilizing the combined power of frozen tier searchable snapshots and cross-cluster search — limitless data — to provide unprecedented security to their organizations. Time and time again, we find that our implementation is not only far more powerful than legacy data lakes, but also less expensive.
One customer averaging about 20TB of data per year saw a 10% savings on their data lake bill. And remember, they are saving money and powering previously impossible workflows.
For an extreme scale example, look no further than the United States’ Cybersecurity and Infrastructure Security Agency (CISA).
The May 2021 release of the Executive Order on Improving the Nation’s Cybersecurity greatly accelerated these efforts. The order requires agencies to deploy an endpoint detection and response (EDR) capability. CISA is tasked with leading the Federal EDR deployment initiative to support host-level visibility, attribution, and response regarding Federal Civilian Executive Branch (FCEB) information systems at scale. The order also mandates the authorization of much-anticipated changes to the agreements between FCEB agencies and DHS, which now require agencies to share detailed information about their systems through the CDM program.
For the first time, the CDM program now has both the technical ability to hunt for threats at scale and policy authorizing it to do so.With the strong support of our partner, ECS, CISA has seen strong success:
In recent weeks, a federal agency identified an active exploit targeting their network. The agency quickly shared cyber threat intelligence with our team at the Cybersecurity and Infrastructure Security Agency (CISA). Though the agency quickly mitigated the threat, CISA used our Continuous Diagnostics and Mitigation (CDM) Federal Dashboard and quickly detected several other vulnerable systems in the federal government related to this exploit. Within minutes, we leveraged this host-level visibility into federal agency infrastructure to confirm potential risks, alert affected agencies, and actively track mitigation — preventing an active exploit from causing widespread harm across agency systems and impacting essential services upon which Americans depend.
Earlier this spring, we achieved a major milestone — all 23 Chief Financial Officer (CFO) Act agencies are now sharing cyber risk information with CISA on a continuous basis through their CDM Agency Dashboards.To learn more about how you can benefit from Elastic’s Limitless Data and try it yourself, start a free cloud trial.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print