Elasticsearchでのソートクエリの最適化によって結果の取得を高速化


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
Elasticsearchでは、特定のフィールドに基づいて結果をソートするようリクエストすることがきわめて一般的です。私たちはユーザーのためにソートクエリを高速化できるよう、時間と労力をつぎ込んでソートクエリを最適化しました。このブログでは、数値および日付フィールドのソート最適化の一部について説明します。
ソートクエリの仕組み
フィルターに一致するドキュメントを検索すると同時にその結果を特定のフィールドに基づいてソートするようリクエストした場合、Elasticsearchでは、該当フィールドのドキュメント値を検証してフィルターに一致したすべてのドキュメントから、上位値を持つ上位K件のドキュメントを選択します。適用範囲がきわめて広いフィルター(match_allクエリなど)の場合、インデックス内のすべてのドキュメントのドキュメント値を検証し、比較する必要があるため、最大の処理負荷がかかります。この場合にインデックスが大きければ、途方もない時間がかかってしまいます。
特定のフィールドに基づいたソートクエリを最適化する1つの方法は、インデックスのソートを使用して、該当フィールドのインデックス全体をソートすることです。インデックスがフィールドでソートされれば、ドキュメント値もソートされます。そうすることで、フィールドでソートして上位K件のドキュメントを得るには上位K件のドキュメントだけあれば済むようになるため、残りのドキュメントを検証する必要がなくなります。そのため、ソートクエリがきわめて高速化されます。
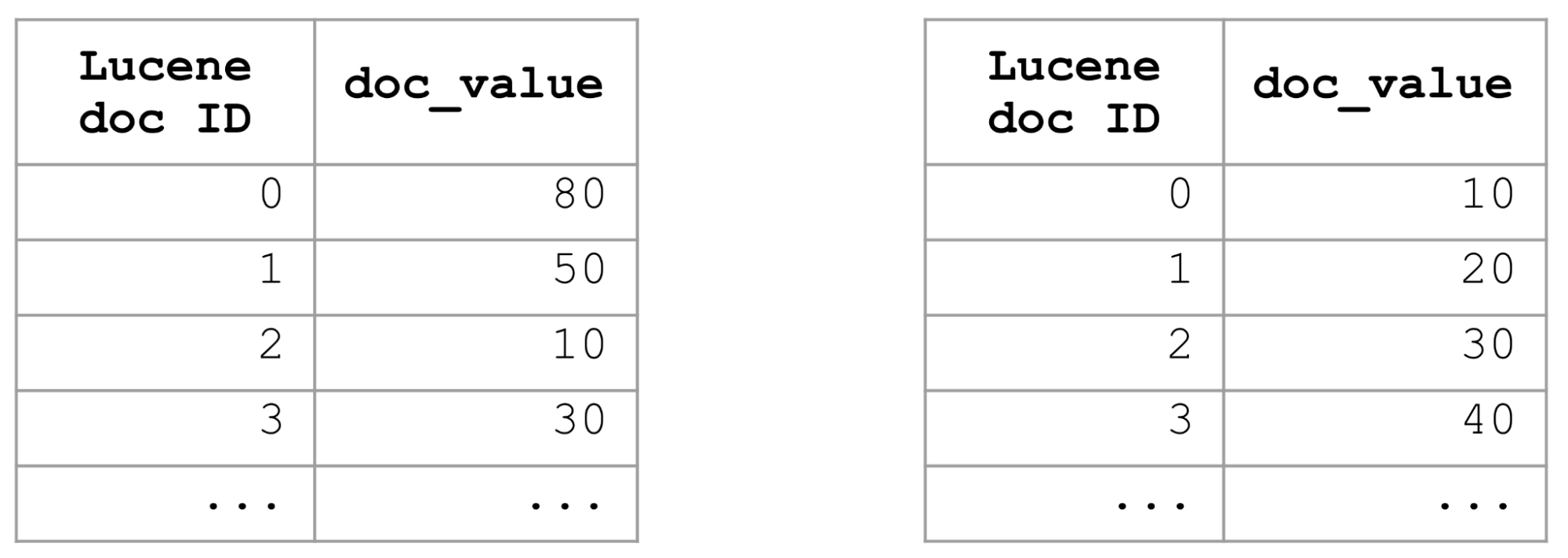
インデックスのソートはすばらしい解決策ですが、これは単一の方法でしか実行できません。そのため、インデックスのソートの定義とは異なるソート基準がソートクエリに設定されている場合は役に立ちません。たとえば、インデックスのソートが降順に対してソートクエリが昇順の場合や、両者のソート基準のフィールドが異なる場合または組み合わせが異なる場合などです。そのような場合は、ソートクエリを高速化するさらに柔軟な他のアプローチが必要です。
distance_featureクエリで数値のソートクエリを最適化
これまでには、ドキュメントの各ブロックについて最大スコア(用語の頻度とドキュメントの長さ)を保存し、_scoreを使用して用語ベースのクエリをソートすることで、大幅な高速化を実現しました。これにより、クエリ中にその最大スコアを確認することでドキュメントのブロックが上位候補であるかどうかを素早く判断できます。ブロックが上位候補ではない場合、ドキュメントのそのブロック全体をスキップすることができるため、クエリがきわめて高速化されます。
これと同様のアプローチを適用することで、数値または日付フィールドに対するソートクエリを高速化することができるのではないかと考えました。そして、ソートをdistance_featureクエリに置き換えることで可能なことが分かりました。distance_featureクエリは、指定した起点に最も近い上位K件のドキュメントを返す興味深いクエリです。起点としてフィールドの最小値を使用した場合、昇順にソートされた上位K件のドキュメントが得られます。起点としてフィールドの最大値を使用した場合、降順にソートされた上位K件のドキュメントが得られます。
distance_featureクエリの最も興味深い特性は、上位候補にならないドキュメントブロックを効率的にスキップできることでした。これは、Elasticsearchで数値および日付フィールドのインデックス化に使用されるBKDツリーの特性によって実現します。テキストフィールドのポスティングインデックスがドキュメントブロックに分割されるのと同様に、BKDインデックスはセルに分割され、各セルはその最小値と最大値を認識します。したがって、distance_featureクエリは、セルの最小値と最大値を検証するだけで効率的に、上位候補にならないドキュメントセルをスキップできます。このソート最適化を機能させるには、数値または日付フィールドがインデックスされていて、ドキュメント値を持っている必要があります。
ドキュメント値のソートをdistance_featureクエリに置き換えることで、大幅な高速化を実現できます(一部のデータセットでは最大35倍高速化)。Elasticsearch 7.6では、日付およびlong型フィールドにこのソート最適化を導入しました。
search_afterでソートクエリを最適化
上述のような高速化を実現できて嬉しく思っていますが、search_afterパラメーターを使用したソートに関する優れた解決策がまだありません。search_afterによるソートはきわめて一般的です。ユーザーは往々にして、結果の1ページ目だけでなく、そのあとのページにも関心があります。そこで、Elasticsearchでのソートクエリの再記述という現在のアプローチに代えて、Lucene内でコンパレーターとコレクターを使用してそのようなソート最適化を実行し、上位候補にならないドキュメントをスキップすることが、より優れた解決策ではないかと判断しました。Luceneのコンパレーターとコレクターはすでにsearch_afterに対応しているため、この問題の解決策となるはずです。上位候補にならないドキュメントブロックをスキップするためにdistance_featureクエリが使用したElasticsearchコードと同じものを、Luceneの数値コンパレーターに追加しました。
search_afterパラメーターによるこのソート最適化は、Elasticsearch 7.16で導入しました。早々に、ナイトリーパフォーマンスペンチマークの一部が大幅に高速化しました(最大10倍)。
複数のセグメント全体のソートを最適化
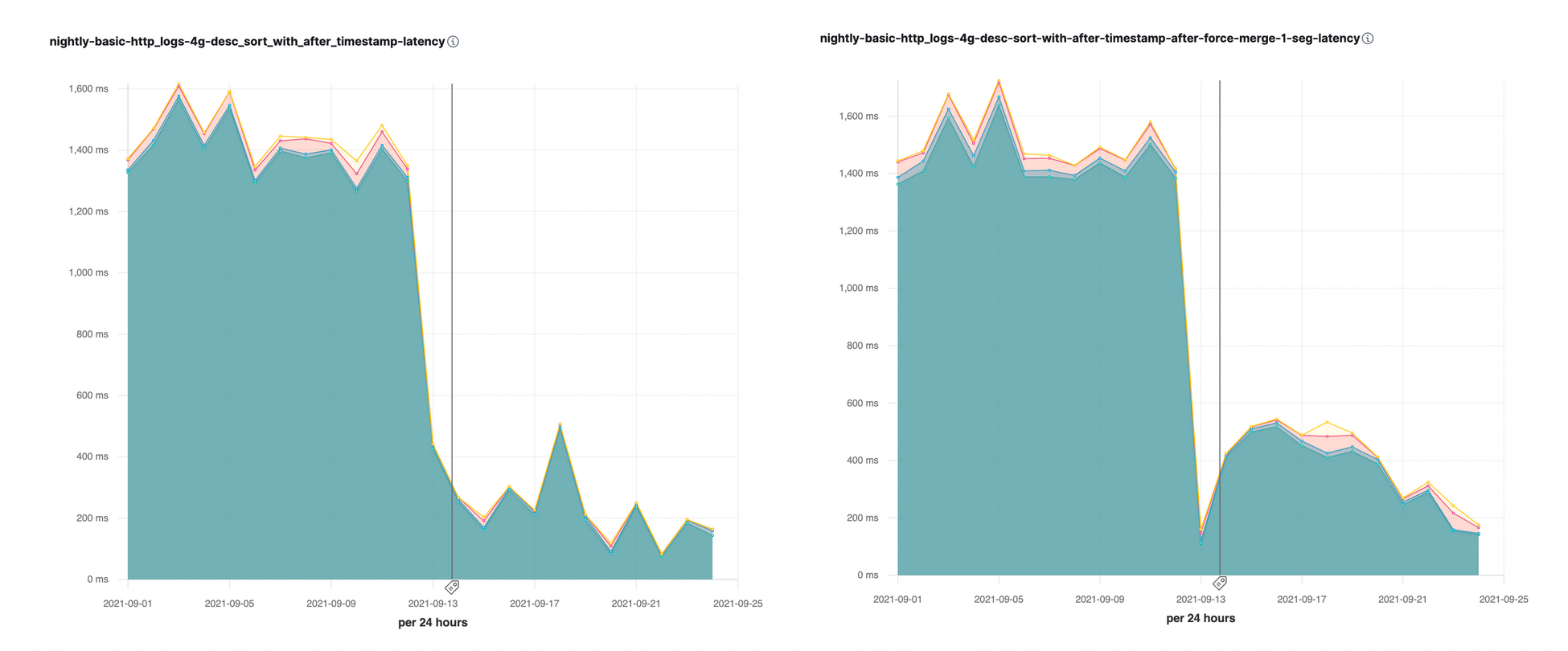
シャードは複数のセグメントから成ります。Elasticsearchでは検索時にセグメントを順番に検証するため、上位K件となるドキュメントを含んでいる可能性が高いセグメントから処理を開始することが非常に有益です。上位K件となるドキュメントを収集すると、それより下位の値を含んでいるその他のセグメントをきわめて迅速にスキップできます。
どのセグメントから処理を開始するかについては、ユースケースによります。時系列インデックスの場合、最も一般的なリクエストはタイムスタンプフィールドで結果を降順に並べ替えることです。これは、最新のイベントが最も関心度の高い項目だからです。時系列インデックスに対するこのようなソートを最適化するためには、@timestampフィールドに基づいてセグメントを降順でソートします。これにより、最新のデータを含むセグメントから処理を開始することができ、タイムスタンプが最新のドキュメントを最初のセグメントで収集し、他のすべてのセグメントをスキップできるため理想的です。この結果、タイムスタンプフィールドの降順によるソートクエリを大幅に高速化することができました。
小さいセグメントはより大きなセグメントにマージされるため、最近のドキュメントが含まれている新しいセグメントが最後になるようなことは避けたいところです。よりバランスの取れたマージセグメントを作成するために、古いセグメントと新しいセグメントを交互に配置する新しいマージポリシーを導入しました。これにより、古いセグメントのドキュメントと新しいセグメントのドキュメントが、新たにマージされたセグメント内に組み合わされた順序で配置されます。このため、マージされていても最新のドキュメントを効率的に検索することができます。
複数のシャード全体のソートを最適化
Elasticsearchの力は、その分散検索にあります。そのため、どの最適化も分散型という側面を考慮しなければ不完全なものとなります。数百ものシャードにわたる検索(時系列インデックスの検索など)では、シャードの「正しい」セットから開始し、上位候補を含んでいないシャードをショートカットすることが非常に有益です。Elasticsearchでは、まさにこのアプローチを導入しています。Elasticsearch 7.6からは、プライマリソートフィールドの最高/最小値に基づいてシャードを事前にソートし、上位値を含んでいることが想定されるシャードセットから分散検索を開始できるようになりました。Elasticsearch 7.7からは、他のシャードの結果を使用してクエリフェーズをショートカットできるようになりました。つまり、一旦、最初のシャードセットから上位値を収集すれば、その他のシャードの値はその収集された上位値の中の最下位の値よりも下位になるため、完全にスキップできます。マシン生成の時系列インデックスの多くでは、ドキュメントはインデックスライフサイクルポリシーに従い、最初はパフォーマンス最適化ハードウェアに格納され、最後はコスト最適化ハードウェアへと移動し、最終的に削除されます。このシャードスキップメカニズムは、通常、パフォーマンス最適化ハードウェアで適用範囲の広いクエリを実行して、そのハードウェアのクエリパフォーマンスを存分に活用するとともに、速度が遅く経済性の高いハードウェアにあるシャードはスキップされる、ということを意味します(特に検索可能スナップショットの使用が効率的です)。
ユーザーへの影響
Elasticsearchのユーザーは、これらのソート最適化をどのように活用すればよいのでしょうか?これらのソート最適化は、リクエストの正確な総ヒット数を追跡する必要がなく、リクエストに集約が含まれていない場合にのみ役立ちます。正確な総ヒット数を知る必要がある場合は、フィルターに一致するすべてのドキュメントの数が必要なため、どの部分もスキップすることができません。track_total_hitsのデフォルト値は10,000に設定されています。これは、10,000件のドキュメントを収集した後にのみ、ソート最適化が開始されることを意味します。この値をより少なく設定した場合、または「false」に設定した場合、Elasticsearchは早めにソート最適化を開始することになり、応答が迅速化されます。
最近、Kibanaでもtrack_total_hitsが無効になっているリクエストの送信を開始したため、Kibanaでのソートクエリも高速になっているはずです。
試してみましょう
Elastic Cloudをご利用のお客様は、ご紹介した機能にElastic Cloudコンソールから直接アクセスしていただけます。Elastic Cloudの導入をご検討中の方は、導入に最適な短いトレーニングビデオ「Quick Start guides」(クイックスタートガイド)や、Elasticが提供する無料の基礎コースをご利用いただけます。Elasticは、Elasticエンタープライズサーチの14日間無料トライアルを常時ご用意しています。また、セルフマネージド版のElastic Stackを無料でダウンロードしてお使いいただくこともできます。
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷