Incorpora búsqueda de AI en tus aplicaciones
Elasticsearch Relevance Engine™ (ESRE) se diseñó para impulsar las aplicaciones de búsqueda basadas en inteligencia artificial. Usa ESRE para aplicar la búsqueda semántica con relevancia superior lista para usar (sin adaptación para el dominio), integrarte en modelos de lenguaje grandes (LLM) externos, implementar la búsqueda híbrida y usar modelos de transformadores propios o de terceros.

Mira lo fácil que es comenzar a configurar Elasticsearch Relevance Engine.
Mira el video de inicio rápidoCompila aplicaciones avanzadas basadas en RAG usando ESRE.
Regístrate para la capacitaciónUsa datos internos privados como contexto con las capacidades de los modelos de AI generativa para brindar respuestas actualizadas y confiables a las consultas de los usuarios.
Mira el videoAI para todos los desarrolladores
Eleva la búsqueda con AI
Brinda capacidades de relevancia de AI avanzadas a tu aplicación con ESRE, sin importar tu nivel de experiencia. ESRE tiene un conjunto de características que te ayudan a dar los primeros pasos o aumentar tu experiencia con la AI. Tienes la flexibilidad y el control para desplegar aplicaciones de búsqueda de machine learning y AI generativa como consideres adecuado.



Elasticsearch Relevance Engine
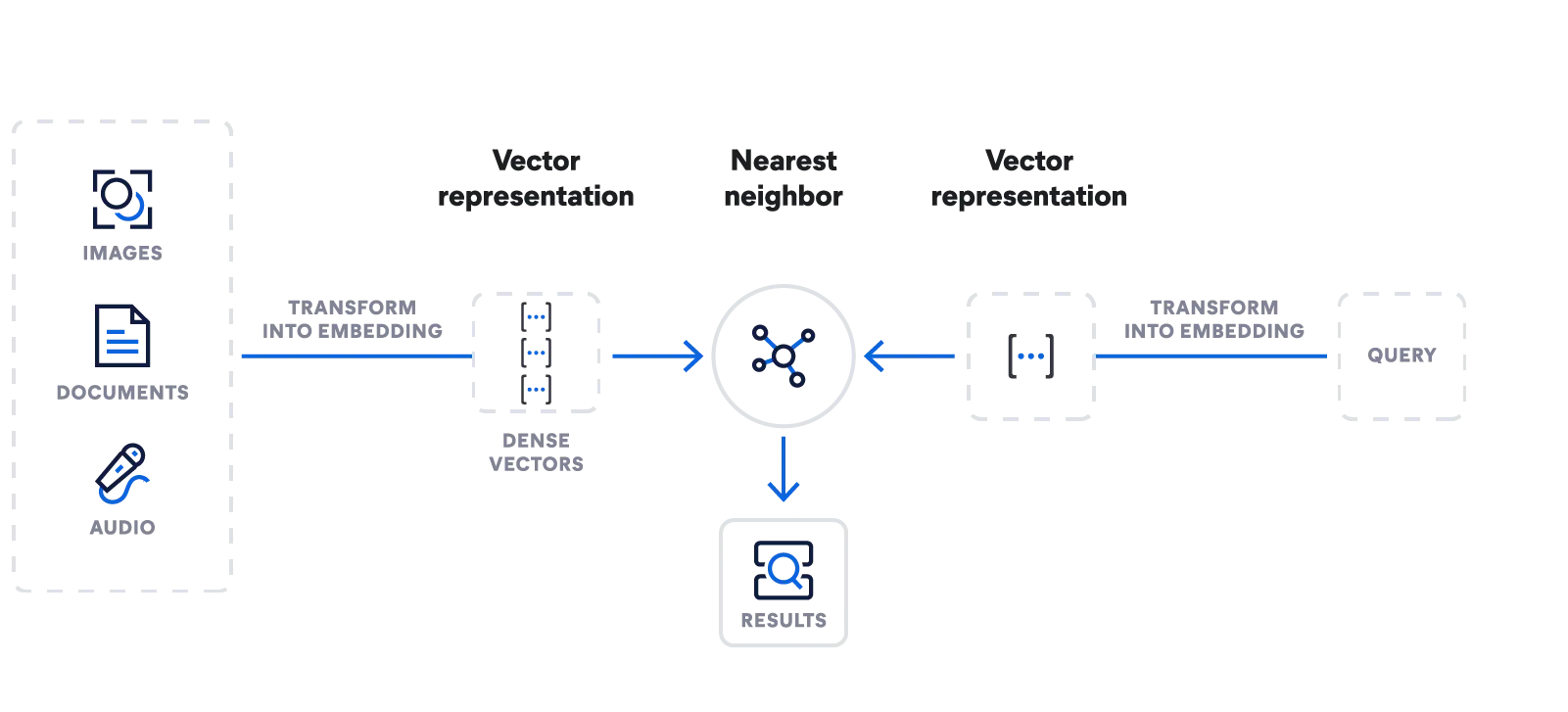
Elasticsearch: Fuente de búsqueda de vectores todo en uno
Genera incrustaciones. Almacena, busca y gestiona vectores. Obtén búsqueda semántica con el modelo de machine learning Learned Sparse Encoder propio de Elastic. Ingesta datos de todo tipo. Intégrate a modelos de lenguaje grandes que evolucionan rápidamente.
Muestras de código
Comienza a crear la búsqueda de vectores
Usa una sola API para importar un modelo de incrustación, generar incrustaciones y escribir búsquedas a escala con la búsqueda de vecino más cercano aproximado.
docker run -it --rm elastic/eland \
eland_import_hub_model \
--cloud-id $CLOUD_ID \
-u <username> -p <password> \
--hub-model-id sentence-transformers/msmarco-MiniLM-L-12-v3 \
--task-type text_embedding \
--startPreguntas frecuentes
¿Qué es Elasticsearch Relevance Engine?
¿Qué es Elasticsearch Relevance Engine?
Elasticsearch Relevance Engine es un conjunto de características que ayuda a los desarrolladores a compilar aplicaciones de búsqueda de AI e incluye:
- Características de clasificación de relevancia avanzadas líderes en la industria, entre las que se encuentran la búsqueda de palabras clave con BM25, una base de búsqueda híbrida y relevante para todos los dominios.
- Capacidades de base de datos de vectores completas, lo cual incluye la capacidad de crear incrustaciones, además del almacenamiento y la recuperación de vectores.
- Elastic Learned Sparse Encoder, nuestro nuevo modelo de machine learning para búsqueda semántica en una variedad de dominios. Clasificación híbrida (RRF) para emparejar capacidades de búsqueda textual y de vectores con el objetivo de alcanzar una relevancia de búsqueda óptima en una variedad de dominios.
- Soporte para la integración de modelos de transformadores de terceros, como OpenAI GPT-3 y 4 a través de API.
- Un conjunto completo de herramientas de ingesta de datos, como conectores de bases de datos, integraciones de datos de terceros, rastreador web y API para crear conectores personalizados.
- Herramientas para desarrolladores que permiten compilar aplicaciones de búsqueda en todo tipo de datos: texto, imágenes, series temporales, geográficos, multimedia y más.
¿Qué puedo crear con Elasticsearch Relevance Engine?
¿Qué puedo crear con Elasticsearch Relevance Engine?
Elasticsearch es una tecnología líder de búsqueda para sitios web (como descubrimiento y productos de comercio electrónico) e información interna (como búsqueda empresarial y bases de conocimiento de éxito de clientes). Con ESRE, brindamos un kit de herramientas para crear experiencias de búsqueda impulsadas por AI. Permite a los usuarios expresar sus búsquedas en lenguaje natural, en forma de pregunta o descripción del tipo de información que buscan. Combina esta capacidad de lenguaje natural con AI generativa para mejorar aún más las capacidades de estos modelos con contexto de tus propios datos privados.
¿Son Elasticsearch y Elasticsearch Relevance Engine lo mismo?
¿Son Elasticsearch y Elasticsearch Relevance Engine lo mismo?
Sí, las capacidades incluidas en Elasticsearch Relevance Engine están diseñadas e integradas dentro de la API _search en Elasticsearch. Los desarrolladores pueden usar la API de Elastic o herramientas conocidas, como Kibana, a fin de interactuar con las capacidades que componen Elasticsearch Relevance Engine junto con Elasticsearch para una experiencia sin inconvenientes.
¿Qué es Elastic Learned Sparse Encoder?
¿Qué es Elastic Learned Sparse Encoder?
Elastic Learned Sparse Encoder es un modelo creado por Elastic para la búsqueda semántica de alta relevancia en una variedad de dominios. En la actualidad, es un modelo de machine learning solo en inglés y captura las relaciones entre los significados y las palabras para la recuperación de información. ¿Te interesan las pruebas comparativas con nuestro nuevo modelo de recuperación? Lee este blog para conocer más.
¿Qué es un transformador? ¿Es Elastic Learned Sparse Encoder un modelo de transformador?
¿Qué es un transformador? ¿Es Elastic Learned Sparse Encoder un modelo de transformador?
Un transformador es una arquitectura de red neuronal profunda que sirve como base para los LLM. Los transformadores consisten en varios componentes y pueden estar compuestos por codificadores, descodificadores y muchas capas de red neuronal "profunda" con muchos millones (o miles de millones) de parámetros. Por lo general, se entrenan con un gran corpus de texto, como datos en Internet, y pueden ajustarse para realizar diversas tareas de NLP. Nuestro nuevo modelo de recuperación usa una arquitectura de transformadores, pero solo contiene un codificador diseñado específicamente para la búsqueda semántica en una gran variedad de dominios.
¿Cómo doy los primeros pasos con Elasticsearch Relevance Engine? ¿Debo comprar Elasticsearch Relevance Engine por separado?
¿Cómo doy los primeros pasos con Elasticsearch Relevance Engine? ¿Debo comprar Elasticsearch Relevance Engine por separado?
Todas las capacidades de Elasticsearch Relevance Engine están incluidas en los planes Platino y Enterprise de Elastic Enterprise Search, como parte de la versión 8.8. Puedes dar los primeros pasos en la búsqueda de vectores e incrustaciones con facilidad y probar el modelo de recuperación. Echa un vistazo a la demostración de las capacidades de Elastic Learned Sparse Encoder. Si tienes una licencia de Elasticsearch, Elasticsearch Relevance Engine está incluido como parte de tu compra.