Vektordatenbank vs. Graphdatenbank: Was sind die Unterschiede?


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Beim Big Data-Management geht es nicht nur darum, möglichst viele Daten zu speichern. Es kommt auch darauf an, aussagekräftige Einblicke zu identifizieren, verborgene Muster zu entdecken und fundierte Entscheidungen zu treffen. Dieser Bedarf nach erweiterten Analytics ist der Innovationsmotor in den Bereichen Datenmodellierung und Speicherlösungen und geht weit über herkömmliche relationale Datenbanken hinaus.
Vektordatenbanken und Graphdatenbanken sind zwei solcher Innovationen. Beide Optionen stehen für beachtliche Fortschritte bei der Datenverwaltung und bieten einzigartige Datenstrukturen, jeweils mit eigenen Vorteilen. Sie müssen sich jedoch mit ihrer Funktionsweise und den Unterschieden vertraut machen, um eine sinnvolle Wahl für Ihr Projekt oder Ihre Ziele treffen zu können.
Dieser Blogpost dient Ihnen als Leitfaden – er zeigt auf, wie sie funktionieren, welche Gemeinsamkeiten sie haben und worin sie sich grundlegend unterscheiden. Wir werden die gegensätzlichen Datenstrukturen untersuchen, ihre idealen Anwendungsfälle beleuchten und Sie bei der Entscheidung zwischen den beiden Optionen unterstützen. Um Ihnen den Überblick zu erleichtern, haben wir den Text in folgende Abschnitte unterteilt:
Vektordatenbank: Definition und Konzepte
Was sind Graphdatenbanken?
Gegenüberstellung von Vektor- und Graphdatenbanken
Anwendungsfälle für Vektor- und Graphdatenbanken
Auswahl zwischen Vektor- und Graphdatenbanken
Dieser Artikel enthält alle Informationen, die Sie für eine fundierte Entscheidung brauchen, um Ihre Daten optimal nutzen zu können.
Vektordatenbank: Definition und Konzepte
Anstelle von Zeilen und Spalten werden Daten in einer Vektordatenbank in einem riesigen, mehrdimensionalen Raum organisiert. Jeder Punkt bildet ein Datenelement ab, und seine Position bildet die Eigenschaften relativ zu anderen Datenelementen ab. Stellen Sie sich ein Universum vor, in dem jeder Planet ein Datenelement ist und in dem ähnliche Planeten näher beieinander liegen als Planeten mit weniger Ähnlichkeiten.
Zu diesem Zweck werden die Daten als hochdimensionale Vektoren mit numerischen Abbildungen der Datenmerkmale gespeichert. Diese Vektoren erfassen die Essenz der Daten, die sie abbilden, um sie im mehrdimensionalen Raum codieren und organisieren zu können. Je näher zwei Punkte einander in diesem mehrdimensionalen Raum sind, desto ähnlicher sind die zugrunde liegenden Daten.
Darum eignen sich Vektordatenbanken hervorragend für die Ähnlichkeitssuche. Da die Vektoren anhand ihrer Ähnlichkeit strukturiert sind, können Sie im Handumdrehen Datenpunkte identifizieren, die Ihrem Abfragevektor am nächsten liegen. Dadurch eignet sich diese Technologie ideal für einige wichtige Anwendungsfälle:
Abrufen von Bildern und Dokumenten: Finden Sie ähnliche Bilder basierend auf dem tatsächlichen Inhalt und nicht mehr nur auf der Grundlage von Schlüsselwörtern.
Personalisierte Empfehlungen: Empfehlen Sie Produkte oder Inhalte, die denen ähneln, mit denen ein Nutzer zuvor interagiert hat.
Anomalieerkennung: Identifizieren Sie ungewöhnliche Datenpunkte, die von der Norm abweichen und auf Betrugsversuche oder Systemfehler hindeuten können.
Machine Learning: Verarbeiten und analysieren Sie hochdimensionale Daten für Aufgaben wie Textanalyse, Bildklassifizierung und natürliche Sprachverarbeitung.
Sie benötigen eine detailliertere Anleitung? Unter „Was ist eine Vektordatenbank?“ finden Sie eine ausführliche Anleitung.
Was sind Graphdatenbanken?
Graphdatenbanken sehen zwar auf den ersten Blick ähnlich aus, organisieren aber Daten auf völlig andere Art und Weise. Anstelle von starren Tabellen wie in einer relationalen Datenbank oder nach Ähnlichkeitskriterien wie in Vektordatenbanken speichern sie Daten in einer Graphstruktur. Entitäten werden auf dem Graph als Knoten abgebildet und Beziehungen als Kanten. Stellen Sie sich eine Art Gedächtniskarte vor, bei der jeder Knoten ein Kreis ist, der Personen, Orte oder Dinge abbildet, und die Linien (Kanten) zwischen ihnen zeigen, wie sie miteinander verbunden sind.
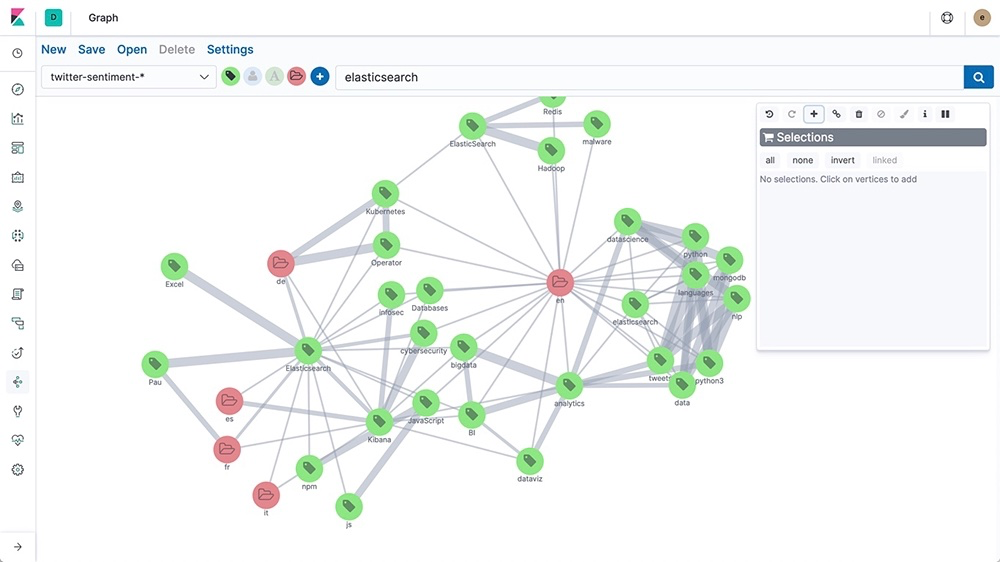
Einer der Vorteile dieser Struktur ist die Tatsache, dass sie komplexe Beziehungen auf natürliche Weise abbilden kann. Auf diese Weise lassen sich die Verbindungen im Vergleich zu anderen Datenbanktypen einfacher auswerten. Durch die schemalose Struktur können Sie in Graphdatenbanken mühelos neue Knoten und Kanten hinzufügen, wenn Ihre Daten wachsen. Damit sind diese Datenbanken sowohl flexibel als auch skalierbar. Dank dieser Eigenschaften eignen sich Graphdatenbanken ideal für viele Anwendungsfälle:
Echtzeit-Analysen: Analysieren Sie Streamingdaten, prognostizieren Sie zukünftige Ereignisse und optimieren Sie dynamische Systeme in Echtzeit mit Graphdatenbanken.
Master Data Management: Erstellen Sie eine einheitliche Ansicht für Entitäten, lösen Sie Mehrdeutigkeiten auf und verfolgen Sie die Entwicklung von Entitäten mit einem einzigen vernetzten Graph.
Netzwerkerkennung: Entdecken Sie verborgene Verbindungen, identifizieren Sie Anomalien und sagen Sie kaskadierende Ausfälle vorher, indem Sie Beziehungen in Netzwerken analysieren.
Aufbau von Wissensgraphen: Erstellen Sie intelligente Wissensdatenbanken, beantworten Sie komplexe Fragen und füttern Sie intelligente Anwendungen mit vernetzten Entitäten und Konzepten.
Gegenüberstellung von Vektor- und Graphdatenbanken
Inzwischen sollten Sie wissen, wie diese Datenbanken funktionieren und wie sie Daten strukturieren. Es ist jedoch auch wichtig, die genauen Unterschiede zwischen Vektor- und Graphdatenbanken zu kennen. Betrachten wir dazu diese direkte Gegenüberstellung:
| Vektordatenbank | Graphdatenbank | |
| Abbildung der Daten | Daten werden als Punkte in einem riesigen, mehrdimensionalen Raum abgebildet. Punkte, die einander näher stehen, bilden ähnliche Inhalte ab. Ideal zum Erfassen von Ähnlichkeiten in den eigentlichen Daten unabhängig von Verbindungen oder Beziehungen. | Daten werden als Netz aus Knoten (Entitäten) dargestellt, die über Kanten (Beziehungen) miteinander verbunden sind. Konzentriert sich auf die Verbindungen und Hierarchien zwischen Datenpunkten und liefert wertvolle Einblicke in die Beziehungen zwischen Entitäten. |
| Abfrage und Abruf | Eignet sich hervorragend für die Ähnlichkeitssuche und kann Datenpunkte, die einem Abfragevektor ähneln, effektiv finden. Ideal für Aufgaben wie Bild- oder Dokumentabruf, bei denen es darauf ankommt, die Ähnlichkeit zwischen Inhalten zu verstehen. | Leistungsstark beim Navigieren zwischen Beziehungen und Verbindungen. Gut geeignet zum Durchlaufen von Netzwerkstrukturen, perfekt für Analysen in sozialen Netzwerken oder Empfehlungssysteme sowie zum Erkunden von Wissensgraphen. |
| Leistung und Skalierbarkeit | Skaliert im Allgemeinen gut mit großen Datensätzen aufgrund von optimierten Algorithmen für die Ähnlichkeitssuche. Schemaänderungen können jedoch erneute Dateneinbettungen erfordern, was die Leistung beeinträchtigen kann. | Extrem flexibel durch die schemalose Struktur, einfaches Hinzufügen und Verändern von Daten. Komplexe Abfragen oder große Netzwerke können jedoch die Leistung beeinträchtigen und erfordern sorgfältige Optimierung. |
Anwendungsfälle
Sehen wir uns nun die Einsatzmöglichkeiten von Vektor- und Graphdatenbanken innerhalb derselben Branche an, um uns die Unterschiede der beiden Technologien zu verdeutlichen. Dabei lernen Sie nicht nur die Unterschiede kennen, sondern erfahren auch, wie sich mit einer kombinierten Lösung großartige Ergebnisse erzielen lassen:
Betrugserkennung
Vektordatenbanken: Identifizieren Sie betrügerische Transaktionen durch die Analyse von Transaktionsmustern und Nutzerdaten. Erkennen Sie Anomalien bei Konsumgewohnheiten, Kaufübergreifenden Standorten oder Geräte-Fingerabdrücken auf der Grundlage erlernter Ähnlichkeitsprofile.
- Graphdatenbanken: Decken Sie verdächtige Netzwerke von miteinander verknüpften Personen oder Transaktionen auf. Identifizieren Sie betrügerische Aktivitäten, indem Sie die Beziehungen zwischen den Entitäten analysieren, die an potenziellen Betrugsversuchen beteiligt sind.
Wissenschaft und Forschung
Vektordatenbanken: Analysieren Sie komplexe Datenstrukturen wie Proteinsequenzen, Genexpressionen oder chemische Verbindungen. Vergleichen Sie unterschiedliche Datensätze und identifizieren Sie Ähnlichkeiten auf der Grundlage mehrdimensionaler Merkmale, um den Weg für neue wissenschaftliche Erkenntnisse zu ebnen.
- Graphdatenbanken: Modellieren Sie biologische Pfade oder molekulare Interaktionen. Erforschen Sie komplexe Beziehungen zwischen Entitäten und visualisieren Sie vielschichtige Systeme, um ein tieferes Verständnis biologischer Prozesse zu erlangen.
E-Commerce
Vektordatenbanken: Analysieren Sie Produktattribute wie Bilder, Textbeschreibungen und technische Spezifikationen. Empfehlen Sie ähnliche Produkte auf der Grundlage von Inhaltsähnlichkeiten, um relevantere und ansprechendere Vorschläge zu liefern.
- Graphdatenbanken: Erfassen Sie Interaktionen zwischen Nutzer:innen und Produkten, wie Käufe, Browserverlauf und Wunschlisten. Empfehlen Sie Produkte basierend auf den Ähnlichkeiten zu anderen Nutzer:innen mit vergleichbarem Geschmack, um ein personalisierteres Einkaufserlebnis zu schaffen.
Medien und Entertainment
Vektordatenbanken: Analysieren Sie Inhaltsmerkmale wie Musikgenres, Artikelthemen oder Filmgenres. Empfehlen Sie ähnliche Songs, Filme oder Artikel auf der Grundlage inhärenter Inhaltsähnlichkeiten, um gezielt auf individuelle Vorlieben einzugehen.
- Graphdatenbanken: Erforschen Sie die Beziehungen zwischen Nutzer:innen und Inhalten, wie den Wiedergabeverlauf, Leselisten oder Social-Media-Shares. Empfehlen Sie Inhalte basierend auf den Verbindungen zwischen Nutzer:innen mit ähnlichen Interessen, um die Interaktion zu fördern und Neuentdeckungen zu ermöglichen.
Auswahl zwischen Vektor- und Graphdatenbanken
Trotz all den Informationen, die wir in diesem Artikel behandelt haben, ist die Wahl der richtigen Datenbank manchmal immer noch eine abschreckende Aufgabe. Um diesen Prozess zu vereinfachen, haben wir das folgende Framework erstellt, das Sie bei einer optimalen Entscheidung für Ihre Ziele unterstützt.
Schritt 1: Daten verstehen
Zuallererst ist es wichtig, sich mit der Komplexität Ihrer Daten auseinanderzusetzen. Sind die Daten hauptsächlich strukturiert oder unstrukturiert? Enthalten sie vielschichtige Beziehungen oder voneinander unabhängige Entitäten?
Berücksichtigen Sie außerdem das Volumen und das erwartete Wachstum Ihrer Daten. Entscheiden Sie anschließend, welche Merkmale oder Attribute Ihre Datenpunkte definieren und ob diese Merkmale oder Attribute numerisch oder kategorisch sind.
Schritt 2: Wichtige Anwendungsfälle identifizieren
Kurz gesagt: Welche Einblicke erhoffen Sie sich von Ihrer Datenanalyse? Möchten Sie ähnliche Datenpunkte anhand bestimmter Inhalte finden oder komplexe Verbindungen zwischen Entitäten erkunden. Welche Arten von Abfragen werden Sie häufig ausführen?
Schritt 3: Leistungs- und Skalierbarkeitsanforderungen
Fragen Sie sich im dritten Schritt, wie wichtig Geschwindigkeit und Skalierbarkeit für Ihr Ziel sind. Wie entscheidend sind Echtzeitantworten für Ihre Anwendung? Wie groß sind Ihre Datensätze, und wie komplex sind die zu erwartenden Abfragen? Betrachten Sie außerdem Ihre Budget- und Ressourceneinschränkungen.
Schritt 4: Die spezifischen Vorteile jeder Technologie bewerten
Jeder dieser Datenbanktypen hat eigene Stärken und Schwächen. Vektordatenbanken eignen sich ideal für die Ähnlichkeitssuche, den Umgang mit hochdimensionalen Daten und große Datensätze. Graphdatenbanken eignen sich dagegen besser zum Navigieren von Beziehungen sowie zur Analyse komplexer Netzwerke und sind extrem flexibel im Hinblick auf ihr Schema.
Potenzial Ihrer Daten voll ausschöpfen
Für die Navigation im Big Data-Umfeld brauchen Sie leistungsstarke Tools, und sowohl Vektor- als auch Graphdatenbanken sind innovative Alternativen in diesem Informationsraum. Die Auswahl des passenden Modells für Ihre Anforderungen ist jedoch manchmal abschreckend.
Überprüfen Sie die oben genannten Faktoren sorgfältig, um sich mit den Stärken der einzelnen Technologien vertraut zu machen. Dabei erhalten Sie eine Liste von Faktoren, die Sie dabei unterstützen, das richtige Datenbankmodell zu wählen, um das Potenzial Ihrer Daten voll auszuschöpfen.
Nächste Schritte
Sobald Sie bereit sind, helfen wir Ihnen auf die folgenden vier Arten, bessere Sucherlebnisse für Ihr Unternehmen zu erstellen:
Starten Sie eine kostenlose Testversion und erfahren Sie, wie Elastic Ihrem Unternehmen helfen kann.
Lernen Sie unsere Lösungen bei einer Tour kennen, um zu sehen, wie die Elasticsearch-Plattform funktioniert und wie unsere Lösungen Ihre Anforderungen erfüllen.
Erfahren Sie, wie Vektordatenbanken die KI-Suche unterstützen.
Teilen Sie diesen Artikel mit interessierten Personen per E-Mail, LinkedIn, Twitter oder Facebook.
Entdecken Sie weitere Ressourcen rund um Datenanalysen und Datenbanken (teils auf Englisch):
Die Entscheidung über die Veröffentlichung der in diesem Blogeintrag beschriebenen Leistungsmerkmale und Features sowie deren Zeitpunkt liegt allein bei Elastic. Es ist möglich, dass noch nicht verfügbare Leistungsmerkmale oder Features nicht rechtzeitig oder überhaupt nicht veröffentlicht werden.
In diesem Blogpost haben wir möglicherweise generative KI-Tools von Drittanbietern verwendet oder darauf Bezug genommen, die von ihren jeweiligen Eigentümern betrieben werden. Elastic hat keine Kontrolle über die Drittanbieter-Tools und übernimmt keine Verantwortung oder Haftung für ihre Inhalte, ihren Betrieb oder ihre Anwendung sowie für etwaige Verluste oder Schäden, die sich aus Ihrer Anwendung solcher Tools ergeben. Gehen Sie vorsichtig vor, wenn Sie KI-Tools mit personenbezogenen, sensiblen oder vertraulichen Daten verwenden. Alle von Ihnen eingegebenen Daten können für das Training von KI oder andere Zwecke verwendet werden. Es gibt keine Garantie dafür, dass von Ihnen bereitgestellte Informationen sicher oder vertraulich behandelt werden. Setzen Sie sich vor Gebrauch mit den Datenschutzpraktiken und den Nutzungsbedingungen generativer KI-Tools auseinander.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine und zugehörige Marken, Waren- und Dienstleistungszeichen sind Marken oder eingetragene Marken von Elastic N.V. in den USA und anderen Ländern. Alle anderen Unternehmens- und Produktnamen sind Marken, Logos oder eingetragene Marken ihrer jeweiligen Eigentümer.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken