Elasticsearch powering Twitter Archives at Institut National de l’Audiovisuel
Since its creation in 1974, Institut national de l’audiovisuel (Ina) is, by law, in charge of collecting, preserving and making available French audiovisual collections. In 1992 due to its existing obligations, Ina was designated by law as being responsible for the Legal Deposit of radio and television.
In 2006, the Legal Deposit’s scope was extended to cover French public web content splitting responsibility between the French national library (BnF) and Ina. Since then, DLWeb team at Ina is in charge of archiving all the broadcast-related French websites e.g. radio and TV channels websites, blogs, etc. and also providing interfaces to help users to better visualize and analyze web archives. As part of these efforts, the team has also been collecting and archiving tweets since 2014 by using Twitter APIs to follow 12,000 users and 600 hashtags.
To index the web page archives, representing 4.5 billions web pages, the DLWeb team migrated its search engine to Elasticsearch. In this project, Elasticsearch showed great power and flexibility for search so we decided to also use it to index the Twitter archives, which represent 400 millions of tweets, with an average of 300,000 new tweets per day. Our Twitter index is based on our principal Elasticsearch deployment with 32 shards spread over 4 servers - 32 nodes. Each server has 4 SSD of 1TB and 96 Gb of RAM, and after doing several tests; we have found a performance sweet spot with 2 elasticsearch nodes by SSD. So we finally decided to use 8 elasticsearch nodes with 6Gb of heap size by server to optimize IO and CPU operations. We will be moving to 12 servers - 96 nodes soon.
Providing an efficient search interface combined with multiple filters (e.g. dates, hashtags, mentions, etc.) is very important while working with archived data. Our search interface combines search queries and filters of Elasticsearch as shown below.
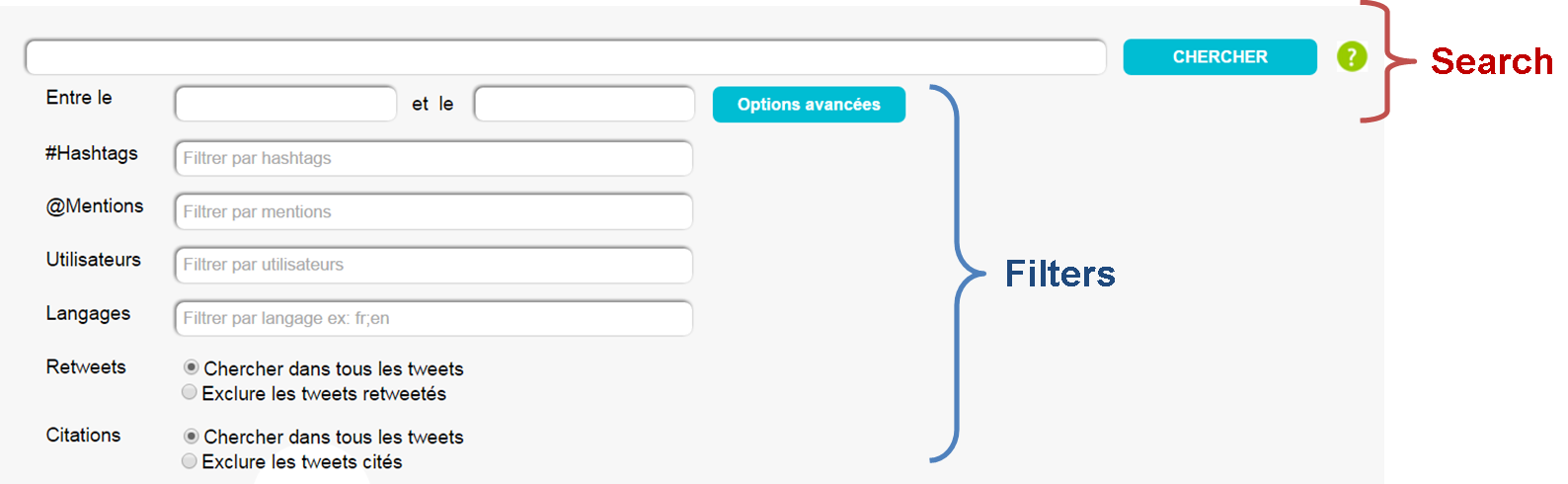
Figure 1 - Twitter Archive Search Interface
Mining Twitter data requires not only full text search but also data aggregation at different levels. To satisfy diverse research needs, we need to offer generic solutions. With Elasticsearch we can search and filter data as well as perform analytics at the same time in a single request. Kibana helps us to build our dashboards and decide which kind of aggregations we can provide to our users. By using aggregations and sub-aggregations we are able to provide diverse analytics (e.g. timelines, top hashtags, top distributions, etc.) for a given query with a high performance as shown below.

Figure 2 - Query Timeline
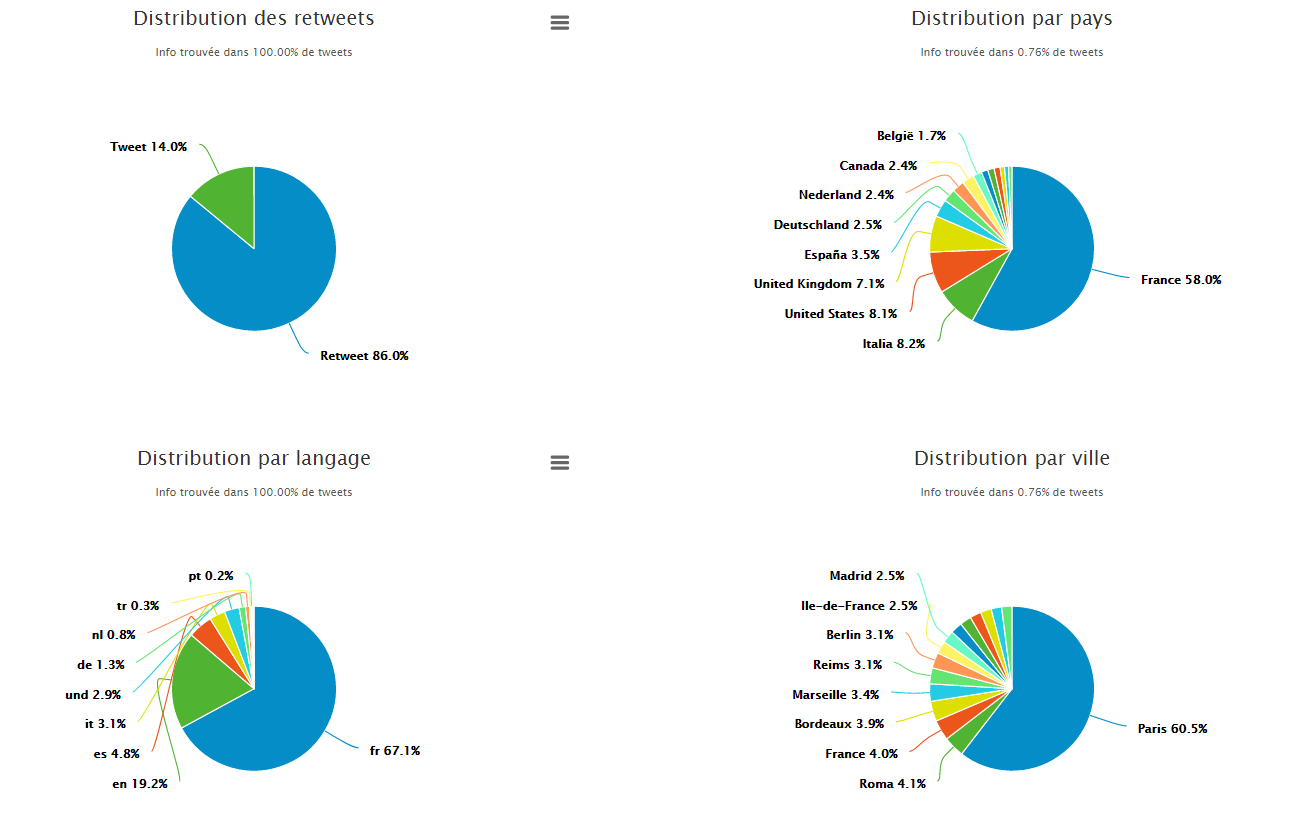
Figure 3 - Aggregations and Sub-Aggregations Dashboards
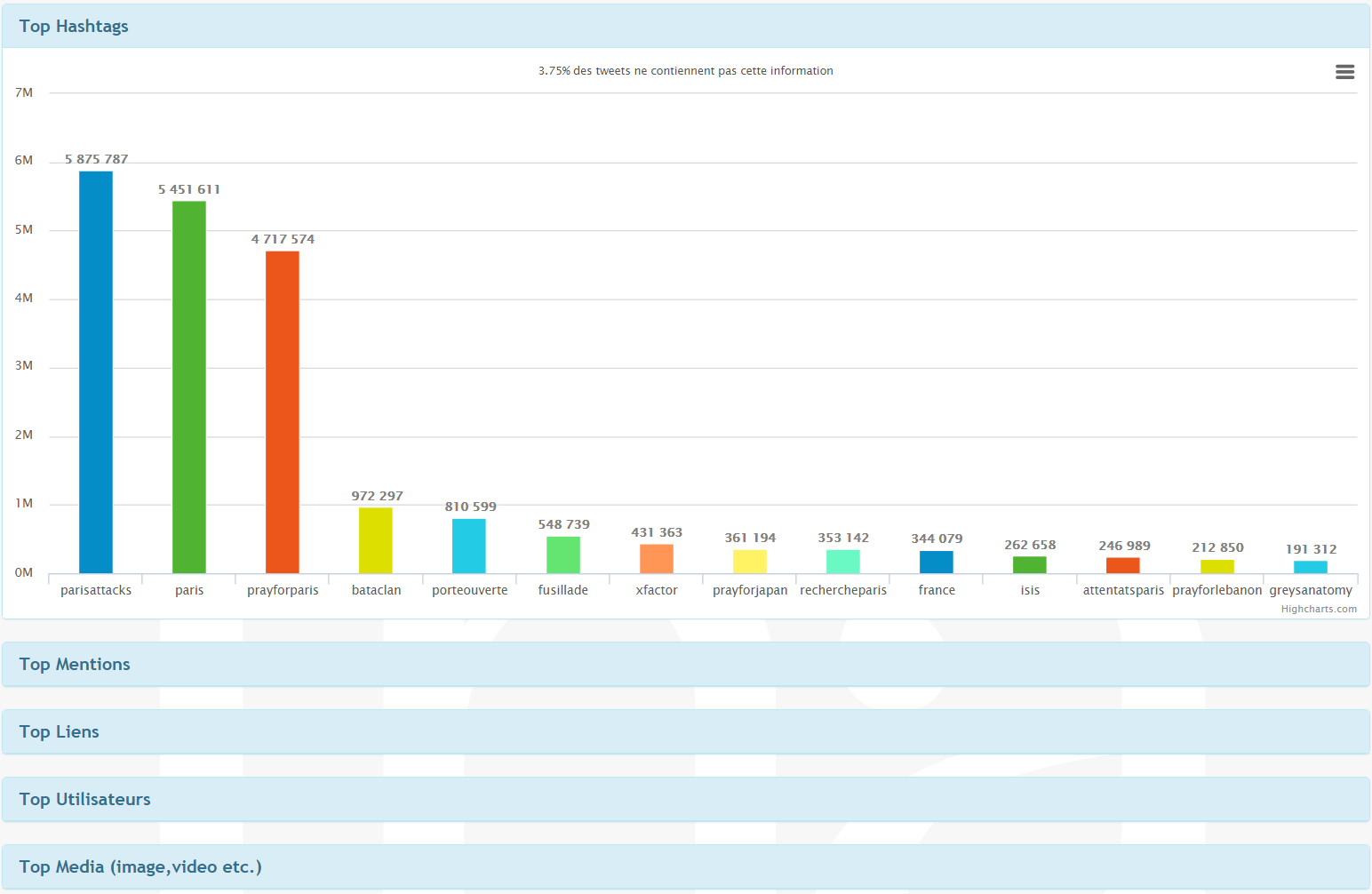
Figure 4 - Top Entities for a Given Query
Legal Deposit web archives of Ina may only be accessed for study and research purposes at Inatheque.
DLWeb team is involved in several national and international research projects based on Twitter data such as ASAP: https://asap.hypotheses.org/ and REAT: https://reat.hypotheses.org/ where the interface described above is used by several researchers.