关于重建索引 API 使用和故障排查的 3 个最佳实践


 Share on Twitter
Share on Twitter在 Twitter 上分享

 Share on LinkedIn
Share on LinkedIn在 LinkedIn 上分享

 Share on Facebook
Share on Facebook在 Facebook 上分享

 Share by Email
Share by Email通过邮件分享

 Print this page
Print this page打印
使用 Elasticsearch 时,您可能想要将数据从一个索引移动到另一个索引,甚至是从一个 Elasticsearch 集群移动到另一个 Elasticsearch 集群。您可以使用多种变体和功能,重建索引 API 就是其中之一。
在本篇博文中,我将介绍重建索引 API,探讨如何判断该 API 是否在正常运行,有哪些因素会导致潜在的故障,以及如何排除故障。
阅读完本篇博文后,您将会了解重建索引 API 的各个选项,以及如何自信地运行它。
重建索引 API 是众多用例中最实用的 API 之一:
- 在集群之间传输数据(从远程集群重建索引)
- 重新定义、更改和/或更新映射
- 通过采集管道进行处理和编制索引
- 通过清除已删除的文档回收存储空间
- 通过查询筛选器将大型索引拆分成较小的索引组
在中型或大型索引中运行重建索引 API 时,完整的重建索引可能需要超过 120 秒的时间,这意味着您将不会收到重建索引 API 的最终响应,也不知道它何时完成、状态是否正常或是否存在故障。
下面让我们一探究竟!
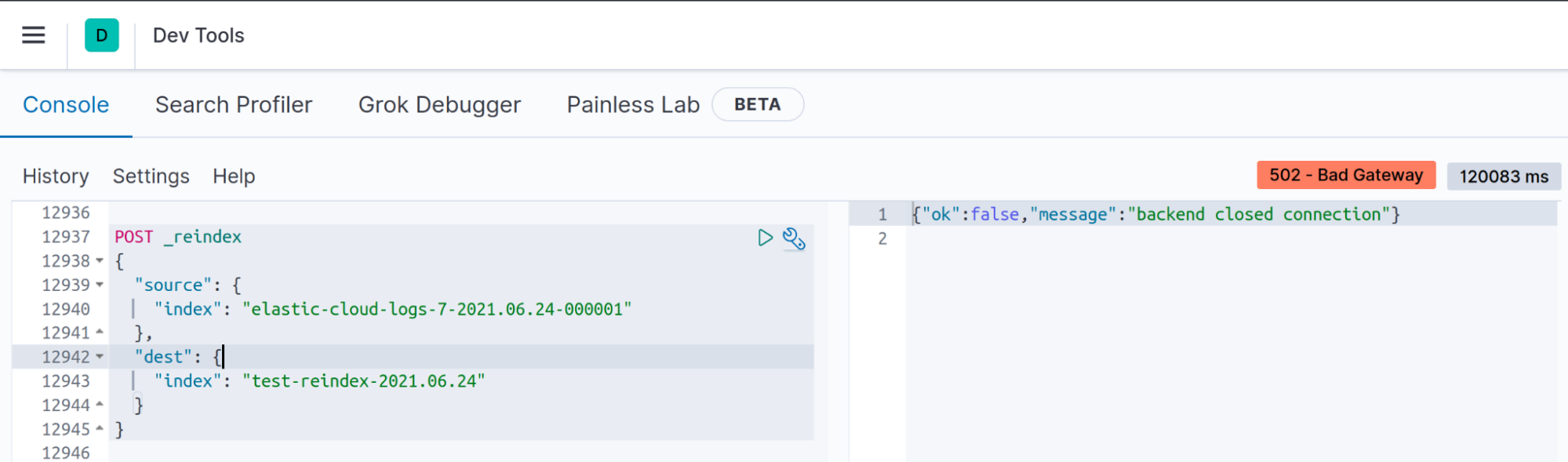
症状:Kibana 开发工具中显示“backend closed connection”(后端已关闭连接)
当您对中型或大型索引执行重建索引 API 时,客户端与 Elasticsearch 之间的连接会超时,但这并不意味着不会执行重建索引。
问题
您的客户端将在 N 秒后关闭非活动套接字;以 Kibana 为例,如果重建索引操作无法在 120 秒内(v7.13 中默认的 server.socketTimeout 值)完成,您将看到“backend closed connection”(后端已关闭连接)消息。
解决方案 #1 - 获取在集群上运行的任务列表
其实这并不是问题,即使您在 Kibana 中看到这条消息,Elasticsearch 也会在后台运行重建索引 API。
您可以使用 _task API 跟踪重建索引 API 的执行情况,并查看所有指标:
GET _tasks?actions=*reindex&wait_for_completion=false&detailed这个 API 将向您显示当前在 Elasticsearch 集群中运行的所有重建索引 API,如果您在此列表中没有看到您的重建索引 API,即表明它已完成。

如上图所示,我们可以看到关于文档的创建、更新甚至是冲突的详细信息。
解决方案 #2 - 将重建索引结果存储在 _tasks 上
如果已知重建索引操作需要的时间超过 120 秒(120 秒是 Kibana 开发工具的超时时间),可以使用查询参数 wait_for_completion= false 来存储重建索引 API 的结果,这样您就能使用 _task API 来获取重建索引 API 结束时的状态(也可以从“.tasks”索引获取文档,如 wait_for_completion=false 的文档中所述)。
POST _reindex?wait_for_completion=false
{
"conflicts": "proceed",
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
当您使用“wait_for_completion=false”执行重建索引时,响应将类似于以下内容:
{
"task" : "a9Aa_I_ZSl-4bjR5vZLnSA:247906"
}
您需要保留这里提供的任务,搜索重建索引的结果时会用到(您将看到已创建的文档数、冲突甚至是错误;完成后,您将看到所花费的时间、批次数等等):
GET _tasks/a9Aa_I_ZSl-4bjR5vZLnSA:247906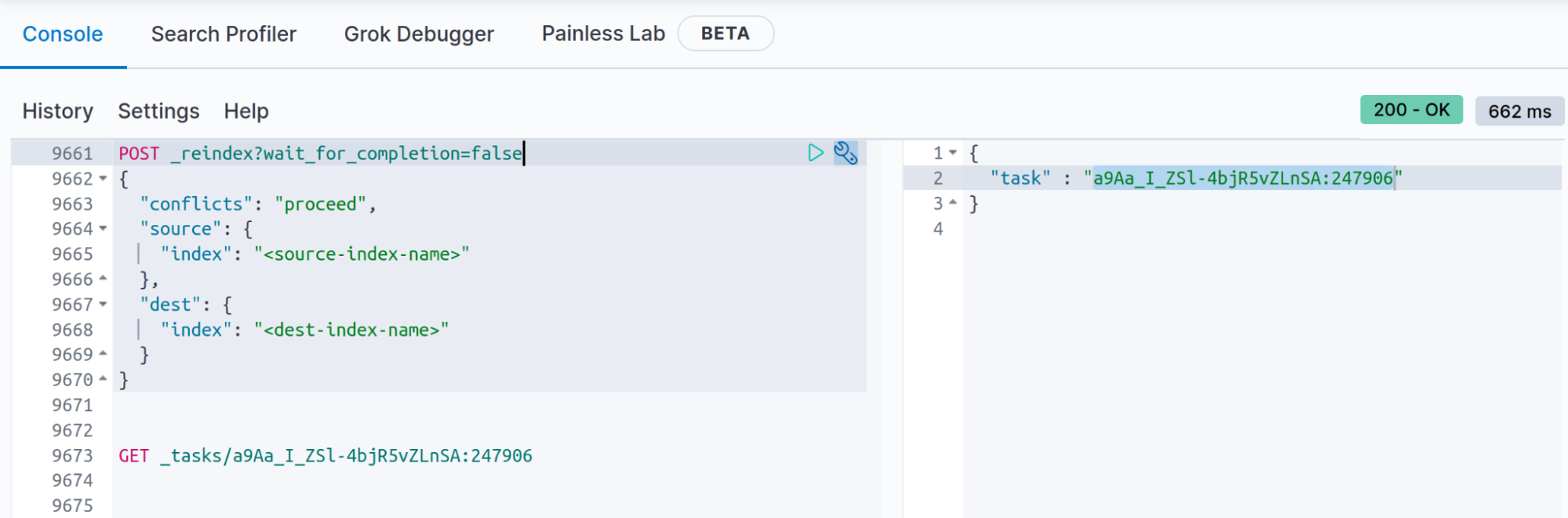
症状:_task API 列表中没有您的重建索引 API。
如果使用上文提到的 API 无法找到重建索引 API 操作,可能这又是另一个问题,下面我们一个一个地解决。
问题
如果重建索引 API 不在列表中,即表明操作已完成,因为没有更多的文档需要重建索引,或者是因为出现了错误。
我们将使用 _cat count API 来查看存储在两个索引中的文档数量,如果两个数值不同,则表明您的重建索引 API 执行已失败。
GET _cat/count/<source-index-name>?h=count
GET _cat/count/<dest-index-name>?h=count
您需要将
解决方案 #1 - 这是一个冲突问题
最常见的错误之一是存在冲突,默认情况下,如果有冲突,重建索引 API 将中止。
现在,我们有两个选择:
- 将“conflicts”设置为“proceed”,这样重建索引 API 将忽略无法索引的文档,转而索引其他文档。
- 或者,我们也可以选择修复冲突,这样就可以为所有文档重建索引。
第一个选择中的冲突设置如下所示:
POST _reindex
{
"conflicts": "proceed",
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
或者,在第二个选择中,我们将搜索并修复产生冲突的错误:
- 避免这一问题的最佳实践是在目标索引上定义映射或模板。这些错误中 99% 是源索引和目标索引之间的字段类型不匹配。
- 如果在定义了映射或模板后,问题仍然存在,则表明某些文档可能无法建立索引,并且默认情况下不会记录错误。我们需要启用记录器,以便在 Elasticsearch 日志中查看错误。
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":"DEBUG"
}
}
- 启用记录器后,我们需要再执行一次重建索引 API,如果可能的话,将“conflicts”设置为“proceed”,因为很多时候源索引和目标索引之间会有多个字段发生冲突。
- 现在,重建索引 API 正在运行,我们将在日志中使用 grep 命令查找/搜索“failed to execute bulk item”或“MapperParsingException”
failed to execute bulk item (index) index {[my-dest-index-00001][_doc][11], source[{
"test-field": "ABC"
}
或
"org.elasticsearch.index.mapper.MapperParsingException: failed to parse field [test-field] of type [long] in document with id '11'. Preview of field's value: 'ABC'",
"at org.elasticsearch.index.mapper.FieldMapper.parse(FieldMapper.java:216) ~[elasticsearch-7.13.4.jar:7.13.4]",
通过这个堆栈跟踪,我们已经有足够的信息来理解冲突是什么。在我的重建索引 API 中,目标索引有一个名为 [test-field] 的字段,类型为 [long],重建索引 API 尝试将该字段设置为字符串“ABC”(您可以用自己的内容字段替换“ABC”)。
在 Elasticsearch 中,字段数据类型是可以定义的,您可以在索引创建期间或使用模板设置这些类型。索引创建完成后,类型便不能更改,您需要先删除目标索引,然后使用之前提供的选项来设置新的固定映射。
- 修复了错误之后,请记得将记录器转换为没那么冗长的模式:
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":NULL
}
}
解决方案 #2 - 没有冲突错误,但重建索引仍然失败
如果在重建索引执行期间,您在 Elasticsearch 日志中发现以下跟踪:
'search_phase_execution_exception', 'No search context found for id [....]')
可能有很多种原因:
- 集群存在一些不稳定问题,并且在重建索引执行过程中,一些数据节点进行了重启或不可用。
如果是这个原因,在运行重建索引之前,请确保集群是稳定的,且所有数据节点都运行良好。 - 如果您是远程执行重建索引操作,并且已知节点之间的网络不可靠:
- 建议选择快照 API(如本文结尾处所述)。
- 我们可以尝试对重建索引 API 执行手动切片,该操作可以将请求过程分割成较小的部分(当我们在同一集群中使用重建索引 API 时,可以使用这个选项)。
如果您的 Elasticsearch 集群存在过度分片、资源利用率高或垃圾收集问题,可能会在滚动搜索查询过程中出现超时。默认的滚动超时值为 5 分钟,因此,您可以尝试将重建索引 API 上的滚动设置为一个更高的值。
POST _reindex?scroll=2h
{
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
症状:Elasticsearch 日志中显示“节点未连接”
我们始终建议在集群稳定且状态为绿色的情况下运行重建索引 API,集群需要足够的容量才能运行搜索和索引操作。
问题
NodeNotConnectedException[[node-name][inet[ip:9300]] Node not connected]; ]
如果您的日志中出现这类错误,表明您的集群存在稳定性和连接问题,而不仅仅是重建索引 API 出现了问题。
但不妨设想一下,已知存在连接问题,但是需要运行重建索引 API,该怎么办。
解决方案
修复连接问题。
但是,假设我们知道有连接问题,可是需要运行重建索引 API,我们可以减少失败的可能性,不过这不是修复操作,并不是在所有情况下都有效。
- 将源索引或目标索引(主索引或副本)的分片移出存在连接问题的节点。使用分配筛选 API 移动分片。
- 您也可以移除目标索引上的副本(仅针对目标索引),这将加快重建索引 API 的执行速度,毕竟重建索引的运行速度越快,出现故障的可能性就越小。
PUT /<dest-index-name>/_settings
{
"index" : {
"number_of_replicas" : 0
}
}
如果这两种操作都无法让您成功执行重建索引 API,表明您需要先修复稳定性问题。
症状:日志中没有错误,但两个索引的文档计数不一致
有时,重建索引 API 已经完成,但是源索引与目标索引中的文档计数不一致。
问题
如果我们尝试在一个目标中从多个源重建索引(即在一个目标中合并多个索引),问题可能源自您为这些文档分配的 _id。
假设我们有 2 个源索引:
- 索引 A,_id:1,信息:“Hello A”
- 索引 B,_id:1,信息:“Hello B”
两个索引在 C 中合并后:
- 索引 C,_id:1,信息:“Hello B”
两个文档的 _id 相同,因此,最后索引的文档将覆盖前一个索引的文档。
解决方案
您可以选择不同的采集管道,也可以在重建索引 API 中使用 Painless。在这篇博文中,我们将使用脚本选项,在请求正文中使用“Painless”。
操作起来非常简单,只需使用原始 _id 并添加源索引名称:
POST _reindex
{
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
},
"script": {
"source": "ctx._id = ctx._id + '-' + ctx._index;"
}
}
还是前面的示例:
- 索引 A,_id:1,信息:“Hello A”
- 索引 B,_id:1,信息:“Hello B”
两个索引在 C 中合并后:
- 索引 C,_id:1-A,信息:“Hello A”
- 索引 C,_id:1-B,信息:“Hello B”
结论
当您需要更改某些字段的格式时,重建索引 API 是一个不错的选择。下面我们将列出一些关键方面,确保重建索引 API 尽可能顺利地运行:
- 为目标索引创建并定义映射(或模板)。
- 调整目标索引,使重建索引 API 尽可能快地索引文档。我们有一个文档页面,其中提供了用于调整和加快索引速度的所有选项。
https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html - 如果源索引的大小为中型或大型,请定义“wait_for_completion=false”设置,以便重建索引 API 结果存储 在 _tasks API 上。
- 将索引分成更小的组,您可以使用查询(范围、术语等)定义不同的组,或者使用切片功能将请求分成较小的部分。
- 运行重建索引 API 时,稳定性是关键因素,参与重建索引 API 的索引需要处于绿色状态(最糟糕的情况是黄色状态),然后确保我们的数据节点中没有很长的 GarbageCollections,并且 CPU 和磁盘使用率为正常值。
从 v7.11 开始,我们发布了一项新功能,让您无需为数据重建索引,这项功能称为“运行时字段”。使用这个 API 可以修复错误,而无需为数据重建索引,因为您可以在索引映射或搜索请求中定义运行时字段。您可以通过这两种方式在采集数据后灵活地更改文档的模式,并生成只作为搜索查询的一部分存在的字段。
运行时字段功能的最佳佐证就是,能够创建一个与映射中已存在的字段同名的运行时字段,运行时字段会覆盖映射字段,只需按照此处提供的步骤操作即可进行测试。
有关运行时字段的更多详细信息,可以参阅我们的文档或入门博文。
当您尝试将数据从一个集群移动到另一个集群时,可以使用快照-恢复 API。借助快照,您可以更快地移动数据,因为集群不需要搜索,然后为数据重建索引。您需要确保两个集群都可以访问相同的快照存储库,详情请参阅快照 API。
我们已经介绍了重建索引的常见问题和常见错误的解决方案。如果您现在仍无法解决问题,请随时与我们联系。我们将竭诚为您提供帮助!您可以通过 Elastic Discuss、Elastic 社区 Slack、咨询、培训和支持团队与我们联系。
分享
- Share on Twitter
在 Twitter 上分享
- Share on LinkedIn
在 LinkedIn 上分享
- Share on Facebook
在 Facebook 上分享
- Share by Email
通过邮件分享
- Print this page
打印