Why the Elasticsearch Platform is the missing piece in your AI stack
.jpg)

 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Enterprise AI has a dirty secret: The model is the easy part. The hard part is everything around it — memory, retrieval, state management, and the connective tissue that turns a chatbot into something people actually rely on at work.
Most teams solve this by bolting together a vector database for embeddings, a document store for context, a cache layer for sessions, and maybe a time-series database for telemetry. That's four systems to operate, four failure modes to debug, four vendor contracts to manage, and four integration seams where data silently gets lost or stale.
Our team at Elastic has now shipped two AI systems that use the Elasticsearch Platform as the sole data backend: ElasticGPT, an internal chatbot with 2,000+ users, 125,000+ chats, and 400,000+ interactions, and AgentEngine, an API-driven autonomous agent framework. The bet we made on our tech stack was the same each time: one engine for memory, retrieval, and state. No Redis. No Pinecone. No Postgres sidecar. Just the Elasticsearch Platform.
The problem: AI memory is harder than AI inference
When the team built ElasticGPT, model selection took about a week. The retrieval architecture took months. When we later built AgentEngine, the same pattern held: The hard problems were all about data infrastructure.
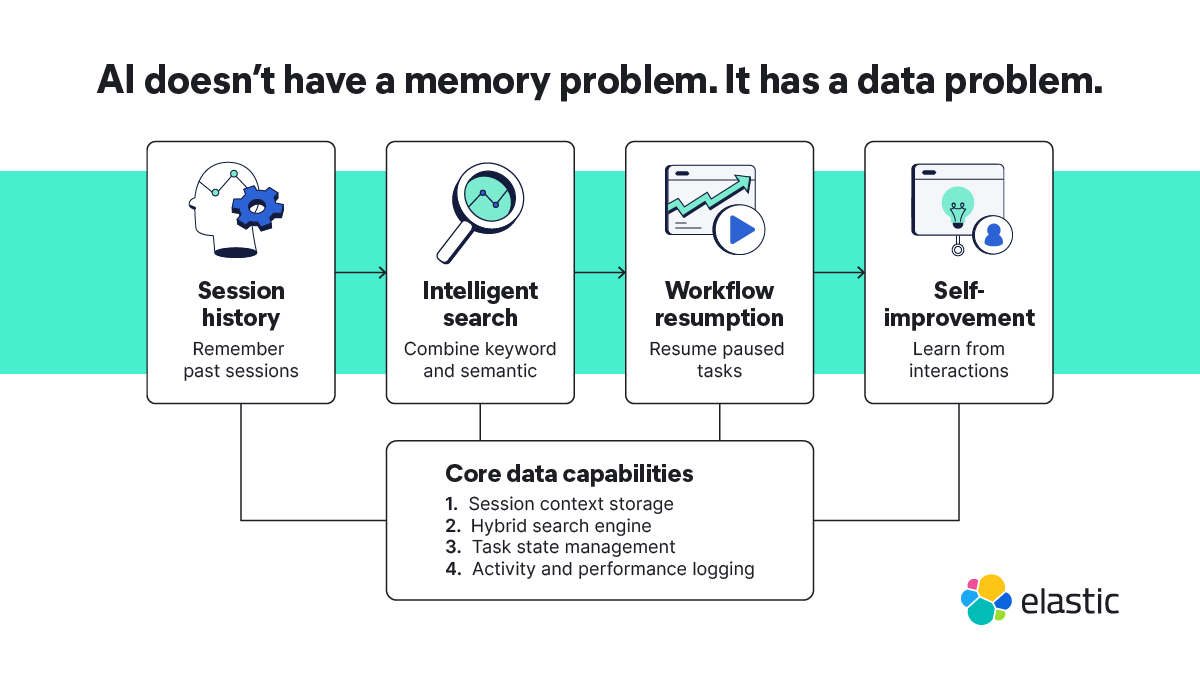
Here's why. A production AI system needs to:
Remember context across sessions: Recall relevant history from weeks ago, not just the last 10 messages.
Search its own knowledge intelligently: Match exact terms like error codes and tool names, surface semantically similar concepts, and merge both result sets without one drowning out the other.
Resume interrupted workflows: Pick up exactly where the user left off after they close their laptop mid-task and return later.
Learn from its own behavior: Track which tool chains worked for specific task types and improve over time.
These aren't model problems; they're data infrastructure problems. And they map directly to capabilities that the Elasticsearch Platform has shipped for years, but just applied to a new use case.
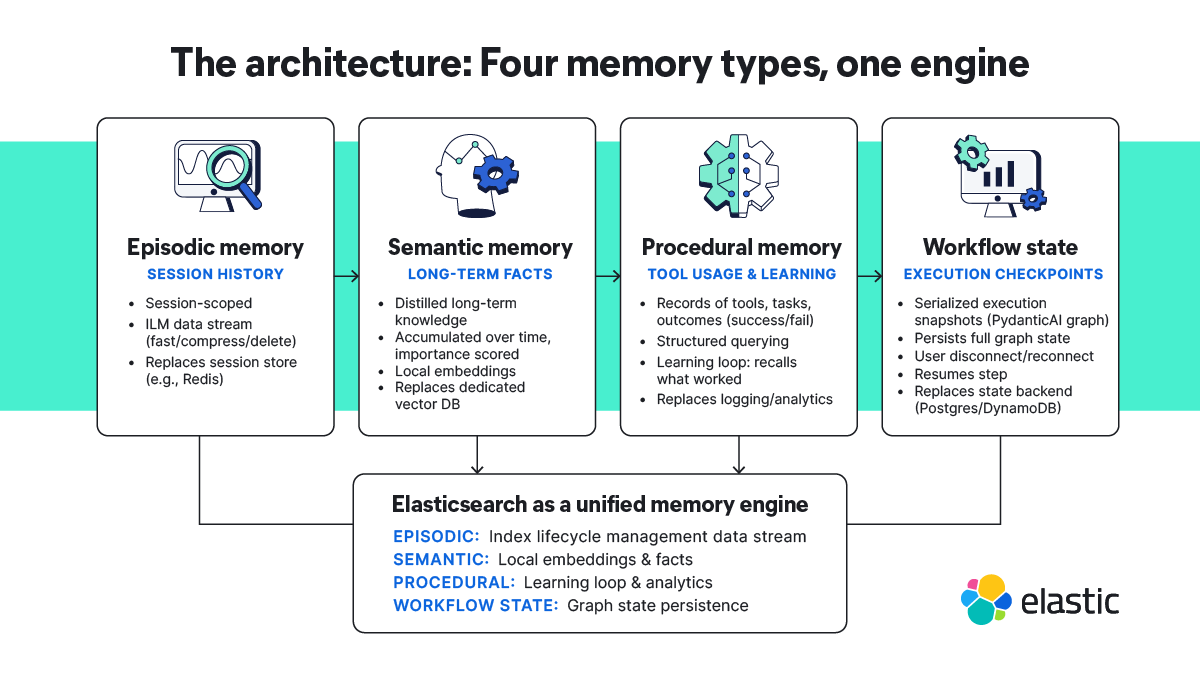
The architecture: 4 memory types, 1 engine
AgentEngine’s backend is built on top of the Elasticsearch Platform with four distinct memory functions. Each one would traditionally require a separate system.
Episodic memory: Session-scoped conversation history stored as a data stream with index lifecycle management (ILM). Recent turns live on fast storage, compress after 30 days, and auto-delete after 90 — no cron jobs and no manual retention scripting. This replaces a session store like Redis.
Semantic memory: Long-term facts extracted and distilled across conversations each scored by importance. The agent accumulates knowledge over time and a background consolidation process merges related facts using local embeddings. This replaces a dedicated vector database.
Procedural memory: Records of which tools the agent used, for what task type, whether it succeeded, and any correction notes. This gives the agent a learning loop; when facing a similar task next time, it recalls what worked. This replaces an analytics or logging system with structured querying.
- Workflow state: Serialized execution snapshots from PydanticAI's graph API. When the agent hits a checkpoint, the full graph state persists to Elasticsearch. Users disconnect and reconnect; the agent resumes from the exact step. This replaces a state backend like Postgres or DynamoDB.
Why one unified platform works
Consolidating your search and AI data into a single platform is a strategic advantage that reduces total cost of ownership (TCO) and accelerates time-to-market.
Eliminating infrastructure overhead
In a traditional setup, preparing company data for AI requires complex, fragile pipelines and separate databases just to translate text into a format AI can understand. A unified platform eliminates this technical debt. It handles the translation automatically — your teams simply input standard text, and the platform natively prepares it for AI. There are no external pipelines to manage and no constant syncing between disconnected systems.
Smarter retrieval, right out of the box
When users or AI agents look for information, the access patterns are inherently mixed. Sometimes you need the precision of an exact keyword match ("Find the Q3 budget report for Project X"), and sometimes you need conceptual understanding ("What are our common data pipeline failures?").
Most of the time, you need both. A unified platform seamlessly combines traditional keyword search with the contextual understanding of modern AI. It intelligently weighs and merges these results behind the scenes, ensuring your AI applications consistently deliver accurate, relevant answers without requiring your engineers to constantly tune the search algorithms manually.
What changes operationally
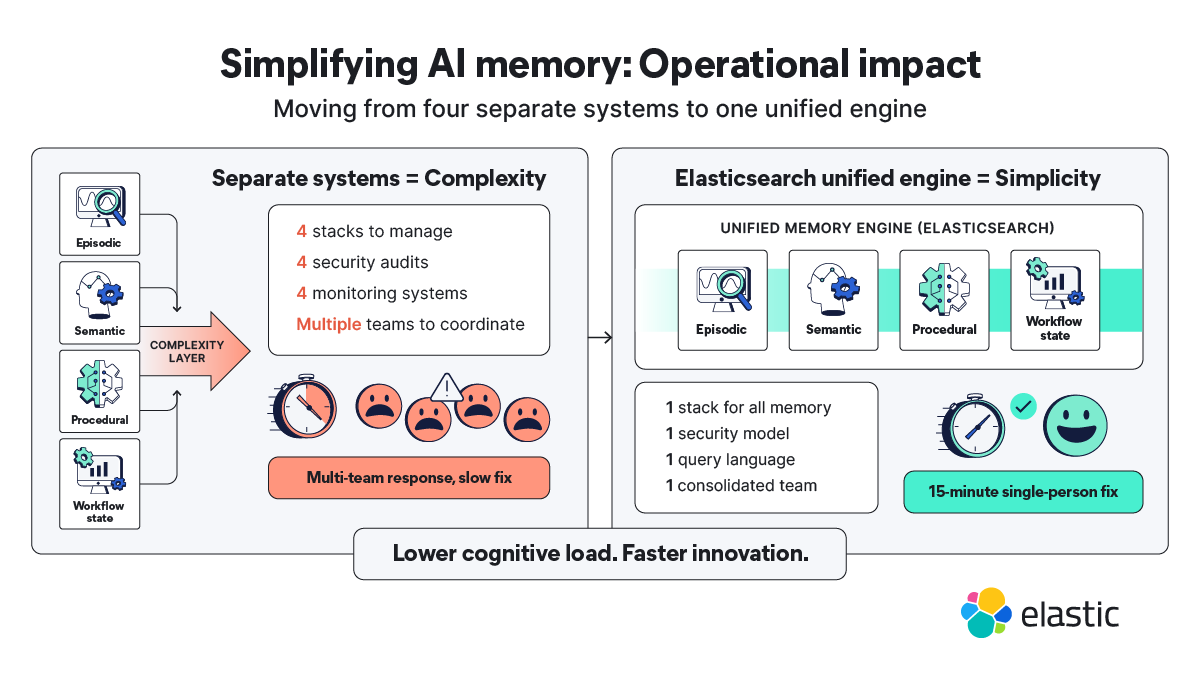
The consolidation argument isn't about saving a few thousand dollars a month on infrastructure, though, that's real. It's about operational surface area.
Every system in your AI stack is a system that needs monitoring, alerting, security review, backup/restore procedures, upgrade cycles, and at least one person who deeply understands it. Four systems means four of all of that, plus the integration layer between them.
When AgentEngine has a memory issue, we look at one system. One set of indices. One query language. One security model. One team that knows how it works. At 3:00 a.m. when something breaks, this is the difference between a 15-minute fix and a multiteam incident.
For context, we manage $1.3 million per year in cloud spend across three cloud service providers. Every system we can eliminate from the stack reduces not just cost but cognitive load on the engineering team.
The hybrid search advantage
Most teams I've talked to who are evaluating vector databases are solving the wrong problem. They're asking "which vector database should we use for embeddings?" when the real question is "do we even need a separate vector database?"
Keyword search misses context (e.g., failing to link "ETL crash" with "pipeline failure") while pure AI search often misses exact critical details like product codes. A unified platform runs both simultaneously. It automatically weighs and surfaces the most relevant, up-to-date information so that your AI always has the right context.
Uninterrupted business continuity
Fragmented systems are fragile; if an external AI pipeline fails, your application breaks. A consolidated platform prevents this with built-in resilience. If the AI model temporarily degrades, the system instantly falls back to standard search. Your applications stay online, and your workflows remain unblocked.
What this means for your AI stack
If your organization already uses the Elasticsearch Platform — and many tech companies do for logging, observability, or product search — you may be sitting on an AI-ready platform without realizing it. The same cluster that handles your application logs can, with the right index design and inference endpoints, serve as the memory backbone for an agentic AI system.
The companies that ship AI fastest won't be the ones with the most sophisticated model pipelines. They'll be the ones with the simplest, most reliable data infrastructure underneath.
See how we’re working to become an AI-first enterprise in our internal playbook.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, and associated marks are trademarks, logos or registered trademarks of elasticsearch B.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print