ElasticとNVIDIAは、ITインフラに負担をかけずにAIアプリをより速く導入できるよう支援します。
ボトルネックを解消し、よりスマートにスケールし、コストを抑制。ElasticとNVIDIAの連携により、GPUアクセラレーションを活用したベクトルデータベースのパワーを活用し、高性能AIを実現できます。

詳しく知る
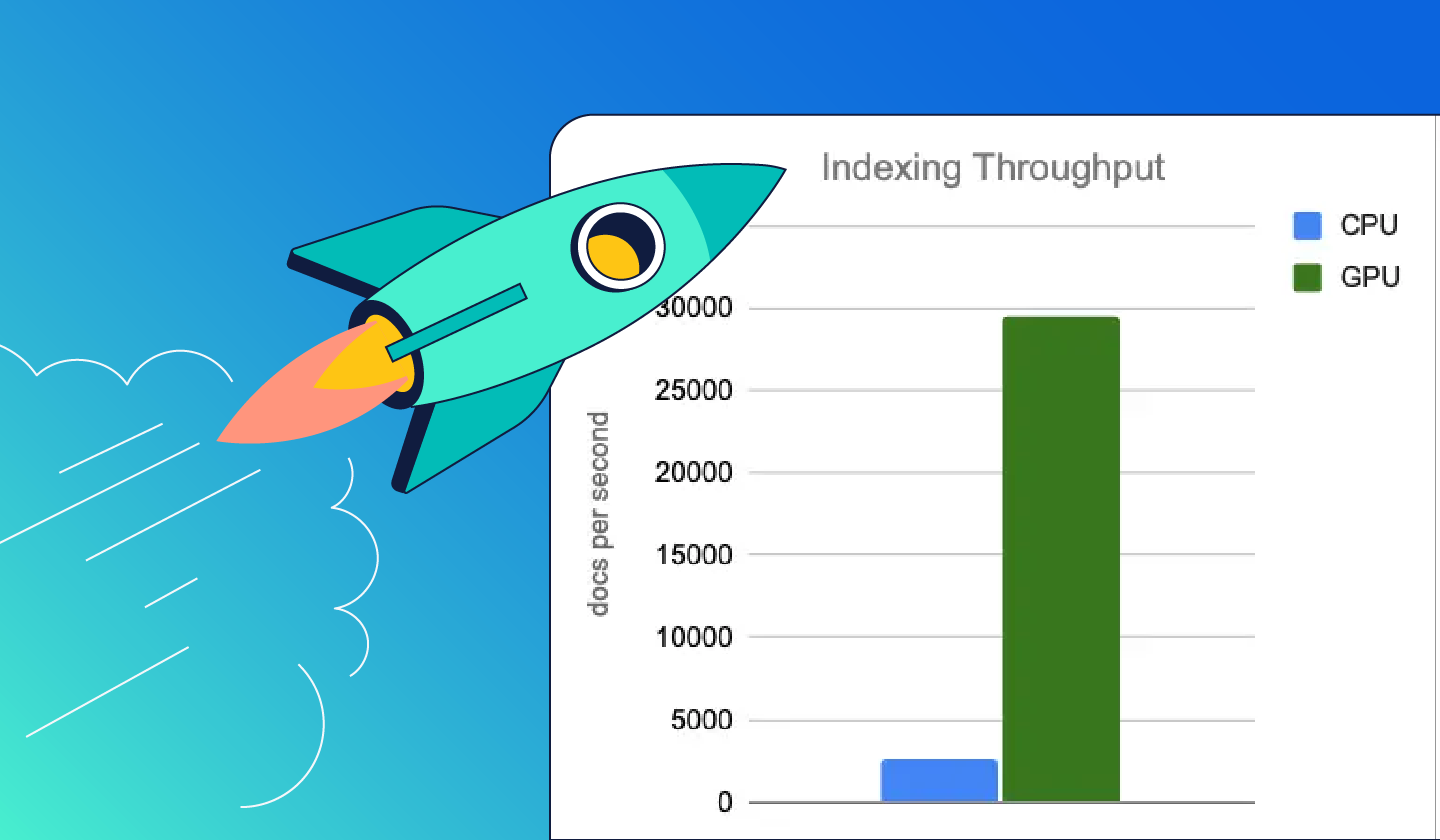

GPUアクセラレーションによるベクトル検索でAIパフォーマンスを最大化
ElasticsearchはNVIDIAと提携し、検索スタックにGPUパワーをもたらします。cuVSライブラリとCAGRAアルゴリズムを活用することで、Elasticsearchは大規模な並列処理を解き放ち、最も要求の厳しいRetrieval-Augmented Generation(RAG)パイプラインやAIアプリケーションに高速かつ超低レイテンシのインデキシングを提供します。
GPUでインデックスを作成し、最大スループットを実現。CPUでの検索でコストパフォーマンスを追求。パフォーマンスとコストの両方を最適化します。
NVIDIA cuVSとElasticsearchベクトルデータベース:組み合わせて、よりよく




エンタープライズ対応
ElasticとNVIDIAの最高の組み合わせをニーズに合わせて最適化


よくあるご質問
ElasticsearchのGPUアクセラレーションによるベクトルインデキシングはオープンソースで利用できますか?
ElasticsearchのGPUアクセラレーションによるベクトルインデキシングはオープンソースで利用できますか?
はい、GPUアクセラレーションによるベクトルインデキシングを実装するコードはオープンソースです(AGPLとELv2のデュアルライセンス下)。ElasticsearchはELv2ライセンスの下でライセンスされ、エンタープライズサブスクリプション枠で利用できるプラグインを介して、GPUアクセラレーションによるベクトルインデキシング機能を公開しています。ElasticsearchのGPUインデックス機能を強化するライブラリのNVIDIA cuVSは、Apache 2.0ライセンスの下でオープンソースとしても利用可能です。
問題が発生した場合や提案がある場合はどうすればよいですか?
問題が発生した場合や提案がある場合はどうすればよいですか?
問題が発生した場合はトラブルシューティングの手順を試してください。それでも問題が解決しない場合は、Elasticsearch GitHubでイシューを作成してください。問題がNVIDIA cuVSとその依存関係に関係している場合はNVIDIA cuVSのGitHubでイシューを開いてください。エンタープライズサブスクリプションをお持ちの場合はElasticカスタマーサポートチャネル経由で当社に連絡して問題を解決してください。提案や機能リクエストには同じチャネルを使用してください。
Elasticsearch データノードに NVIDIA cuVS をインストールして GPU ベクトルインデキシングを有効にするにはどうすればよいですか?
Elasticsearch データノードに NVIDIA cuVS をインストールして GPU ベクトルインデキシングを有効にするにはどうすればよいですか?
NVIDIA cuVSは、データベースユーザーの場合はNVIDIAチャネルからtarball経由で、データサイエンスユーザーの場合はpipまたはcondaパッケージマネージャー経由で、プリコンパイル済みパッケージとしてインストールできます。また、ソースから cuVS をビルドし、バイナリを自分で保守することもできます。詳細についてはNVIDIA cuVSインストールページをご覧ください。GPUにNVIDIA AI Enterprise(NVAIE)サブスクリプションをご利用のユーザーの場合はCVE修正がサポートされ、CVEのサポートが保証されたcuVS tarballが数か月以内にNGCカタログから提供される予定です。詳細についてはNVAIEサポートチームまたはNVIDIAの営業担当者にお問い合わせください。
ベクトルインデキシングは、1台または複数のサーバーにわたる複数のGPUでスケールできますか?
ベクトルインデキシングは、1台または複数のサーバーにわたる複数のGPUでスケールできますか?
はい、Kubernetesのようなコンテナオーケストレーションシステムを使用して、各Elasticsearchプロセスを1つの利用可能なGPUにマッピングできます。1つのElasticsearchプロセスは1つのGPUを専有する必要があります。このように、複数のGPUを使用するスケーリングは、クラスター内のノードをスケーリングすることになります。
ベクトルインデックスのサイズは利用可能なGPUメモリによって制限されますか?
ベクトルインデックスのサイズは利用可能なGPUメモリによって制限されますか?
GPUメモリよりも大きなインデックス(アウトオブコア)をバッチで構築できます。GPUインデックス作成では、CPUベースのインデックス作成で既に存在する制限以外に、新たな制限は発生しません。
ベクトル検索にGPUアクセラレーションは利用可能ですか?
ベクトル検索にGPUアクセラレーションは利用可能ですか?
いいえ、現時点ではHNSWインデックス構築のみがGPUアクセラレーションの対象です。生成されたHNSWグラフはホスト(CPU)メモリにロードされ、ベクトル検索はCPU上で実行されます。この決定の理由は、GPUがバルクベクトル演算において大きな優位性を持つためです。技術とユースケースの進化に伴い、GPUの活用範囲をさらに拡大することを検討していきます。
GPUベクトルインデキシングのパフォーマンスとコストの利点を評価するにはどうすればよいですか?
GPUベクトルインデキシングのパフォーマンスとコストの利点を評価するにはどうすればよいですか?
ElasticのRallyツールを使用して、GPUがインデキシングスループット、強制マージレイテンシ、ベクトル検索の精度とレイテンシ/スループットに与える影響を評価できます。Rallyを使用してGPUでE2Eベクトルインデキシングのベンチマークを実行する手順とベストプラクティスをご覧ください。
どの要素タイプとインデックスタイプがサポートされていますか?
どの要素タイプとインデックスタイプがサポートされていますか?
Elasticsearchはいくつかの異なるインデキシングパラメータをサポートしています。hnsw値とint8_hnsw値の両方がindex_options.typeパラメータでサポートされています。element_typeではfloatのみがサポートされています。現時点では、他のインデックスおよび要素タイプはサポートされていません。