Try out vector search for yourself using this self-paced hands-on learning for Search AI. You can start a free cloud trial or try Elastic on your local machine now.
Earlier this year, Elastic announced the collaboration with NVIDIA to bring GPU acceleration to Elasticsearch, integrating with NVIDIA cuVS—as detailed in a session at NVIDIA GTC and various blogs. This post is an update on the co-engineering effort with the NVIDIA vector search team.
Recap
First, let’s bring you up to speed. Elasticsearch has established itself as a powerful vector database, offering a rich set of features and strong performance for large-scale similarity search. With capabilities such as scalar quantization, Better Binary Quantization (BBQ), SIMD vector operations, and more disk-efficient algorithms like DiskBBQ, it already provides efficient and flexible options for managing vector workloads.
By integrating NVIDIA cuVS as a callable module for vector search tasks, we aim to deliver significant gains in vector indexing performance and efficiency to better support large-scale vector workloads.
The challenge
One of the toughest challenges in building a high-performance vector database is constructing the vector index - the HNSW graph. Index building quickly becomes dominated by millions or even billions of arithmetic operations as every vector is compared against many others. In addition, index lifecycle operations, such as compaction and merges, can further increase the overall compute overhead of indexing. As data volumes and associated vector embeddings grow exponentially, accelerated computing GPUs, built for massive parallelism and high-throughput math, are ideally positioned to handle these workloads.
Enter the Elasticsearch-GPU Plugin
NVIDIA cuVS is an open-source CUDA-X library for GPU-accelerated vector search and data clustering that enables fast index building and embedding retrieval for AI and recommendation workloads.
Elasticsearch uses cuVS through cuvs-java, an open-source library developed by the community and maintained by NVIDIA. The cuvs-java library is lightweight and builds on the cuVS C API using Panama Foreign Function to expose cuVS features in an idiomatic Java way, while remaining modern and performant.
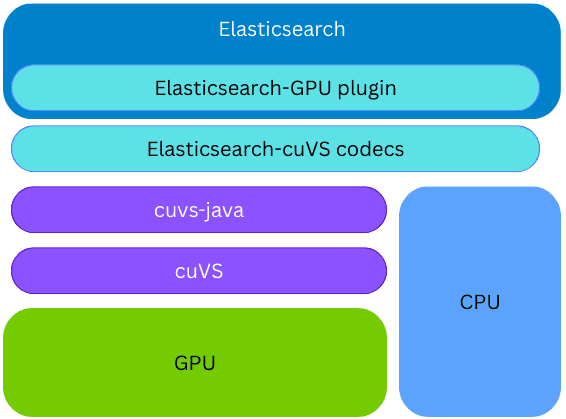
The cuvs-java library is integrated into a new Elasticsearch plugin; therefore, vector indexing on the GPU can occur on the same Elasticsearch node and process, without the need to provision any external code or hardware. During index building, if the cuVS library is installed and a GPU is present and configured, Elasticsearch will use the GPU to accelerate the vector indexing process. The vectors are given to the GPU, which constructs a CAGRA graph. This graph is then converted to the HNSW format, making it immediately available for vector search on the CPU. The final format of the built graph is the same as what would be built on the CPU; this allows Elasticsearch to leverage GPUs for high-throughput vector indexing when the underlying hardware supports it, while freeing CPU power for other tasks (concurrent search, data processing, etc.).
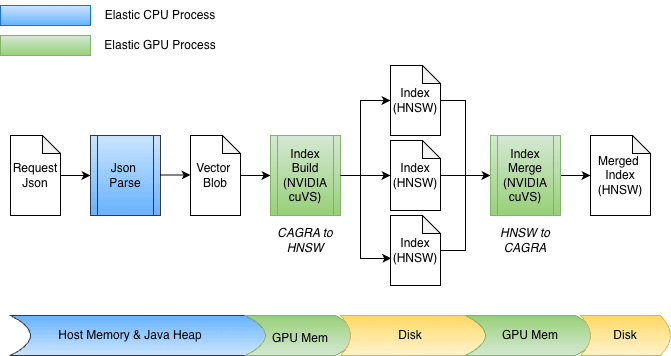
Index build acceleration
As part of integrating GPU acceleration into Elasticsearch, several enhancements were made to cuvs-java, focusing on efficient data input/output and function invocation. A key enhancement is the use of cuVSMatrix to transparently model vectors, whether they reside on the Java heap, off-heap, or in GPU memory. This enables data to move efficiently between memory and the GPU, avoiding unnecessary copies of potentially billions of vectors.
Thanks to this underlying zero-copy abstraction, both transferring to GPU memory and retrieving the graph can occur directly. During indexing, vectors are first buffered in memory on the Java heap, then sent to the GPU to construct the CAGRA graph. The graph is subsequently retrieved from the GPU, converted into HNSW format, and persisted to disk.
At merge time, the vectors are already stored on disk, bypassing the Java heap entirely. Index files are memory-mapped, and data is transferred directly into GPU memory. The design also easily accommodates different bit-widths, such as float32 or int8, and naturally extends to other quantization schemes.
Drumroll…so, how does it perform?
Before we get into the numbers, a bit of context is helpful. Segment merging in Elasticsearch typically runs automatically in the background during indexing, which makes it difficult to benchmark in isolation. To obtain reproducible results, we used force-merge to explicitly trigger segment merging in a controlled experiment. Since force-merge performs the same underlying merge operations as background merging, its performance serves as a useful indicator of expected improvements, even though the exact gains may differ in real-world indexing workloads.
Now, let’s see the numbers.
Our initial benchmark results are very promising. We ran the benchmark on an AWS g6.4xlarge instance with locally attached NVMe storage. A single node of Elasticsearch was configured to use the default, optimal number of indexing threads (8 - one for each physical core), and to disable merge throttling (which is less applicable with fast NVMe disks).
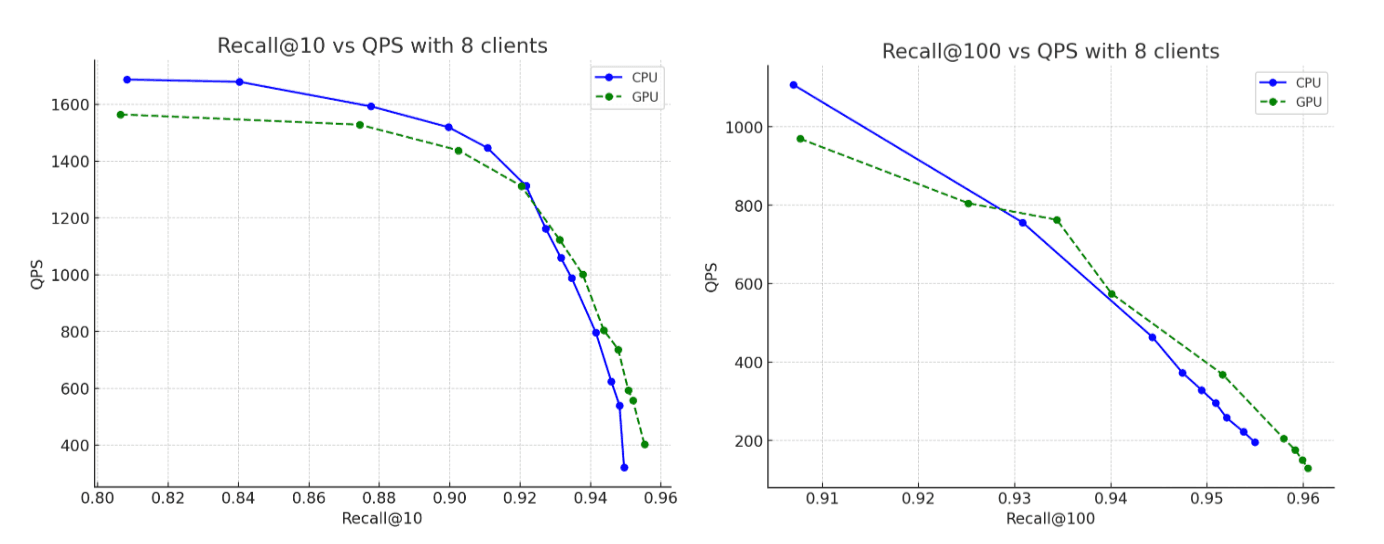
For the dataset, we used 2.6 million vectors with 1,536 dimensions from the OpenAI Rally vector track, encoded as base64 strings, and indexed as float32 hnsw. In all scenarios, the constructed graphs achieve recall levels of up to 95%. Here’s what we found:
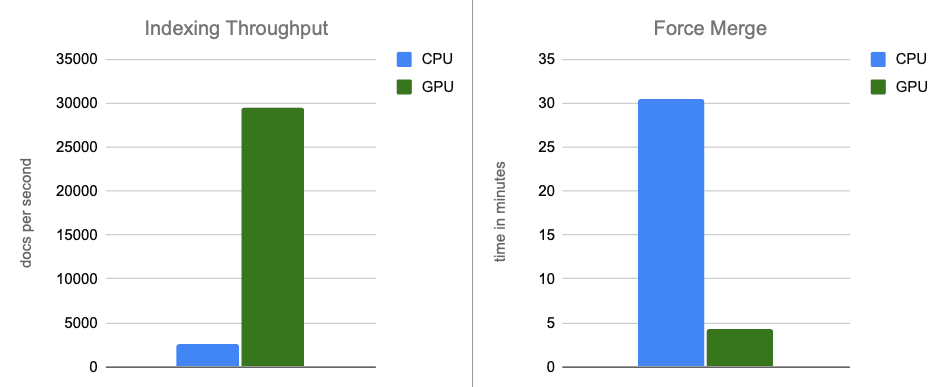
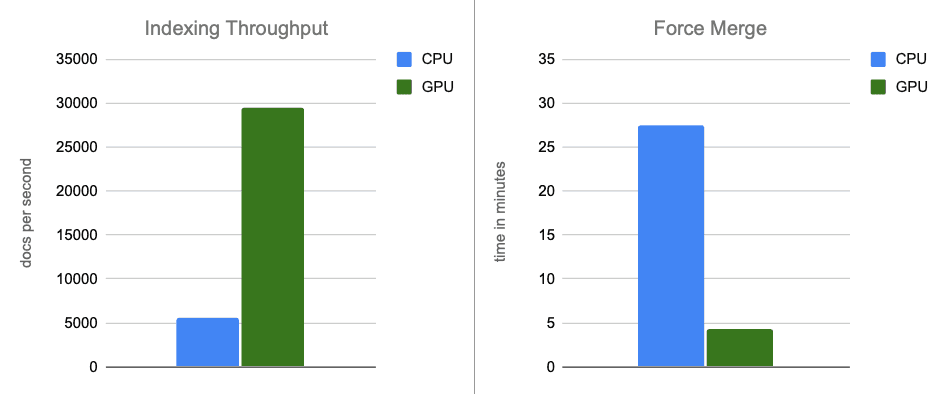
- Indexing Throughput: By moving graph construction to the GPU during in-memory buffer flushes, we increase throughput by ~12x.
- Force-merge: After indexing completes, the GPU continues to accelerate segment merging, speeding up the force-merge phase by ~7x.
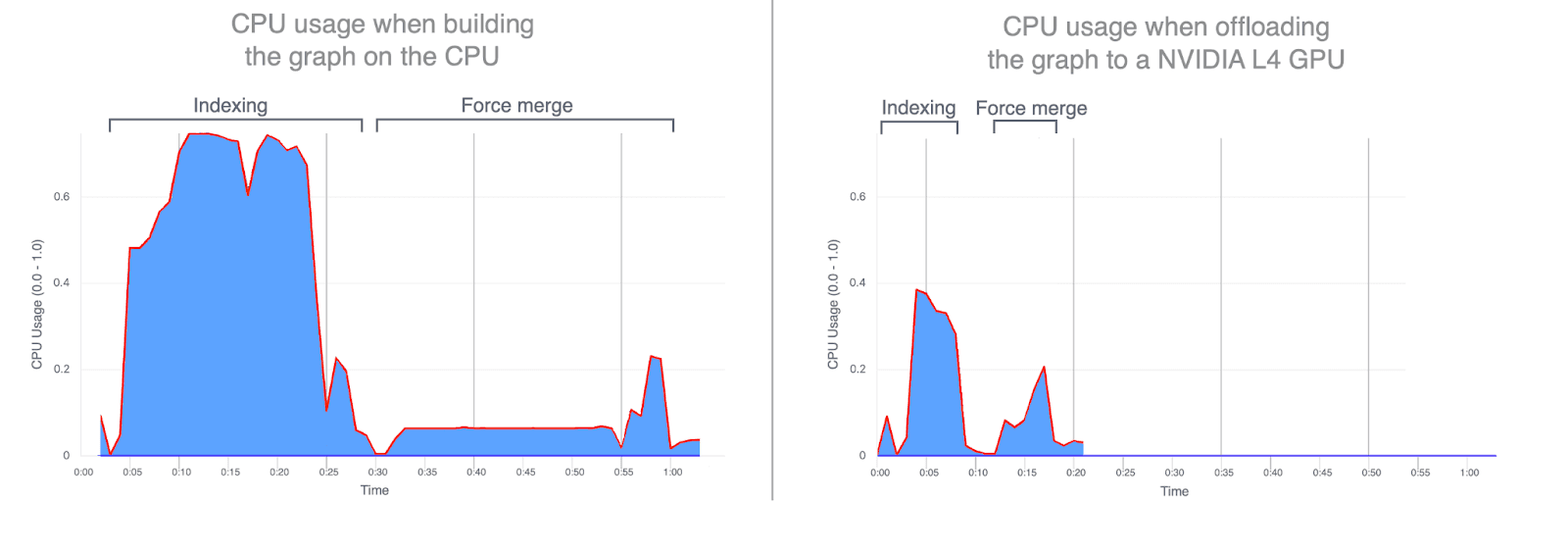
- CPU usage: Offloading graph construction to the GPU significantly reduces both average and peak CPU utilization. The graphs below illustrate CPU usage during indexing and merging, highlighting how much lower it is when these operations run on the GPU. Lower CPU utilization during GPU indexing frees up CPU cycles that can be redirected to improve search performance.
- Recall: Accuracy remains effectively the same between CPU and GPU runs, with the GPU-built graph reaching marginally higher recall.
Comparing along another dimension: Price
The earlier comparison intentionally used identical hardware, with the only difference being whether the GPU was used during indexing. That setup is useful for isolating raw compute effects, but we can also look at the comparison from a cost perspective.
At roughly the same hourly price as the GPU-accelerated configuration, one can provision a CPU-only setup with approximately twice the comparable CPU and memory resources: 32 vCPUs (AMD EPYC) and 64 GB of RAM, allowing to double the number of indexing threads to 16.
To keep the comparison fair and consistent, we ran this CPU-only experiment on an AWS g6.8xlarge instance, with the GPU explicitly disabled. This allowed us to hold all other hardware characteristics constant while evaluating the cost–performance trade-off of GPU acceleration versus CPU-only indexing.
The more powerful CPU instance does show improved performance compared to the benchmarks in the above section, as you would expect. However, when we compare this more powerful CPU instance against the original GPU-accelerated results, the GPU still delivers substantial performance gains: ~5x improvement in indexing throughput, and ~6x in force merge, all while building graphs that achieve recall levels of up to 95%.
Conclusion
In end-to-end scenarios, GPU acceleration with NVIDIA cuVS delivers nearly a 12x improvement in indexing throughput and a 7x decrease in force-merge latency, with significantly lower CPU utilization. This shows that vector indexing and merge workloads benefit significantly from GPU acceleration. On a cost-adjusted comparison, GPU acceleration continues to yield substantial performance gains, with approximately 5x higher indexing throughput and 6x faster force-merge operations.
GPU-accelerated vector indexing is currently planned for Tech Preview in Elasticsearch 9.3, which is scheduled to be released early in 2026.
Stay tuned for more.
Related Content

July 16, 2026
A picture is worth 1.5x the words: What we learned benchmarking product search embeddings
We benchmarked two embedding models on 5,000 real products and found that combining image and text beats either alone by up to 50%. Here's the data and the model that won.

July 13, 2026
The disk that never woke up: what actually decided our Qdrant vector search benchmark rematch
On the same hardware, Elasticsearch and Qdrant land in the same range at 56 QPS. The io_uring disk scorer and memory claims turned out to be the two things that mattered least.

July 10, 2026
How BBQ shrinks Jina v5 embeddings by 29x without losing recall in Elasticsearch
A hands-on test comparing BBQ and float32 vector indices in Elasticsearch, measuring memory, disk and recall@10 across five languages.

July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.

July 2, 2026
A simdvec deep-dive: How Elasticsearch uses neural-net and video-codec CPU instructions for vector search
Four ways Elasticsearch's vector search engine reuses neural-network, video-codec and cryptography CPU instructions for up to 6x speedups; with the math, the failed attempts and the benchmarks.