Jina AIモデル
検索パイプラインの各段階における最先端のモデル
検索専用に設計されたJinaモデルは、サイズの5倍のモデルよりも精度と速度を発揮します。多言語、マルチモーダル(テキスト、画像、音声、動画)で、Elasticsearchでネイティブになりました。

Jina AIモデルの紹介
当社のフロンティアモデルは、高品質のエンタープライズ検索およびRetrieval-Augmented Generation(RAG)システムの検索基盤を形成します。



コンパクトな設計、正確な結果
1つのAPIで生データから高精度な結果まで。

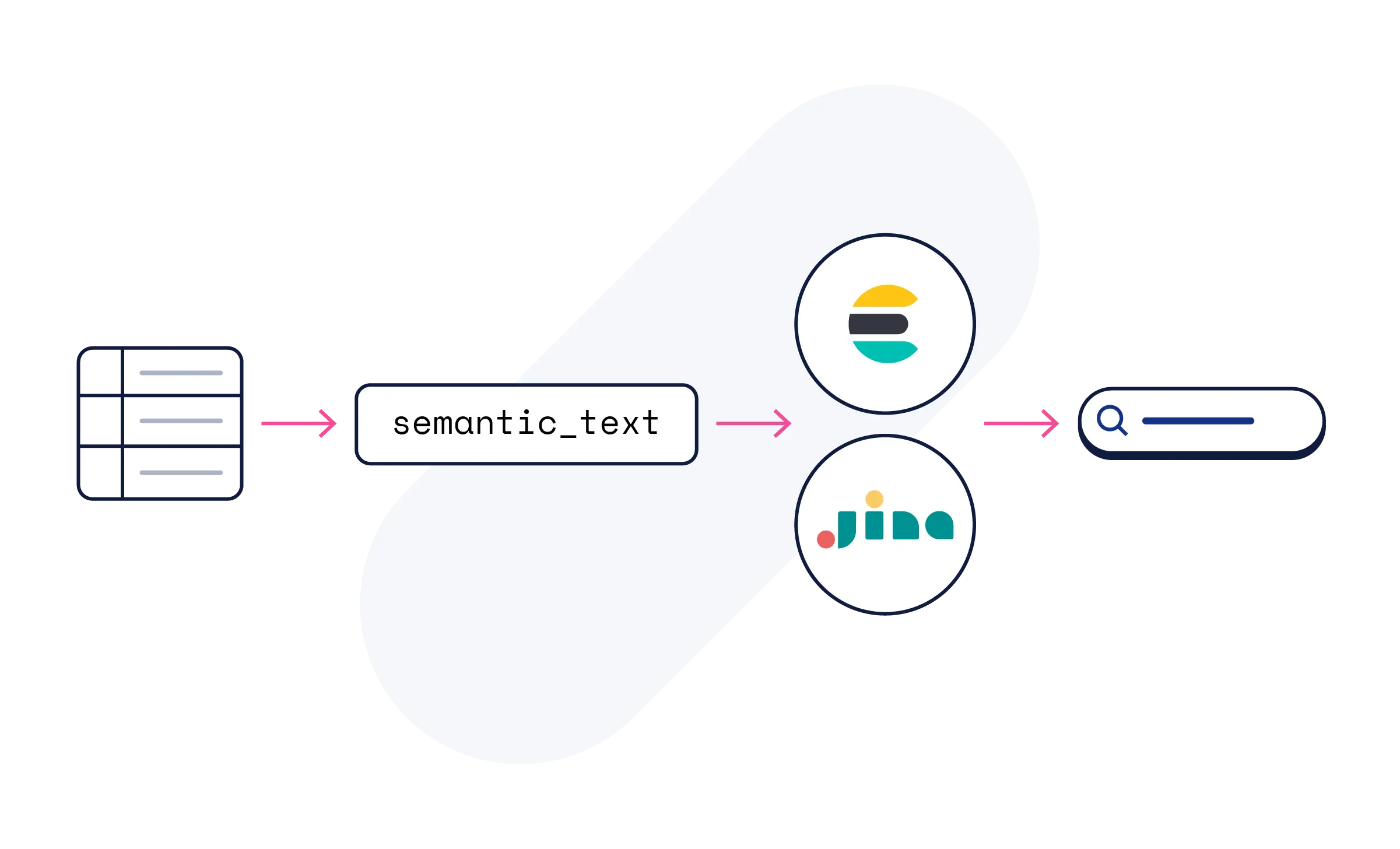
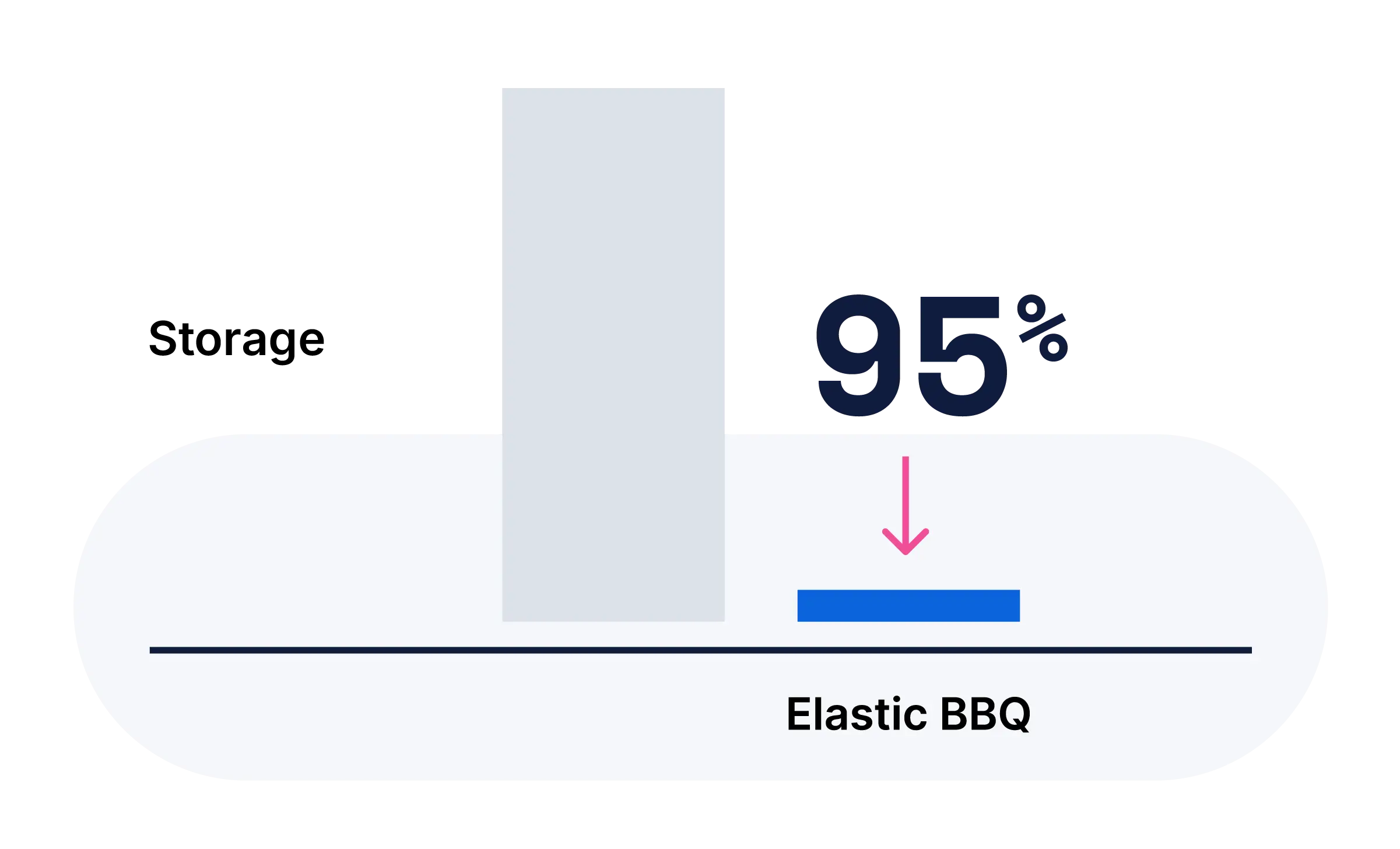
構築するあらゆる場所でJinaモデルを活用
フルマネージドからセルフホスティングまで、Jinaのモデルはデータの保存場所に合わせて提供されます。最適なアクセスパスをお選びください。



Elasticの調査




オープンソースコミュニティに参加
Jinaのモデルはオープンウェイトで、Hugging Faceで無料で入手でき、毎月数百万回ダウンロードされています。コードベースはGitHubで公開されています。コミュニティは開発者に直接アクセスできます。




よくあるご質問
Jina検索モデルとは何ですか?
Jina検索モデルとは何ですか?
Jinaモデルは検索用のオープンソースのフロンティアAIモデルです。ベクトル用の埋め込みモデル、精度を高めるためのリランカー、URLやドキュメントからコンテンツを抽出して構造化するためのリーダーなどが含まれています。
これらを使用するにはAIや機械学習の専門知識が必要ですか?
これらを使用するにはAIや機械学習の専門知識が必要ですか?
いいえ。Elasticsearchのsemantic_textフィールドを使用するとAIによる処理が自動的に行われます。Jinaのモデルを使用すると、コンテンツをセマンティックに検索できます。モデルの設定やMLの専門知識は必要ありません。
利用を開始するにはどうすればよいですか?
利用を開始するにはどうすればよいですか?
Jinaのモデルは、Elastic Cloud上のElastic Inference Serviceでご利用いただけます。semantic_textから始めるか、コード例、APIリファレンス、チュートリアルのモデルサブページをご覧ください。
現在入手可能なJinaモデルはどれですか?
現在入手可能なJinaモデルはどれですか?
最新のv5-text(nano/small)は、32Kのコンテキスト、マトリョーシカ次元、最新のアーキテクチャを備えており、Jina-embeddings-v3、Reranker v2およびv3とともに、すべてElastic Inference Serviceで利用できます。
いくつの言語がサポートされていますか?
いくつの言語がサポートされていますか?
Jina-embeddings-v5-textは30以上の言語をサポートしており、ある言語でクエリを実行すると、翻訳パイプラインを必要とせずに、別の言語で書かれた関連コンテンツが見つかります。
ELSERとの関係は?
ELSERとの関係は?
ELSERは英語のセマンティック検索をカバーします。Jinaは30言語以上の多言語をカバーし、高い精度を誇ります。どちらもElasticsearchのハイブリッド検索フレームワークで動作します。
これは別の製品ですか?
これは別の製品ですか?
いいえ。Elastic Inference ServiceのJina検索モデルは、すべてのElastic Cloudユーザーが従量課金制で利用できます。個別のライセンス、サブスクリプション、APIキーは必要ありません。
これはElasticのベクトルデータベースページとどのように関係していますか?
これはElasticのベクトルデータベースページとどのように関係していますか?
ベクトルデータベースのページでは、ベクトルがどのように大規模に格納され、検索されるかを説明します。このページでは、ベクトルを生成してランク付けするAIモデルについて説明します。ストレージ、コンピュート、アプリケーションの3つを合わせてご覧ください。