Elastic App SearchでSpring Bootを使用する


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
この記事では、何もない状態から、WebサイトのコンテンツをクロールしたElastic App Searchにクエリを発行するSpring Bootアプリケーションを完全に実行するところまで説明します。クラスターを起動し、アプリケーションを段階的に構成します。
クラスターの起動
例に従うための最も簡単な方法は、サンプルGitHubリポジトリを複製することです。terraformを実行し、すぐに起動して稼働させることができます。
git clone https://github.com/spinscale/spring-boot-app-searchサンプルを起動し、実行するためには、terraformプロバイダーの設定の説明に従い、Elastic CloudでAPIキーを作成する必要があります。
それが完了したら、実行し
terraform init
terraform validate
terraform apply少し待つと、処理が開始します。数分後に、次のように、Elastic Cloud UIでインスタンスが起動し、実行されるのを確認できます。
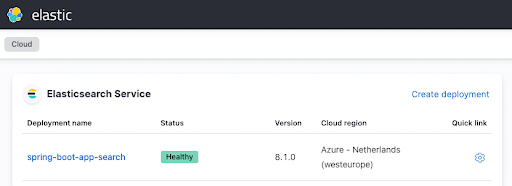
Spring Bootアプリケーションを構成する
先に進む前に、Javaアプリケーションを構築して実行できることを確認します。必要なのは、Java 17がインストールされていることだけです。確認できたら、次のコマンドを実行します。
./gradlew clean checkこれにより、すべての依存関係がダウンロードされます。そして、テストが実行され、失敗します。まだどのデータもApp Searchインスタンスにインデックス化していないため、これは想定通りの動作です。
ただ、その前に、構成を変更し、一部のデータにインデックスを作成する必要があります。まず、src/main/resources/application.propertiesファイル(以下のスニペットは変更が必要なパラメーターのみを示しています)を編集して、構成を変更します。
appsearch.url=https://dc3ff02216a54511ae43293497c31b20.ent-search.westeurope.azure.elastic-cloud.com
appsearch.engine=web-crawler-search-engine
appsearch.key=search-untdq4d62zdka9zq4mkre4vv
feign.client.config.appsearch.defaultRequestHeaders.Authorization=Bearer search-untdq4d62zdka9zq4mkre4vvKibanaにログインするためにパスワードを入力する必要がない場合は、Elastic Cloud UI経由でKibanaインスタンスにログインし、Enterprise Search > App Searchに移動します。
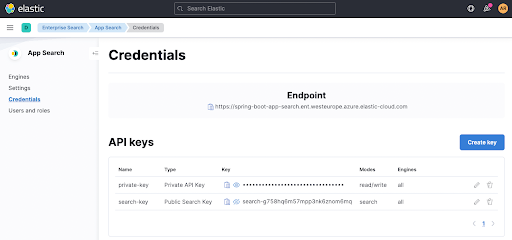
App Search内のCredentialsページからappsearch.keyおよびfeign...検索パラメーターを抽出できます。同じことが、上部に表示されるEndpointにも当てはまります。
ここで、./gradlew clean checkを実行すると、正しいApp Searchエンドポイントが
一致しますが、まだデータにインデックスを作成していないため、テストは引き続き失敗します。では、ここでそれをやってみましょう。
クローラーの構成
クローラーを設定する前に、ドキュメントのコンテナーを作成する必要があります。これはengineと呼ばれます。では、1つ作成してみましょう。エンジンにweb-crawler-search-engineという名前を付け、application.confファイルと一致するようにします。
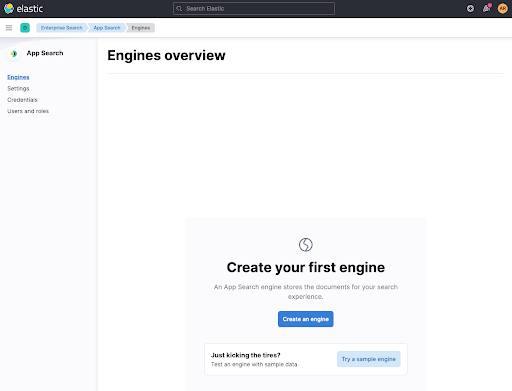
その後に、Use The Crawlerをクリックして、クローラーを構成します。
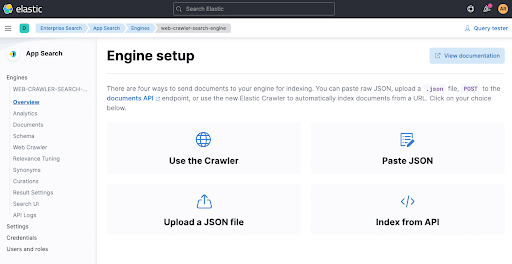
ドメインを追加します。ここでは、独自のドメインを追加できます。私は、誰の領域にも入りたくないので、自分の個人的なブログのspinscale.deを使いました。
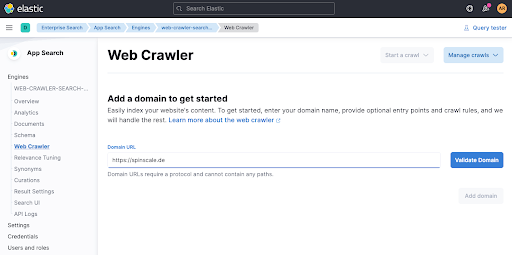
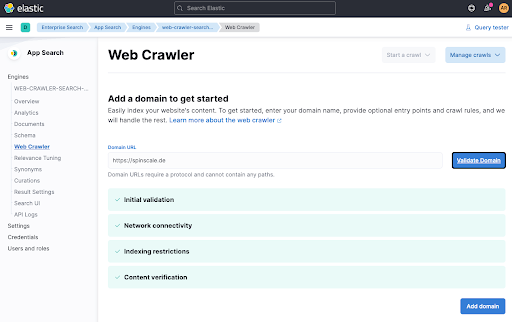
Validate Domainをクリックすると、数回のクリックが実行されます。そして、ドメインがエンジンに追加されます。
最後の手順では、クロールを手動でトリガーし、今すぐデータにインデックスが作成されるようにします。Start a crawlをクリックします。
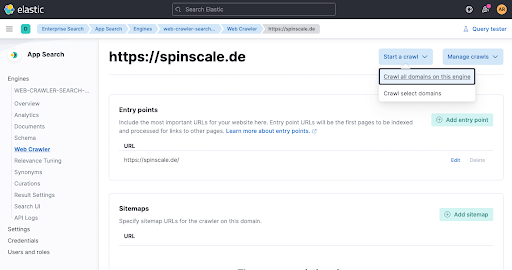
数分間待ち、エンジンの概要で、ドキュメントが追加されたかどうかを確認します。
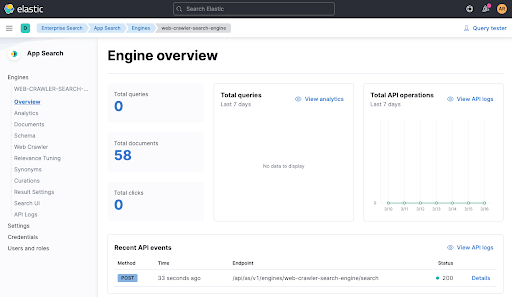
エンジンでデータがインデックス化されたため、テストを再実行します。./gradlew checkを使用して、成功したかどうかを確認します。今度は成功しているはずです。また、エンジンの概要では、テストでの最近のAPI呼び出しを確認することもできます。
アプリを起動する前に、テストコードを簡単に確認してみましょう。
@SpringBootTest(classes = SpringBootAppSearchApplication.class, webEnvironment = SpringBootTest.WebEnvironment.NONE)
class AppSearchClientTests {
@Autowired
private AppSearchClient appSearchClient;
@Test
public void testFeignAppSearchClient() {
final QueryResponse queryResponse = appSearchClient.search(Query.of("seccomp"));
assertThat(queryResponse.getResults()).hasSize(4);
assertThat(queryResponse.getResults().stream().map(QueryResponse.Result::getTitle))
.contains("Using seccomp - Making your applications more secure",
"Presentations",
"Elasticsearch - Securing a search engine while maintaining usability",
"Posts"
);
assertThat(queryResponse.getResults().stream().map(QueryResponse.Result::getUrl))
.contains("https://spinscale.de/posts/2020-10-27-seccomp-making-applications-more-secure.html",
"https://spinscale.de/presentations.html",
"https://spinscale.de/posts/2020-04-07-elasticsearch-securing-a-search-engine-while-maintaining-usability.html",
"https://spinscale.de/posts/"
);
}
}このテストでは、ポートにバインドせずに、Springアプリケーションを起動します。そして、AppSearchClientクラスを自動的にインジェクトし、seccompを検索するテストを実行します。
アプリケーションの起動
起動してテストを実行し、アプリケーションが起動しているかどうかを確認します。
./gradlew bootRun数件のログメッセージが表示されます。最も重要なのは、次のように、アプリケーションが起動したというメッセージです。
2022-03-16 15:43:01.573 INFO 21247 --- [ restartedMain] d.s.s.SpringBootAppSearchApplication : Started SpringBootAppSearchApplication in 1.114 seconds (JVM running for 1.291)ブラウザーでアプリを開き、アプリを見ることができるようになりましたが、ここでは先にJavaコードを確認したいと思います。
検索クライアント専用のインターフェースの定義
Spring Boot内でApp Searchエンドポイントに対してクエリを実行するには、実装する必要があるのはインターフェースだけです。Feignを使用するからです。JSONシリアル化やHTTP接続の作成については気にする必要がありません。POJOでのみ作業できます。これはアプリ検索クライアントの定義です。
@FeignClient(name = "appsearch", url="${appsearch.url}")
public interface AppSearchClient {
@GetMapping("/api/as/v1/engines/${appsearch.engine}/search")
QueryResponse search(@RequestBody Query query);
}クライアントは、urlおよびengineでapplication.properties定義を使用するため、API呼び出しの部分としては何も指定する必要がありません。また、このクライアントは、application.propertiesファイルで定義されたヘッダーを使用します。このように、アプリケーションコードでは、URL、エンジン名、カスタム認証ヘッダーが指定されていません。
追加の実装が必要なクラスは、リクエスト本文をモデリングするためのQueryと、リクエストに対する応答をモデリングするQueryResponseだけです。通常は、JSONにはもっと多くの情報が含まれていますが、ここでは、応答で絶対に必要なフィールドのみをモデリングします。その他のデータが必要なときにはいつでも、データをQueryResponseクラスに追加できます。
ここでは、クエリクラスはqueryフィールドのみです。
public class Query {
private final String query;
public Query(String query) {
this.query = query;
}
public String getQuery() {
return query;
}
public static Query of(String query) {
return new Query(query);
}
}そして、最後に、アプリケーション内から検索をいくつか実行します。
サーバー側クエリとレンダリング
サンプルアプリケーションは、App Searchインスタンスに対してクエリを実行し、Spring Bootアプリケーション内でそのインスタンスを統合する3つのモデルを実装します。1つ目のモデルは、検索用語をSpring Bootアプリに送信します。そして、Spring BootアプリがそのクエリをApp Searchに送信し、thymeleafを使用して結果をレンダリングします。thymeleafはSpring Bootの標準レンダリング依存関係です。これはコントローラーです。
@Controller
@RequestMapping(path = "/")
public class MainController {
private final AppSearchClient appSearchClient;
public MainController(AppSearchClient appSearchClient) {
this.appSearchClient = appSearchClient;
}
@GetMapping("/")
public String main(@RequestParam(value = "q", required = false) String q,
Model model) {
if (q != null && q.trim().isBlank() == false) {
model.addAttribute("q", q);
final QueryResponse response = appSearchClient.search(Query.of(q));
model.addAttribute("results", response.getResults());
}
return "main";
}
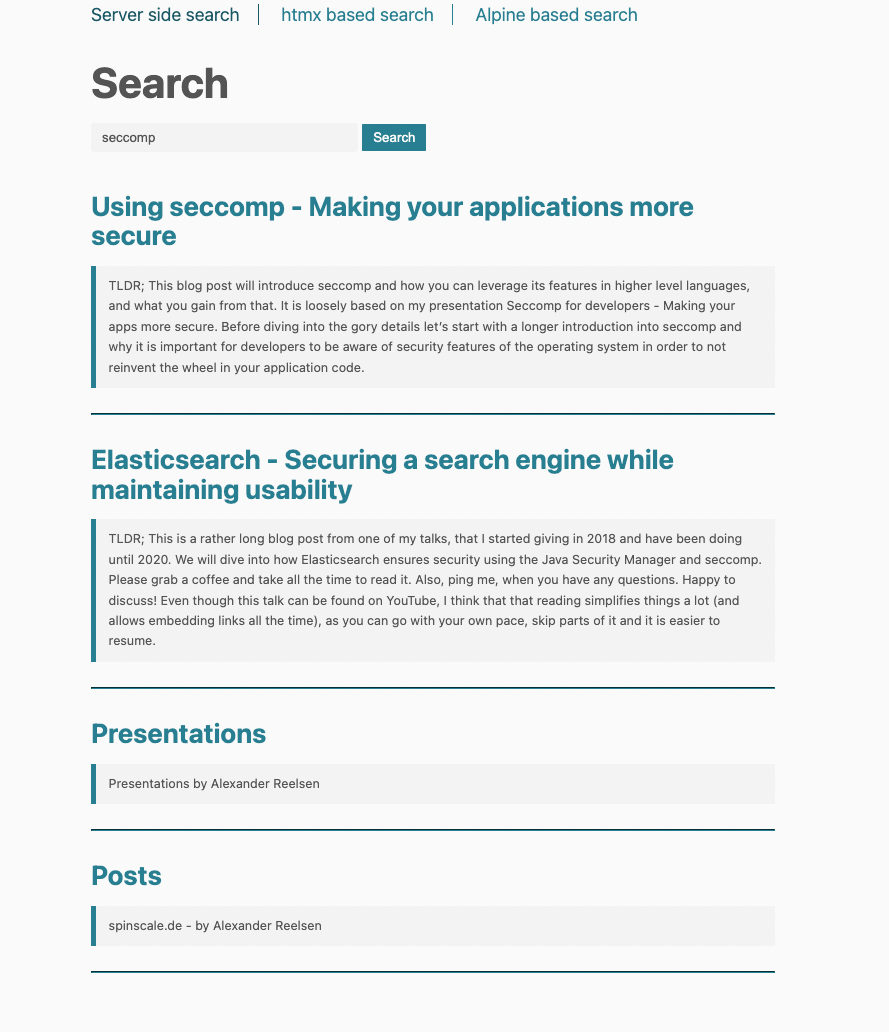
}main()メソッドを見ると、qパラメーターのチェックがあります。このパラメーターが存在する場合は、クエリがApp Searchに送信され、modelが結果でエンリッチされます。そして、main.html thymeleafテンプレートがレンダリングされます。次のように表示されます。
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org"
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content">
<div>
<form action="/" method="get">
<input autocomplete="off" placeholder="Enter search terms..."
type="text" name="q" th:value="${q}" style="width:20em" >
<input type="submit" value="Search" />
</form>
</div>
<div th:if="${results != null && !results.empty}">
<div th:each="result : ${results}">
<h4><a th:href="${result.url}" th:text="${result.title}"></a></h4>
<blockquote style="font-size: 0.7em" th:text="${result.description}"></blockquote>
<hr>
</div>
</div>
</div>
</body>
</html>テンプレートはresults変数をチェックします。この変数が設定されている場合は、そのリストを繰り返します。すべての結果に対して、同じテンプレートがレンダリングされます。次のように表示されます。
htmxを使用してページを動的に更新する
上部のナビゲーションに表示されているように、3つの選択肢から検索方法を変更できます。2番目のhtmxベースの検索をクリックすると、実行モデルが少し変わります。
ページ全体を再読み込みするのではなく、結果の一部のみがサーバーによって返される内容で置換されます。この方法の利点は、JavaScriptを記述せずに実行できることです。これは、優れたhtmxライブラリによって可能になっています。記述を引用 > htmxでは、属性を使用して、直接HTMLでAJAX、CSS Transitions、WebSockets、サーバーによって送信されたイベントにアクセスできるため、ハイパーテキストのシンプルさと高機能を利用して最新のユーザーインターフェースを構築できます。
この例では、htmxの小さいサブセットのみを使用します。まず、2つのエンドポイント定義を見てみましょう。HTMLをレンダリングするエンドポイントと、必要なHTMLスニペットを返し、ページの一部のみを更新するエンドポイントです。
htmxでは、属性を使用して、直接HTMLでAJAX、CSS Transitions、WebSockets、サーバーによって送信されたイベントにアクセスできるため、ハイパーテキストのシンプルさと高機能を利用して最新のユーザーインターフェースを構築できます。
1つ目のエンドポイントはhtmx-mainテンプレートをレンダリングします。2つ目のエンドポイントは結果をレンダリングします。htmx-mainテンプレートは次のようになります。
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org"
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content">
<div>
<form action="/search" method="get">
<input type="search"
autocomplete="off"
id="searchbox"
name="q" placeholder="Begin Typing To Search Articles..."
hx-post="/htmx-search"
hx-trigger="keyup changed delay:500ms, search"
hx-target="#search-results"
hx-indicator=".htmx-indicator"
style="width:20em">
<span class="htmx-indicator" style="padding-left: 1em;color:red">Searching... </span>
</form>
</div>
<div id="search-results">
</div>
</div>
</body>
</html><input> HTML要素のhx-属性で魔法が起こります。つまり、次の処理が実行されます。
- 500ミリ秒間入力操作がなかった場合は、HTTPリクエストのみがトリガーされます。
- そして、HTTP POSTリクエストが/htmx-searchに送信されます。
- 待っている間に、.htmx-indicator要素が表示されます。
- 応答は、ID #search-resultsの要素にレンダリングされます。
キーリスナーに関するすべてのロジック、応答を待機するための要素の表示、AJAXリクエストの送信に必要な膨大な量のJavaScriptを考えてみてください。
もう一つの大きな利点は、任意のサーバー側レンダリングソリューションを使用して、返されるHTMLを作成できるということです。つまり、何らかのクライアント側テンプレート言語を実装せずに、thymeleafエコシステムを維持できるということです。これにより、結果を繰り返すだけで済むため、htmx-search-resultsテンプレートが非常にシンプルになります。
<div th:each="result : ${results}">
<h4><a th:href="${result.url}" th:text="${result.title}"></a></h4>
<blockquote style="font-size: 0.7em" th:text="${result.description}"></blockquote>
<hr>
</div>最初の例との違いの1つは、この検索のURLは変更されないことです。このため、URLをブックマークに追加することはできません。htmxでは履歴サポートがありますが、正しく行うには、もう少し慎重な実装が必要なので、この例では割愛しました。
ブラウザーを使用してApp Searchに対して検索を実行する
では、最後の例に進みます。これにはSpring Bootサーバー側がまったく関与しないため、大きく異なります。すべての処理がブラウザーで実行されます。これはAlpine.jsを使用して実行されます。サーバー側エンドポイントは次のようにシンプルになります。
@GetMapping("/alpine")
public String alpine() {
return "alpine-js";
}alpine-js.htmlテンプレートにはもう少し説明が必要ですが、まずは見てみましょう。
<!DOCTYPE html>
<html
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content" x-data="{ q: '', response: null }">
<div>
<form @submit.prevent="">
<input type="search" autocomplete="off" placeholder="Begin Typing To Search Articles..." style="width:20em"
x-model="q"
@keyup="client.search(q).then(resultList => response = resultList)">
</form>
</div>
<template x-if="response != null && response.info.meta != null && response.info.meta.request_id != null">
<template x-for="result in response.results">
<template x-if="result.data != null && result.data.title != null && result.data.url != null && result.data.meta_description != null ">
<div>
<h4><a class="track-click" :data-request-id="response.info.meta.request_id" :data-document-id="result.data.id.raw" :data-query="q" :href="result.data.url.raw" x-text="result.data.title.raw"></a></h4>
<blockquote style="font-size: 0.7em" x-text="result.data.meta_description.raw"></blockquote>
<hr>
</div>
</template>
</template>
</template>
<script th:inline="javascript">
var client = window.ElasticAppSearch.createClient({
searchKey: [[${@environment.getProperty('appsearch.key')}]],
endpointBase: [[${@environment.getProperty('appsearch.url')}]],
engineName: [[${@environment.getProperty('appsearch.engine')}]]
});
document.addEventListener("click", function(e) {
const el = e.target;
if (!el.classList.contains("track-click")) return;
client.click({
query: el.getAttribute("data-query"),
documentId: el.getAttribute("data-document-id"),
requestId: el.getAttribute("data-request-id")
});
});
</script>
</div>
</body>
</html>1番の大きな違いは、application.propertiesファイルで構成されたプロパティを使用して、ElasticAppSearchクライアントを初期化するために実際にJavaScriptを使用する点です。クライアントが初期化されると、HTML属性でクライアントを使用できます。
このコードは使用される2つの変数を初期化します。
<div layout:fragment="content" x-data="{ q: '', response: null }">q変数には、入力フォームのクエリが格納されます。応答には、検索からの応答が格納されます。次に興味深い部分は、フォーム定義です。
<form @submit.prevent="">
<input type="search" autocomplete="off" placeholder="Search Articles..."
x-model="q"
@keyup="client.search(q).then(resultList => response = resultList)">
</form><input x-model="q"...>変数を使用すると、q変数が入力に関連付けられ、ユーザーが入力するたびに更新されます。また、「keyup」のイベントもあり、client.search()を使用して検索を実行し、出力をresponse変数に割り当てます。このため、クライアント検索が返されると、応答変数が空になることはなくなります。最後に、@submit.prevent=""を使用して、フォームが送信されないことを保証します。
次はすべての
<div>
<h4><a class="track-click"
:data-request-id="response.info.meta.request_id"
:data-document-id="result.data.id.raw"
:data-query="q"
:href="result.data.url.raw"
x-text="result.data.title.raw">
</a></h4>
<blockquote style="font-size: 0.7em"
x-text="result.data.meta_description.raw"></blockquote>
<hr>
</div>このレンダリングは、クリックされたリンクを追跡する機能が追加されているという点で、2つのサーバー側レンダリング実装とは少し異なります。テンプレートを実装する際の重要な部分は、リンクとリンクのテキストを設定する:hrefとx-textプロパティです。もう一つの:dataパラメーターは、リンクを追跡するためのものです。
クリックの追跡
では、なぜリンクのクリックを追跡したいのでしょうか。答えはシンプルです。ユーザーが検索結果をクリックしたかどうかを測定することで、検索結果の質の程度を把握できる方法の1つだからです。このため、このHTMLスニペットには追加のJavaScriptがいくつか含まれています。まず、これがKibanaでどのようになるのかを見てみましょう。
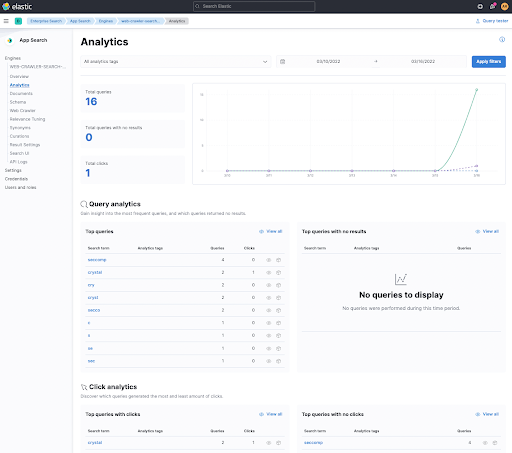
一番下にClick analyticsが表示されます。これは、クリックされた最初のリンクでcrystalを検索した後に、クリックを追跡しました。その用語をクリックすることで、どのドキュメントがクリックされたのかがわかり、基本的にユーザーのクリックの痕跡を追跡できます。
では、これはこの小さいアプリでどのように実装されているのでしょうか。特定のリンクに対してclick JavaScriptリスナーを使用します。これはJavaScriptスニペットです。
document.addEventListener("click", function(e) {
const el = e.target;
if (!el.classList.contains("track-click")) return;
client.click({
query: el.getAttribute("data-query"),
documentId: el.getAttribute("data-document-id"),
requestId: el.getAttribute("data-request-id")
});
});クリックされたリンクがtrack-clickクラスの場合、ElasticAppSearchクライアントを使用して、クリックイベントを送信します。このイベントには、元のクエリ用語のほか、documentIdとrequestIdが含まれています。これは検索応答の一部であり、上記のテンプレートの要素にレンダリングされました。
また、ユーザーがリンクをクリックしたときに、その情報を提供することで、この機能をサーバー側レンダリングに追加することもできます。このため、これはブラウザーに対してまったく排他的ではありません。ここでは、簡単にするため、実装については省略します。
まとめ
開発者の視点によるElastic App Search入門と、これをアプリケーションに統合するさまざまな方法をお楽しみいただけたでしょうか。ぜひ、GitHubリポジトリを確認し、サンプルを試してください。
Elastic Cloudプロバイダーではterraformを使用して、すぐにElastic Cloudを導入し実行できます。
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷