Measuring ‘Mean Time to Knowledge’ (MTTK)
Real-time insight into infrastructure operations accelerates knowledge and understanding of the real cause of an incident.
Complete Control and Easier Management
Fewer Incidents, More Uptime
Every minute counts. Monitoring tools provide an end-to-end view to help deliver incident-free experience for clients.
Visibility Drives Productivity
Cerner is a company at the intersection of two main industries, healthcare and information technology. It designs open and interoperable solutions, and provides a broad range of hosting services to enable organizations in today’s challenging health care landscape. Recognized for innovation, Cerner offers solutions and services for health care organizations of every size. Together with its clients, Cerner is committed to creating a future where the health care system works to improve the well-being of individuals and communities.
CERNER’S JOURNEY WITH ELASTIC
Cerner: Powering the Search for Faster Mean Time to Knowledge (MTTK)
Cerner’s health information and electronic health record technologies connect people, information, and systems at more than 27,000 contracted provider facilities (e.g. hospitals and medical clinics) around the world. And every day, more than 662,000 physicians and two million non-physicians rely on Cerner applications such as the patient portal, electronic health records, physician mobile app, etc. Monitoring the health of these applications’ network connections is mission-critical.
As a health care company, any disruption time is extremely impactful. Every second counts. Just like turning on the lights, our clients expect our applications to always be available so that they can focus on patients instead of technology. That means getting to root cause knowledge and remediation as quickly as possible.
Going beyond hypothesis
Jim Avazpour, Director of Cerner’s Global Operations Center reporting to Asby, and his 60+ person team are responsible for end-to-end infrastructure monitoring – from below the operating system through all the infrastructure layers. Since Avazpour joined Cerner in 2013, he’s been taking steps to improve data collection and analysis, with the goal of creating proactive – and ultimately, predictive – infrastructure monitoring.
Avazpour and his team were experiencing rampant alerts and the familiar ‘needle in a haystack’ scenario made it nearly impossible for a human to effectively investigate every issue efficiently.
To approach near real-time resolution times, Avazpour adopted a fresh take on the Mean Time to Resolution (MTTR) metric: Mean Time to Knowledge, which is based on how quickly you can piece together sharable insight and find the root cause of incidents.
Having a hypothesis is good if you’re solving for something in the future. But if you’re trying to proactively stop an incident from happening, a hypothesis is wasted time not solving the problem. You need data now.
Cerner needed to increase visibility into data and drive faster knowledge, faster resolution. It was time to go beyond the traditional enterprise approach and make a move to open source technologies and processes. When seeking out solutions, scale was a challenge; it was difficult to find a solution that provided the ingestion performance needed in a scalable manner.
While the Elastic Stack offered a cost-effective solution to achieve performance at scale, it was the combination of an active open source community and an authentic relationship that sealed the deal. With a strong affinity for open source software, Avazpour and his team plugged into the Elastic meetup and technical community and connected with some of Elastic’s customers. They already had confidence in the products when their Elastic Sales Director reached out. Compared to many salespeople Avazpour meets, the Sales Director wasn’t selling “the next big shiny thing”, but rather made introductions to other Elastic employees, who all showed a genuine interest in listening to his needs and facilitating a solution that would be best for Cerner. Serving as a partner created genuine trust.
As Avazpour explained, “Every time I have a question or reach out, Elastic immediately finds the right person to do anything we need. They’re my ally in our internal goals and there is tremendous value in that kind of relationship.”
An open source approach to proactive monitoring
Today, the team uses the Elastic Stack together with OpenNMS, an open source networking monitoring solution, to proactively monitor their infrastructure.
We needed a solution with powerful analytics that was fast, flexible, scalable, cost effective and resilient. While there were other ways to tackle the problem, the elegance and cost-benefit of open source and the Elastic solution was inspiring.
Elasticsearch handles billions of syslogs and events sent to the monitoring platform from over 8,000 network devices connected to Cerner systems. Cerner’s huge footprint currently generates 3TB of monitoring data, which is anticipated to grow by a factor of eleven over the next 12 months. In the absence of dedicated in-house data analyst and data scientist resources, the team relies on Elasticsearch to sort, categorize and group alerts in real-time to increase infrastructure health visibility.
Making the leap from alerts to insight
Previously, when a client’s system was down or slow, the Immediate Response Center (IRC) paged all on-call engineers to start investigating and join an incident call to share their findings; but they’d frequently find themselves in the dreaded position of having nothing to report. The reactive calls resulted in hours of investigation time. The team wanted to find a better way.
The solution was to use the Elastic Stack to index and analyze events and tease out the alerts that needed immediate attention. This includes two data feeds: one that displays on the 24x7x365 surveillance team’s consoles and the other that goes to the Elastic Stack for high resolution visibility and machine learning analytics. Utilizing the Elastic machine learning feature’s models, they’re able to take advantage of the higher resolution data to look for patterns and anomalies.
- Data Feed 1 (“DF1”) generates alerts that adhere to the industry standard threshold (e.g., above 80% for three or four consecutive five-minute cycles, generate an alert.)
- Data Feed 2 (“DF2”) which breaks the industry rules for reducing noise, actually generates an alert for every violation. Because of the massive volume of these alerts, these alerts cannot be handled by humans and must be sent to the Elastic Stack for near real-time analysis, visualization, alerting and machine learning tasks.
Displayed in near real-time with Kibana, these alerts enable on-call engineers to marry infrastructure data (DF1 and DF2) with application data to quickly pinpoint what started the problem, then hand it over to the 24x7 surveillance team to take immediate action to resolve it. Individual threshold violations that wouldn’t have registered before are now easy to investigate thanks to higher resolution on data and alerts.
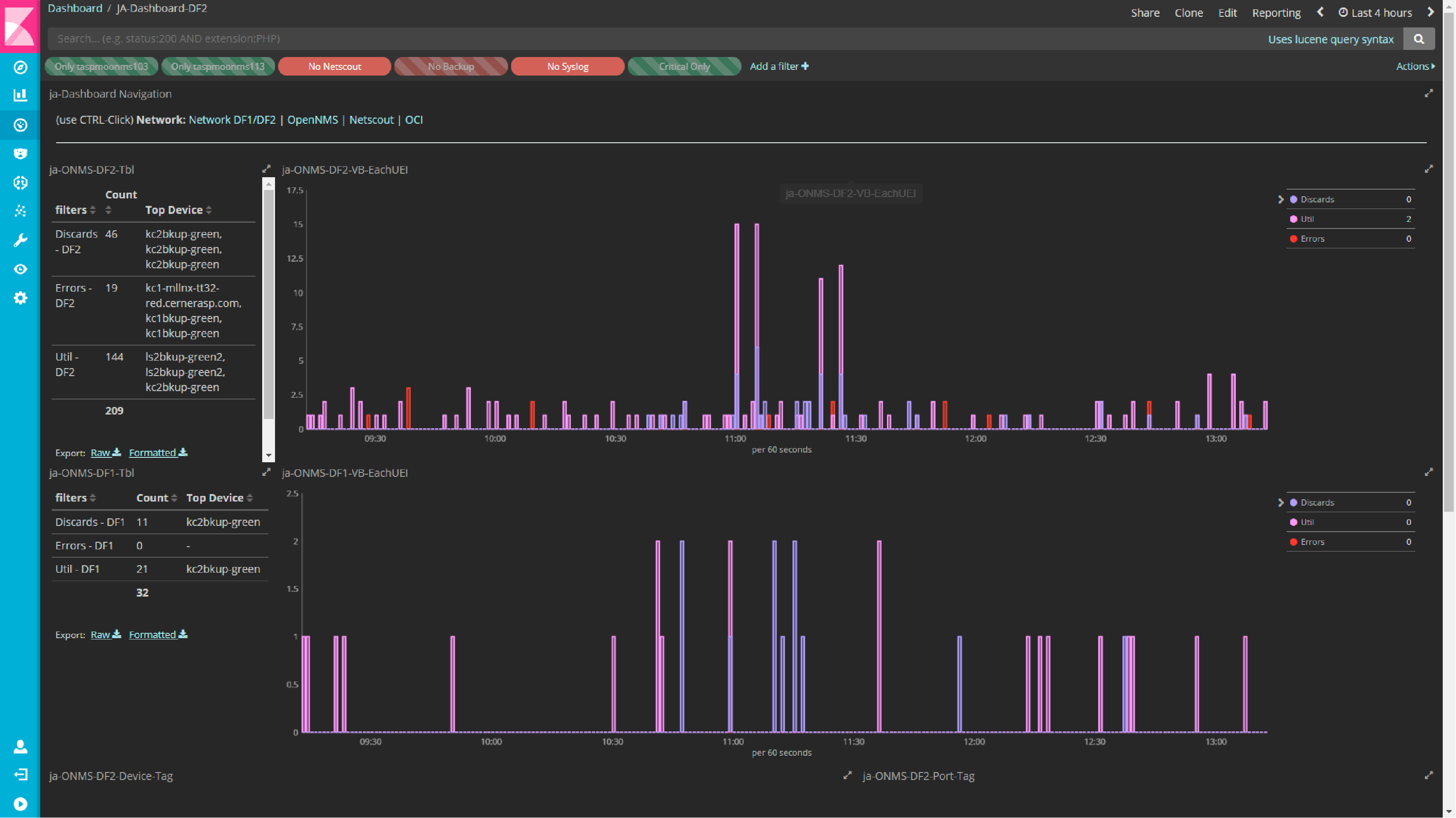
Dashboards built on Kibana eliminate the noise of excess alerts (above graph), offering a single pane of glass into the data and transforming what would otherwise be a sea of network alerts (600-700 every hour) into meaningful insight.
Insight by infrastructure layer and by client
Most importantly, the open source solutions enable Cerner to correlate and visualize alerts in real-time by service lane in the infrastructure layer (e.g. network, storage, virtualization, LDAP/DNS, hardware), as well as by client.
Using proprietary in-house technology and the Elastic Stack, the team built a tool that tags each event with the client mnemonic and other crucial information. This client tagging reveals what’s happening in the infrastructure topology, and when, for every device and client at the port level. Currently in production with network and storage searching, Cerner is exploring plans to extend the client tagging to search for anomalies in all service lanes.
Cerner also plans to take advantage of predictive analytics and use a machine learning feature that plugs into the Elastic Stack to look for patterns and anomalies. “Being able to sort and visualize data with the Elastic Stack has been a game changer for us,” said Avazpour. “Putting intelligence on top of the problem is so important and useful in providing the optimal client experience.”
Impacting 'mean time to knowledge'
Before using the Elastic Stack, searching, analyzing and visualizing in a secured manner across all service lanes’ events and alerts was cumbersome and time consuming. Now if there is an incident, the team can zoom in on exactly where the issue is. This brings MTTK down from hours to minutes – even to near real-time.
Armed with this insight, engineers can accelerate fixes and close the loop with executives and internal teams, such as the application monitoring team, who answer to Cerner’s external clients. In many cases, the team is able to prevent an incident from happening in the first place.
According to Asby, the goal is to drive towards zero incidents that impact clients. In fact, Cerner’s reporting model includes “incident free time” as part of client SLAs. “The closer we get to zero, the better we’ll be,” said Asby. “The Elastic Stack provides us that end-to-end view to help us get on top of incidents and eventually deliver an incident-free experience for clients.”
In order to ensure the accuracy of their monitoring data used for analysis, predictions and alerting, Cerner decided to use the Elastic Stack’s Metricbeat on their collection nodes. Metricbeat, a lightweight way to send system and service statistics, provided the necessary monitoring metrics to guarantee that their data collection platform was not dropping data and maintaining their 100% uptime goal.
While resource constraints would have limited how quickly projects get implemented in a conventional manner, the open source and distributed model of the Elastic Stack enables Cerner to rapidly scale out and meet their IT roadmap requirements with existing engineering resources. “Nowadays your most valuable asset is your data. If you don’t have tools like the Elastic Stack, then data will be collected but you won’t know what to do with it,” said Avazpour.
I feel so comfortable using the Elastic Stack and I’m so used to it, that I can’t imagine going without it.
And once you start solving one problem, it’s easy to continually solve new ones. Based on the project’s success to date, more teams across application and infrastructure support want in.
Infrastructure growing, data increasing, incidents decreasing
In combination with Cerner’s overall technology and process improvements, the Elastic Stack, along with OpenNMS, has contributed to a dramatic increase in productivity – thanks to a decrease in the number of incidents, even in the face of ever increasing data volumes. Engineers are now empowered to tackle infrastructure issues, while others are freed up to focus on more strategic initiatives. “We’ve traveled light years in a very short amount of time,” said Asby.
While conventional success measurement may focus on ROI and total cost of ownership (TCO), the Cerner team has a fresh take on client satisfaction. According to Avazpour: “In IT operations, every minute counts. The less incidents causing downtime or slow performance, the happier our clients are.”
Cerner's Clusters
- Number of Clusters9
- Number of NodesMaster and Data: 64
Total: 74 - Total Number of DocumentsCurrent 3,881,415,067 Anticipated: 11x this amount over the next year
- Total Data Size3TB Anticipated: 11x this amount over the next year
- Replicas1
- Hosting EnvironmentOn premises Oracle Enterprise Linux 6.6
- Daily Ingest Rate~400 million docs Anticipated: 4.5 billion docs
- Hardware StatsProLiant BL460c Gen9, 128 GB Ram, 48 cores, 6TB tier 1 SAN storage