Modelos de Jina AI
Modelos de última generación para cada etapa del pipeline
Los modelos Jina de recuperación ofrecen precisión y velocidad que superan a los modelos más grandes. Plurilingües, multimodales (texto, imágenes, audio y video), ahora nativos en Elasticsearch.

Conoce los modelos de Jina AI
Nuestros modelos de frontera forman la base de búsqueda para sistemas empresariales de alta calidad de búsqueda y Retrieval-Augmented Generation (RAG).



De diseño compacto y resultados precisos
Convierte los datos sin procesar en resultados de alta precisión en una sola API.

Utiliza los modelos de Jina para cualquier desarrollo
Tanto los modelos completamente administrados como los autohospedados de Jina se adaptan donde residen tus datos. Elige la ruta de acceso que más te convenga.



Nuestra investigación




Únete a nuestra comunidad de open source
Los modelos de Jina son de código abierto y están disponibles gratuitamente en Hugging Face, con millones de descargas mensuales. El código fuente es público en GitHub. La comunidad tiene acceso directo a nuestros desarrolladores.

Accede a nuestros modelos de incrustaciones, reclasificadores y pequeños modelos de lenguaje para una búsqueda refinada.



Preguntas frecuentes
¿Qué son los modelos de búsqueda de Jina?
¿Qué son los modelos de búsqueda de Jina?
Los modelos de Jina son modelos de IA de vanguardia open source para la recuperación. Incluyen modelos de incrustación para vectores, clasificadores para precisión y lectores para extraer y estructurar contenido de URL y documentos.
¿Necesito conocimientos de IA o machine learning para usarlos?
¿Necesito conocimientos de IA o machine learning para usarlos?
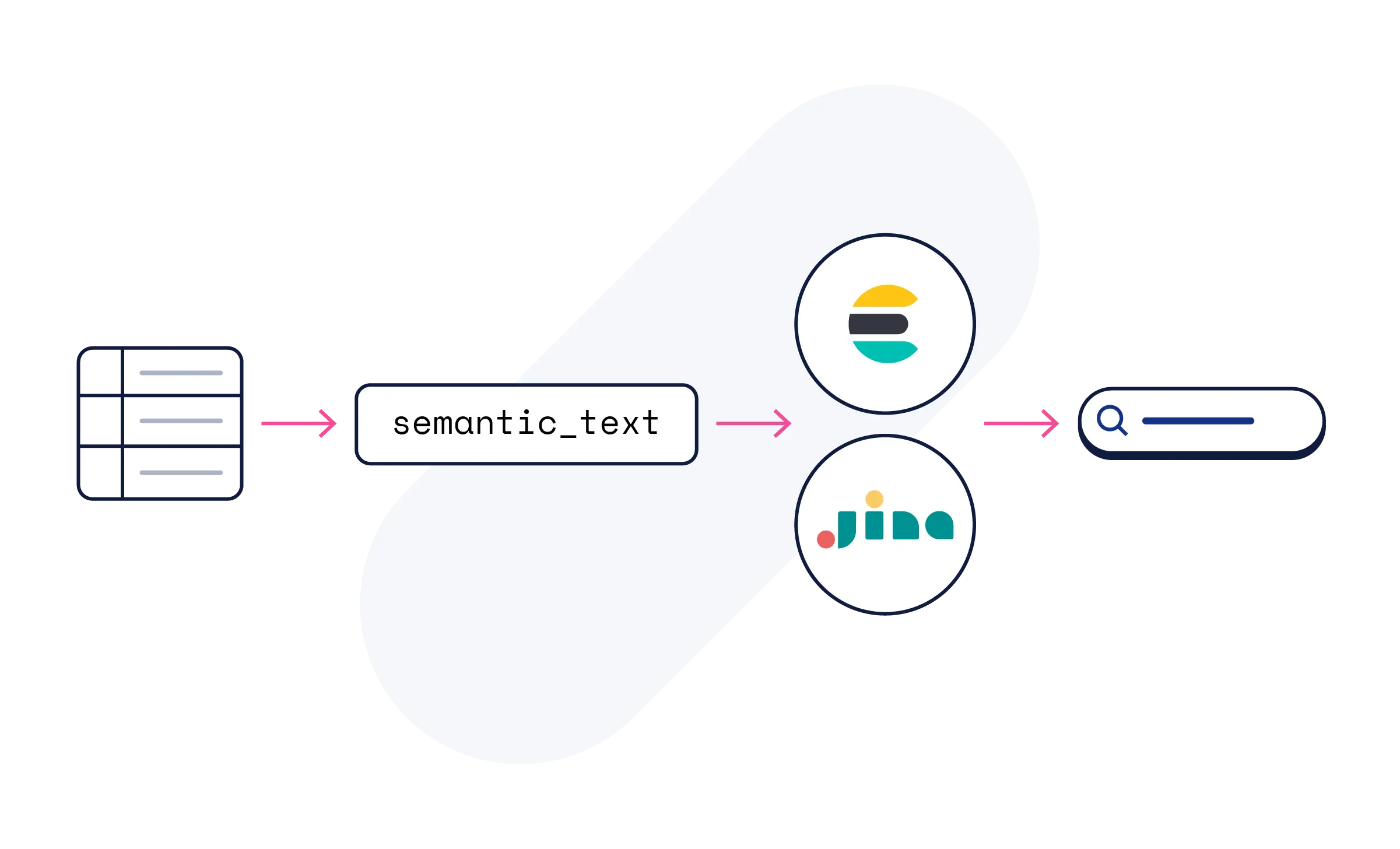
No. Usa el campo semantic_text de Elasticsearch y el procesamiento de la IA se realiza automáticamente. Los modelos de Jina hacen que tu contenido sea semánticamente buscable; no se requiere configuración de modelos ni conocimientos de ML.
¿Cómo comienzo?
¿Cómo comienzo?
Los modelos de Jina están disponibles en el servicio de inferencia de Elastic en Elastic Cloud y se incluyen en todas las pruebas. Comienza con semantic_text o explora las subpáginas de modelos para obtener ejemplos de código, referencias de API y tutoriales.
¿Qué modelos de Jina están disponibles hoy?
¿Qué modelos de Jina están disponibles hoy?
Nuestras últimas características v5-text (nano/small) incluyen 32K de contexto, dimensiones Matryoshka y la arquitectura más reciente, junto con Jina-embeddings-v3 y Reranker v2 y v3, todo disponible en el servicio de inferencia Elastic.
¿Cuántos idiomas son compatibles?
¿Cuántos idiomas son compatibles?
Jina-embeddings-v5-text admite más de 30 idiomas: una consulta en un idioma encuentra contenido relevante escrito en otro, sin necesidad de pipelines de traducción.
¿Cómo se relaciona esto con ELSER?
¿Cómo se relaciona esto con ELSER?
ELSER cubre la búsqueda semántica en inglés. Jina añade cobertura multilingüe en más de 30 idiomas con precisión superior: ambos funcionan dentro del marco de trabajo de búsqueda híbrida de Elasticsearch.
¿Es este un producto independiente?
¿Es este un producto independiente?
No. Los modelos de búsqueda Jina en Elastic Inference Service están disponibles para todos los usuarios de Elastic Cloud con precios basados en el consumo. No se requiere ninguna licencia, suscripción o clave API adicional.
¿Cómo se relaciona esto con la página de la base de datos vectorial de Elastic?
¿Cómo se relaciona esto con la página de la base de datos vectorial de Elastic?
La página de la base de datos vectorial cubre cómo se almacenan y se realiza la búsqueda de los vectores a escala. Esta página cubre los modelos de IA que los generan y reclasifican. Juntos: almacenamiento, cómputo y aplicación.