Jina AI-Modelle
Modernste Modelle für jede Phase der Retrieval-Pipeline
Spezial entwickelt für das Retrieval bieten Jina-Modelle Genauigkeit und Geschwindigkeit, die Modelle, die 5× so groß sind, übertreffen. Mehrsprachig, multimodal – Text, Bilder, Audio und Video – und jetzt nativ auf Elasticsearch.

Lernen Sie die KI-Modelle von Jina kennen
Unsere Frontier-Modelle bilden die Suchgrundlage für hochwertige Such- und Retrieval-Augmented-Generation-(RAG)-Systeme der Unternehmensklasse.



Kompaktes Design, präzise Ergebnisse
Von Rohdaten zu hochpräzisen Ergebnissen in einer API.

Verwenden Sie Jina-Modelle, wo immer Sie bauen
Von vollständig verwaltet bis selbstgehostet – Jina-Modelle treffen Sie dort, wo Ihre Daten gespeichert sind. Wählen Sie den Zugangsweg, der passt.



Unsere Forschung




Werden Sie Teil unserer Open-Source-Community
Die Modelle von Jina sind Openweight-Modelle und kostenlos auf Hugging Face erhältlich, mit Millionen monatlicher Downloads. Der Code ist öffentlich auf GitHub verfügbar. Die Community hat direkten Zugang zu unseren Entwicklern.

Greifen Sie auf unsere Modelle für Embeddings, Reranker und kleine LMs zu, um besser suchen zu können.



Häufig gestellte Fragen
Was sind Jina-Suchmodelle?
Was sind Jina-Suchmodelle?
Jina-Modelle sind Open-Source-Modelle mit Frontier-KI für den Abruf. Dazu gehören Embedding-Modelle für Vektoren, Reranker für Präzision und Reader zum Extrahieren und Strukturieren von Inhalten aus URLs und Dokumenten.
Brauche ich KI- oder Machine-Learning-Expertise, um sie zu nutzen?
Brauche ich KI- oder Machine-Learning-Expertise, um sie zu nutzen?
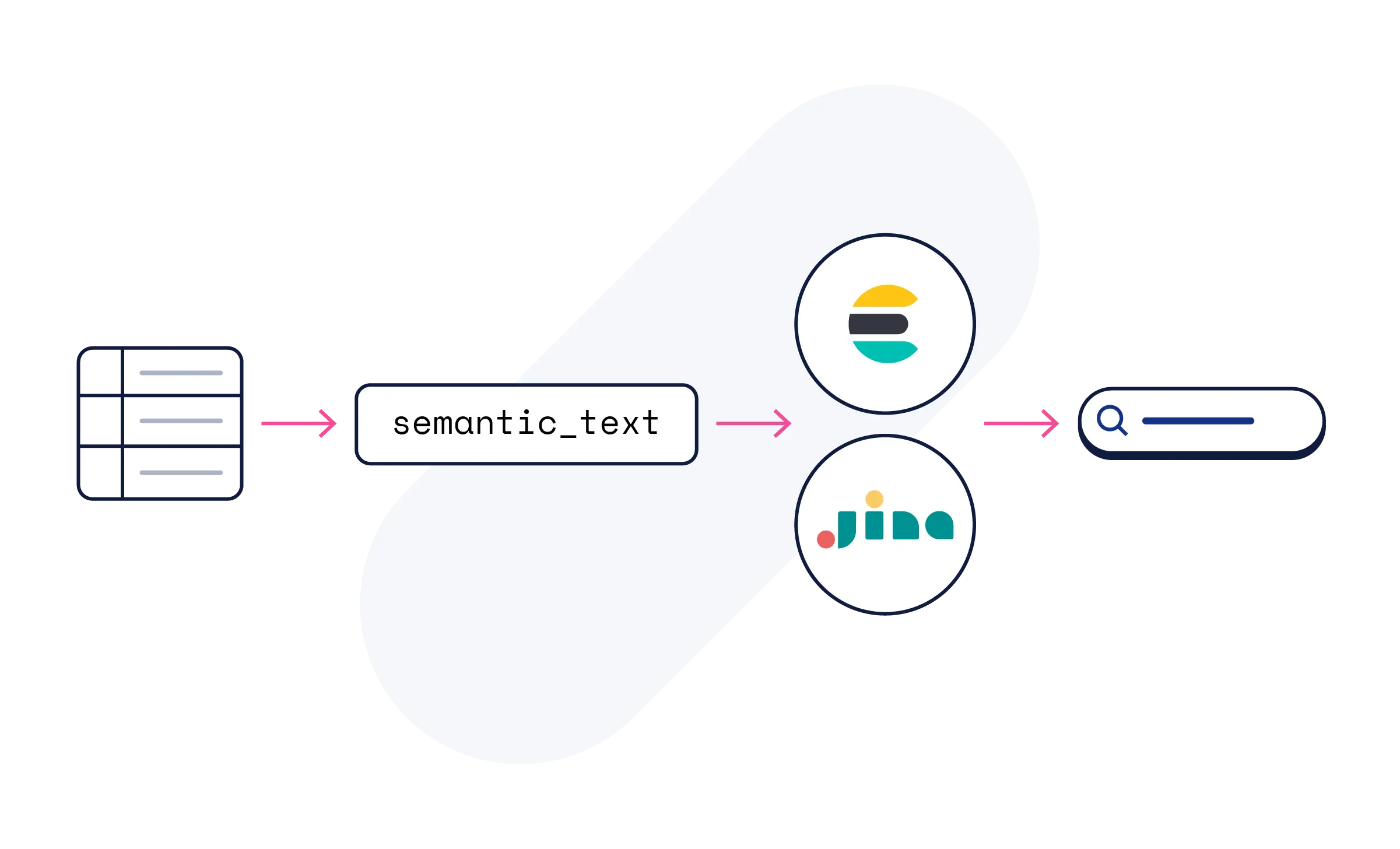
Nein. Verwenden Sie das Feld semantic_text von Elasticsearch, und die KI-Verarbeitung erfolgt automatisch. Die Modelle von Jina machen Ihre Inhalte semantisch durchsuchbar – keine Modellkonfiguration oder ML-Expertise erforderlich.
Wie kann ich anfangen?
Wie kann ich anfangen?
Jina-Modelle sind auf Elastic Inference Service auf Elastic Cloud verfügbar und in allen Testversionen enthalten. Beginnen Sie semantic_text oder suchen Sie auf den Modellunterseiten nach Codebeispielen, API-Referenzen und Tutorials.
Welche Jina-Modelle sind heute verfügbar?
Welche Jina-Modelle sind heute verfügbar?
Unser neuestes v5-text (nano/small) umfasst 32K-Kontext, Matrjoschka-Dimensionen und die neueste Architektur – neben Jina-embeddings-v3 und Reranker v2 und v3 – alle verfügbar auf Elastic Inference Service.
Wie viele Sprachen werden unterstützt?
Wie viele Sprachen werden unterstützt?
Jina-embeddings-v5-text unterstützt über 30 Sprachen – eine Abfrage in einer Sprache findet relevante Inhalte, die in einer anderen geschrieben sind, ohne dass Übersetzungs-Pipelines erforderlich sind.
Wie hängt das mit ELSER zusammen?
Wie hängt das mit ELSER zusammen?
ELSER deckt die semantische Suche in englischer Sprache ab. Jina erweitert die Funktionalität um mehrsprachige Unterstützung für über 30 Sprachen mit führender Genauigkeit – beide arbeiten innerhalb des hybriden Frameworks von Elasticsearch.
Ist dies ein separates Produkt?
Ist dies ein separates Produkt?
Nein. Die Jina-Suchmodelle im Elastic Inference Service stehen allen Elastic Cloud-Nutzern mit verbrauchsabhängigen Preisen zur Verfügung – keine separate Lizenz, kein Abonnement und kein API-Schlüssel erforderlich.
Wie hängt das mit der Vektordatenbank-Seite von Elastic zusammen?
Wie hängt das mit der Vektordatenbank-Seite von Elastic zusammen?
Die Vektordatenbank-Seite behandelt, wie Vektoren skaliert gespeichert und gesucht werden. Diese Seite behandelt die KI-Modelle, die sie generieren und neu anordnen. Zusammen: Speicher, Rechenleistung und Anwendung.