Unternehmensweit KI ermöglichen: Die Integration von Elastic und NVIDIA cuVS
Mit dem neuen Goldstandard für GPU-beschleunigte Vektorsuche können Sie große Datenmengen nahtlos vektorisieren und Ihre Produktionszeit beschleunigen.


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Zusammenfassung
- In Zusammenarbeit mit NVIDIA führt Elastic die GPU-beschleunigte Vektor-Indexierung mit NVIDIA cuVS ein.
- Elasticsearch, integriert in das von NVIDIA AI Factory validierte Design, bietet eine bewährte, vollständige, vorgefertigte Blaupause für schnellere KI-Anwendungen.
- Unternehmen können damit riesige Mengen unstrukturierter Daten bis zu 12-mal schneller vektorisieren als mit CPU-basierten Ansätzen.
Organisationen investieren massiv in KI. Doch um echten Geschäftswert zu erzielen, benötigen Sie eine Infrastruktur, die nicht nur riesige Datenmengen speichern, sondern diese auch schnell durchsuchen und Kontext daraus abrufen kann. Darüber hinaus brauchen Sie Systeme, die nicht nur Suchergebnisse zurückgeben, sondern schlussfolgern, lernen, Fragen beantworten und Aktionen ausführen können.
Die Elastic Vektorindexierung mit der GPU-Beschleunigung von NVIDIA cuVS beseitigt eine kritische Hürde für erfolgreiche KI-Bereitstellungen im Unternehmensmaßstab und ermöglicht es Organisationen, riesige Mengen unstrukturierter Daten zu vektorisieren und so den genauen Echtzeit-Kontext bereitzustellen, den moderne KI-Lösungen benötigen.
KI auf Neuland
Unternehmen treten in eine neue Phase der KI-Adoption ein, in der die Verteilung unstrukturierter Daten und die traditionelle Suche für ein Gewinnen von Einblicken nicht mehr ausreicht. Daher setzen sie nun auf leistungsstarke Vektordatenbanken und semantische Suche, die moderne KI-Anwendungen wie generative KI (GenAI), Retrieval-Augmented Generation (RAG) und KI-Agenten unterstützen sollen.
Unterdessen bauen Organisationen KI-Fabriken auf, um die Bereitstellung von KI zu vereinfachen, die Leistung zu skalieren und die Effizienz und Kapazität von GPUs zu maximieren. Der integrierte Stack, der beschleunigte Rechenleistung mit hochleistungsfähiger Vektorsuche kombiniert, ist die wirtschaftlich effizienteste Methode, um Ihren Kunden und Unternehmen KI nahezubringen.
Ist effiziente KI möglich?
Wenn große Unternehmen interne generative KI-Plattformen entwickeln, die Kontext aus Petabytes an Unternehmensdaten effizient indexieren und abrufen müssen, rücken die Kosten sofort in den Vordergrund. Diese KI-Fabriken brauchen jeden möglichen Vorteil, um kostspielige Workloads zu reduzieren.
Ähnlich verhält es sich mit Organisationen, die ihre Vektorsuchfähigkeiten skalieren möchten: Sie möchten dies möglichst ohne eine sofortige Erhöhung der CPU-Hardware-Kosten erreichen. Wenn Sie eine leistungsstarke Vektordatenbank erstellen wollen, stehen Sie vor der Herausforderung, den Vektorindex (HNSW-Graph) auf der CPU zu konstruieren. Beim Vergleich der einzelnen Vektoren kann die Indexbildung auf Millionen oder sogar Milliarden arithmetischer Operationen anwachsen. Und diese Komplexität bringt Engpässe bei der Ingestion mit sich. Fügen Sie Indexlebenszyklus-Vorgänge wie Komprimierung und Zusammenführungen hinzu, und Ihr Rechenaufwand kann erheblich steigen.
Kostenoptimierte Vektorinfrastruktur
Um Ihnen bei der Bewältigung solcher Herausforderungen zu helfen, stellen Elastic und NVIDIA gemeinsam das Elastic AI-Ökosystem bereit. Damit definieren sie neu, wie Unternehmen KI-Fabriken aufbauen und skalieren, indem sie GPU-beschleunigte Vektorsuche und eine leistungsstarke KI-Infrastruktur bereitstellen, die eine Echtzeit-Intelligenz der nächsten Generation ermöglicht.
Durch die Kombination des validierten Designs der NVIDIA Enterprise AI Factory mit der leistungsstarken Vektordatenbank von Elasticsearch können Unternehmen tiefere Einblicke und relevante Echtzeitdaten für KI-Agenten und GenAI-Anwendungen sicher und auf Unternehmensebene bereitstellen.
Mit Elastic und NVIDIA erhalten Sie die Kraft einer hochleistungsfähigen, funktionsreichen Vektordatenbank mit GPU-Beschleunigung, die für moderne KI entwickelt wurde.
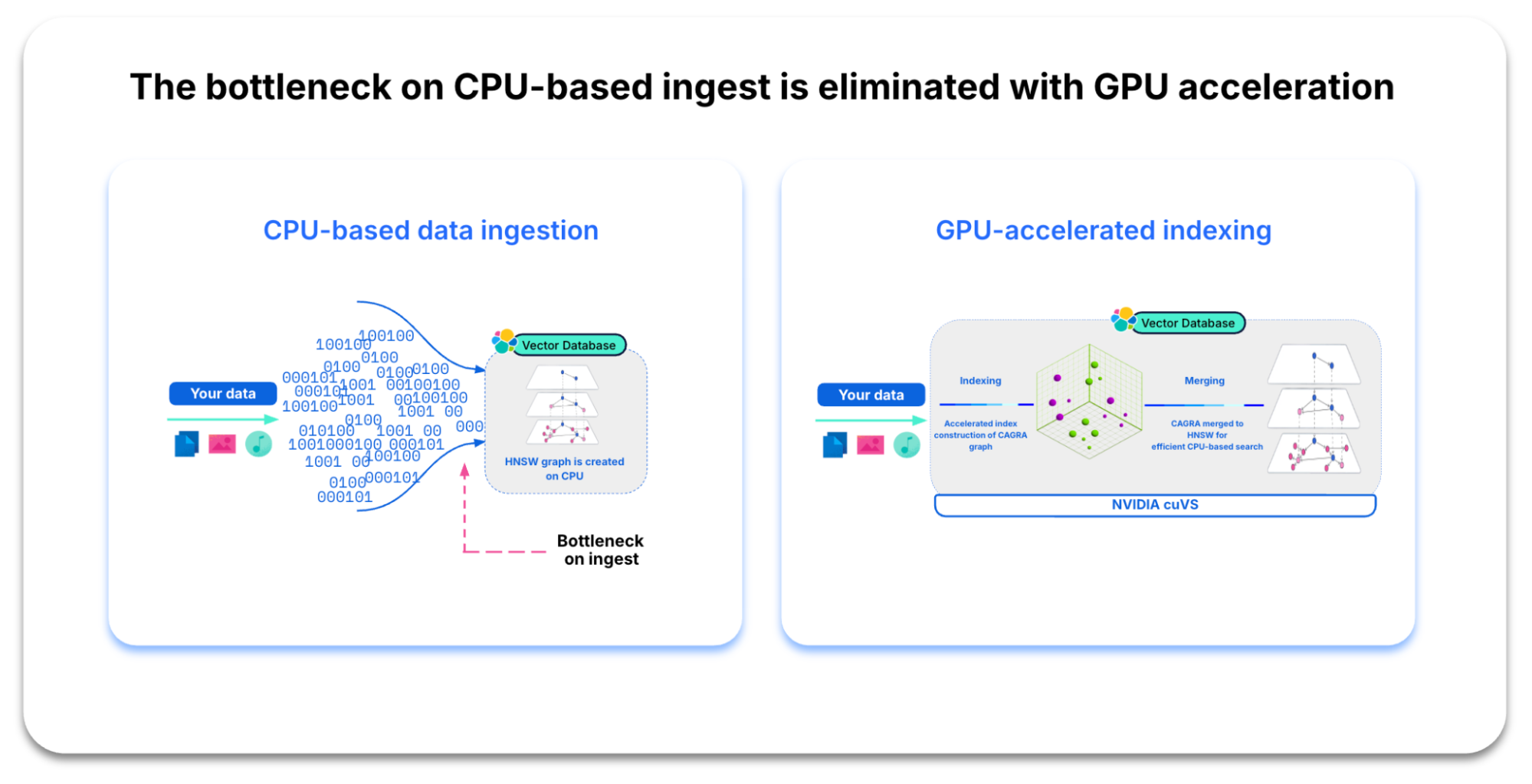
Nachfolgend sind einige der Vorteile aufgeführt, die Sie von dieser Integration erwarten können.
Schnelleres Deployment
Verkürzen Sie die Markteinführungszeit, indem Sie ein vorgefertigtes Komplettsystem für den Bau von On-Prem-KI-Fabriken verwenden. Elasticsearch ist eine validierte und unterstützte Vektordatenbank innerhalb des von NVIDIA Enterprise AI Factory validierten Designs und gewährleistet ein zuverlässiges Framework für die Bereitstellung agentischer KI-Anwendungen.
Schnelles, effizientes Indexieren
Verarbeiten Sie exponentiell wachsende Vektoreinbettungen und große Datenmengen effizienter. Durch die Integration von NVIDIA cuVS in Elasticsearch wird eine fast 12-fache Verbesserung des Indexierungsdurchsatzes und eine 7-fache Steigerung der Geschwindigkeit beim Force-Merging erreicht.
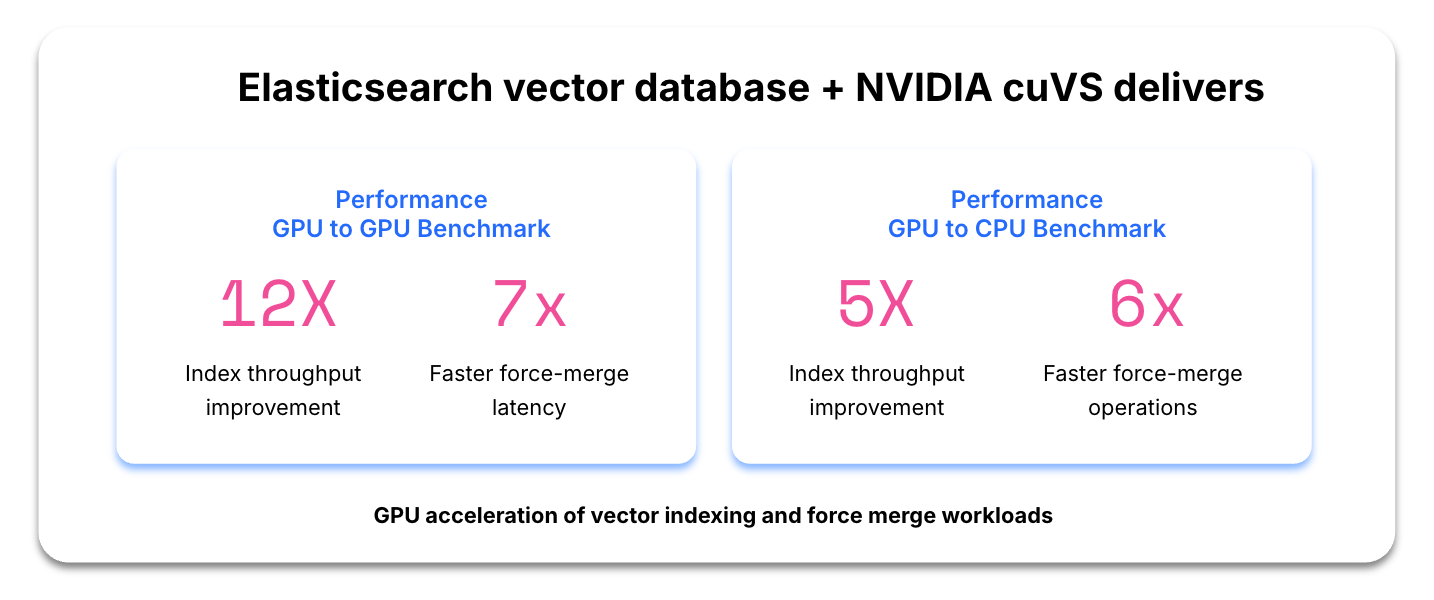
Kosteneffizienz und Ressourcenoptimierung
Die Auslagerung von rechenintensiven Arbeitslasten auf GPUs reduziert die CPU-Auslastung und maximiert den Wert Ihrer bestehenden Infrastruktur. Im Kostenvergleich bietet die GPU-Beschleunigung im Vergleich zur Standard-CPU-Nutzung etwa einen 5-fach höheren Indexierungsdurchsatz und 6-fach schnellere Force-Merging-Operationen.
Verbesserte Echtzeit-Abfrageleistung
Die NVIDIA-beschleunigte Vektorsuche von Elastic beseitigt Leistungsengpässe und ermöglicht es Ihrer Infrastruktur, massive Abfragevolumina mit nahezu sofortigen Reaktionszeiten zu bewältigen, sodass Sie generative KI- und RAG-Anwendungen effizient skalieren und gleichzeitig relevante Einblicke in Echtzeit liefern können.
Nahtlose Zukunftssicherheit und Skalierbarkeit
Pflegen Sie eine leistungsstarke, im großen Maßstab bewährte Vektordatenbank ohne den Aufwand ständiger manueller Optimierung. NVIDIA cuVS optimiert und beschleunigt Vektorsuchvorgänge über neue NVIDIA-GPU-Architekturen und CUDA-Versionen hinweg und gewährleistet so Spitzenleistung und nahtlose Skalierbarkeit für KI- und datenintensive Arbeitslasten.
Native GPU-beschleunigte Inferenz und Modellverwaltung
Eliminieren Sie die Komplexität der Verwaltung externer Inferenzanbieter und der Infrastruktur. Der Elastic Inference Service (EIS) ermöglicht native, hocheffiziente Inferenz direkt in Elasticsearch und nutzt dabei die moderne KI-Infrastruktur von NVIDIA, um auch im großen Maßstab skalieren und eine niedrige Latenz aufrechtzuerhalten. Binden Sie produktionsbereite, verwaltete Modelle, einschließlich der mehrsprachigen Embedding- und Reranker-Modelle von Jina AI, nativ ein, um präzises Abruf-Tuning und Datensouveränität ohne zusätzlichen operativen Aufwand sicherzustellen.
Was kommt als Nächstes?
Elastic und NVIDIA haben gemeinsam mehr Geschwindigkeit, Skalierbarkeit und Mehrwert für Unternehmen geschaffen, die die Vektorsuche für die Entwicklung und Bereitstellung von Echtzeit-RAG- und KI-Anwendungen nutzen. Ihr Team kann so die Leistung in großem Umfang steigern und gleichzeitig Ihre Infrastruktur und Ihr Budget schonen.
Da Elasticsearch im validierten Design der NVIDIA AI Factory enthalten ist, erhalten Sie eine bewährte, vorgefertigte, vollständige Blaupause zur Beschleunigung von KI-Anwendungen, was mehr Effizienz und eine schnellere Markteinführung bedeutet.
Die NVIDIA cuVS-Integration befindet sich derzeit in der technischen Vorschau für Unternehmenskunden mit selbstverwalteten Lösungen von Elastic (Version 9.3). Die allgemeine Verfügbarkeit ist für April 2026 mit der Version 9.4 geplant, die eine produktionsreife Grundlage für hochvolumige Vektorsuche und Echtzeit-Kontextabruf bieten wird.
Erfahren Sie mehr über das wachsende Elastic AI-Ökosystem, laden Sie das Elastic AI-Ökosystem-Entwicklerhandbuch herunter oder tauschen Sie sich auf der NVIDIA GTC mit den technischen Experten von Elastic über Hochleistungs-KI aus. Besuchen Sie uns am Stand Nr. 3200, sehen Sie sich Live-Demos an und sprechen Sie mit den Experten von Elastic.
Die Entscheidung über die Veröffentlichung der in diesem Blogeintrag beschriebenen Leistungsmerkmale und Features sowie deren Zeitpunkt liegt allein bei Elastic. Es ist möglich, dass noch nicht verfügbare Leistungsmerkmale oder Features nicht rechtzeitig oder überhaupt nicht veröffentlicht werden.
In diesem Blogpost haben wir möglicherweise generative KI-Tools von Drittanbietern verwendet oder darauf Bezug genommen, die von ihren jeweiligen Eigentümern betrieben werden. Elastic hat keine Kontrolle über die Drittanbieter-Tools und übernimmt keine Verantwortung oder Haftung für ihre Inhalte, ihren Betrieb oder ihre Anwendung sowie für etwaige Verluste oder Schäden, die sich aus Ihrer Anwendung solcher Tools ergeben. Gehen Sie vorsichtig vor, wenn Sie KI-Tools mit personenbezogenen, sensiblen oder vertraulichen Daten verwenden. Alle von Ihnen eingegebenen Daten können für das Training von KI oder andere Zwecke verwendet werden. Es gibt keine Garantie dafür, dass von Ihnen bereitgestellte Informationen sicher oder vertraulich behandelt werden. Setzen Sie sich vor Gebrauch mit den Datenschutzpraktiken und den Nutzungsbedingungen generativer KI-Tools auseinander.
Elastic, Elasticsearch und zugehörige Marken sind Marken, Logos oder eingetragene Marken von Elasticsearch N.V. in den Vereinigten Staaten und anderen Ländern. Alle anderen Unternehmens- und Produktnamen sind Marken, Logos oder eingetragene Marken ihrer jeweiligen Eigentümer.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken