Modelos Jina AI
Modelos de última geração para cada estágio do pipeline de recuperação.
Projetados especificamente para recuperação, os modelos Jina oferecem precisão e rapidez que superam modelos 5× maiores. Multilíngues, multimodais — texto, imagens, áudio e vídeo — e agora nativos no Elasticsearch.

Conheça os modelos Jina AI
Nossos modelos de ponta formam a base da busca para sistemas empresariais de busca de alta qualidade e de retrieval-augmented generation (RAG).



Compacto por concepção, preciso nos resultados
Obtenha resultados de alta precisão a partir de dados brutos em uma única API.

Use modelos Jina onde você já constrói
De totalmente gerenciados a auto-hospedados, os modelos Jina atendem você onde seus dados estão. Escolha um caminho de acesso.



Nossa pesquisa




Faça parte da nossa comunidade open source
Os modelos Jina são de código aberto e estão disponíveis gratuitamente no Hugging Face, com milhões de downloads mensais. O código-fonte é público no GitHub. A comunidade tem acesso direto aos nossos desenvolvedores.

Acesse nossos modelos para embeddings, reclassificadores e pequenos LMs para melhorar a busca.



Perguntas frequentes
O que são os modelos de busca Jina?
O que são os modelos de busca Jina?
Os modelos Jina são modelos de IA de ponta e open source para recuperação de informações. Eles incluem modelos de embedding para vetores, reclassificadores para precisão e leitores para extrair e estruturar conteúdo de URLs e documentos.
Preciso de experiência em IA ou machine learning para usá-los?
Preciso de experiência em IA ou machine learning para usá-los?
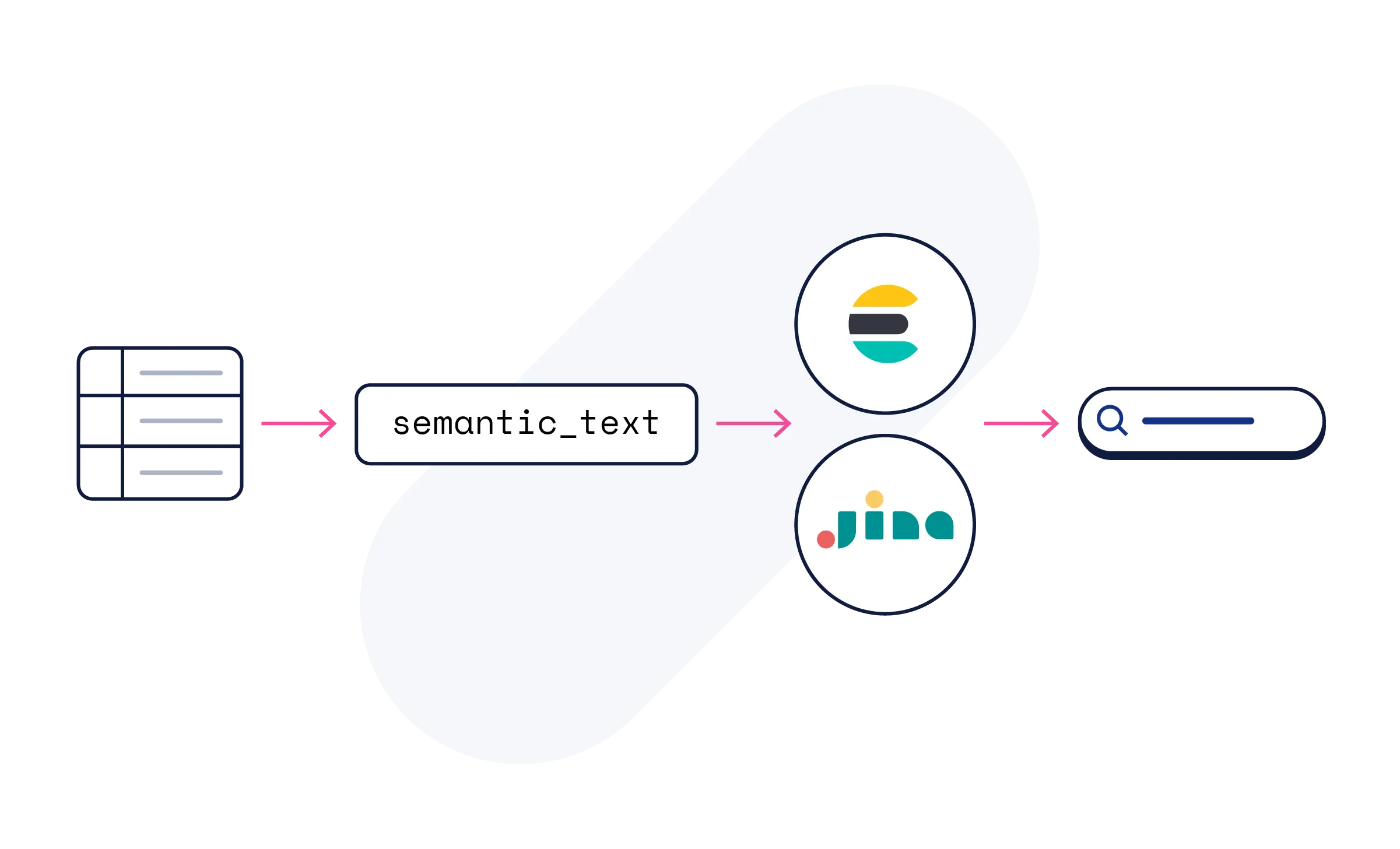
Não. Use o campo semantic_text do Elasticsearch e o processamento da IA acontece automaticamente. Os modelos Jina tornam seu conteúdo semanticamente pesquisável — sem a necessidade de configuração de modelos ou conhecimento em ML.
Como começar?
Como começar?
Os modelos Jina estão disponíveis no Elastic Inference Service no Elastic Cloud, incluídos em todos os testes. Comece com semantic_text ou explore subpáginas de modelos para exemplos de código, referências de API e tutoriais.
Quais modelos Jina estão disponíveis hoje?
Quais modelos Jina estão disponíveis hoje?
Nossa versão mais recente v5-text (nano/small) apresenta o recurso de contexto de 32K, dimensões Matryoshka e a arquitetura mais recente — junto com Jina-embeddings-v3 e Reclassificador v2 e v3 — tudo disponível no Elastic Inference Service.
Quantos idiomas são suportados?
Quantos idiomas são suportados?
Jina-embeddings-v5-text suporta mais de 30 idiomas — uma consulta em um idioma encontra conteúdo relevante escrito em outro, sem a necessidade de pipelines de tradução.
Qual a relação disso com o ELSER?
Qual a relação disso com o ELSER?
O ELSER abrange a busca semântica em inglês. O Jina adiciona cobertura multilíngue em mais de 30 idiomas com precisão líder de mercado — ambos funcionam dentro do framework de busca híbrida do Elasticsearch.
Este é um produto separado?
Este é um produto separado?
Não. Os modelos de busca Jina no Elastic Inference Service estão disponíveis para todos os usuários do Elastic Cloud com preços baseados no consumo. Não é necessária nenhuma licença, assinatura ou chave de API separada.
Como isso se relaciona com a página do banco de dados vetorial da Elastic?
Como isso se relaciona com a página do banco de dados vetorial da Elastic?
A página sobre o banco de dados vetorial aborda como os vetores são armazenados e pesquisados em grande escala. Esta página aborda os modelos de IA que os geram e reclassificam. Em conjunto: armazenamento, computação e aplicação.