On-demand webinar
Integrating Human Genetic Data to Help Drive Drug Discovery: Elastic @ Merck
Hosted by:

Bhasker Bokuri
Software Engineer
Merck

Daniel Myung
Senior Engineer
Merck
Overview
As genome sequencing’s costs have dramatically fallen, scientists have been awash in genetic data for novel research – but the existing tools and methods for analysis were not scaling well in terms of data size and harmonization, and they are also tedious, manual, and require a significant amount of expert integration.
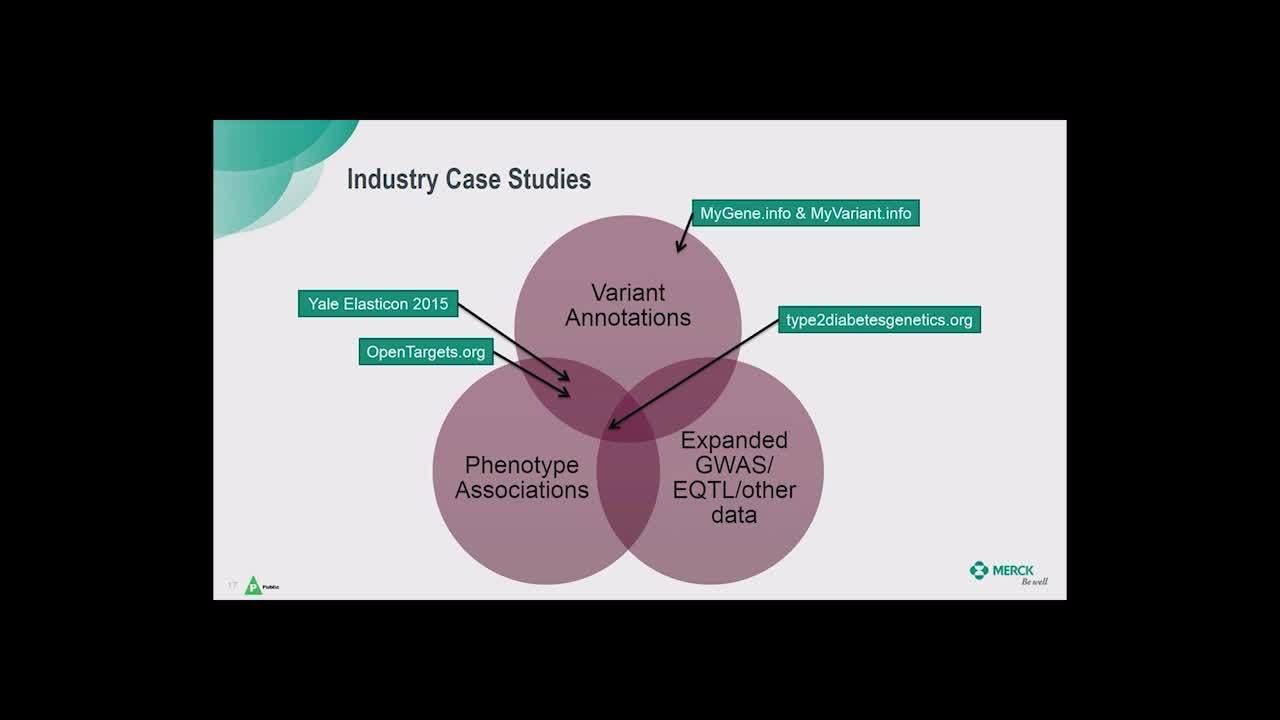
Daniel and Bhasker will share Merck’s journey with Elasticsearch, which has enabled them to harmonize a data ingestion pipeline and create a universal coordinate system for genetic variants as a backbone to help scientists uncover new insights on human genetics across a broad spectrum of diseases (from cancers, alzheimer’s, diabetes), and to aid in the discovery and validation of new therapies.
View next
Upcoming webinar
From search to agents: How buyer expectations are reshaping AI platforms in 2026