Made To Measure: How to Use the Ranking Evaluation API in Elasticsearch
The Ranking Evaluation API that's been added to Elasticsearch is a new, experimental REST API that lets you quickly evaluate the quality of search results for a typical query set. This can be useful either while developing new search queries, incremental improvements of the query templates of an an existing system, or as a basic monitoring tool to detect changes in the search quality of a system in production.
A recent blog post about relevance tuning already gave some initial motivation for why Ranking Evaluation is useful and gave a first glimpse at the new API. This post will show you how to use the new Ranking Evaluation API in Elasticsearch to measure search performance on real-life data and will show some common usage examples. The goal is to give you some hands-on experience using the API to initially develop a simple search query and measure its ranking quality. Then you’ll gradually improve it, learning about some of the details of the new API along the way.
Setting Up the Demo Project
Before we start diving into the API itself, let us take a quick look at a demo project that will help you setting up the dataset we are going to play with. We will use a small subset of documents from the English Wikipedia that Wikimedia provides publicly for download. If you are interested in how to index data from Wikipedia in general, take a look at this Loading Wikipedia's Search Index for Testing blog post. For now, we keep things simple. I have already prepared the scripts that will create the index you are going to use. Let’s start by cloning the project itself:
git clone https://github.com/cbuescher/rankEvalDemo.git
Inside the main folder you can find a directory called bulkdata which contains the documents that we are going to index. In order to index this data, start a local instance of Elasticsearch 6.3 now. Note: For other versions, please check if there is a corresponding branch in the demo project. API syntax might change, since this API is still experimental at the time of this writing, so you need to adapt the following examples if necessary.
Next, we are going to create an index named "enwiki_rank" that contains the demo documents. Assuming Elasticsearch is reachable at the default of localhost:9200 (otherwise you’ll need to adapt the script slightly), run the ./setup.sh script, which will create a new index called “enwiki_rank” and then index the above mentioned bulk files, which should usually take just a few seconds.
Let’s take a quick look at the data by using the Kibana Console:
GET /enwiki_rank/_count
Response:
{
"count": 1882
}
So we have about 1900 documents in the index to play with. A quick inspection of the mapping shows that there is quite a bit of information available for each Wikipedia document:
GET /enwiki_rank/page/_mapping
Besides the text content field itself (aptly called “text”), we find fields like “title”, “opening_text” and “category” in various analysis variants, as well as several additional metadata fields like incoming and outgoing links, redirects or popularity measures. We don’t need to go through all of them now, instead take a quick look at one example document (the page about John F. Kennedy) to get an idea about a typical document:
GET /enwiki_rank/page/5119376
The returned document is huge, but at least take a look at some of the content fields like “title”, “text”, “opening_text” and “redirect” (which lists titles of pages redirecting to this one).
Creating a Simple Query
Let’s start some searching now. Imagine your task is to develop some general purpose search frontend for this kind of data. Currently, you have little idea of how the documents are structured and which kind of queries to translate your users input to. You start your journey by imagining a typical user who wants to find information about president Kennedy, but unfortunately types “JFK” into the search box. You now have to make a choice how your search system translates this into an Elasticsearch query. Since we don’t know any better yet, let’s start simple by querying the “all” field (the catch-all copy-to field in the Wikipedia mappings. Note: this is NOT the Elasticsearch “_all” field, which is disabled by default in the mappings as of version Elasticsearch 6.0). Because documents are very large, and at this point we only need their titles, let us use source filtering to select only the title field:
GET enwiki_rank/page/_search?filter_path=hits.hits._source.title
{
"query" : {
"match" : {
"all" : "JFK"
}
}
}
The response might be a bit disappointing. It contains many documents about the JFK airport and related locations, a football club, a Boston train station, but only the "JFK (disambiguation)" page and the page called "Reactions to the assassination of John F. Kennedy" are somehow related to Kennedy, the president. Maybe we can try to be more specific by searching on the “title”, “opening_text” and a fuzzy version of the redirect page title called “redirect.title.near_match”:
GET enwiki_rank/page/_search?filter_path=hits.hits._source.title
{
"query": {
"multi_match": {
"query": "JFK",
"type": "best_fields",
"fields": [
"title",
"opening_text",
"redirect.title.near_match"
]
}
}
}
The result already looks more promising:
"hits": [{ [...]
"title": "JFK (disambiguation)" [...]
"title": "JFK Medical Center (Edison, New Jersey)" [...]
"title": "AirTrain JFK" [...]
"title": "John F. Kennedy" [...]
"title": "John F. Kennedy International Airport" [...]
"title": "JFK Express" [...]
"title": "Sutphin Boulevard–Archer Avenue–JFK Airport (Archer Avenue Lines)" [...]
"title": "JFK (soundtrack)" [...]
"title": "Howard Beach–JFK Airport (IND Rockaway Line)" [...]
"title": "Skaboy JFK" [...]
}]
In addition to the disambiguation page, we find the article about president John F. Kennedy and the soundtrack of the movie JFK, but the rest of the result still doesn’t look great.
We could continue like this: looking at some data, improving the query bit by bit and checking the results, until we are satisfied. But there are many disadvantages to this. First, you will need to look through the list of results every time you change anything in your query and make a judgement call whether the results are better or worse than the previous ones. This is more or less a gut feeling. While it is sometimes clear which documents should be returned on top, it is much harder to judge the “somewhat okay” and the “really bad” cases in a consistent way over time. And then there is your colleague or boss that in many cases will have a slightly different opinion on which search results should be leading the list, so once they start tuning the query, everything moves into a different direction. A structured way of evaluating your search ranking is clearly needed.
Good, Better, Best
This is where the new Ranking Evaluation API comes into play. It provides a way of attaching a set of document ratings to each of the typical search cases relevant for your system. By doing so, it offers a repeatable way of calculating various evaluation measures (that are well known in information retrieval literature) on top of those ratings to guide you in your decisions on how to optimize your system.
To make this more concrete, let us take a look at how such document ratings might look like. The Wikimedia foundations Discovery department has been working on improving their site search for a long time, and they struggled with the same kind of problems as the ones described above. This is why they launched their own service Discernatron with the goal to collect human judgments of search result relevance by letting users rate the quality of results on a scale from 0 (irrelevant) to 3 (relevant). User with a Wikimedia account can login at https://discernatron.wmflabs.org and check out the tool. It’s really worth a look and you might even be able to help improving the search quality of the largest knowledge base of our time by rating a few documents yourself. Just in case you don’t want to do that right now, here is what the user interface looks like:
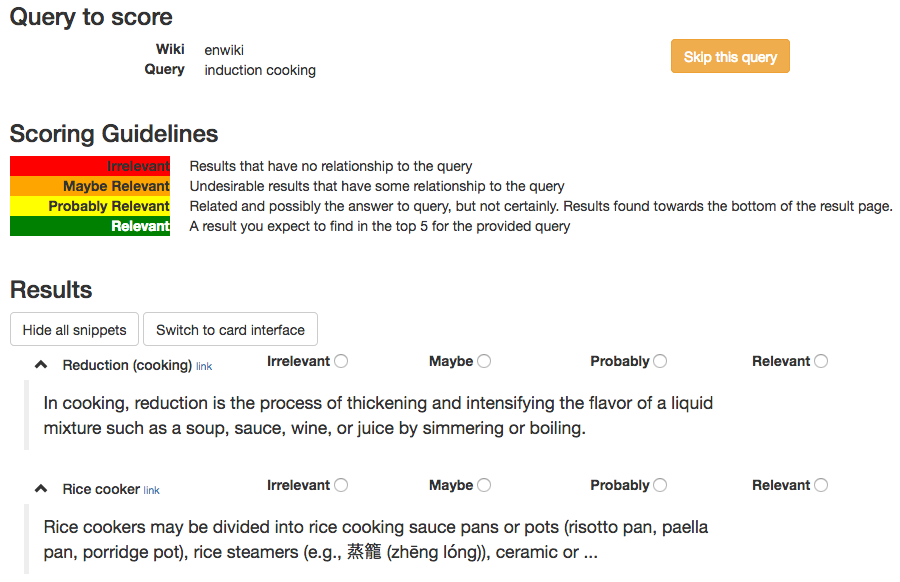
The full dataset is available for users with a Wikimedia account (also optionally in JSON format), currently containing more than 6000 ratings associated with about 150 user queries. The document ratings for the rest of this demo are all based on this data to save of the trouble of having to come up with our own relevance ratings.
Basic Request and Response
So let’s get back to our search for “JFK” that we started to build a query for. Luckily, there are already about 60 document ratings for this query in the Discernatron dataset. The demo project contains a slightly older, reduced dataset containing the document ratings. When you inspect that file, the first three columns contain the query, page title and average rating for the document in question. We can see that the ratings for the result “John F. Kennedy” is most relevant (score 3.0) while things like the JFK movie (score 2.25) or the airport (score 2.25) are rated lower and articles about the movie soundtrack (score 1.0) or the football team JFK Olimps (score 0.75) are judged as rather irrelevant with respect to the query. We can use this data to create out first request to the Ranking Evaluation API. Because the list of ratings is quite long, the full ratings array is abbreviated here, but you can find the full request in the demo project.
POST /enwiki_rank/_rank_eval
{
"requests": [{
"id": "JFK_query",
"request": {
"query": {
"multi_match": {
"query": "JFK",
"type": "best_fields",
"fields": [
"title",
"opening_text",
"redirect.title.near_match"
]
}
}
},
"summary_fields": [
"title"
],
"ratings": [{
"_id": "3054546",
"rating": 1,
"_index": "enwiki_rank"
},
{
"_id": "5119376",
"rating": 3,
"_index": "enwiki_rank"
}, [...]
]
}],
"metric": {
"precision": {
"relevant_rating_threshold": 2,
"k": 5
}
}
}
Let’s examine this request part by part. The largest part of the request is an array called "requests". It defines the set of different search cases that are part of the evaluation. We start simple by only evaluating the “JFK” search at the moment, but will extend that later. We give this use-case an id and specifying the query from above to be executed. The summary_fields parameter defines a filter on the document fields that we want to see in the response. For the sake of this demo it is sufficient to see the document title. The "ratings" section contains all the relevance judgements that we extracted from the Discernatron dataset by mapping the page title to out internal document id. Here e.g. the document with "_id": "5119376" refers to the John F. Kennedy article and gets the highest score of 3.0.
The following, smaller section defines the evaluation metric itself. We choose Precision, or more specifically, Precision at K, which is a metric that takes the first K returned search results and calculates the fraction of relevant documents. Since we use rating on a scale from zero to three, we also need to define from which ratings on this scale we consider as “relevant”. We choose a rating of 2 and above to be “relevant” by setting the relevant_rating_threshold accordingly. For the sake of brevity, we also choose to evaluate the query only on the top 5 documents. This means that when those top 5 results contain three documents with score two or higher, the precision will be 3 / 5 = 0.6. You can check this now by running the full request in the Kibana Console. This is the abbreviated response:
{
"quality_level": 0.6,
"details": {
"JFK_query": {
"quality_level": 0.6,
"unknown_docs": [
{
"_index": "enwiki_rank",
"_id": "26509772"
}
],
"hits": […],
"metric_details": {
"precision": {
"relevant_docs_retrieved": 3,
"docs_retrieved": 5
}
}
}
}
}
As we can see, apart from the total result, a precision score of 0.6, the details section contains additional information about each evaluated search case, in this case only the “JFK_query”. The metric_details section shows how the score was calculated. As expected, we found 3 relevant documents out of 5 retrieved. But what about the other two documents? Either the document had a rating of less than 2, or some of the results returned by the query were not rated at all. It can be useful to present especially these unrated documents to the user and ask for a rating. The unknown_docs section contains those documents for exactly this purpose. In addition, the hits section contains all the search hits returned for the particular query under evaluation. The difference between a usual search and "hits" is that each hit contain its rating (or null if there is none) and usually _source is omitted. Document fields can be included (e.g. because we want to present them to a user when asking for a rating) by explicitly specifying them in the request's summary_fields.
Improving Queries Incrementally
Now that we know what the basic requests and responses look like, let us use this to improve our query some more. By looking at the title of the results, we can see that the three relevant documents we get back are “John F. Kennedy”, “JFK (disambiguation)" and “John F. Kennedy International Airport”. Not too bad, but we might get even better. Poking around in the Wikipedia document definition, we find a field called popularity_score, which seems to be higher for popular articles like “John F. Kennedy” than for niche articles like "JFK Medical Center (Edison, New Jersey)". Let us see if we can use this to boost search results with a function score query using this request:
POST /enwiki_rank/_rank_eval
{
"requests": [{
"id": "JFK_query",
"request": {
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "JFK",
"type": "best_fields",
"fields": [
"title",
"opening_text",
"redirect.title.near_match"
]
}
},
"functions": [{
"field_value_factor": {
"field": "popularity_score",
"missing": 1
}
}],
"boost_mode": "multiply"
}
}
},
"summary_fields": [
"title"
],
"ratings": [… ]
}],
"metric": {
"precision": {
"k": 5,
"relevant_rating_threshold": 2
}
}
}
We now even get 4 out of 5 relevant documents in the result, which leads to a precision score of 0.8. Well done. But what if this is just improving results for this particular query. After all, out users are not just interested in the results for typing in “JFK” into the search box. Time to put some more typical searches in the mix.
Extending the Set of Evaluated Queries
Looking at the user queries in first column of the document ratings, we can discover more cases which we have ratings for. Typically you would try using the whole data if possible, but for now, let's just add two cases to the evaluation. The first search we’ll add (“the great beer flood”) relates to a curious historical incident called the London beer flood, where in 1814, after a brewery accident, more than 1 million liters of beer were running into the streets. The second search case we’ll add is about “naval flags” and we’ll assume users are interested in things like maritime flags or other kinds of naval ensigns.
We want to use the same query as the one above, but we don’t want to repeat it three times. We can avoid this by using the templates section, that allows sharing queries common to all search use cases and to parametrize them later. The query that we previously defined in the requests section gets its own template id (“my_template”) and uses a placeholder ("{{query_string}}") inside the query that is later replaced by the actual user query. If you ever used search templates before, this will look familiar. In the requests sections we can now refer to this template by its id using the template_id and providing the parameter replacements in the params object:
POST /enwiki_rank/_rank_eval
{
"templates": [{
"id": "my_template",
"template": {
"source": {
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "{{query_string}}",
"type": "best_fields",
"fields": [
"title.near_match",
"opening_text.plain",
"redirect.title.near_match"
]
}
},
"functions": [{
"field_value_factor": {
"field": "popularity_score",
"missing": 1,
"modifier": "none"
}
}],
"boost_mode": "multiply"
}
}
}
}
}],
"requests": [{
"id": "JFK_query",
"template_id": "my_template",
"params": {
"query_string": "JFK"
},
"ratings": […]
},
{
"id": "the_great_beer_flood_query",
"template_id": "my_template",
"params": {
"query_string": "the great beer flood"
},
"ratings": […]
},
{
"id": "naval_flags_query",
"template_id": "my_template",
"params": {
"query_string": "naval flags"
},
"ratings": […]
},
"metric": {
"precision": {
"k": 5,
"relevant_rating_threshold": 2
}
}
}
}
When we run the full request, the result might be a bit surprising at first: the combined average "quality_level" is now only 0.26. While the “JFK” query still performs well (a precision of 0.8), the other two queries show a precision of 0, meaning they don’t have any relevant document in their results. This leads to an average precision of only 0.26. What seems to be wrong? If we look at the results in the details, we see that e.g. the “naval flags” query returns the “Union Jack” as first search hit, and the “great beer flood” query features things like “Great White Shark” or “Bob Dylan” among its search results. Maybe the influence of the popularity_score field we added to the query to get better results with the “JFK” example is too high? Let’s just try it out by taking the function_score query out again. This already increases precision to 0.46. Still not great, but at least each search now contains some relevant results: while precision for the “JFK” query dropped a bit to 0.6, we now also get 0.6 on the “naval flags” query and at least 0.2 with the “beer flood” query:
{
"quality_level": 0.4666666666666666,
"details": {
"JFK_query": {
"quality_level": 0.6,
[...]
},
"naval_flags_query": {
"quality_level": 0.6,
[...]
},
"the_great_beer_flood_query": {
"quality_level": 0.2,
[...]
}
}
}
Start Exploring
In the end, finding a good query template usually means finding a compromise that works reasonably well across all search use cases in the test set. After all, a query template that returns some good results for most use cases is better than a query template that gets a perfect score for one particular use case but returns nothing useful for all the others.
There are many aspects we haven’t touched yet, but that are worth exploring on your own. For example, we used the precision metric throughout this blog post because its relatively easy to explain and calculate. However, it doesn’t take the positions of the rated documents in the result set into account — a relevant result in the first position counts the as a relevant document in the last position of the top results. The Discounted Cumulative Gain (DCG) metric is much better suited for these cases. You can try it out by simply exchanging the “metric” section in the examples above with:
"metric": {
"dcg": {
"normalize": true,
"k": 5
}
}
This will calculate the normalized variant of the metric on the top 5 results. Start by using it with just one search query first and observe how the evaluation score changes when document with a high rating are returned further up the result list.
Using the Ranking Evaluation API won’t magically make your search queries return only relevant results out of a sudden, but it will help you a lot in guiding your decisions while prototyping and maintaining a search system later on. No reasonably complex search application should be run in production without any kind of quality testing, be simple unit test, A/B tests or periodically running one of the metrics the Ranking Evaluation API offers. Coming up with relevance judgements for specific search cases might seem a bit of work first, but once you have your basic test set, you can iterate much faster and with more confidence on making changes, be it to your queries, analysis, or other parts of your system.