Elastic Enterprise Search 8.6: Reduce time to relevant search results — for file systems, MongoDB, and Amazon S3


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Elastic Enterprise Search 8.6 enables customers to index searchable content on file systems, network drives, MongoDB, and Amazon S3. With new connectors for network drives and Amazon S3, content indexed can easily be transformed for natural language processing (NLP) use cases with intuitive tooling to test and tune your search experience with the trained model of your choice.
Relevant search starts with indexing the data you need, with a resilient solution that minimizes impact to your data sources. We’ve added greater precision to scheduling web crawls to offload traffic to sites during peak business hours, filtering rules for our MongoDB connector, and additional operator support with sync monitoring. With these additional capabilities, Enterprise Search on Elastic Cloud is a cost effective solution to keep your search experience and data in sync without the operational overhead of maintaining your own code or custom solution.
Ready to roll up your sleeves and get started? We have the links you need:
- Start Elasticsearch on Elastic Cloud
- Download Elasticsearch, Kibana, Integrations
- 8.6 Release notes for Enterprise Search
- 8.6 Breaking changes
Using the indexing API, customers could always bring in the data they needed with code that would be hosted on their own infrastructure and would continue to demand constant investment from their developers. While flexible and powerful, choosing to use Enterprise Search’s connector clients and framework gives your team more options to offload the pager to be supported by Elastic while retaining that flexibility and power to build for your needs.
The integration catalog for Enterprise Search consists of our web crawler, native connectors, and connector clients. The life cycle for these connectors starts with the connector client, which can be deployed on self managed infrastructure, is open code, and is customizable for your business needs. Any changes your developers choose to contribute into these open code repositories can be accepted and merged to be part of the native version of the connector, thus opening the door to a fully supported Elastic connector that your developers no longer have to maintain.
What else is new in Elastic 8.6? Check out the 8.6 announcement post to learn more >>
Open code connector clients for network drives and Amazon S3
In this release, we add the technical preview for two connector clients: network drives and Amazon S3. Customers who have utilized FSCrawler previously but needed a supported official Elastic connector have a great path to a native connector in this client.
Both of these clients allow you to take full advantage of search optimized Elasticsearch indices, defined ingest pipelines with PDF extraction support, and the improved tooling for NLP management.
These connectors unlock search experiences that allow your organization to find PII, for GDPR compliance and more. The answer to questions like: “What files in this file server contain social security numbers?” is only a search away.
Better tools to implement and manage NLP in search indices
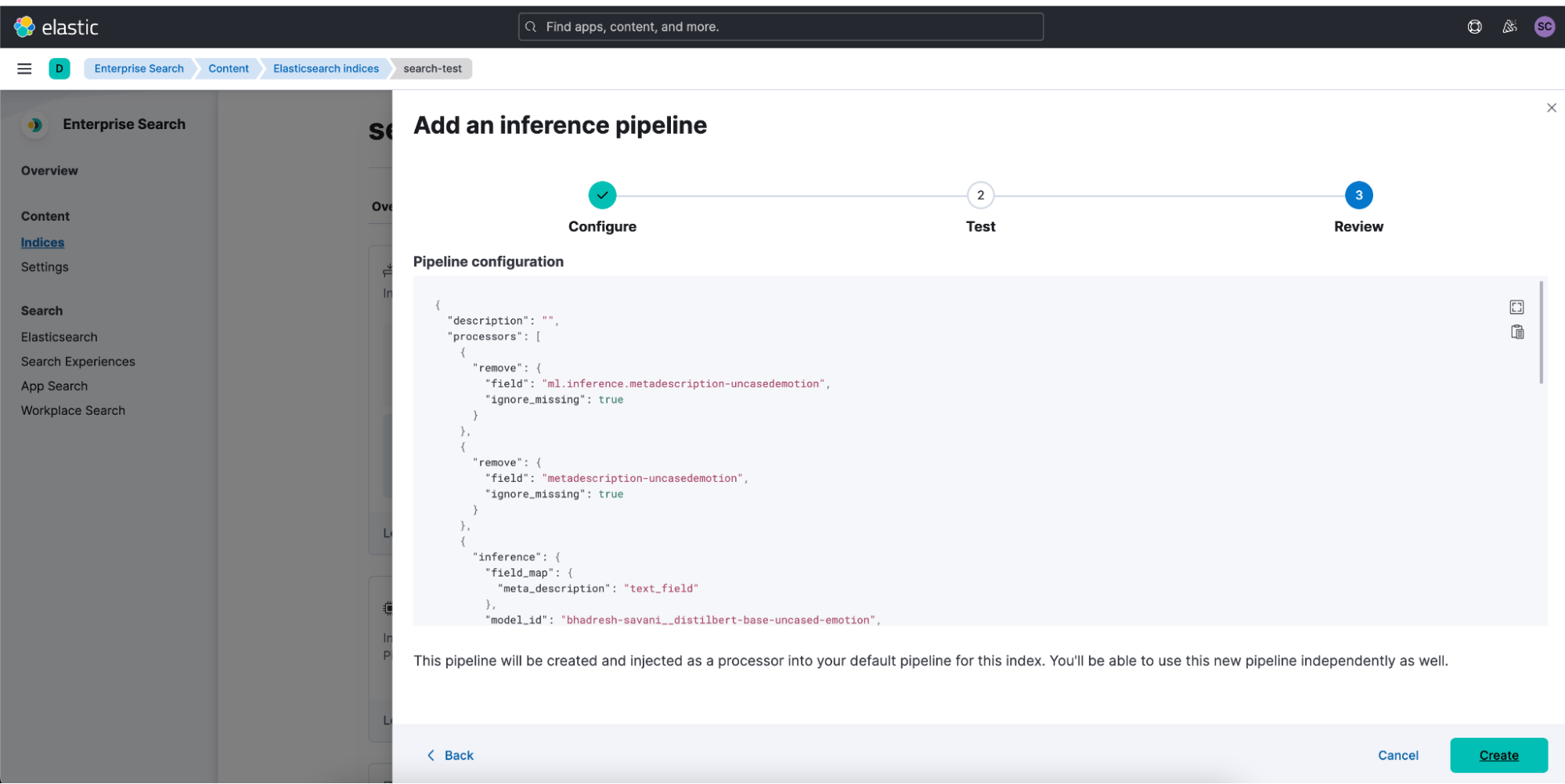
In 8.5, we defined ingestion pipelines to easily allow customers to plug in defined inference pipelines with their trained model of choice. 8.6 brings a continuation of this work to enable intuitive testing within the UI. Using these new management tools, users can now see a search optimized index’s inference history, logs with any errors, and the JSON config for easy editing. We’ve also added the ability for users to define a field for the ML model outputs to copy to as well as a confidence threshold.
It’s easier and faster than ever to set up searchable NLP outputs with high confidence values.
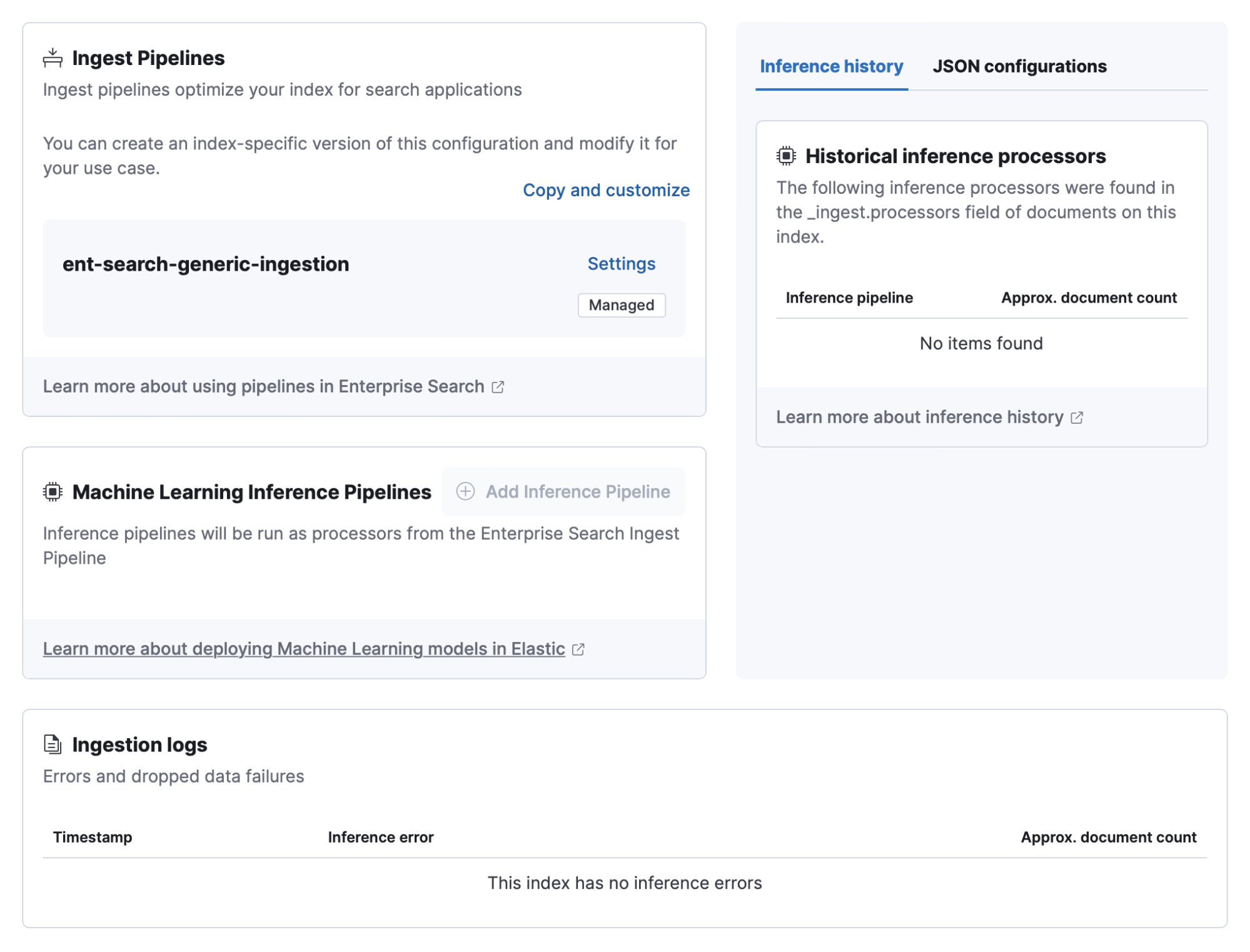
Click Copy and Customize to add any inference pipelines to analyze outcomes in your indexed data.
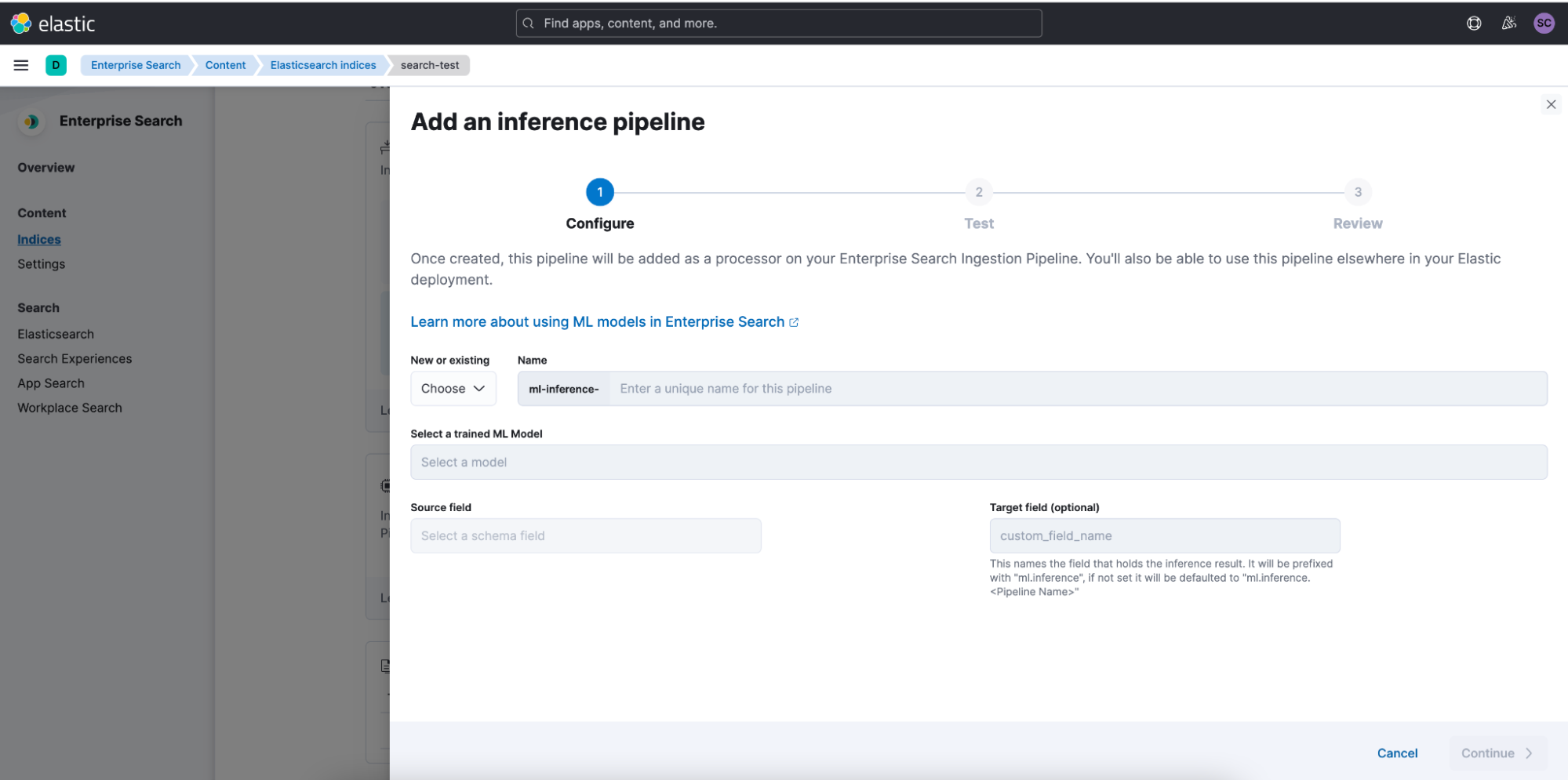
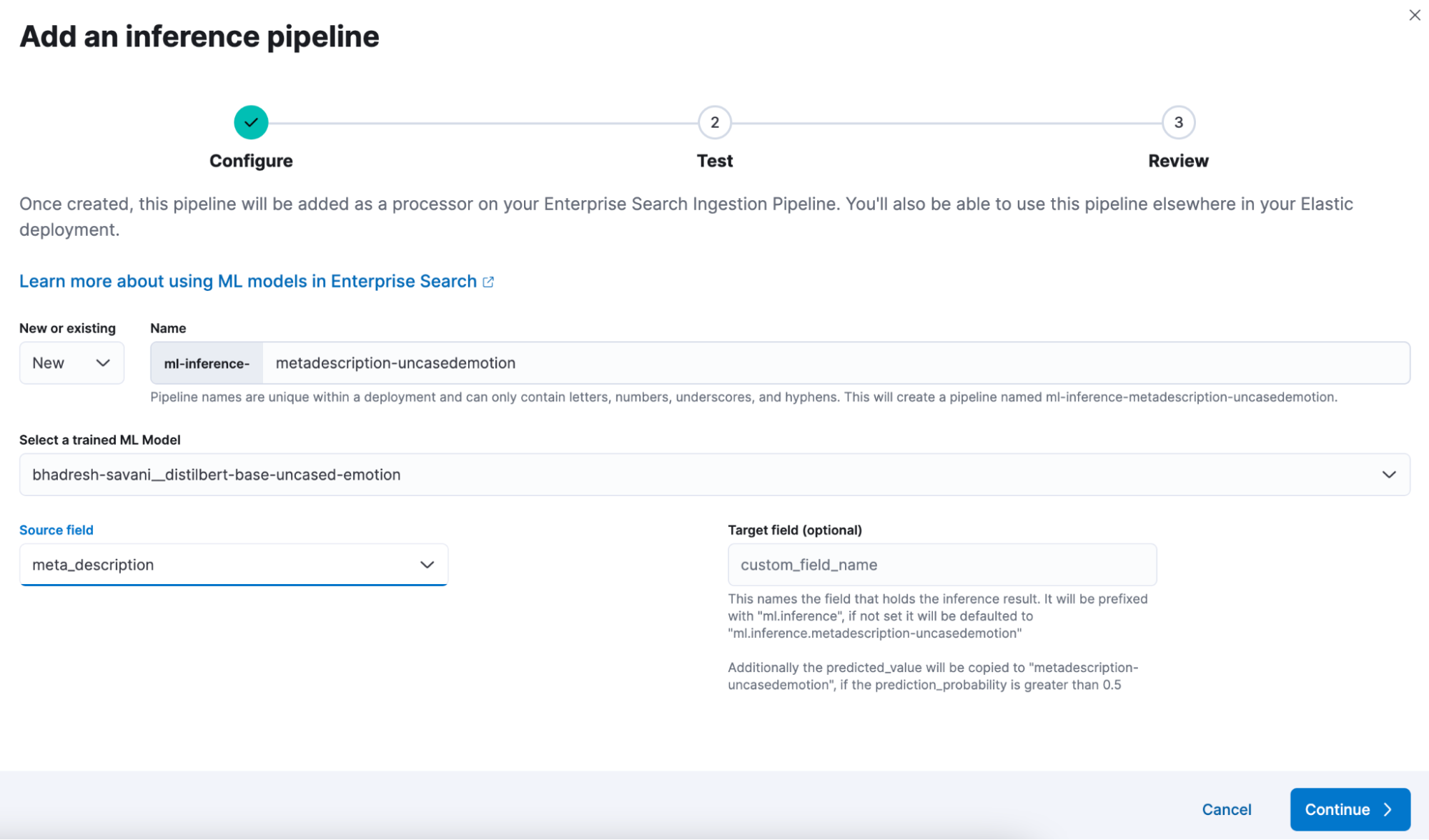
By adding your document and simulating the pipeline, you can quickly test the outcome that will be retrieved against the configured field without needing to wait for a reindex or sync of the searchable corpus.
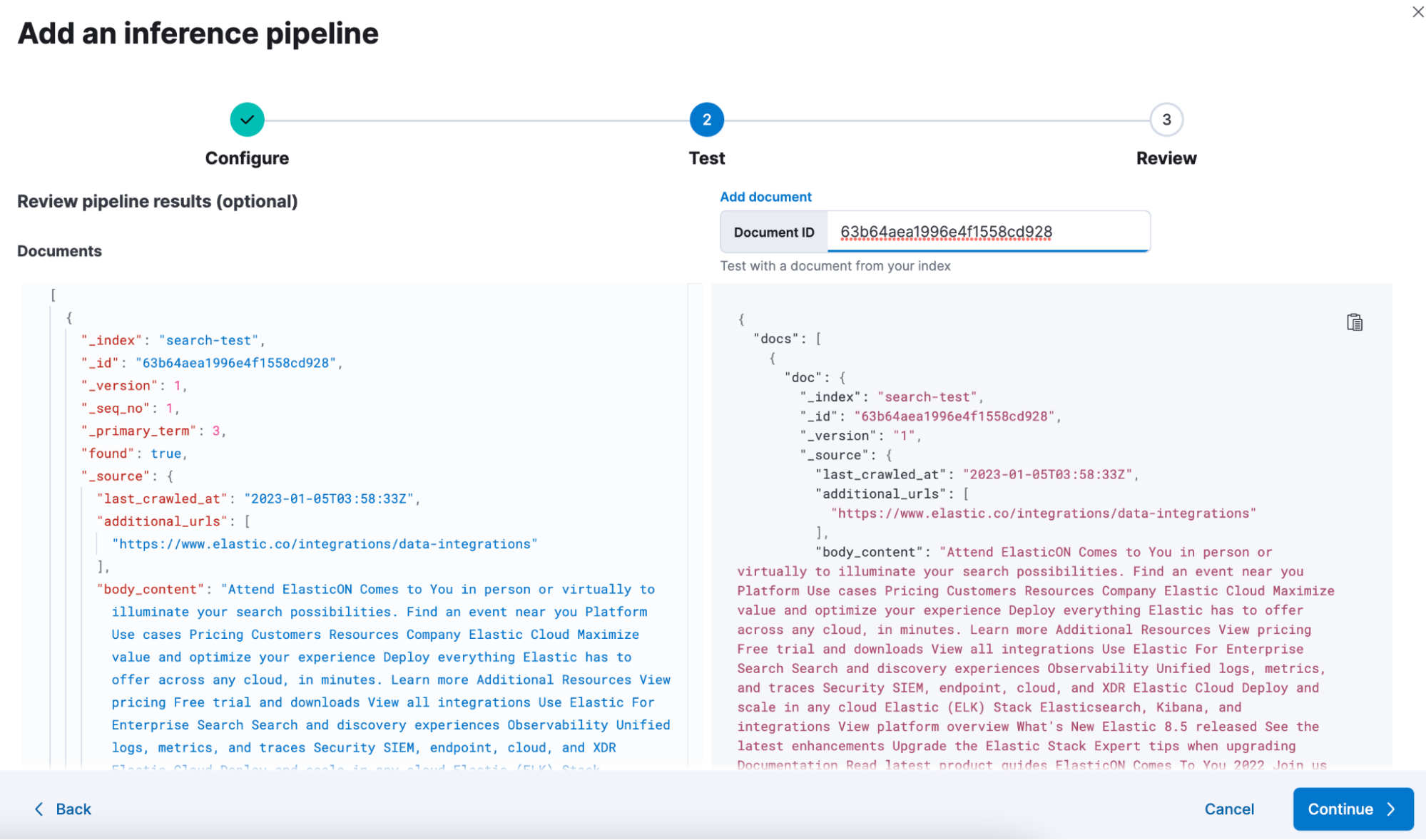
Scroll to see the difference between the previously indexed document and the simulated result from your inference pipeline.
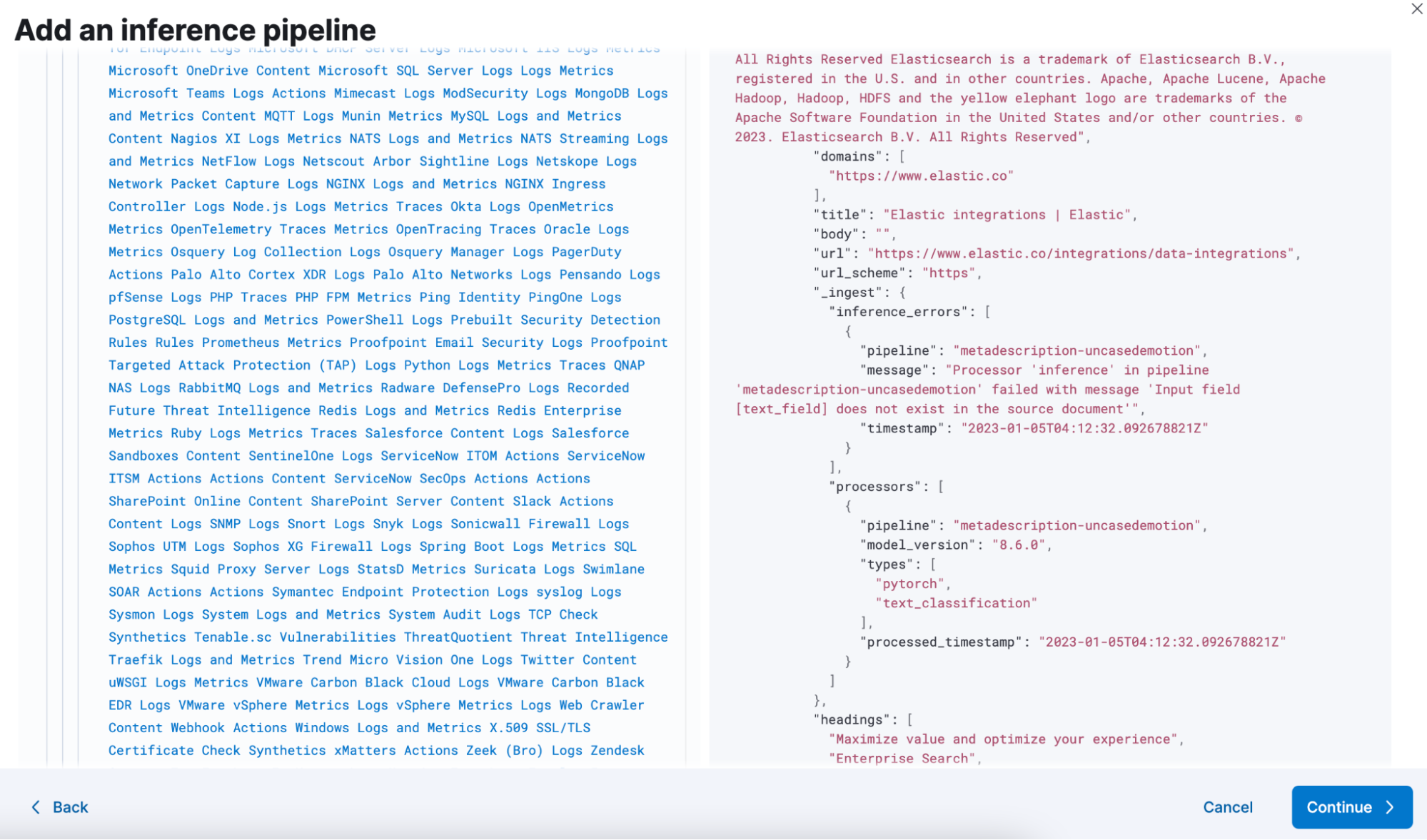
Once you’re satisfied with your changes, create this pipeline and then reuse it for other search optimized Elasticsearch indices.
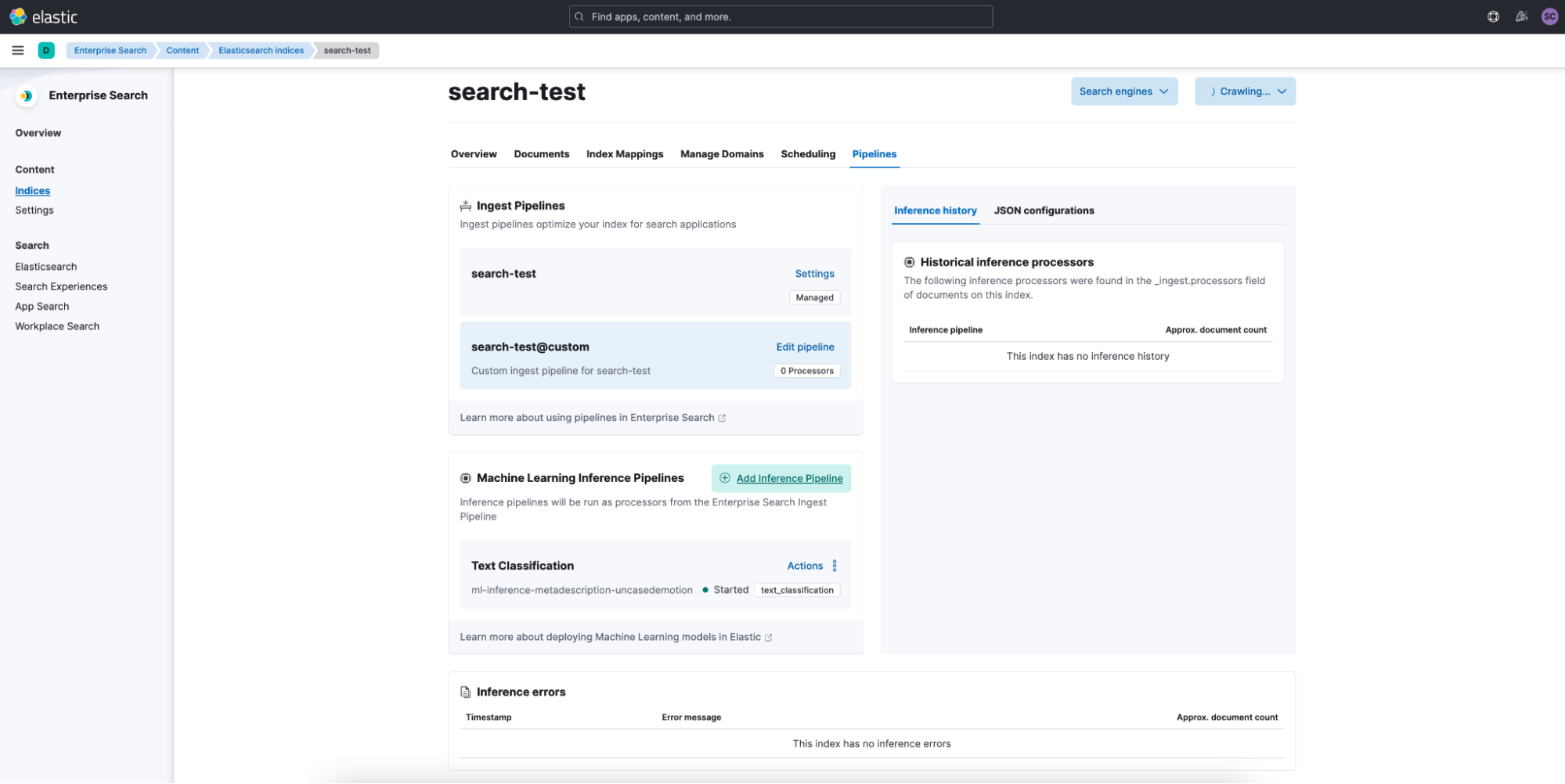
These tools are best used with our connectors and web crawler, and of course in Elastic Cloud.
Optimized search with MongoDB
As mentioned above, the life cycle for connectors begins with the client and matures to the native connector, which is completely hosted and supported in Elastic Cloud. In 8.5, our MongoDB connector formed the start of our native connector experience alongside our MySQL capabilities.
The 8.6 release brings greater control and precision on what is ingested. Using a combination of basic or advanced sync rules allows the user to harness the power of existing defined MongoDB aggregation pipelines. Keeping your operational data in Mongo with a scalable and performant search experience in Elastic with Enterprise Search brokering the sync between these systems allows you to keep these components focused on what they do best.
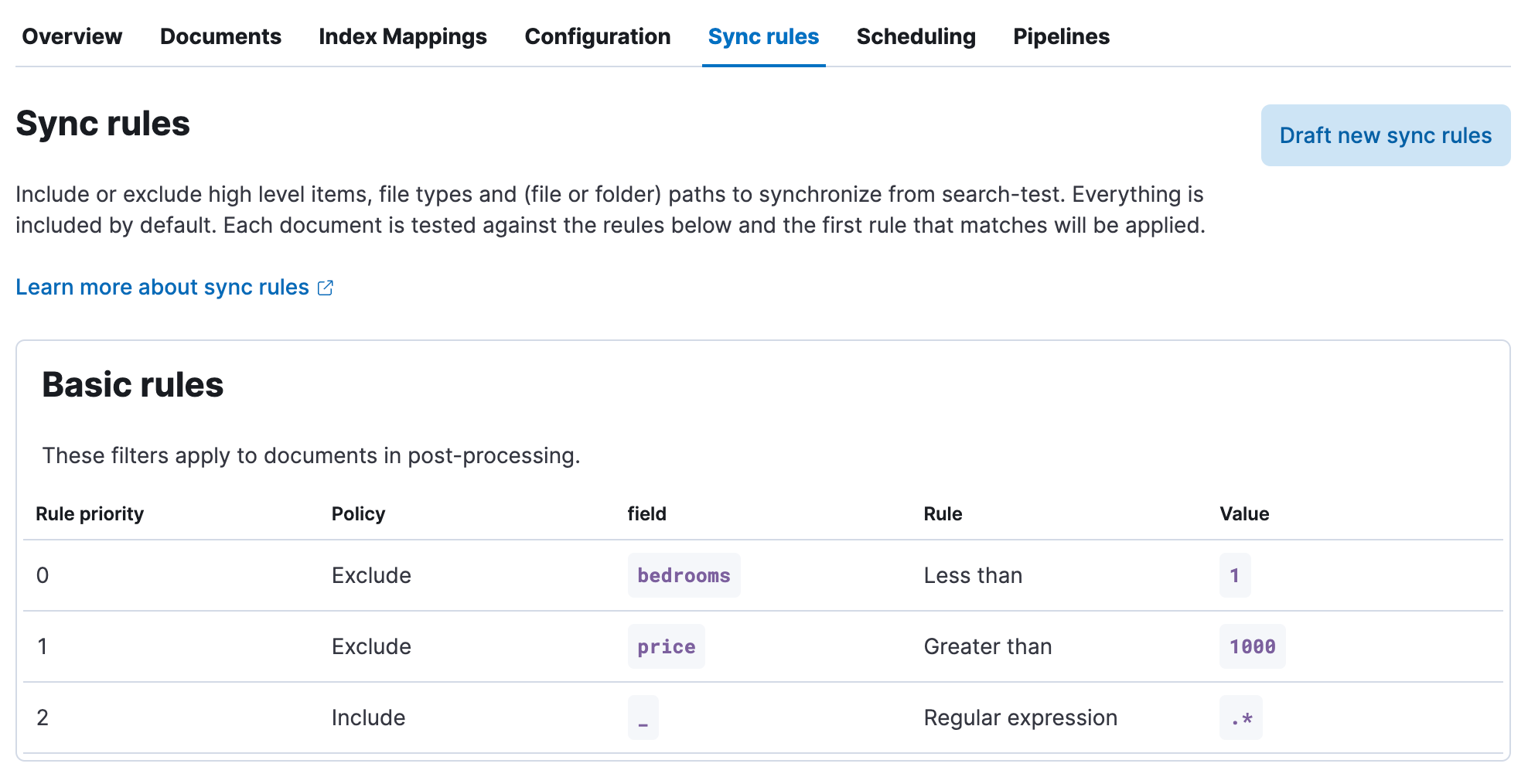
Your business may filter a dataset to only sync on listings in certain geographic regions using “Advanced rules.” The possibilities to tailor your search experience to your target consumer are endless.
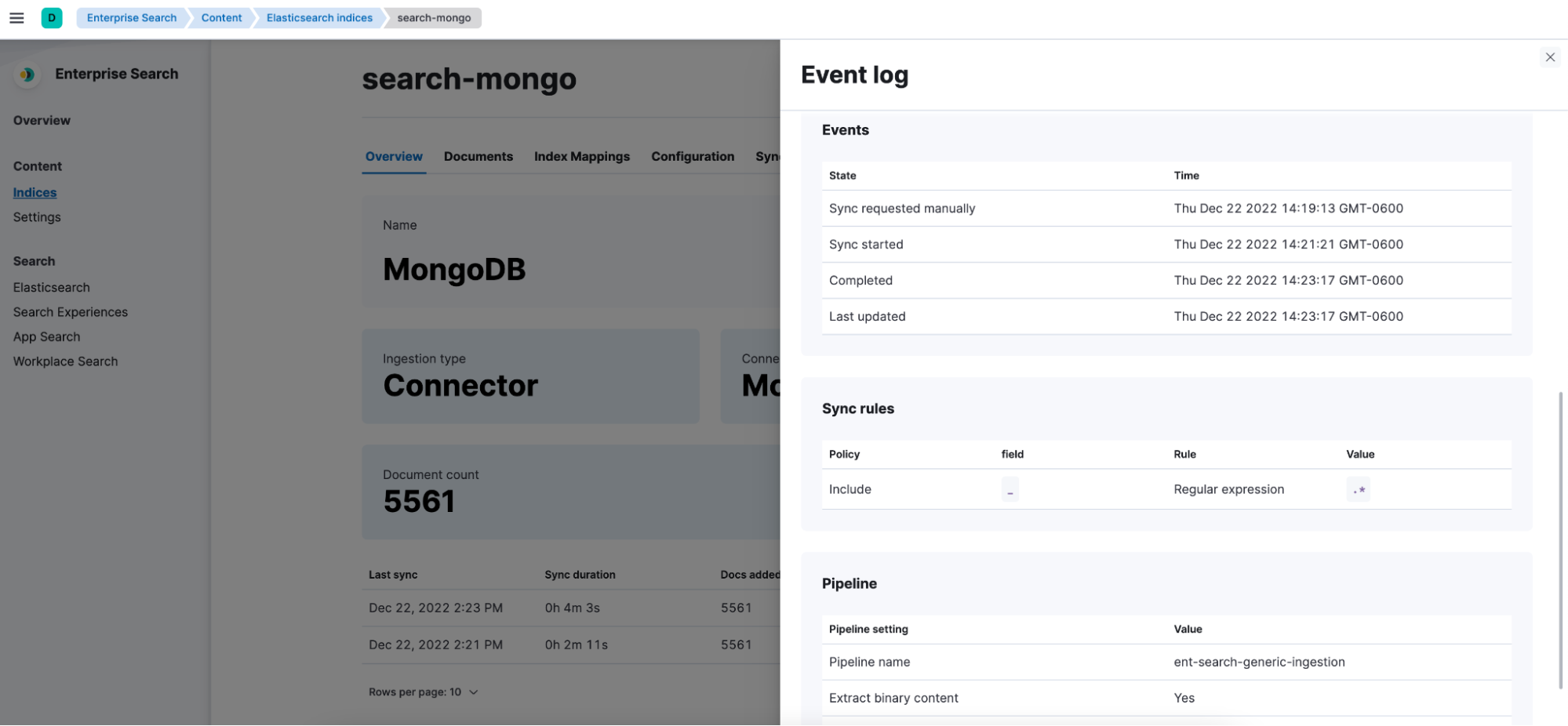
Enhanced visibility into sync jobs
Not only do administrators have additional control over what data is indexed, but we provide additional insight into the health of their connectors and the status of syncs. View the status, completion times, and more all in one simplified view.
Navigate to the Enterprise Search Content view to see the status of your syncs across your search optimized Elasticsearch indices.
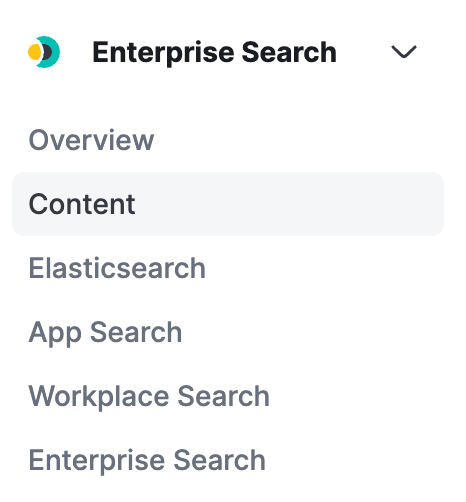
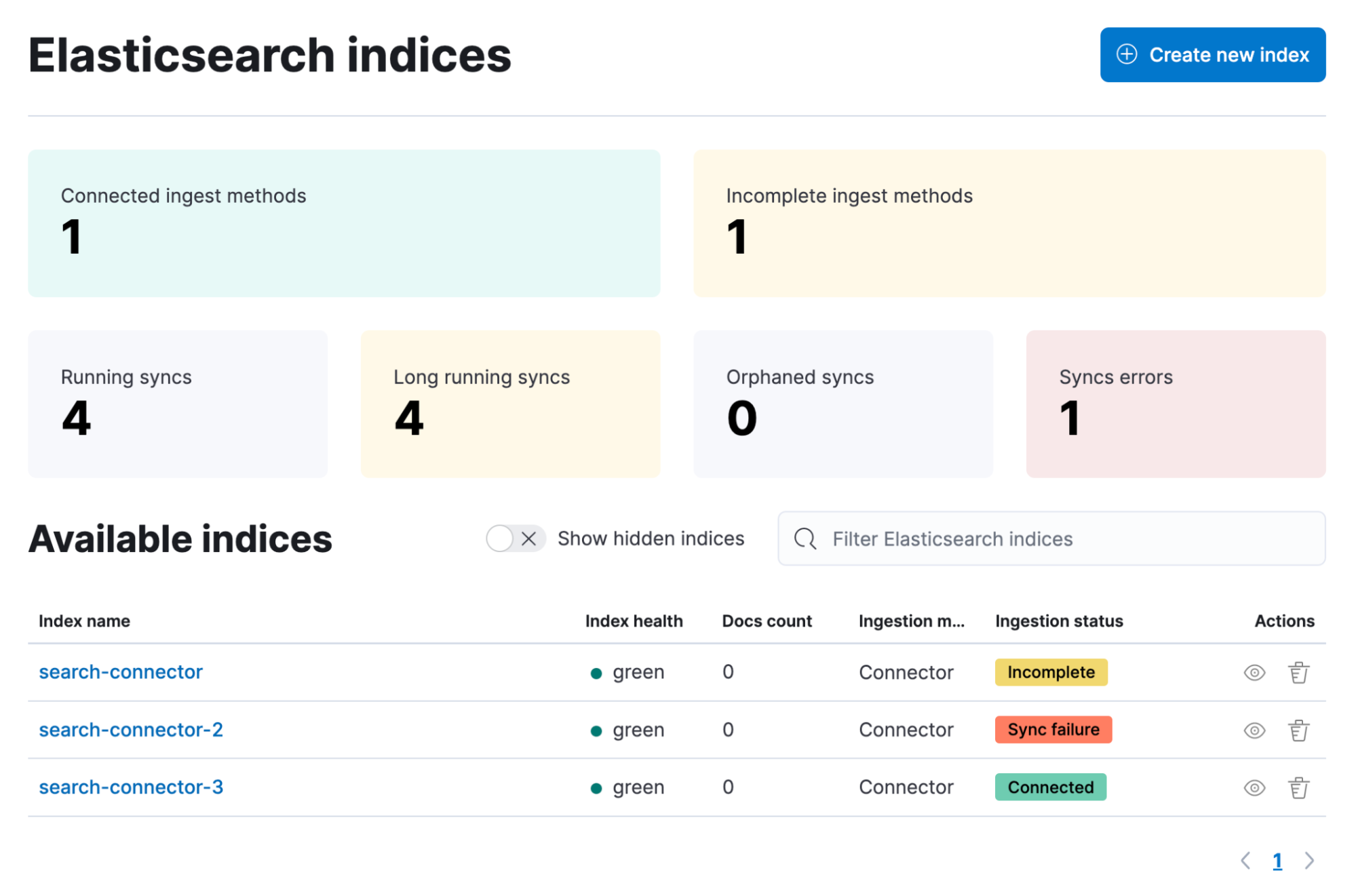
Clicking into the index Overview page will allow you to drill into the details of the most recent sync jobs per connector.
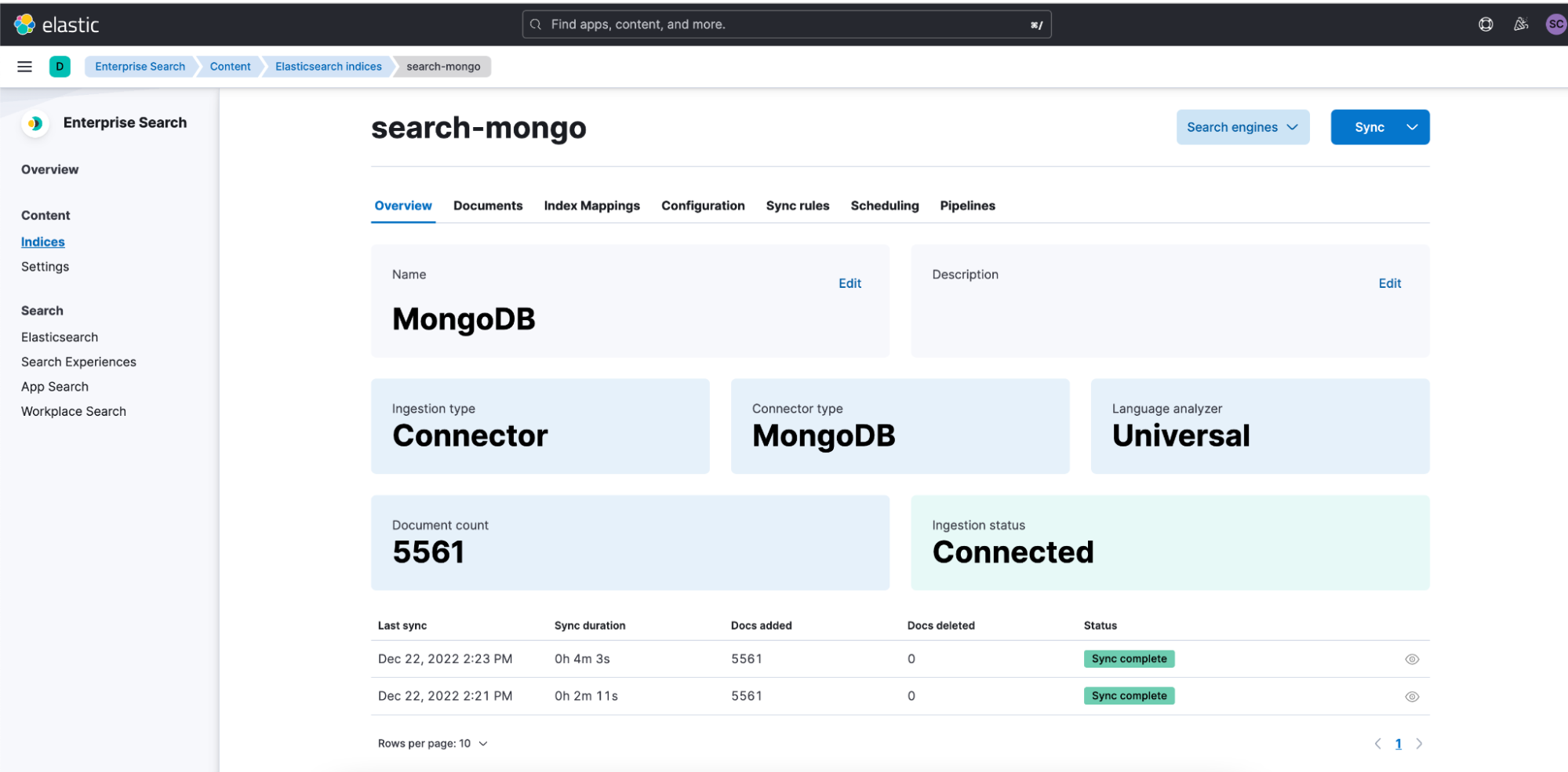
Clicking into the sync details gives you quick access to the document delta from this job.
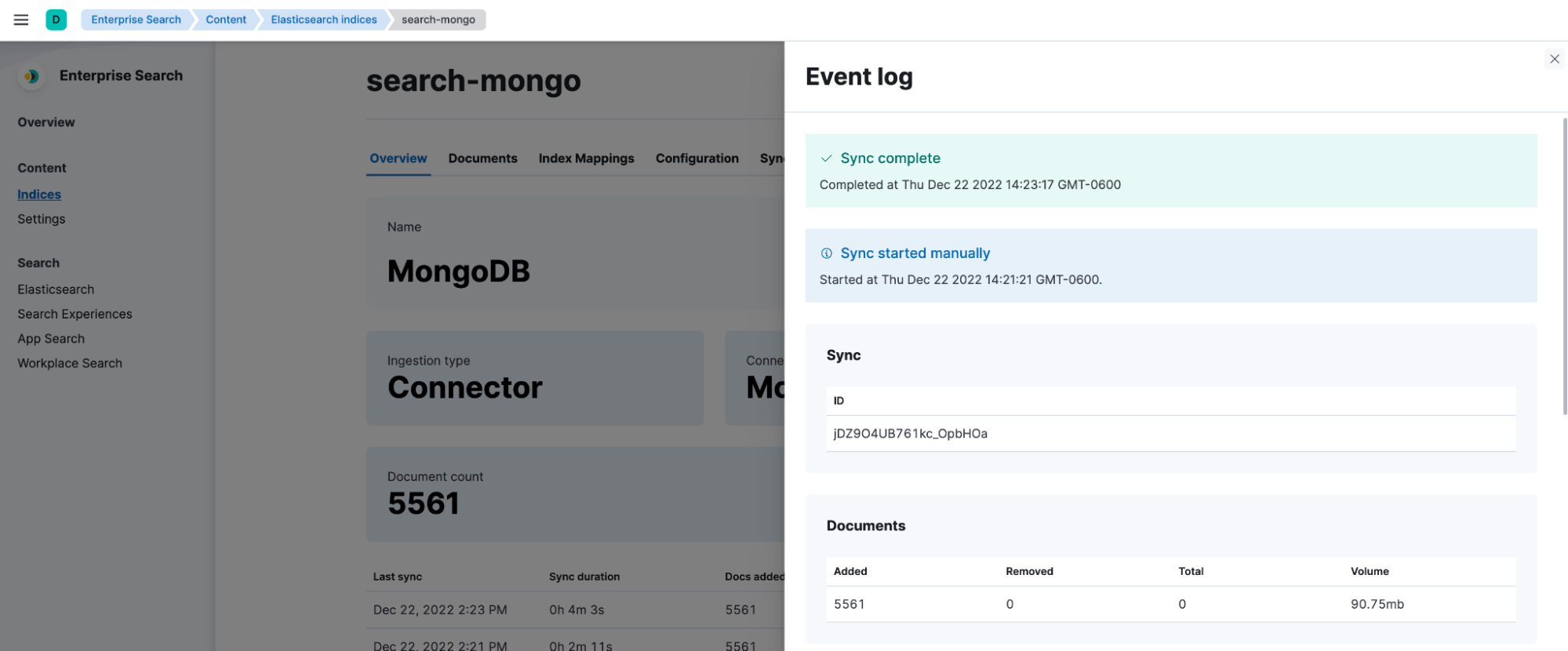
It also shows recent events and configured pipelines that can impact the state of your indexed data.
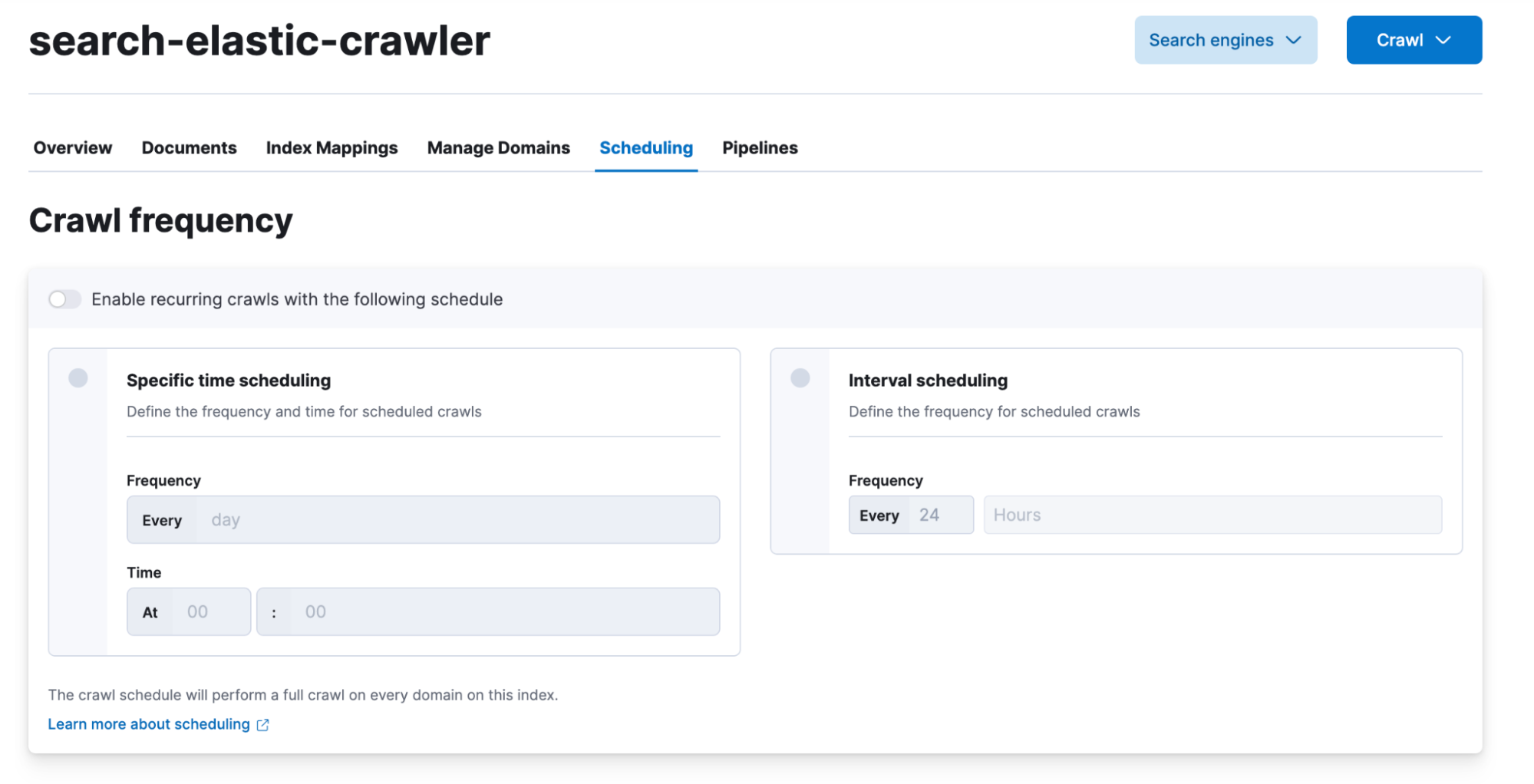
Web crawler
The Elastic web crawler now provides an additional scheduling option for customers needing to avoid specific time windows. This is an especially useful option when crawling a website with known high traffic time frames.
In addition, we have added a configurable option for customers looking to improve the speed of web crawls. Our tests have shown that this provides the best performance improvement for websites with large sets of binary content such as PDFs or Word documents. This can be enabled in Enterprise Search user settings for Elastic Cloud deployments.

With these improvements, fast crawls for highly volatile websites are easily accommodated and the path to relevant search is clear.
Try 8.6 today
Read about these capabilities and more in the release notes.
Existing Elastic Cloud customers can access many of these features directly from the Elastic Cloud console. Not taking advantage of Elastic on cloud? Start a free trial.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print