Monitoring Ihrer Anwendungen mit Elasticsearch and Elastic APM
Was ist APM?
Es empfiehlt sich, das Monitoring der Anwendungsleistung (Application Performance Monitoring, APM) im Zusammenhang mit den anderen Aspekten der Beobachtbarkeit, den Logs (Protokollen) und Infrastrukturkenndaten zu betrachten. Logs, APM und Infrastrukturkenndaten sind die drei Komponenten der Beobachtbarkeit:
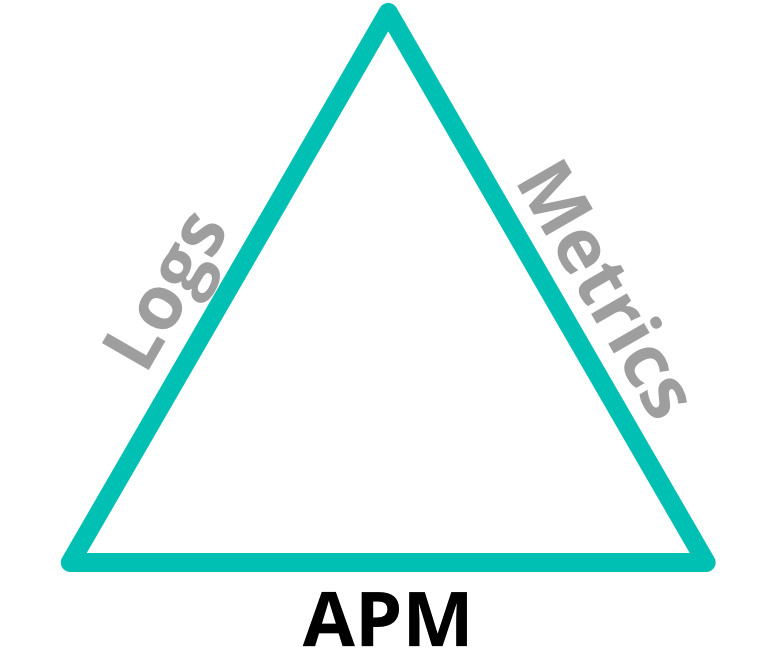
Diese Bereiche überschneiden sich – und zwar gerade genug, um eine Korrelation über jeden dieser Bereich hinweg zu unterstützen. In Logs werden zwar mögliche Fehlerereignisse aufgezeichnet, deren Ursache ist jedoch nicht unbedingt ersichtlich. Anhand der Kenndaten ist möglicherweise erkennbar, dass die CPU-Nutzung auf einem Server Spitzenwerte erreicht hat, nicht jedoch, wodurch dies hervorgerufen wurde. Die Kombination dieser Aspekte ermöglicht daher Lösungen für eine weitaus breitere Palette von Problemen.
Logs
Schauen wir uns zunächst einmal die Definitionen der Begriffe an. Zwischen Logs und Kenndaten besteht ein feiner, aber merklicher Unterschied. Im Allgemeinen repräsentieren Logs das Auftreten von Ereignissen: Eine Anforderung wird empfangen und auf die Anforderung wird reagiert, eine Datei wurde geöffnet, ein Befehl printf wurde im Code erkannt.
Ein gängiges Logformat stammt beispielsweise vom Apache HTTP-Serverprojekt (fake und gekürzt):
264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "GET /ESProductDetailView HTTP/1.1" 200 6291 264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "POST /intro.m4v HTTP/1.1" 404 7352 264.242.88.10 - - [22/Jan/2018:16:38:53 -0800] "POST /checkout/addresses/ HTTP/1.1" 500 5253
Logs sind meist nicht auf die gesamte Anwendung ausgerichtet, sondern auf die Komponentenebene. Ihr Vorteil besteht darin, dass sie in der Regel intuitiv verständlich sind. Im oben abgebildeten Beispiel sehen wir folgende Informationen: eine IP-Adresse, ein anscheinend nicht festgelegtes Feld, ein Datum, die Seite, auf die der Anwender zugegriffen hat, (sowie die verwendete Zugriffsmethode) und eine Reihe von Zahlen. Bei den Zahlen handelt es sich erfahrungsgemäß um den Antwortcode („200“ ist gut; „404“ ist nicht so gut wie „200“, aber besser als „500“) und die Menge der zurückgegebenen Daten.
Logs sind in der Regel auf der Instanz des Hosts, des Geräts oder des Containers verfügbar, auf der die dazugehörige Anwendung oder der entsprechende Dienst ausgeführt wird, und sie sind, wie oben ersichtlich, für Menschen verständlich. Hieraus ergibt sich jedoch auch der Nachteil der Logs: Ohne Kodierung wird nichts gedruckt. Für den Druck sind Befehle wie z. B. puts in Ruby oder system.out.println in Java erforderlich. Und selbst dann kommt es auf die Formatierung an. Die oben abgebildeten Apache-Logs weisen scheinbar ein merkwürdiges Datumsformat auf. Betrachten wir beispielsweise das Datum „01/02/2019“. Für mich in den USA bedeutet dies der 2. Januar 2019, doch in Großbritannien und anderswo wird dieses Datum als der 1. Februar 2019 interpretiert. Dinge dieser Art müssen bei der Formatierung von Logging-Anweisungen berücksichtigt werden.
Kenndaten
Bei Kenndaten handelt es sich meist um Zusammenfassungen für bestimmte Zeiträume oder Zählerstände: In den letzten 10 Sekunden betrug die durchschnittliche CPU-Nutzung 12 %, der von einer Anwendung belegte Speicherplatz betrug 27 MB oder die Kapazität des primären Datenträgers betrug 71 %.
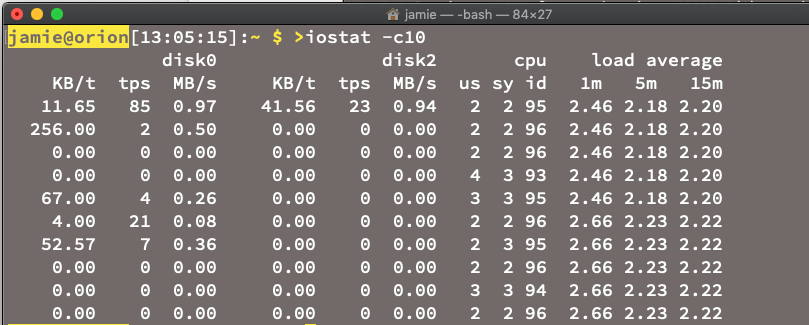
Im oben abgebildeten Screenshot wird die Ausführung von iostat auf einem Apple Mac dargestellt. Der Screenshot zeigt eine Vielzahl von Kenndaten. Kenndaten dienen zur Veranschaulichung von Trends und dem Verlauf. Sie sind besonders gut zur Erstellung von einfachen, vorhersagbaren und zuverlässigen Regeln geeignet, mit denen Vorfälle und Anomalien erfasst werden können. Ein Nachteil von Kenndaten besteht jedoch darin, dass sie meist zur Überwachung von Infrastrukturebenen dienen und Daten auf der Ebene der Komponenteninstanz erfassen – z. B. Hosts, Container und Netzwerk – statt auf der Ebene der benutzerdefinierten Anwendung. Da Kenndaten in der Regel über einen Zeitraum erfasst werden, besteht die Gefahr, dass kurze Ausreißer im Durchschnitt verloren gehen.
APM
Das Monitoring der Anwendungsleistung (Application Performance Monitoring, APM) schließt die Lücke zwischen den Kenndaten und den Logs. Während Logs und Kenndaten einen tendenziell größeren Querschnitt liefern und auf Infrastruktur und Komponenten ausgerichtet sind, liegt der Schwerpunkt von APM auf Anwendungen. Die IT und Entwickler erhalten so die Möglichkeit, die Anwendungsschicht ihres Stapels und damit auch die Benutzerfreundlichkeit zu überwachen.
APM bietet folgende Vorteile bei der Überwachung:
- Besseres Verständnis der Abläufe, mit denen der Dienst beschäftigt ist, sowie der Ursache für dessen Absturz
- Darstellung der Interaktion von Diensten sowie Veranschaulichung von Engpässen
- Proaktive Ermittlung und Behebung von Leistungsengpässen und Fehlern
- Hoffentlich, bevor zu viele Ihrer Kunden davon betroffen sind.
- Steigerung der Produktivität Ihres Entwicklungsteams
- Nachverfolgung der Benutzerfreundlichkeit im Browser
Wichtiger Hinweis: APM verwendet Code (hierzu gleich mehr).
Vergleichen wir nun APM mit den Informationen aus den Logs. Der Logeintrag sah wie folgt aus:
264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "GET /ESProductDetailView HTTP/1.1" 200 6291
Auf den ersten Blick sah dieser Eintrag gut aus. Wir haben erfolgreich geantwortet (200) und 6291 Byte zurückgesendet. Anders als auf dem folgenden APM-Screenshot wird im Log jedoch nicht angezeigt, dass die Reaktionszeit 16,6 Sekunden betragen hat.
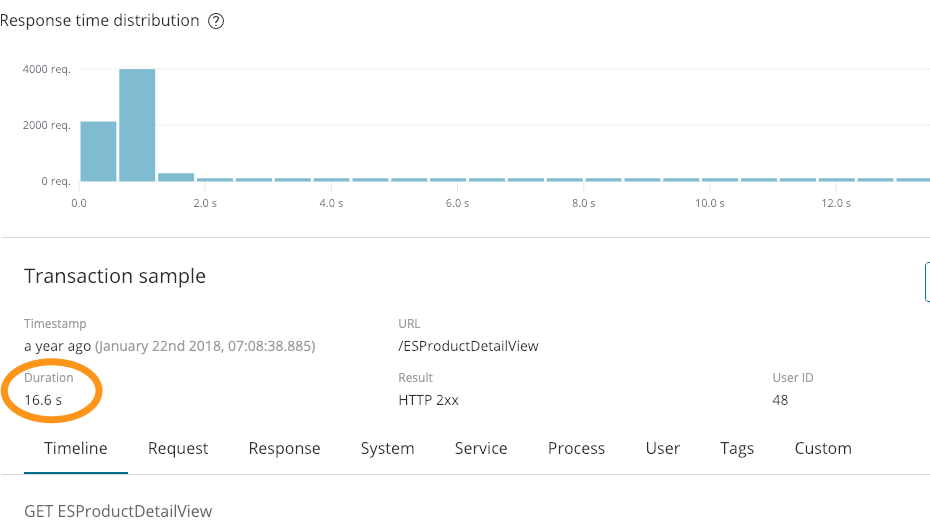
Diese zusätzlichen Kontextinformationen sind sehr nützlich. In den oben abgebildeten Logs ist auch ein Fehler verzeichnet:
264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "POST /checkout/addresses/ HTTP/1.1" 500 5253
Fehler werden auch von APM erfasst:
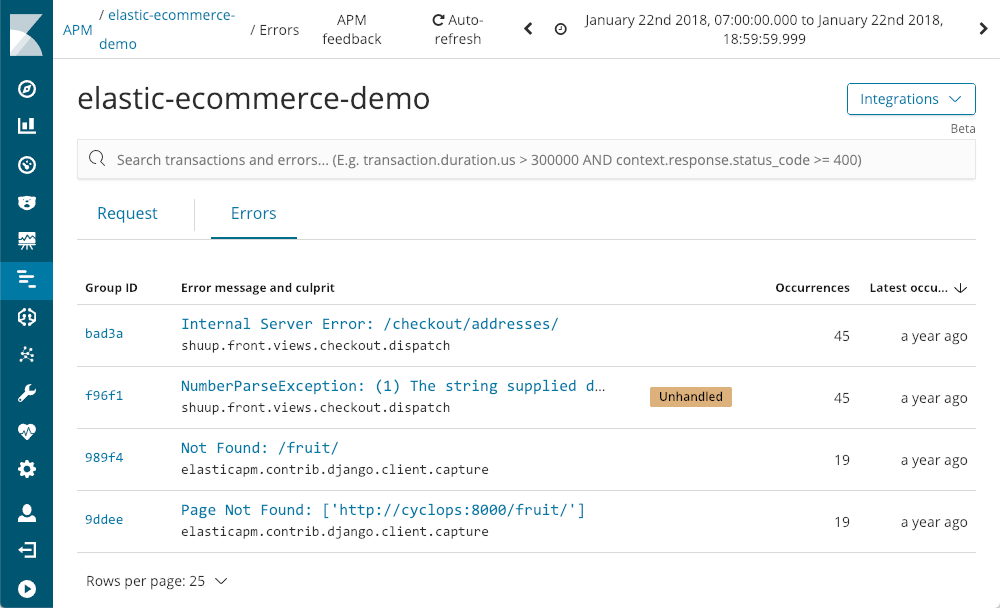
Es wird angezeigt, wann die Fehler zuletzt aufgetreten sind, wie oft sie aufgetreten sind und ob sie von der Anwendung behoben wurden. Wenn wir Detailinformationen zu einer Ausnahme aufrufen (z. B. unter Verwendung von NumberParseException), wird die Verteilung der Anzahl der aufgetretenen Fehlerereignisse im Fenster grafisch dargestellt:
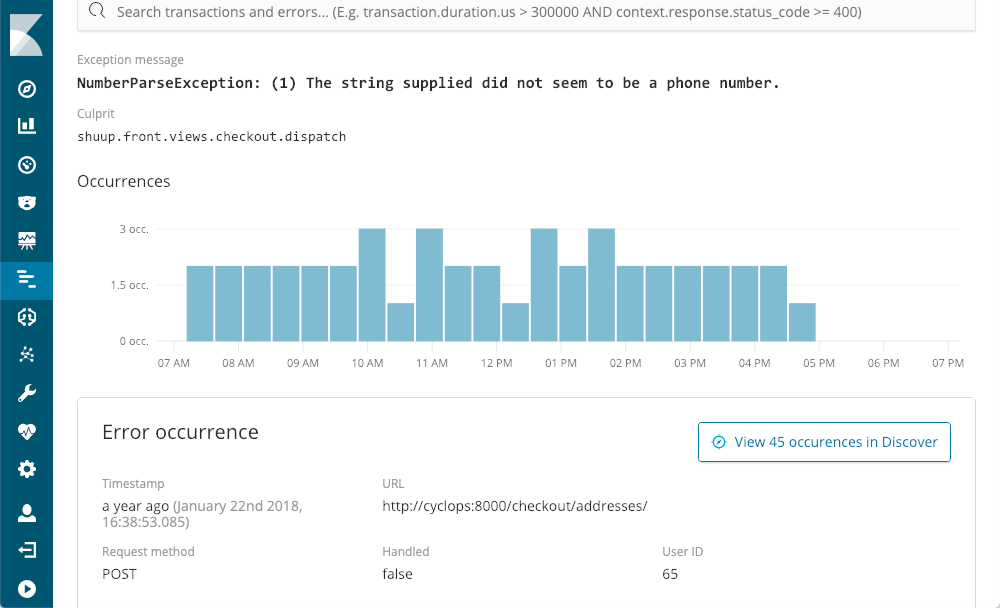
Wir können sofort erkennen, dass der Fehler in den einzelnen Zeiträumen einige Male aufgetreten ist, insgesamt gesehen jedoch den ganzen Tag lang. Wahrscheinlich ist der entsprechende Stacktrace in einem der Logdateien auffindbar, doch dann fehlen meist Kontext und Metadaten, die bei Verwendung von APM verfügbar sind.
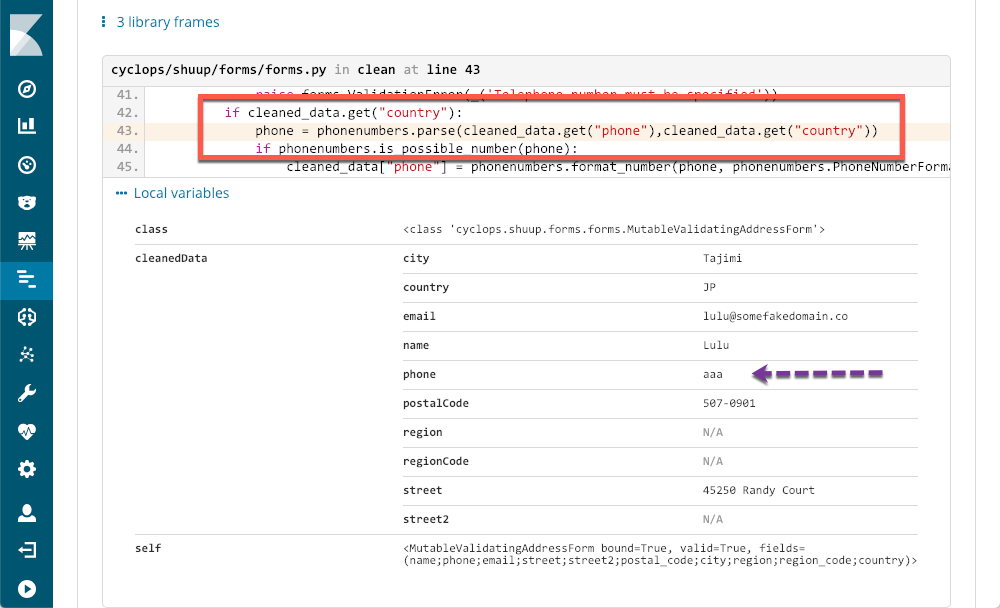
Die Zeile des Codes, von der die Ausnahme verursacht wurde, ist durch ein rotes Rechteck gekennzeichnet. Anhand der von APM bereitgestellten Metadaten lässt sich das Problem genau identifizieren. Selbst jemand, der keine Erfahrung mit Python-Programmierung hat, kann das Problem genau erkennen und verfügt über genügend Informationen, um ein Ticket zu öffnen.
APM in der Praxis (mit Screenshots)
Genug der Theorie, schauen wir uns nun APM in der Praxis an.
Öffnen von APM
Wenn wir in Kibana auf die APM-Anwendung zugreifen, werden alle Dienste angezeigt, die wir mit Elastic APM instrumentiert haben:
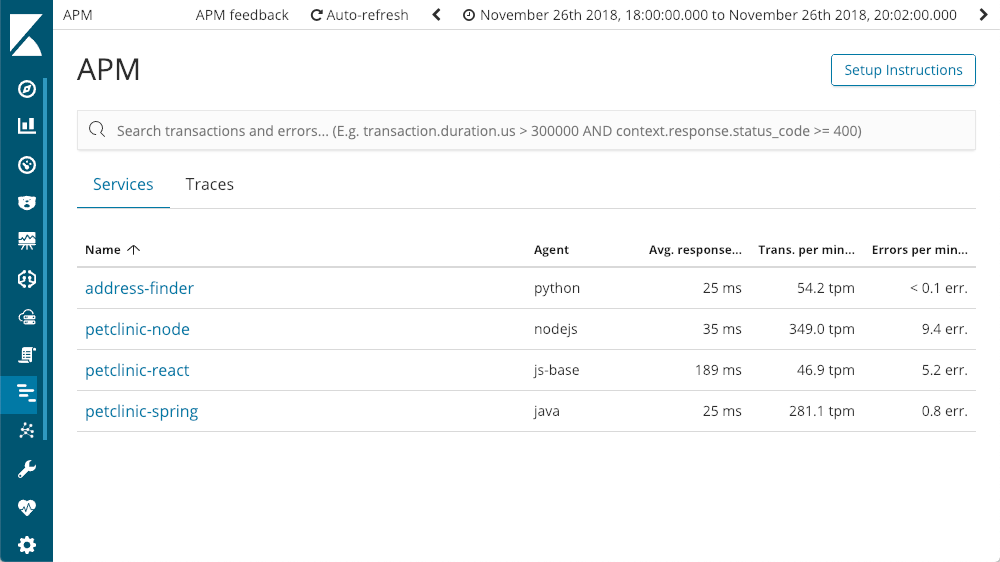
Detailinformationen zu den Diensten
Wir können uns Detailinformationen zu den einzelnen Diensten anzeigen lassen. Schauen wir uns einmal den Dienst „petclinic-spring“ an. Für die einzelnen Dienste wird ein ähnliches Layout angezeigt:
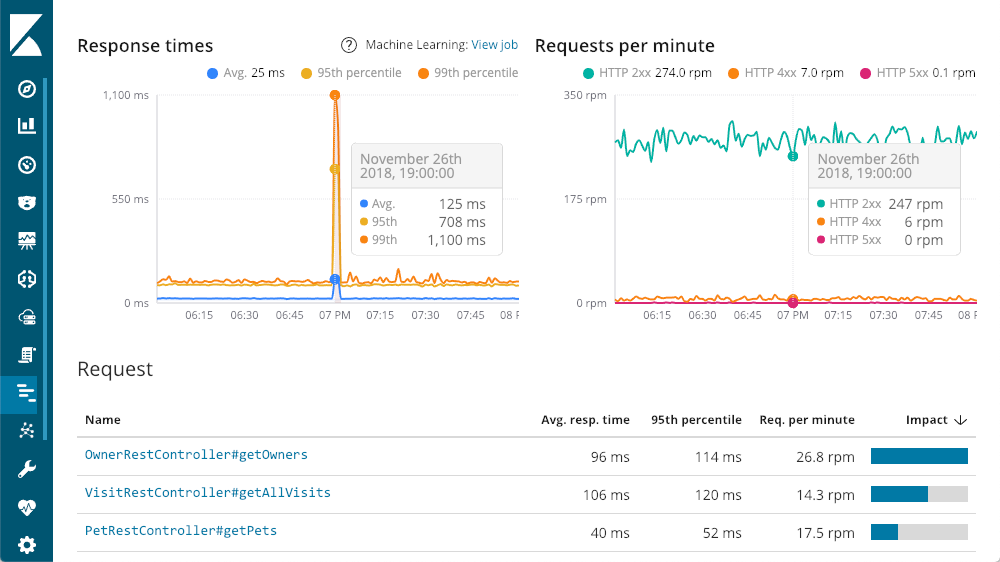
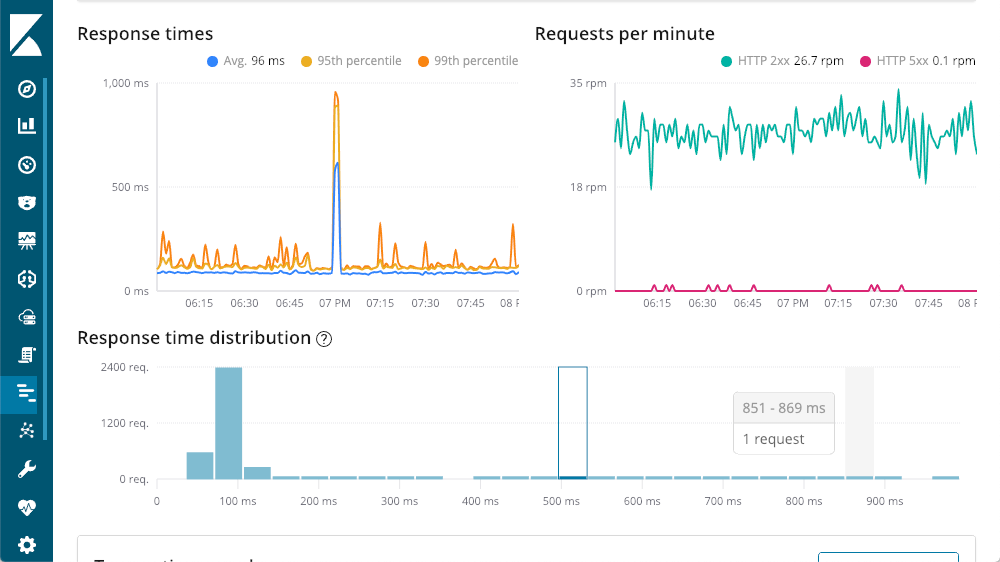
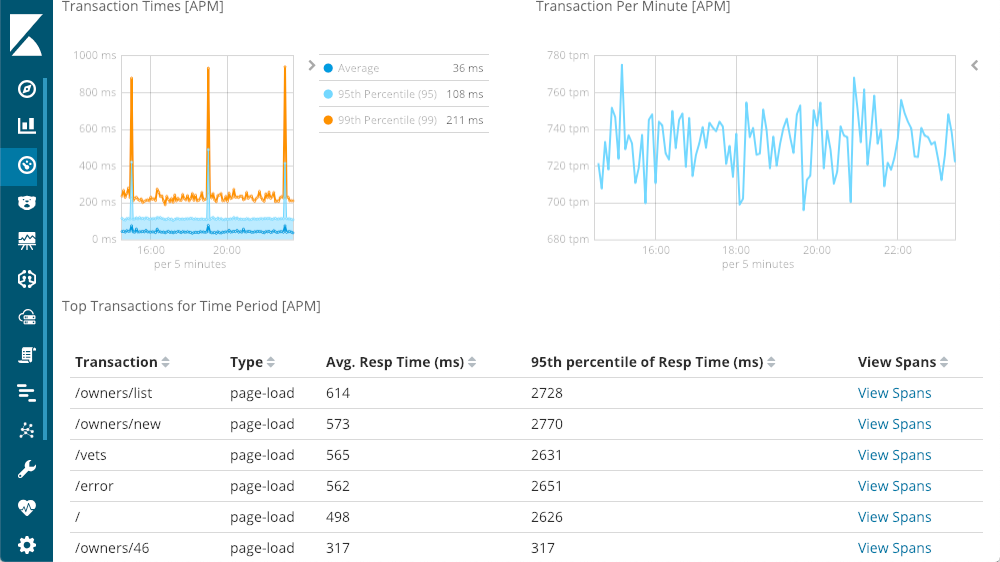
In der linken oberen Ecke werden die Reaktionszeiten angezeigt: Durchschnitt, 95. und 99. Perzentil. Daran lässt sich erkennen, wo die Ausreißer liegen. Es ist auch möglich, verschiedene Zeilenelemente ein- oder auszublenden. So wird klar ersichtlich, wie sich die Ausreißer auf das gesamte Diagramm auswirken. In der rechten oberen Ecke werden meine Antwortcodes angezeigt: Diese sind nicht in Zeiten, sondern in Anforderungen pro Minute (Requests Per Minute, RPM) untergliedert. Wie im Diagramm ersichtlich, wird ein Popup mit einer Zusammenfassung des jeweiligen Zeitpunkts eingeblendet, wenn der Mauszeiger über eines der beiden Diagramme bewegt wird. Schon bevor wir uns mit den Detailinformationen beschäftigen, ist auf den ersten Blick klar: Zu dem riesigen Spike in der Latenz gibt es keine 500 Antworten (Serverfehler).
Detailinformationen zu den Reaktionszeiten für Transaktionen
Im unteren Bereich der Transaktionszusammenfassung wird eine Aufschlüsselung der Anforderungen angezeigt. Jede Anforderung ist im Grunde genommen ein unterschiedlicher Endpunkt in unserer Anwendung (obwohl die Standards auch mithilfe der verschiedenen Agent-API erweitert werden können). Die Sortierung kann nach den Spaltenüberschriften erfolgen, doch ich persönlich bevorzuge die Spalte „Impact“ (Auswirkung), in der die Latenz und die Beliebtheit einer bestimmten Anforderung berücksichtigt wird. In diesem Beispiel scheint „getOwners“ zwar die meisten Probleme zu verursachen, weist jedoch im Durchschnitt immer noch eine ziemlich respektable Latenz von 96 ms auf. Wenn wir uns die Detailinformationen dieser Transaktion anzeigen lassen, sehen wir das gleiche Layout wie zuvor:
Wasserfallansicht der Vorgänge
Selbst für die langsamsten Anforderungen wird weniger als eine Sekunde benötigt. Mit einem Bildlauf nach unten gelangen wir zur Wasserfallansicht der Vorgänge in der Transaktion:
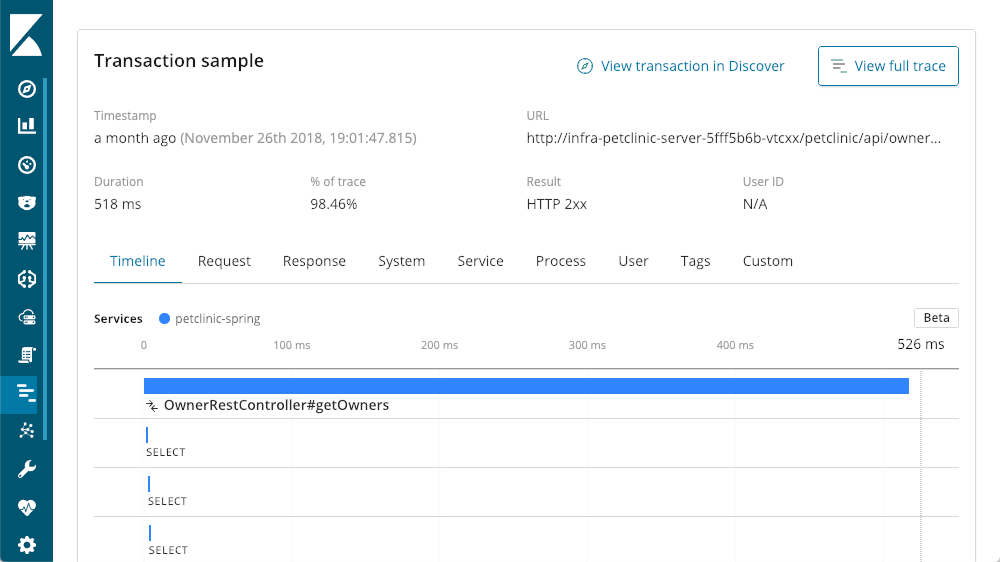
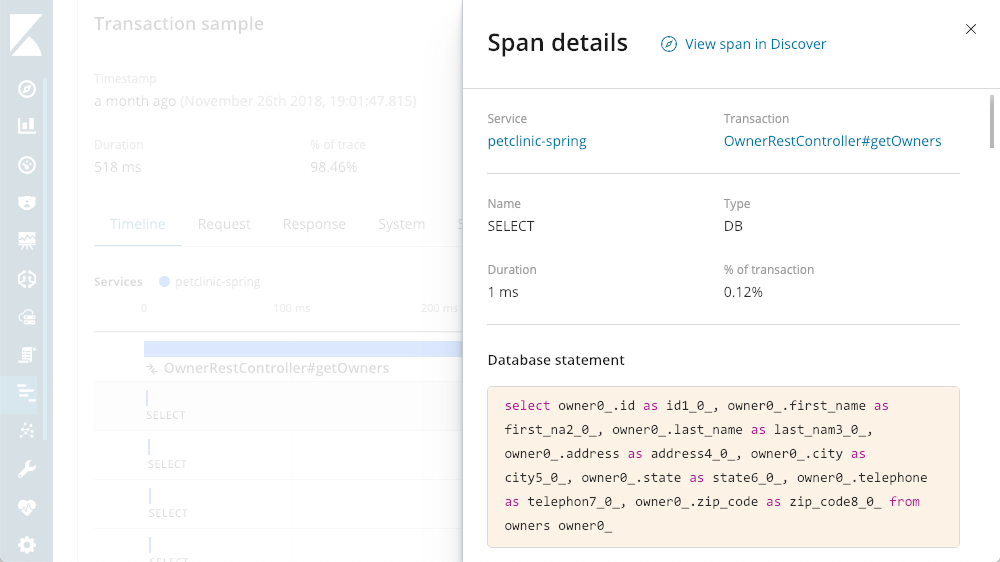
Abfragedetail-Viewer
Es ist sicherlich eine Vielzahl von SELECT-Anweisungen vorhanden. APM ermöglicht es, die Abfragen während ihrer Ausführung zu betrachten:
Verteiltes Tracing
Dieser Anwendungsstapel verfügt über eine mehrstufige Microservicearchitektur. Da alle Ebenen mit Elastic APM instrumentiert sind, kann die Ansicht über die Schaltfläche „View full trace“ (Umfassendes Tracing anzeigen) verkleinert werden, um diesen Aufruf als Ganzes zu betrachten. Es wird ein verteiltes Tracing aller an dieser Transaktion beteiligten Komponenten angezeigt:
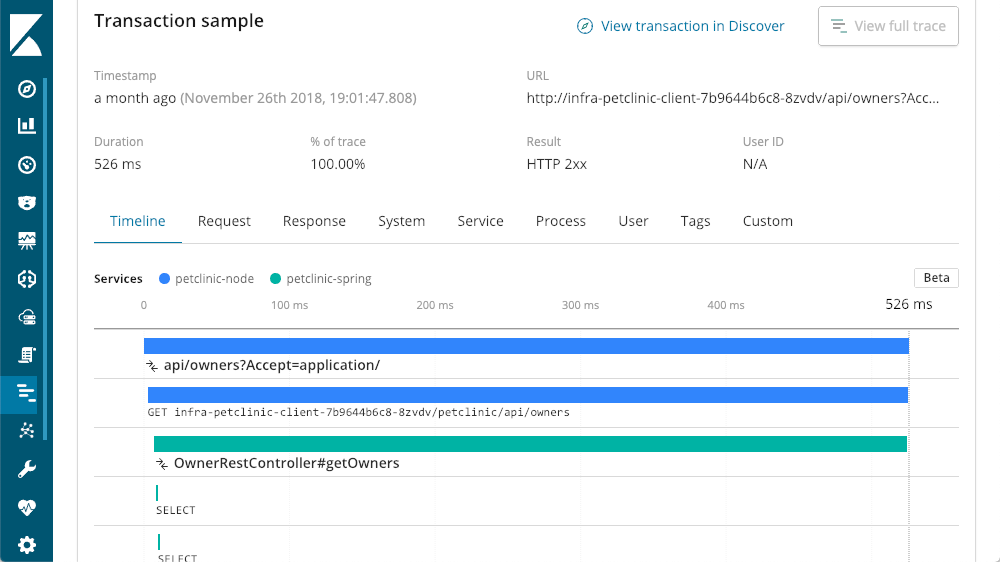
Tracingebenen
In unserem Beispiel haben wir mit der Ebene „Spring“ begonnen. Hierbei handelt es sich um einen Dienst, den die anderen Ebenen aufrufen. Wir können nun erkennen, dass „petclinic-node“ die Ebene „petclinic-spring“ aufgerufen hat. Dies sind nur zwei Ebenen, wir können jedoch viele weitere Ebenen sehen. In diesem Beispiel sehen wir eine Anforderung, die von der Browserebene (React) aus gestartet wurde:
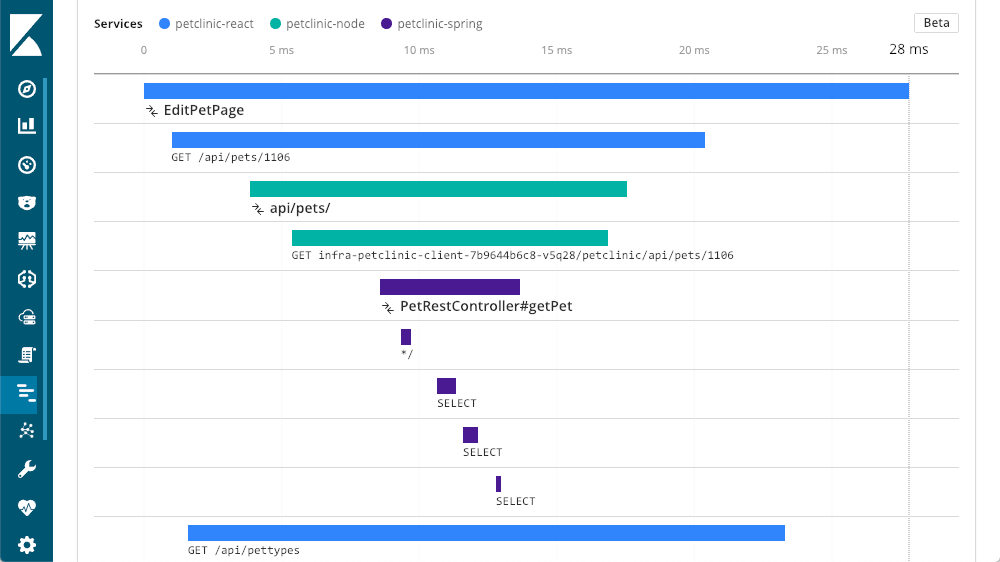
Nutzerüberwachung
Es ist wichtig, so viele Komponenten und Dienste wie möglich zu instrumentieren, um das verteilte Tracing optimal nutzen zu können. Hierzu gehört auch der wirksame Einsatz der Nutzerüberwachung (Real User Monitoring, RUM). Schnelle Reaktionszeiten der Dienste für sich genommen bedeuten noch keine schnelle Ausführung im Browser. Es ist wichtig, die Benutzerfreundlichkeit im Browser feinabzustimmen. In diesem verteilten Tracing werden vier unterschiedliche Dienste dargestellt, die zusammenarbeiten. Hierzu gehören der Webbrowser (der Client) sowie mehrere Dienste. Nach 53 ms war die Analyse des gesamten HTML-Codes im Browser und nach 67 ms war die DOM-Erstellung abgeschlossen (Zeitstempel: domInteractive).
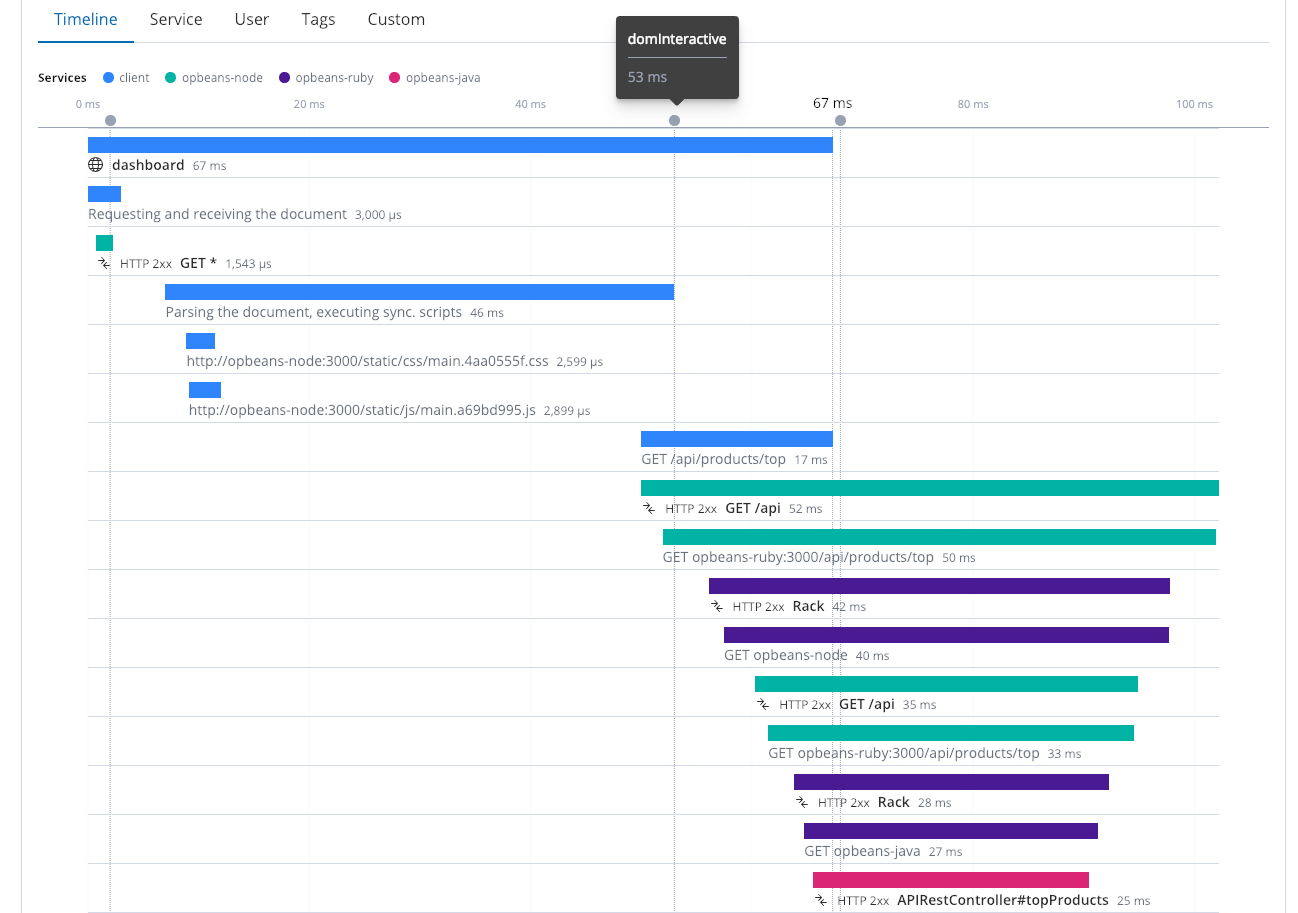
Mehr als nur eine schöne Benutzeroberfläche
Elastic APM bietet viel mehr als nur eine sofort einsatzfähige und auf Anwendungsentwickler zugeschnittene APM-Benutzeroberfläche und auch die Datenunterstützung dient nicht nur dieser Benutzeroberfläche. Tatsächlich besteht einer der wesentlichen Vorteile der Elastic APM-Daten einfach darin, dass sie als ein weiterer Index dienen. Die Informationen stehen neben Ihren Logs, Kenndaten und sogar Geschäftsdaten bereit, sodass sofort erkennbar ist, wie sich eine Drosselung des Servers auf Ihre Umsätze auswirkt. APM-Daten können auch dazu genutzt werden, die nächsten Verbesserungen am Code zu planen (Tipp: Schauen Sie sich die Anforderungen mit der größten Auswirkung an).
APM wird mit Standardvisualisierungen und -dashboards ausgeliefert, die dann mit Visualisierungen aus Logs, Kenndaten oder sogar aus unseren Geschäftsdaten kombiniert werden können.
Erste Schritte mit Elastic APM
Elastic APM kann parallel zu Logstash und Beats ausgeführt werden und verwendet eine ähnliche Deploymenttopologie:
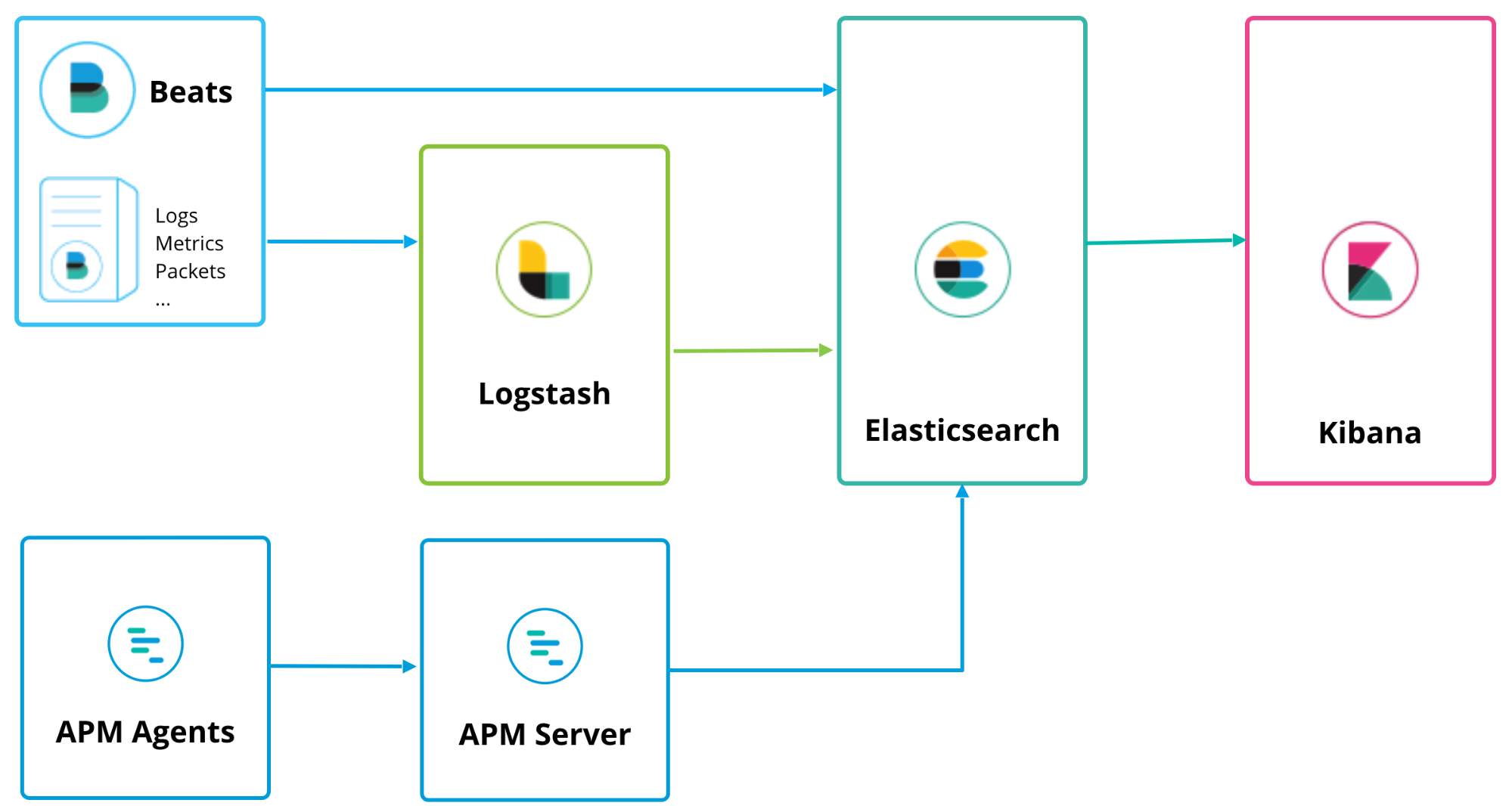
Der APM-Server fungiert als ein Datenprozessor, mit dem APM-Daten von APM-Agents an Elasticsearch weitergeleitet werden. Die Installation ist denkbar einfach und wird in der Dokumentation auf der Seite „Install and Run“ (Installieren und Ausführen) erläutert. Alternativ können Sie auch einfach auf das „K“-Logo in Kibana klicken, um die Kibana-Startseite aufzurufen. Dort wird die Option „Add APM“ (APM hinzufügen) angeboten:
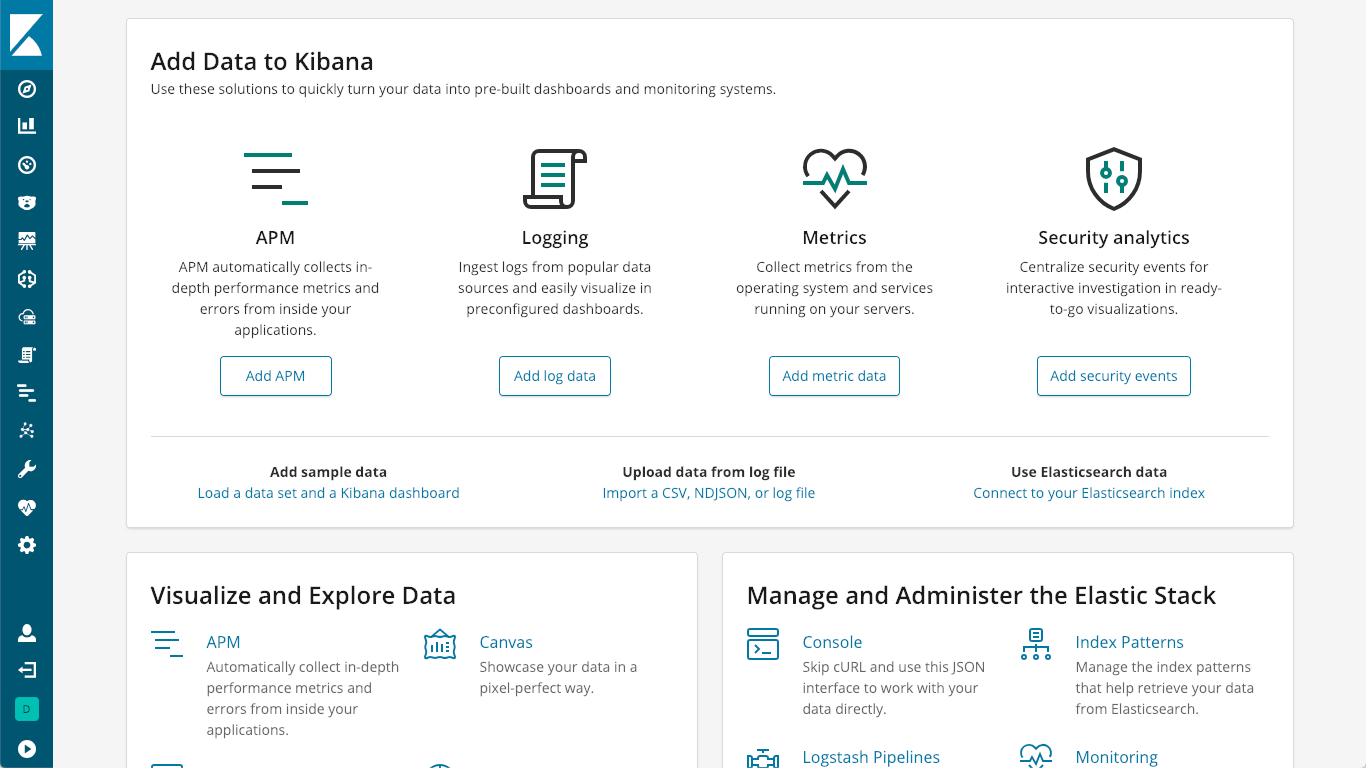
Mit dieser Option werden Sie schrittweise durch die Einrichtung und den Start eines APM-Servers geführt:
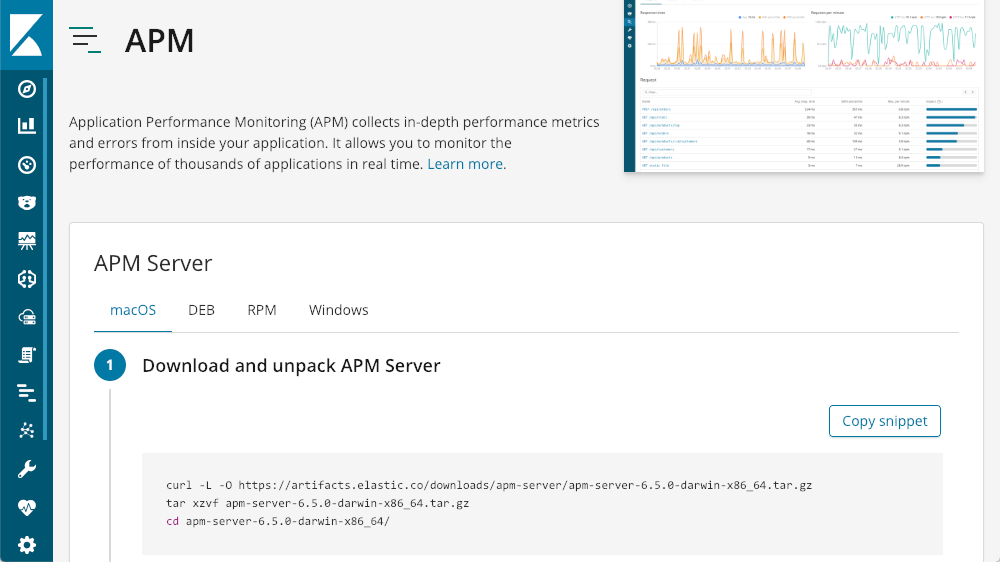
Sobald der APM-Server läuft, bietet Kibana integrierte Tutorials für die einzelnen Agenttypen:
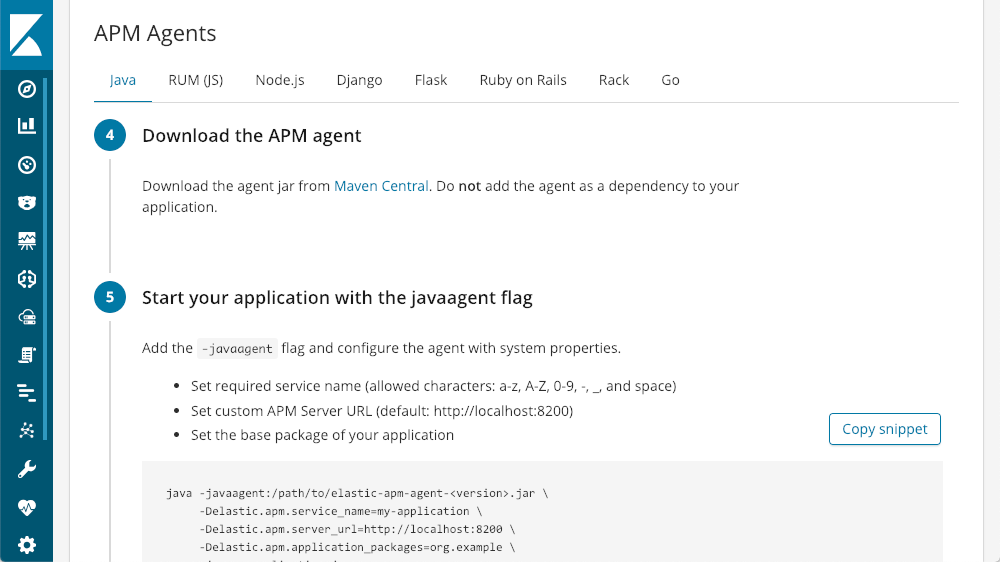
Mit einigen wenigen Zeilen Code kann der APM-Server eingerichtet und gestartet werden.
Probieren Sie Elastic APM einfach aus
Die beste Methode neue Dinge zu lernen, besteht darin, sie einfach auszuprobieren, und uns stehen hierzu verschiedene Möglichkeiten offen. Falls Sie die Benutzeroberfläche live erleben möchten, klicken Sie sich durch unsere APM-Demoumgebung. Falls Sie lieber Dinge lokal ausführen möchten, können Sie den Schritten auf unserer Downloadseite für den APM-Server folgen.
Der kürzeste Weg führt über den Elasticsearch Service in der Elastic Cloud, unser SaaS-Angebot, das Ihnen ein umfassendes Elasticsearch-Deployment, einschließlich eines APM-Servers (ab Version 6.6), einer Kibana-Instanz und eines Machine Learning-Knotens bietet und in wenigen Minuten eingerichtet und gestartet werden kann. Nutzen Sie zwei Wochen lang die kostenlose Testversion. Der größte Vorteil besteht darin, dass wir Ihre Deploymentinfrastruktur für Sie instand halten.
Aktivieren von APM in Elasticsearch Service
Sie können Ihr Cluster mit APM erstellen (oder APM einem vorhandenen Cluster hinzufügen), indem Sie einfach in Ihrem Cluster einen Bildlauf nach unten zum Abschnitt „APM-Konfiguration“ durchführen, „Enable“ (Aktivieren) anklicken und dann entweder beim Update eines vorhandenen Deployments auf „Save changes“ (Änderungen speichern) oder beim Erstellen eines neuen Deployments auf „Create deployment“ (Deployment erstellen) klicken.
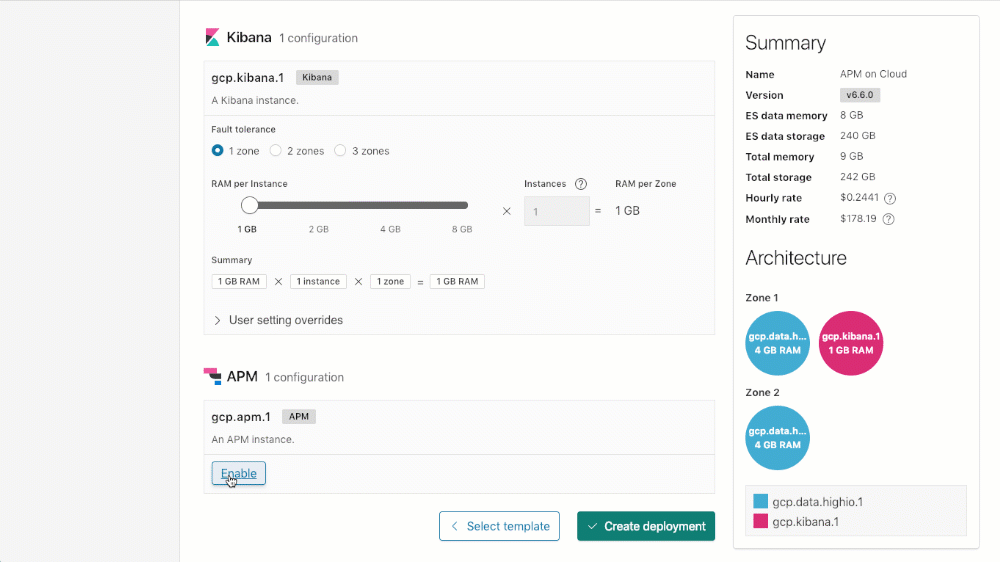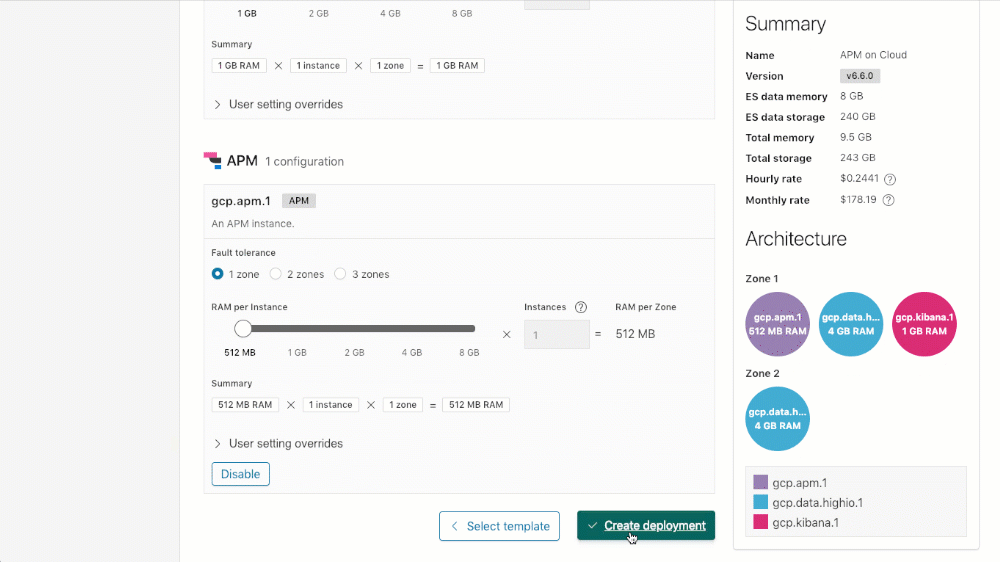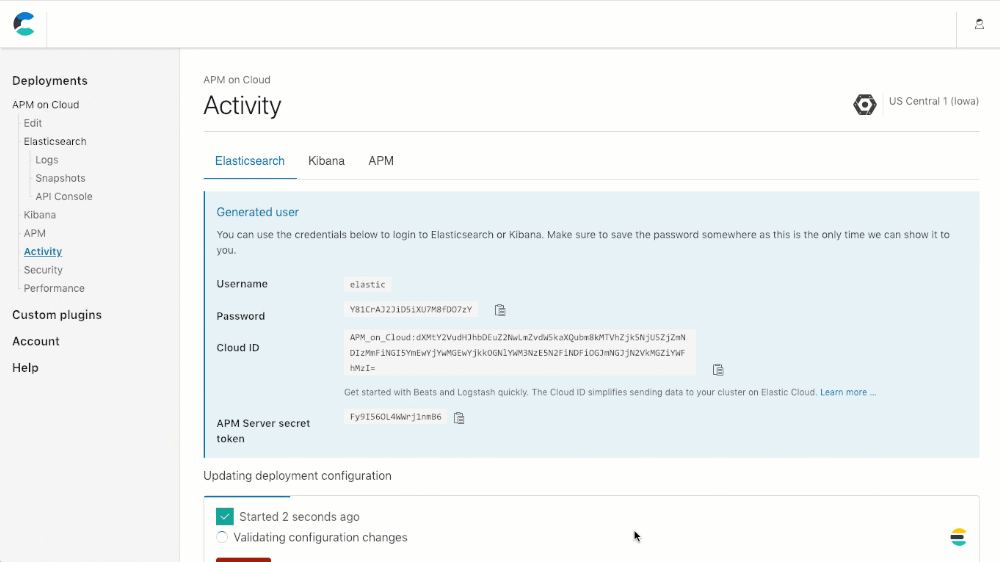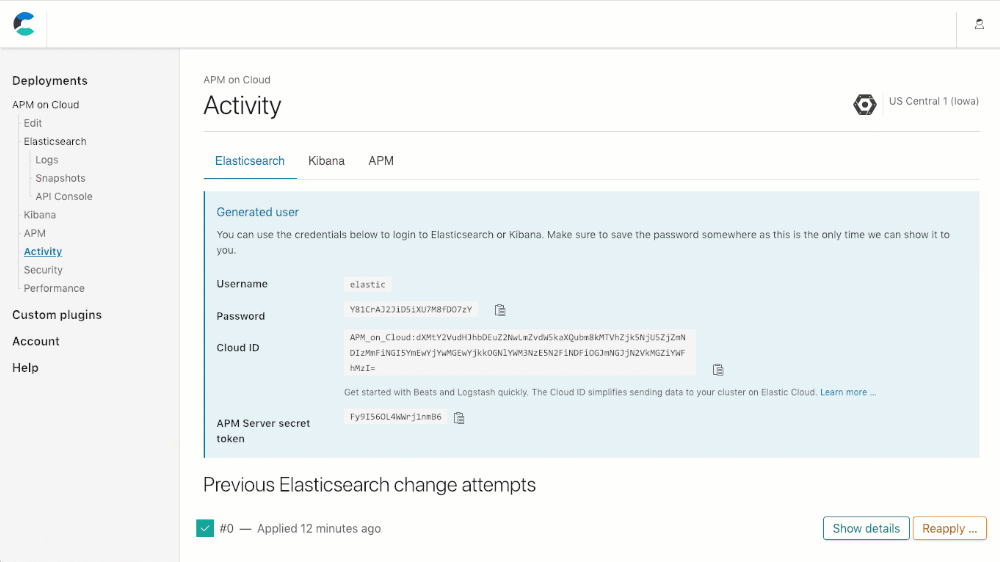
Lizenzierung
Der Elastic APM-Server und alle APM-Agents sind Open Source und die kuratierte APM-Benutzeroberfläche ist Bestandteil der Standardverteilung von Elastic Stack im Rahmen der kostenlosen Basic-Lizenz. Die zuvor erwähnten Integrationen (Alerting und Machine Learning) sind an die zugrundeliegende Lizenz für das Basisfeature gebunden, also Gold für Alerting und Platin für Machine Learning.
Zusammenfassung
Mit APM erhalten wir auf allen Ebenen Einblicke in die Vorgänge in unseren Anwendungen. Mit Integrationen zu Machine Learning und Alerting und in Kombination mit dem Leistungsvermögen der Suche fügt Elastic APM ihrer Anwendungsinfrastruktur eine ganz andere Ebene der Transparenz hinzu. Wir können Elastic APM zur Veranschaulichung von Transaktionen, Tracing und Ausnahmen nutzen und dies alles aus dem Kontext einer kuratierten APM-Benutzeroberfläche heraus. Selbst, wenn wir keine Probleme haben, können wir die Daten aus Elastic APM nutzen, um Fixes zu priorisieren, die Leistung unserer Anwendungen zu optimieren und Engpässe zu bekämpfen.
Weitere Informationen zu Elastic APM und Beobachtbarkeit finden Sie in den folgenden Webinaren:
- Instrumentieren und Überwachen von Java-Anwendungen mit Elastic APM
- Monitoring der Anwendungsleistung mit Elastic Stack
- Monitoring Ihrer OpenShift-Daten mit Elasticsearch, Beats und Elastic APM
- Kombination von APM, Logs und Kenndaten für tiefgreifende operative Transparenz
- Nachverfolgung Ihrer Infrastrukturlogs und Kenndaten in Elastic Stack (ELK Stack)
Probieren Sie es noch heute aus! Diskutieren Sie mit uns auf unserem Diskussionsforum über das Thema APM oder senden Sie Tickets oder Anforderungen für neue Features auf unseren APM GitHub-Repositorys.