Verwendung von Spring Boot mit Elastic App Search


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
In diesem Artikel richten wir eine Spring-Boot-Anwendung ein, die den Inhalt einer zuvor per Crawling indexierten Website aus Elastic App Search abfragt. Zunächst starten wir den Cluster und konfigurieren die Anwendung Schritt für Schritt.
Cluster einrichten
Um diesem Beispiel zu folgen, empfehlen wir Ihnen, das GitHub-Beispiel-Repository zu klonen. Auf diese Weise können Sie terraform ausführen und in kürzester Zeit loslegen.
git clone https://github.com/spinscale/spring-boot-app-searchUm ein Beispiel ausführen zu können, müssen wir einen API-Schlüssel in Elastic Cloud erstellen, wie in der terraform-Einrichtungsanleitung (nur auf Englisch verfügbar) beschrieben.
Anschließend können Sie
terraform init
terraform validate
terraform applyausführen und sich einen Kaffee holen, bevor die eigentliche Arbeit beginnt. Nach einigen Minuten sollte Ihre aktive Instanz in der Elastic Cloud-Oberfläche ungefähr wie folgt angezeigt werden:
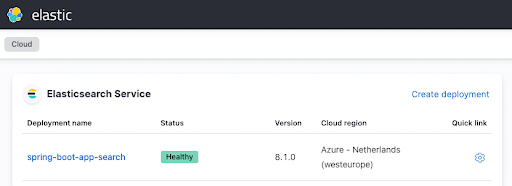
Konfigurieren der Spring-Boot-Anwendung
Bevor wir fortfahren, sollten Sie sicherstellen, dass Sie die Java-Anwendung erstellen und ausführen können. Sie brauchen lediglich Java 17 und können dann den folgenden Befehl ausführen:
./gradlew clean checkDieser Befehl lädt sämtliche Abhängigkeiten herunter, führt die Tests aus und schlägt fehl. Dies ist zu erwarten, da wir in unserer App-Search-Instanz noch keine Daten indexiert haben.
Bevor wir damit anfangen können, müssen wir die Konfiguration anpassen und einige Daten indexieren. Dazu bearbeiten wir zunächst die Datei src/main/resources/application.properties (der folgende Ausschnitt zeigt nur die Parameter, die geändert werden!):
appsearch.url=https://dc3ff02216a54511ae43293497c31b20.ent-search.westeurope.azure.elastic-cloud.com
appsearch.engine=web-crawler-search-engine
appsearch.key=search-untdq4d62zdka9zq4mkre4vv
feign.client.config.appsearch.defaultRequestHeaders.Authorization=Bearer search-untdq4d62zdka9zq4mkre4vvFalls Sie sich ohne Passwort bei Kibana anmelden möchten, melden Sie sich über die Elastic-Cloud-Oberfläche bei der Kibana-Instanz an und öffnen Sie dann Enterprise Search > App Search.
Sie finden die Suchparameter appsearch.key und feign... auf der Seite Credentials in App Search. Dasselbe gilt für den Endpoint, der oben rechts angezeigt wird.
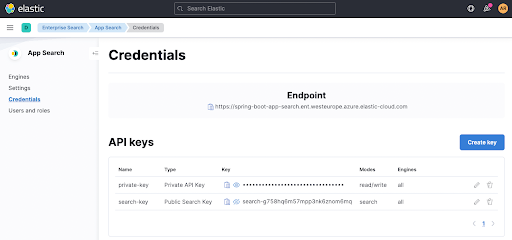
Wenn wir jetzt ./gradlew clean check ausführen, wird zwar der richtige App-Search-Endpunkt verwendet, aber
der Test schlägt weiterhin fehl, da wir noch keine Daten indexiert haben. Das holen wir jetzt nach!
Konfigurieren des Crawlers
Bevor wir den Crawler einrichten, müssen wir einen Container für unsere Dokumente erstellen. Dieser Container, den wir erstellen werden, heißt auch engine. Benennen Sie Ihre Engine web-crawler-search-engine, passend zur Datei application.conf.
Konfigurieren Sie dann einen Crawler, indem Sie auf Use The Crawler klicken.
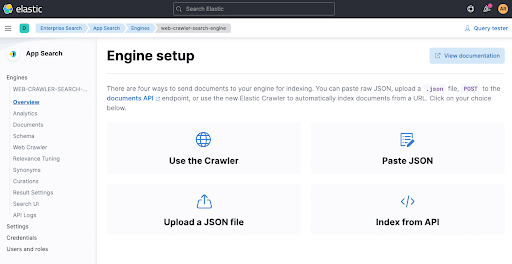
Fügen Sie eine Domäne hinzu. Sie können Ihre eigene Domäne verwenden. Ich habe mein persönliches Blog spinscale.de verwendet, um sicherzugehen, dass ich dabei niemandem auf die Füße trete.
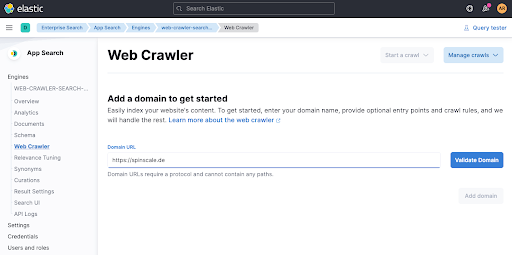
Wenn Sie auf Validate Domain klicken, werden einige Überprüfungen vorgenommen und die Domäne wird zur Engine hinzugefügt.
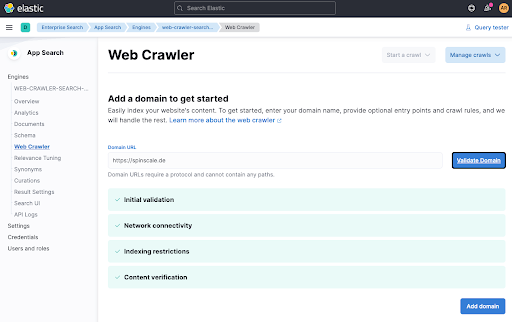
Im letzten Schritt führen wir den Crawler manuell aus, um die Daten sofort zu indexieren. Klicken Sie auf Start a crawl.
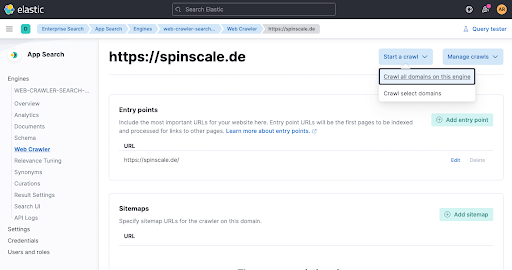
Warten Sie eine Minute und sehen Sie anschließend in der Engine-Übersicht nach, ob Dokumente hinzugefügt wurden.
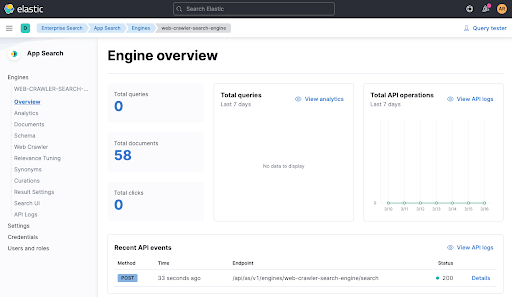
Nachdem wir die Daten in unserer Engine indexiert haben, können wir den Test wiederholen und das Ergebnis in ./gradlew check überprüfen. Jetzt sollte kein Fehler mehr auftreten und Sie sehen einen aktuellen API-Aufruf aus dem Test in der Engine-Übersicht (siehe oben am unteren Rand).
Sehen wir uns den Testcode kurz an, bevor wir unsere App starten.
@SpringBootTest(classes = SpringBootAppSearchApplication.class, webEnvironment = SpringBootTest.WebEnvironment.NONE)
class AppSearchClientTests {
@Autowired
private AppSearchClient appSearchClient;
@Test
public void testFeignAppSearchClient() {
final QueryResponse queryResponse = appSearchClient.search(Query.of("seccomp"));
assertThat(queryResponse.getResults()).hasSize(4);
assertThat(queryResponse.getResults().stream().map(QueryResponse.Result::getTitle))
.contains("Using seccomp - Making your applications more secure",
"Presentations",
"Elasticsearch - Securing a search engine while maintaining usability",
"Posts"
);
assertThat(queryResponse.getResults().stream().map(QueryResponse.Result::getUrl))
.contains("https://spinscale.de/posts/2020-10-27-seccomp-making-applications-more-secure.html",
"https://spinscale.de/presentations.html",
"https://spinscale.de/posts/2020-04-07-elasticsearch-securing-a-search-engine-while-maintaining-usability.html",
"https://spinscale.de/posts/"
);
}
}Der Test startet die Spring-Anwendung, ohne sie an einen Port zu binden, injiziert automatisch die Klasse AppSearchClient und führt einen Test aus, der nach seccomp sucht.
Starten der Anwendung
Im nächsten Schritt können wir unsere Anwendungen starten und überprüfen, ob sie korrekt ausgeführt werden.
./gradlew bootRunSie sollten einige Log-Nachrichten sehen, darunter auch die folgende Nachricht für den Anwendungsstart:
2022-03-16 15:43:01.573 INFO 21247 --- [ restartedMain] d.s.s.SpringBootAppSearchApplication : Started SpringBootAppSearchApplication in 1.114 seconds (JVM running for 1.291)Sie können die App jetzt im Browser starten und einen Blick hineinwerfen, aber zunächst möchte ich noch den Java-Code ansprechen.
Definieren einer Schnittstelle für unseren Such-Client
Um den App-Search-Endpunkt mit Spring Boot abfragen zu können, müssen wir dank Feign lediglich eine Schnittstelle implementieren. Wir interessieren uns weder für die JSON-Serialisierung noch für den Aufbau von HTTP-Verbindungen und können ausschließlich mit POJOs arbeiten. Unser App-Search-Client wird wie folgt definiert:
@FeignClient(name = "appsearch", url="${appsearch.url}")
public interface AppSearchClient {
@GetMapping("/api/as/v1/engines/${appsearch.engine}/search")
QueryResponse search(@RequestBody Query query);
}Der Client verwendet die application.properties-Definitionen für url und engine, um diese Werte nicht mehr im API-Aufruf angeben zu müssen. Außerdem verwendet der Client die in der Datei application.properties angegebenen Header. Auf diese Weise enthält unser Anwendungscode keinerlei URLs, Engine-Namen oder benutzerdefinierte Authentifizierungsheader.
Die einzigen Klassen, die zusätzlichen Code benötigen, sind Query für die Gestaltung des Anforderungstexts und QueryResponse für die Antwort auf unsere Anforderung. In der Antwort habe ich nur die absolut notwendigen Felder modelliert, obwohl Antworten normalerweise viel mehr JSON enthalten. Falls ich mehr Daten brauche, kann ich sie jederzeit zur Klasse QueryResponse hinzufügen.
Die Abfrageklasse enthält momentan nur das Feld query.
public class Query {
private final String query;
public Query(String query) {
this.query = query;
}
public String getQuery() {
return query;
}
public static Query of(String query) {
return new Query(query);
}
}Lassen Sie uns zum Abschluss einige Suchvorgänge aus der Anwendung heraus ausführen.
Serverseitige Abfragen und Rendering
Die Beispielanwendung implementiert drei Modelle für Abfragen an die App-Search-Instanz und integriert sie in die Spring-Boot-Anwendung. Das erste Modell sendet einen Suchbegriff an die Spring-Boot-Anwendung, die die Abfrage an App Search sendet und die Ergebnisse anschließend mit thymeleaf rendert, der standardmäßigen Rendering-Abhängigkeit in Spring Boot. Hier sehen Sie den Controller:
@Controller
@RequestMapping(path = "/")
public class MainController {
private final AppSearchClient appSearchClient;
public MainController(AppSearchClient appSearchClient) {
this.appSearchClient = appSearchClient;
}
@GetMapping("/")
public String main(@RequestParam(value = "q", required = false) String q,
Model model) {
if (q != null && q.trim().isBlank() == false) {
model.addAttribute("q", q);
final QueryResponse response = appSearchClient.search(Query.of(q));
model.addAttribute("results", response.getResults());
}
return "main";
}
}In der Methode main() wird der Parameter „q“ überprüft. Wenn er existiert, wird die Abfrage an App Search gesendet und das model wird mit den Ergebnissen angereichert. Anschließend wird die thymeleaf-Vorlage für main.html gerendert. Die Vorlage sieht wie folgt aus:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org"
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content">
<div>
<form action="/" method="get">
<input autocomplete="off" placeholder="Enter search terms..."
type="text" name="q" th:value="${q}" style="width:20em" >
<input type="submit" value="Search" />
</form>
</div>
<div th:if="${results != null && !results.empty}">
<div th:each="result : ${results}">
<h4><a th:href="${result.url}" th:text="${result.title}"></a></h4>
<blockquote style="font-size: 0.7em" th:text="${result.description}"></blockquote>
<hr>
</div>
</div>
</div>
</body>
</html>Die Vorlage ruft die Variable results ab und iteriert durch die entsprechende Liste, wenn die Variable festgelegt wurde. Für jedes Ergebnis wird dieselbe Vorlage gerendert:
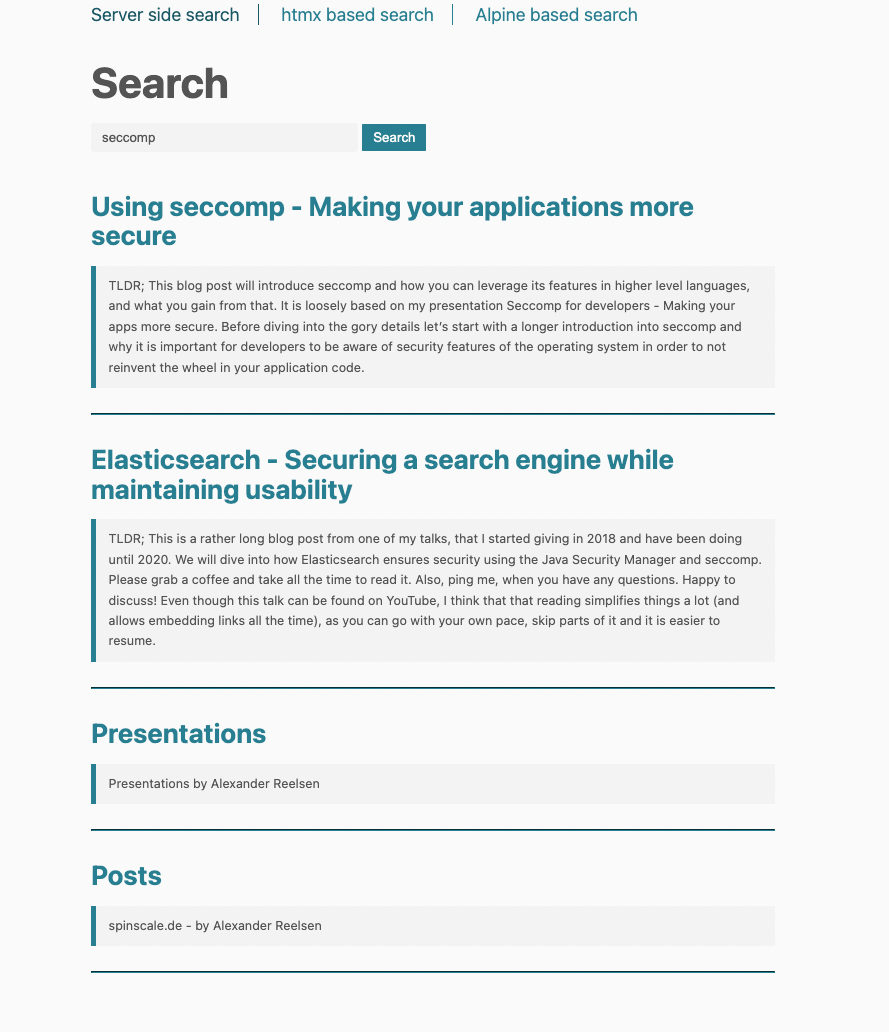
htmx für dynamische Seitenaktualisierungen
Wie Sie in der oberen Navigation sehen, haben wir für unsere Suche drei Alternativen zur Auswahl. Wenn wir die zweite Alternative („htmx based search“) anklicken, wird ein anderes Ausführungsmodell verwendet.
Anstatt die gesamte Seite neu zu laden, wird nur der Teil mit den Ergebnissen durch die vom Server zurückgegebenen Daten ersetzt. Diese Lösung funktioniert, ohne dass wir JavaScript schreiben müssen. Das verdanken wir der fantastischen htmx-Bibliothek. Aus der Beschreibung: htmx bietet Zugriff auf AJAX, CSS Transitions, WebSockets und Server Sent Events direkt in HTML mit Attributen, damit Sie moderne Benutzeroberflächen mit einfachem und leistungsstarkem Hypertext erstellen können.
Dieses Beispiel verwendet nur einen winzigen Teil von htmx. Sehen wir uns zunächst die beiden Endpunktdefinitionen an. Eine Definition ist für das HTML-Rendering zuständig und die andere gibt den HTML-Ausschnitt zurück, den wir zum Aktualisieren der Seite brauchen.
htmx bietet Zugriff auf AJAX, CSS Transitions, WebSockets und Server Sent Events direkt in HTML mit Attributen, damit Sie moderne Benutzeroberflächen mit einfachem und leistungsstarkem Hypertext erstellen können.
Die erste Definition rendert die htmx-main-Vorlage und der zweite Endpunkt rendert die Ergebnisse. Die htmx-main-Vorlage sieht wie folgt aus:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org"
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content">
<div>
<form action="/search" method="get">
<input type="search"
autocomplete="off"
id="searchbox"
name="q" placeholder="Begin Typing To Search Articles..."
hx-post="/htmx-search"
hx-trigger="keyup changed delay:500ms, search"
hx-target="#search-results"
hx-indicator=".htmx-indicator"
style="width:20em">
<span class="htmx-indicator" style="padding-left: 1em;color:red">Searching... </span>
</form>
</div>
<div id="search-results">
</div>
</div>
</body>
</html>Der interessante Teil sind die hx--Attribute im HTML-Element <input>. Dabei geschieht grob gesagt Folgendes:
- Löse eine HTTP-Anforderung aus, wenn seit 500 ms keine Tastatureingabe erfolgt ist.
- Sende eine HTTP POST-Anforderung an /htmx-search.
- Zeige in der Zwischenzeit das .htmx-indicator-Element an.
- Rendere die Antwort im Element mit der ID #search-results.
Stellen Sie sich vor, wie viel JavaScript Sie bräuchten, um diese Logik mit Key-Listenern, der Anzeige von Elementen beim Warten auf die Antwort und dem Versenden der AJAX-Anforderung zu implementieren.
Außerdem hat diese Lösung den Vorteil, dass Sie Ihre bevorzugte serverseitige Rendering-Lösung verwenden können, um das zurückgegebene HTML zu erstellen. Wir können also im thymeleaf-Ökosystem bleiben, anstatt eine clientseitige Vorlagensprache implementieren zu müssen. Damit erhalten wir eine sehr einfache htmx-search-results-Vorlage, die lediglich über die Ergebnisse iteriert:
<div th:each="result : ${results}">
<h4><a th:href="${result.url}" th:text="${result.title}"></a></h4>
<blockquote style="font-size: 0.7em" th:text="${result.description}"></blockquote>
<hr>
</div>Der Unterschied zum ersten Beispiel besteht darin, dass sich die URL für diese Suche niemals ändert und sie daher nicht als Lesezeichen verwendet werden kann. htmx bietet zwar Verlaufsunterstützung, die jedoch sorgfältig implementiert werden muss und daher den Rahmen dieses Beispiels sprengen würde.
Browsersuche mit App Search
Damit kommen wir zum letzten Beispiel. Diese Lösung ist völlig anders als die bisherigen Beispiele und kommt komplett ohne den Spring-Boot-Server aus. Wir brauchen lediglich einen Browser. Dazu verwenden wir Alpine.js. Der Endpunkt auf der Serverseite ist sehr einfach:
@GetMapping("/alpine")
public String alpine() {
return "alpine-js";
}Die alpine-js.html-Vorlage erfordert etwas mehr Erklärung, werfen wir jedoch zunächst einen Blick hinein:
<!DOCTYPE html>
<html
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content" x-data="{ q: '', response: null }">
<div>
<form @submit.prevent="">
<input type="search" autocomplete="off" placeholder="Begin Typing To Search Articles..." style="width:20em"
x-model="q"
@keyup="client.search(q).then(resultList => response = resultList)">
</form>
</div>
<template x-if="response != null && response.info.meta != null && response.info.meta.request_id != null">
<template x-for="result in response.results">
<template x-if="result.data != null && result.data.title != null && result.data.url != null && result.data.meta_description != null ">
<div>
<h4><a class="track-click" :data-request-id="response.info.meta.request_id" :data-document-id="result.data.id.raw" :data-query="q" :href="result.data.url.raw" x-text="result.data.title.raw"></a></h4>
<blockquote style="font-size: 0.7em" x-text="result.data.meta_description.raw"></blockquote>
<hr>
</div>
</template>
</template>
</template>
<script th:inline="javascript">
var client = window.ElasticAppSearch.createClient({
searchKey: [[${@environment.getProperty('appsearch.key')}]],
endpointBase: [[${@environment.getProperty('appsearch.url')}]],
engineName: [[${@environment.getProperty('appsearch.engine')}]]
});
document.addEventListener("click", function(e) {
const el = e.target;
if (!el.classList.contains("track-click")) return;
client.click({
query: el.getAttribute("data-query"),
documentId: el.getAttribute("data-document-id"),
requestId: el.getAttribute("data-request-id")
});
});
</script>
</div>
</body>
</html>Der erste wichtige Unterschied besteht darin, dass wir JavaScript verwenden, um den ElasticAppSearch-Client zu initialisieren, und zwar mit den Eigenschaften, die wir in der Datei application.properties konfiguriert haben. Nachdem wir den Client initialisiert haben, können wir ihn in den HTML-Attributen verwenden.
Der Code initialisiert zwei Variablen für die Verwendung:
<div layout:fragment="content" x-data="{ q: '', response: null }">Die Variable „q“ enthält die Abfrage aus dem Eingabeformular und „response“ enthält die Antwort der Suche. Der nächste interessante Teil ist die Formulardefinition:
<form @submit.prevent="">
<input type="search" autocomplete="off" placeholder="Search Articles..."
x-model="q"
@keyup="client.search(q).then(resultList => response = resultList)">
</form><input x-model="q"...> bindet die Variable „q“ an die Eingabe und wird nach jeder Tastatureingabe aktualisiert. Außerdem haben wir ein Event für „keyup“, das eine Suche mit client.search() ausführt und das Ergebnis der Variable response zuweist. Sobald die Client-Suche eine Rückgabe erhält, ist die Variable „response“ also nicht mehr leer. Zuletzt stellen wir mit @submit.prevent="" sicher, dass das Formular nicht übermittelt wird.
Anschließend werden die
<div>
<h4><a class="track-click"
:data-request-id="response.info.meta.request_id"
:data-document-id="result.data.id.raw"
:data-query="q"
:href="result.data.url.raw"
x-text="result.data.title.raw">
</a></h4>
<blockquote style="font-size: 0.7em"
x-text="result.data.meta_description.raw"></blockquote>
<hr>
</div>Dieses Rendering funktioniert etwas anders als die beiden serverseitigen Rendering-Implementierungen, da es Funktionen zum Nachverfolgen angeklickter Links enthält. Der wichtigste Teil für das Rendering der Vorlagen sind die Eigenschaften :href und x-text, die den Link und den Text des Links festlegen. Die restlichen :data-Parameter dienen zum Nachverfolgen von Links.
Nachverfolgen von Klicks
Warum ist es manchmal sinnvoll, Klicks nachzuverfolgen? Nun, beispielsweise können Sie die Qualität Ihrer Suchergebnisse ermitteln, indem Sie messen, ob Ihre Nutzer darauf klicken. Darum enthält dieser HTML-Ausschnitt etwas mehr JavaScript. Sehen wir uns die Lösung zunächst in Kibana an.
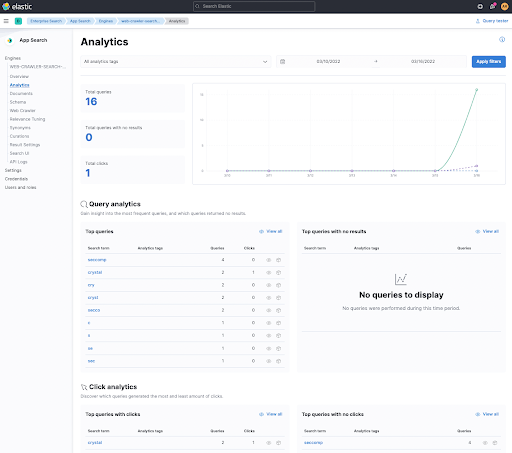
Unter Click analytics am unteren Rand sehen Sie einen nachverfolgten Klick, als ich im angeklickten ersten Link nach crystal gesucht habe. Sie können auf diesen Begriff klicken, um das angeklickte Dokument anzuzeigen und der Klick-Spur Ihrer Nutzer zu folgen.
Wie haben wir diese Funktion in unserer kleinen App implementiert? Mit einem click-JavaScript-Listener für bestimmte Links. Hier sehen Sie den JavaScript-Ausschnitt:
document.addEventListener("click", function(e) {
const el = e.target;
if (!el.classList.contains("track-click")) return;
client.click({
query: el.getAttribute("data-query"),
documentId: el.getAttribute("data-document-id"),
requestId: el.getAttribute("data-request-id")
});
});Wenn ein angeklickter Link die Klasse track-click enthält, wird ein click-Event mit dem ElasticAppSearch-Client gesendet. Das Event enthält den ursprünglichen Suchbegriff sowie die documentId und die requestId aus der Suchantwort, die in das -Element in der oben gezeigten Vorlage gerendert wurden.
Wir könnten diese Funktion auch in das serverseitige Rendering integrieren, indem wir dieselben Informationen bereitstellen, wenn ein Nutzer auf einen Link klickt, und sind also nicht auf den Browser beschränkt. Der Einfachheit halber habe ich diese Implementierung hier ausgelassen.
Zusammenfassung
Hoffentlich fanden Sie diese Einführung in Elastic App Search aus der Entwicklerperspektive und die verschiedenen Integrationsmöglichkeiten in Ihre Anwendungen interessant. Schauen Sie unbedingt im GitHub-Repository vorbei und führen Sie das Beispiel selbst aus.
Sie können terraform mit dem Elastic Cloud Provider verwenden, um in der Elastic Cloud im Handumdrehen loszulegen.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken