Tutoriel sur l'observabilité Kubernetes : Monitoring et analyse des logs
Kubernetes a sorti la technologie d'orchestration des conteneurs dans les faits et une technologie intégrale dans le mouvement natif du cloud. Le mouvement natif du cloud apporte vitesse, flexibilité et agilité au développement des logiciels, mais augmente également la complexité, avec des centaines de microservices sur des milliers (voire des millions) de conteneurs, s'exécutant dans des pods éphémères et jetables. Le monitoring d'un tel système complexe et réparti est difficile et également très important. Heureusement, Elastic facilite l'observabilité de votre environnement Kubernetes.
Dans cette série de tutoriels sur l'observabilité de Kubernetes, nous étudierons comment nous pouvons monitorer tous les aspects de vos applications s'exécutant dans Kubernetes,notamment :
- Ingestion et analyse des logs
- Collecte des indicateurs de performance et d'intégrité
- Monitoring des performances applicatives avec Elastic APM
À la fin de ce tutoriel, vous aurez un exemple de base d'une application qui transfère toutes ses données d'observabilité vers la Suite Elastic pour le monitoring et l'analyse.
Pourquoi choisir Elastic Observability pour Kubernetes ?
L'observabilité s'appuie sur trois "piliers" en matière de données : les logs, les indicateurs et le monitoring des performances applicatives (ou APM). On ne manque pas d'articles qui cartographient les différents outils et fournisseurs pour regrouper "la meilleure race" de monitoring pour Kubernetes, assemblant 3-6 outils, fournisseurs et technologies différents...
N'ayez pas peur. Elastic Observability combine vos logs, indicateurs et données APM pour une visibilité et une analyse unifiées à l'aide d'un outil. Commencez par résoudre les problèmes en vous basant sur une anomalie de latence à laquelle font face les utilisateurs dans les données APM (détectées par Machine Learning), pivotez vers les indicateurs d'un pod Kubernetes en particulier, observez les logs générés par ce pod et corrélez-les avec les indicateurs et les logs décrivant les événements se produisant sur l'hôte et le réseau, tout en restant dans la même interface utilisateur. Maintenant, l'observabilité est bien faite !
Et tandis que cela est plus simple pour les utilisateurs, il y encore beaucoup à faire en arrière-plan parce que...
Les logs Kubernetes sont des cibles en mouvement
Kubernetes effectue l'orchestration en déployant les conteneurs en hôtes disponibles. Cela distribue nativement les composants d'applications dans différents hôtes, rendant impossible de savoir d'avance lorsque le composant atterrit.
Les conteneurs s'exécutant dans les pods Kubernetes produisent des logs comme stdout ou stderr. Ces logs sont écrits dans un emplacement connu comme kubelet comme fichiers nommés après l'ID de pod. Afin de lier les logs au composant ou au pod qui a les a produits, les utilisateurs doivent découvrir quels pods de composants s'exécutent sur l'hôte actuel et quels sont leurs ID.
En ajoutant plus de complexité, Kubernetes peut décider d'augmenter ou de réduire l'application et, par conséquent, le nombre de pods représentant le composant d'applications peut changer.
Heureusement, Filebeat adore une cible en mouvement
Pour collecter les logs des pods, il suffit que Filebeat soit exécuté comme DaemonSet dans notre cluster Kubernetes. Filebeat peut être configuré pour communiquer avec l'API de kubelet locale, obtenir la liste des pods s'exécutant sur l'hôte actuel et collecter les logs produits par les pods. Ces logs sont annotés avec toutes les métadonnées pertinentes de Kubernetes, comme l'ID du pod, le nom du conteneur, les termes et les annotations du conteneur, etc.
Filebeat utilise ces annotations pour découvrir quel type de composants s'exécutent dans le pod et peut décider du module de logging qui s'applique aux logs traités. Regardez, sans les mains ! L'ingestion de logs Kubernetes avec Filebeat est super facile. D'accord, vous êtes sur le point de commencer, mais une remarque rapide (et importante) avant de le faire :
| Avant de commencer : le tutoriel suivant suppose que vous disposez d'un environnement Kubernetes configuré. Nous avons créé un blog supplémentaire qui vous guide tout au long du processus de configuration d'un environnement Minikube à nœud unique avec une application de démonstration pour exécuter le reste des activités. |
Collecte des logs Kubernetes avec Filebeat
Nous utiliserons Elasticsearch Service sur Elastic Cloud. Cependant, tout ce qui est décrit ici peut fonctionner avec les clusters Elastic déployés sur votre propre infrastructure, que vous autogériez ou que vous utilisiez des systèmes d'orchestration comme Elastic Cloud Enterprise (ECE) ou Elastic Cloud on Kubernetes (ECK). Le code de ce tutoriel est disponible dans le référentiel GitHub suivant : http://github.com/michaelhyatt/k8s-o11y-workshop
Déploiement de Filebeat comme un DaemonSet
Une seule instance de Filebeat doit être déployée par hôte Kubernetes. Une fois qu'elle est déployée, Filebeat communique avec l'hôte via l'API kubelet pour récupérer les informations sur les pods qui s'exécutent, toutes les annotations des métadonnées ainsi que l'emplacement des fichiers de logs.
La configuration de déploiement du DaemonSet est définie dans le fichier $HOME/k8s-o11y-workshop/filebeat/filebeat.yml. Ayons une analyse plus approfondie de la partie descripteur de déploiement représentant la configuration de Filebeat.
Cette partie augmente le nombre total de champs possibles de 1 000 par défaut à 5 000. Les déploiements Kubernetes peuvent introduire un grand nombre de termes et d'annotations qui entraînent des champs de schémas qui peuvent excéder les 1 000 par défaut.
setup.template.settings:
index.mapping.total_fields.limit: 5000
Les paramètres du mécanisme de découverte automatique ordonnent à Filebeat d'utiliser la découverte automatique Kubernetes et se basent sur la découverte automatique axée sur les indices qui fonctionne sur les annotations.
filebeat.autodiscover:
providers:
- type: kubernetes
host: ${NODE_NAME}
hints.enabled: true
La prochaine session définit la chaîne de processeurs qui sera appliquée à tous les logs capturés par cette instance Filebeat. Tout d'abord, cela enrichira l'événement avec les métadonnées provenant de Docker, de Kubernetes, de l'hôte et des fournisseurs cloud. Puis, il y a une section drop_event qui filtre les messages en se basant sur le contenu et certains des champs de métadonnées créés par les processeurs précédents. Cela est utile lorsqu'il y a un type d'événements bruyant qui continue de dominer les logs. Remarquez la manière logique dont et et ou sont utilisés pour élaborer l'état de la correspondance.
processors:
- add_cloud_metadata:
- add_host_metadata:
- add_docker_metadata:
- add_kubernetes_metadata:
- drop_event:
when:
or:
- contains:
message: "OpenAPI AggregationController: Processing item k8s_internal_local_delegation_chain"
- and:
- equals:
kubernetes.container.name: "metricbeat"
- contains:
message: "INFO"
- contains:
message: "Non-zero metrics in the last"
- and:
- equals:
kubernetes.container.name: "packetbeat"
- contains:
message: "INFO"
- contains:
message: "Non-zero metrics in the last"
- contains:
message: "get services heapster"
- contains:
kubernetes.container.name: "kube-addon-manager"
- contains:
kubernetes.container.name: "dashboard-metrics-scraper"
Modules Filebeat et découverte automatique utilisant les annotations
Nous avons vu ci-dessus comment la découverte automatique appliquera le module approprié aux stdout/stderr pour les déployer sous un format propre au module. En savoir plus sur la découverte automatique dans les documents Filebeat.
Maintenant, voyons comment les différents composants dans notre exemple d'application sont configurés pour fonctionner avec la découverte automatique axée sur les indices de Kubernetes.
Exemple de NGINX
Voici l'extrait de code de $HOME/k8s-o11y-workshop/nginx/nginx.yml qui demande à Filebeat de traiter les logs depuis ce pod comme logs NGINX, où stdout représente le log d'accès, et stderr représente le log d'erreurs :
annotations:
co.elastic.logs/module: nginx
co.elastic.logs/fileset.stdout: access
co.elastic.logs/fileset.stderr: error
Traitement des logs d'applications multiligne
Un autre exemple de découverte automatique axée sur les indices configure Filebeat pour traiter les entrées de log multiligne petclinic comme événement de log unique. Cela est utile lorsque les composants consignent des messages multiligne, comme les traces de la suite Java qui représentent un seul événement, mais seront traités par défaut comme un seul événement par ligne délimité par la fin de la ligne.
Voici un extrait de $HOME/k8s-o11y-workshop/petclinic/petclinic.yml qui représente la configuration de gestion des événements multiligne qui est comprise par Filebeat au moyen de la découverte automatique axée sur les indices :
annotations:
co.elastic.logs/multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
co.elastic.logs/multiline.negate: "true"
co.elastic.logs/multiline.match: "after"
En savoir plus sur le traitement des événements multiligne dans les documents Filebeat.
Analyse des logs Kubernetes dans la Suite Elastic
Maintenant que les logs ont été ingérés dans Elasticsearch, c'est le moment de les mettre à profit.
Utilisation de l'application Logs dans Kibana
L'application Logs dans Kibana vous permet de rechercher, filtrer et faire le suivi de tous les logs collectés dans la Suite Elastic. Au lieu de devoir accéder en SSH aux différents serveurs, de devoir exécuter "cd" dans le répertoire et d'effectuer le suivi des fichiers individuels, tous les logs sont disponibles dans un seul outil dans l'application Logs.
- Vérifier les logs de filtrage à l'aide de la recherche avec le clavier ou en texte brut.
- Vous pouvez avancer et reculer l'heure à l'aide du sélecteur d'heure ou de l'affichage de la chronologie sur le côté.
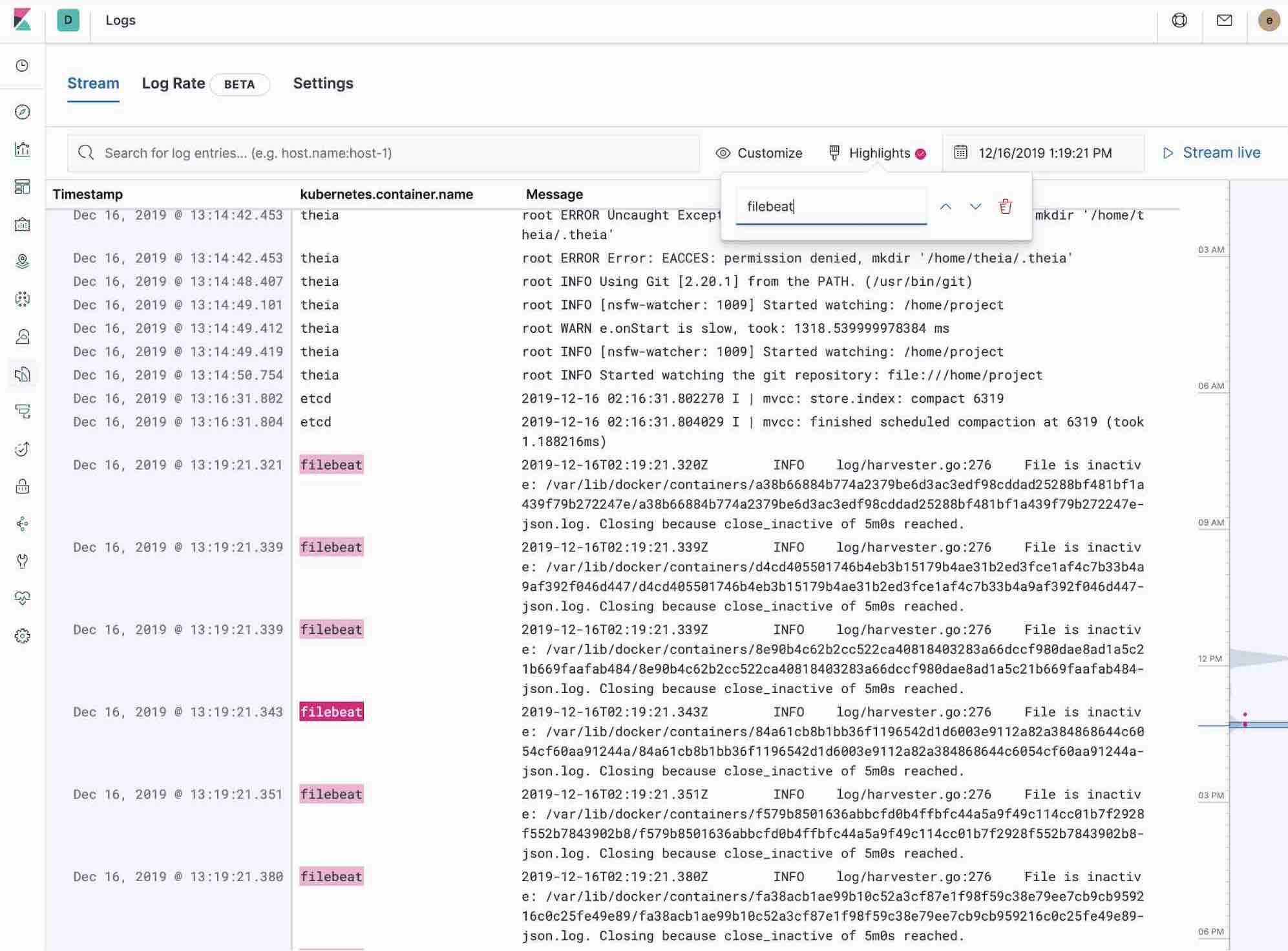
- Si vous souhaitez regarder la mise à jour des logs devant vous de style tail -f, cliquez sur le bouton Streaming (Diffusion), puis utilisez le surlignage pour accentuer la partie importante des informations que vous attendez de voir.
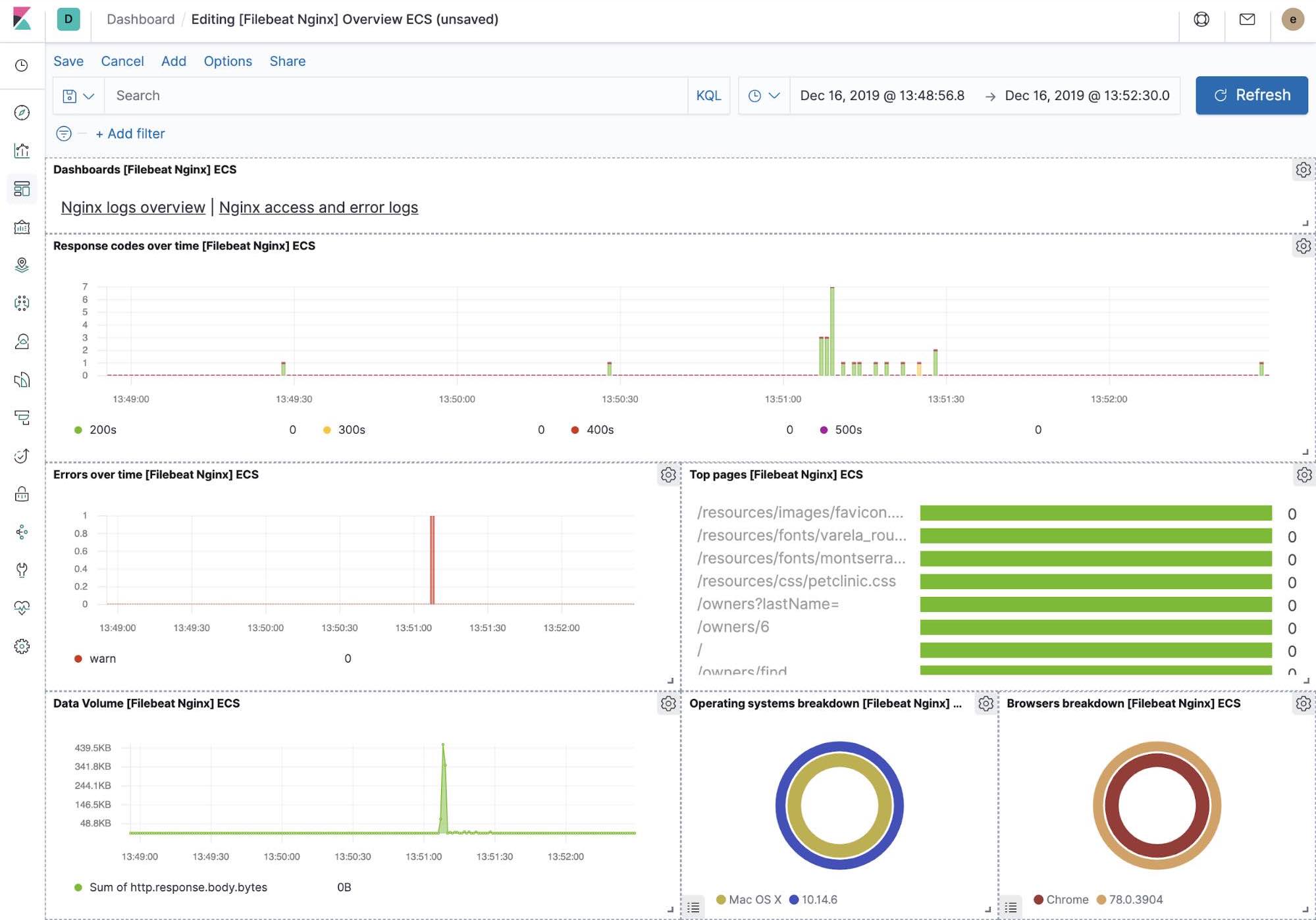
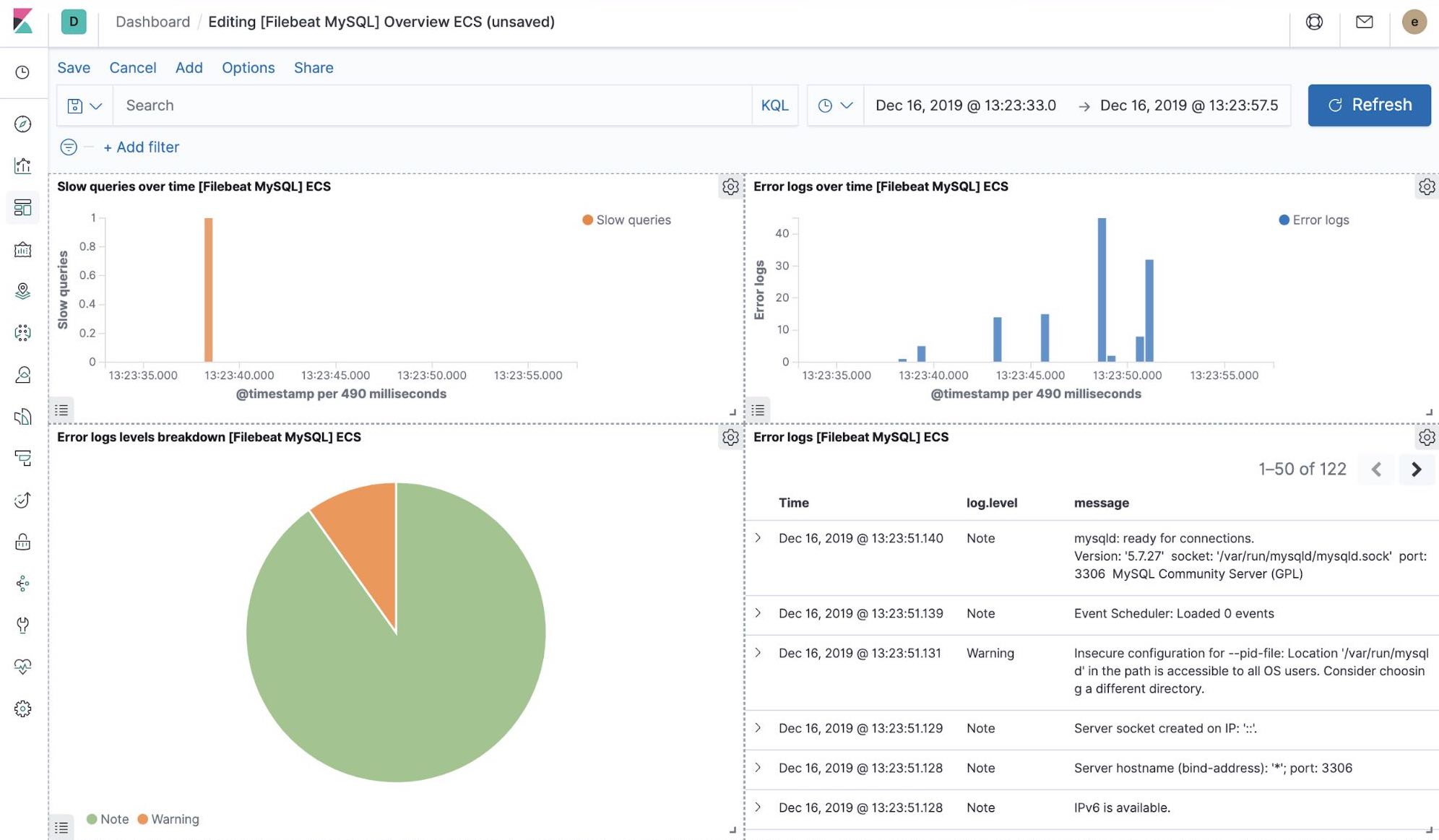
Visualisations Kibana prêtes à utiliser
Lorsque vous exécutez la tâche de configuration de Filebeat, entre autres, cela a précréé un ensemble de tableaux de bord prêts à utiliser dans Kibana. Une fois que notre exemple d'application petclinic est enfin déployé, nous pouvons naviguer vers les tableaux de bord Filebeat prêts à utiliser pour MySQL, NGINX et voir si les modules Filebeat ne capturent pas uniquement les logs, mais peuvent également capturer les indicateurs que les composants consignent. L'activation de ces visualisations nécessite d'exécuter les composants MySQL et NGINX de l'exemple d'application.
Machine Learning et détection des anomalies de logging
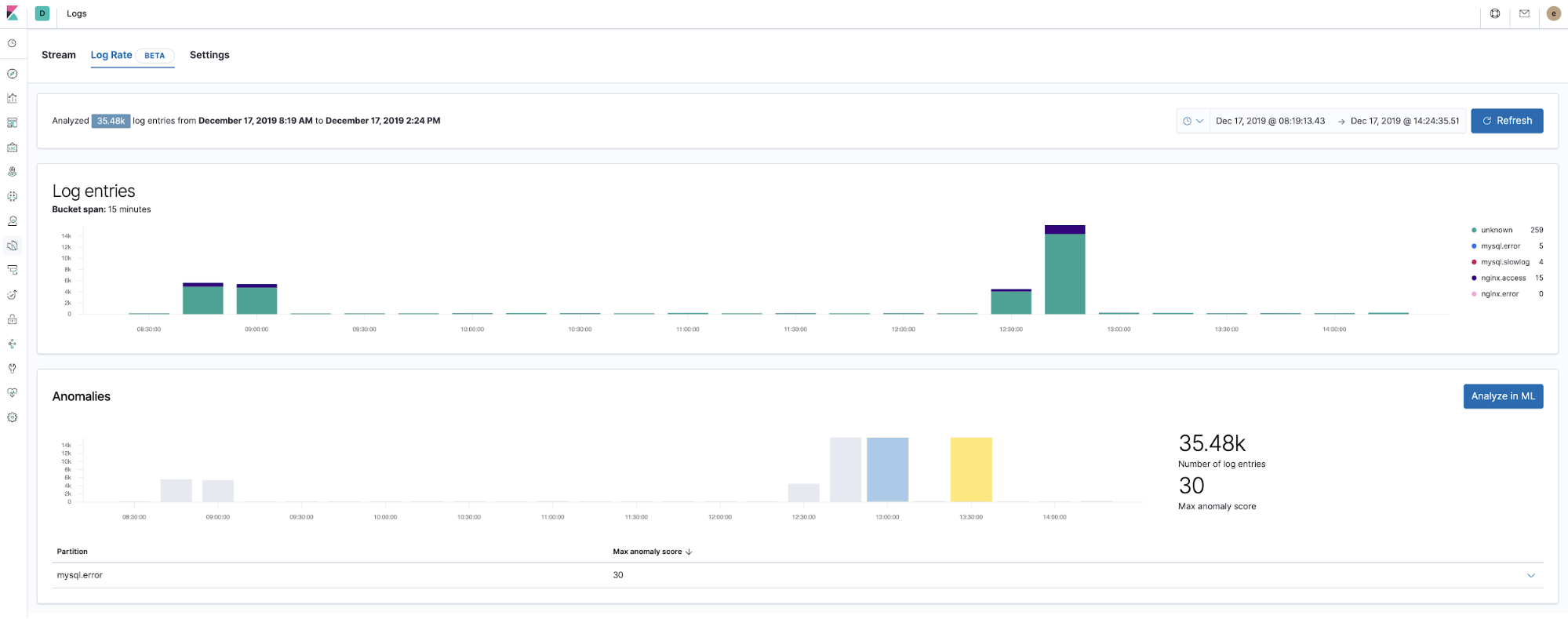
À partir de la version 7.5, la Suite Elastic peut détecter des anomalies dans le taux de logs des composants d'applications. Elle peut être utilisée pour détecter les choses suivantes :
- une nouvelle source d'applications ou de logs vient juste d'arriver ;
- l'activité de logging a soudainement augmenté en raison d'une promotion (ou d'une attaque !) ;
- le transfert de logs s'est soudainement arrêté, peut-être en raison d'un dysfonctionnement d'un agent ou du pipeline d'ingestion.
Nous avons introduit la fonctionnalité d'anomalies de taux de logs directement dans l'application Logs, ce qui permet aux opérateurs d'obtenir des réponses instantanées aux questions ci-dessus. Activez-la en un simple clic dans l'application Logs.
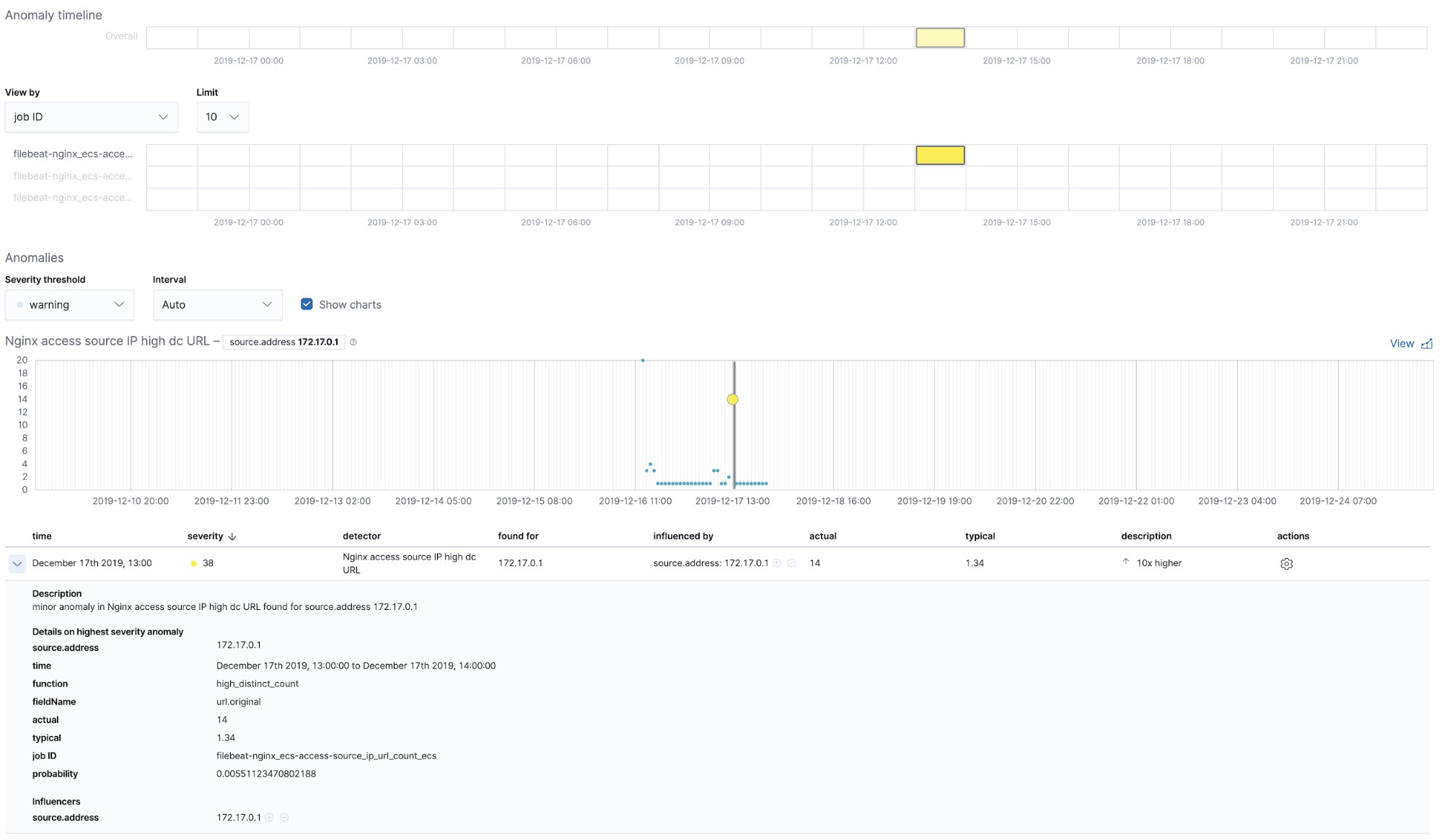
Détection des inconnues avec la classification des entrées de logs
Une autre application utile de Machine Learning associée aux logs est la détection de nouvelles entrées de type logs qui n'ont pas été observées avant. Au plus haut niveau, le Machine Learning enlève toutes les parties numériques et variables des entrées de logs, comme les horodatages, les valeurs numériques, etc., capture ce qui est laissé et effectue une catégorisation des parties fixes des entrées de logs. Puis, il essaie de les rassembler en groupes et continue d'identifier de nouveaux groupes apparaissant comme des anomalies qui représentent les entrées de logs qui n'ont pas été observées avant.

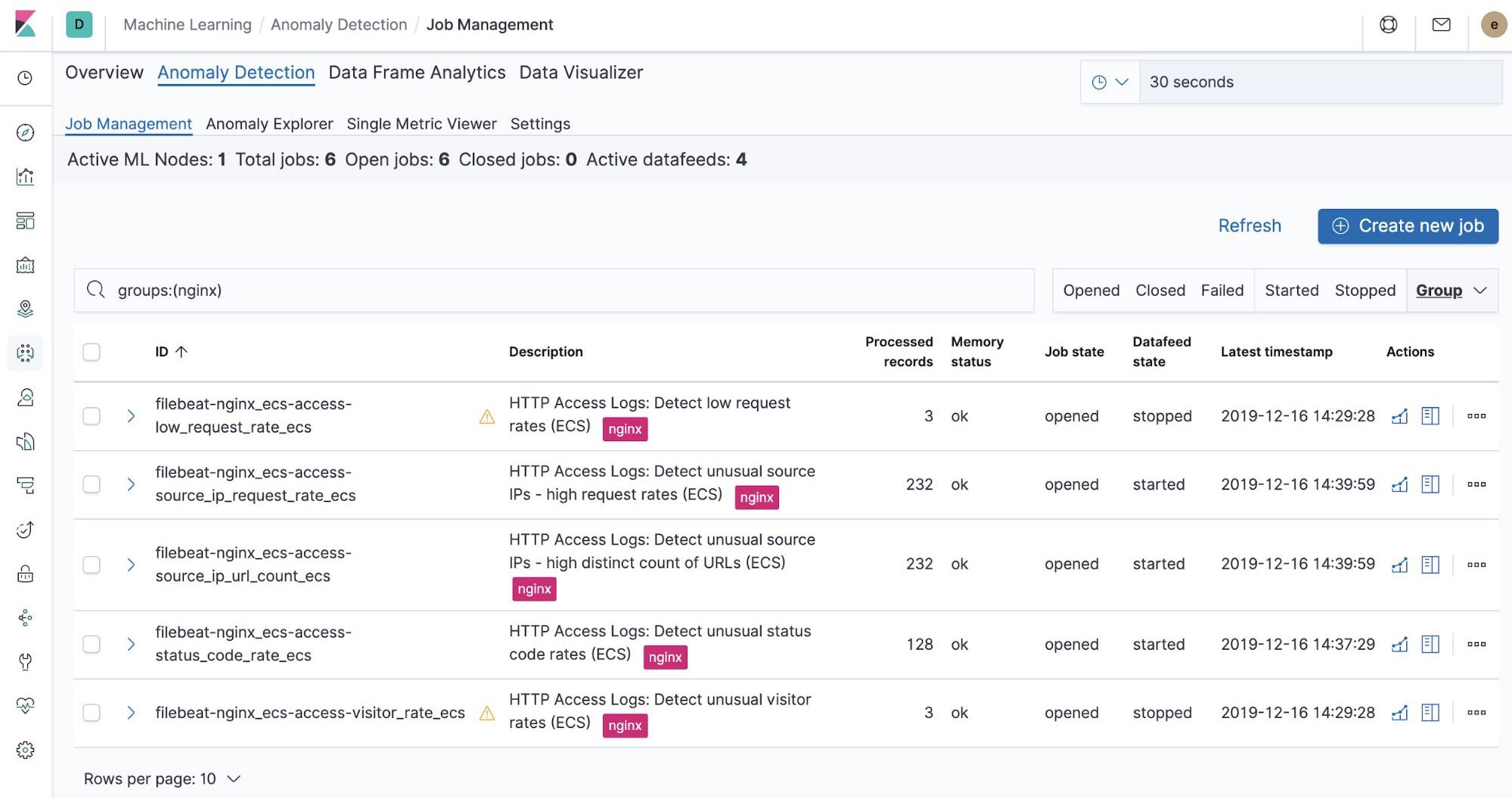
Tâches de Machine Learning prêtes à l'emploi – NGINX
Au moment où nous exécutons la tâche de configuration de Filebeat, cela a précréé les tâches de Machine Learning prêtes à utiliser. Si elles sont activées, elles peuvent commencer à détecter des anomalies dans les données stdout et stderr NGINX ingérées depuis Filebeat.
Résumé
Dans cette partie, nous avons ingéré des logs Kubernetes dans la Suite Elastic à l'aide de Filebeat et de ses modules. Vous pouvez commencer à monitorer vos systèmes et votre infrastructure aujourd'hui en vous inscrivant à un essai gratuit de Elasticsearch Service sur Elastic Cloud ou en téléchargeant la Suite Elastic et en l'hébergeant vous-même. Une fois que vous êtes opérationnel, monitorez la disponibilité de vos hôtes avec Elastic Uptime et instrumentez les applications s'exécutant sur vos hôtes avec Elastic APM. Vous serez en route vers un système entièrement observable, complètement intégré avec votre nouveau cluster d'indicateurs. Si vous rencontrez des difficultés ou si vous avez des questions, allez dans nos forums de discussion, nous sommes là pour vous aider.
À suivre : Collecte des indicateurs de performance et d'intégrité