Tutoriel sur l'observabilité Kubernetes : collecte et analyse des indicateurs
Cet article est le deuxième de notre série de tutoriels sur l'observabilité de Kubernetes, dans lesquels nous étudierons comment nous pouvons monitorer tous les aspects de vos applications s'exécutant dans Kubernetes, notamment :
- Ingestion et analyse des logs
- Collecte des indicateurs de performance et d'intégrité
- Monitoring des performances applicatives avec Elastic APM
Nous couvrirons l'utilisation d'Elastic Observability pour ingérer et analyser les indicateurs des conteneurs dans Kibana à l'aide de l'application Metrics et des tableaux de bord prêts à l'emploi.
Collecte d'indicateurs de Kubernetes
De la même façon que la cible en mouvement des logs Kubernetes, la collecte des indicateurs depuis Kubernetes peut poser problème pour plusieurs raisons :
- Kubernetes exécute des composants sur différents hôtes qui doivent être monitorés par la collecte d'indicateurs tels que celui du processeur, de la mémoire, de l'utilisation du disque, et des E/S du disque et du réseau.
- Les conteneurs Kubernetes, qui sont des sortes de mini-VM, produisent également leur propre ensemble d'indicateurs.
- Tandis que les serveurs et les bases de données d'application peuvent s'exécuter comme des pods Kubernetes, chaque technologie a sa propre façon de faire des rapports sur les indicateurs concernés.
Les entreprises utilisent souvent de nombreuses technologies pour gérer la collecte d'indicateurs sur Kubernetes, ce qui complique davantage la tâche de monitoring de leurs déploiements Kubernetes. C'est là où Elastic Observability change la donne en combinant vos logs, indicateurs et données APM pour une visibilité et une analyse unifiées à l'aide d'un seul outil.
Collecte des indicateurs k8s avec Metricbeat
De la même façon que Filebeat, Metricbeat est le seul composant que nous allons utiliser pour collecter les différents indicateurs des pods s'exécutant sur notre cluster Kubernetes ainsi que les propres indicateurs du cluster Kubernetes. Les modules Metricbeat offrent une façon rapide et facile de prendre les indicateurs des différentes sources et de les transférer vers Elasticsearch comme événements compatibles ECS, prêts à être corrélés avec les logs, la disponibilité et les données APM. Metricbeat est déployé simultanément sur Kubernetes de deux façons :
- un seul pod pour collecter les indicateurs Kubernetes. Ce pod utilise les kube-state-metrics pour collecter les indicateurs au niveau du cluster ;
- un DaemonSet qui déploie Metricbeat comme instance unique par hôte Kubernetes pour collecter des indicateurs des pods déployés sur cet hôte. Metricbeat interagit avec les API kubelet pour que les composants s'exécutent sur cet hôte, et utilise différentes méthodes, comme la détection automatique, pour interroger davantage les composants pour collecter les indicateurs propres à la technologie.
| Avant de commencer : le tutoriel suivant suppose que vous disposez d'un environnement Kubernetes configuré. Nous avons créé un blog supplémentaire qui vous guide tout au long du processus de configuration d'un environnement Minikube à nœud unique avec une application de démonstration pour exécuter le reste des activités. |
Collecte des indicateurs d'hôte, Docker et Kubernetes
Chaque instance DaemonSet collectera les indicateurs d'hôte, Docker et Kubernetes, comme défini dans la configuration YAML $HOME/k8s-o11y-workshop/metricbeat/metricbeat.yml :
Configuration des indicateurs (hôtes) du système
system.yml: |-
- module: system
period: 10s
metricsets:
- cpu
- load
- memory
- network
- process
- process_summary
- core
- diskio
# – socket
processes: ['.*']
process.include_top_n:
by_cpu: 5 # inclure les 5 premiers processus par processeur
by_memory: 5 # inclure les 5 premiers processus par mémoire
- module: system
period: 1m
metricsets:
- filesystem
- fsstat
processors:
- drop_event.when.regexp:
system.filesystem.mount_point: '^/(sys|cgroup|proc|dev|etc|host|lib)($|/)'
Configuration des indicateurs Docker
docker.yml: |-
- module: docker
metricsets:
- "container"
- "cpu"
- "diskio"
- "event"
- "healthcheck"
- "info"
# – "image"
- "memory"
- "network"
hosts: ["unix:///var/run/docker.sock"]
period: 10s
enabled: true
Configuration des indicateurs Kubernetes
Ceci implique de collecter les indicateurs des pods déployés sur l'hôte en communiquant avec l'API kubelet :
kubernetes.yml: |-
- module: kubernetes
metricsets:
- node
- system
- pod
- container
- volume
period: 10s
host: ${NODE_NAME}
hosts: ["localhost:10255"]
- module: kubernetes
metricsets:
- proxy
period: 10s
host: ${NODE_NAME}
hosts: ["localhost:10249"]
Pour plus d'informations sur les modules Metricbeat et les données derrière les ensembles d'indicateurs, consultez la documentation Metricbeat.
Collecte des indicateurs d'état et des événements Kubernetes
Une instance unique est déployée pour collecter les indicateurs Kubernetes. Elle est intégrée avec l'API kube-state-metrics afin de monitorer les changements d'état des objets gérés par Kubernetes. Il s'agit de la section de la configuration qui définit la collecte d'états_d'indicateurs. $HOME/k8s-o11y-workshop/Metricbeat/Metricbeat.yml :
kubernetes.yml: |-
- module: kubernetes
metricsets:
- state_node
- state_deployment
- state_replicaset
- state_pod
- state_container
# Supprimer ceci pour obtenir les événements k8s :
- event
period: 10s
host: ${NODE_NAME}
hosts: ["kube-state-metrics:8080"]
Découverte automatique de Metricbeat à l'aide des annotations de pods
Le déploiement du DaemonSet de Metricbeat peut détecter automatiquement le composant s'exécutant dans le pod et appliquer un module Metricbeat spécifique afin de collecter les indicateurs propres à la technologie. L'une des façons d'activer la découverte automatique est d'utiliser les annotations de pods pour indiquer quel module appliquer en même temps que l'autre configuration propre au module. Cette section de la configuration de Metricbeat active la découverte automatique basée sur Kubernetes. $HOME/k8s-o11y-workshop/metricbeat/metricbeat.yml :
metricbeat.autodiscover:
providers:
- type: kubernetes
host: ${NODE_NAME}
hints.enabled: true
Dans ce tutoriel, il y a deux composants qui utilisent la découverte automatique axée sur les indices :
- Définition de NGINX
$HOME/k8s-o11y-workshop/nginx/nginx.ymltemplate: metadata: labels: app: nginx annotations: co.elastic.metrics/module: nginx co.elastic.metrics/hosts: '${data.host}:${data.port}' - Définition de MySQL
$HOME/k8s-o11y-workshop/mysql/mysql.ymltemplate: metadata: labels: app: mysql annotations: co.elastic.metrics/module: mysql co.elastic.metrics/hosts: 'root:petclinic@tcp(${data.host}:${data.port})/'
Pour plus d'informations sur la découverte automatique axée sur les indices, consultez la documentation Metricbeat.
Collecte des indicateurs d'application, de type Prometheus
Notre application petclinic Spring Boot expose tout l'éventail d'indicateurs propres à l'application exposés sous une forme qui peut être scrapée par Prometheus. Vous pouvez naviguer vers le point de terminaison http de l'application sur http://
Voici un exemple de ce que consignent nos applications :
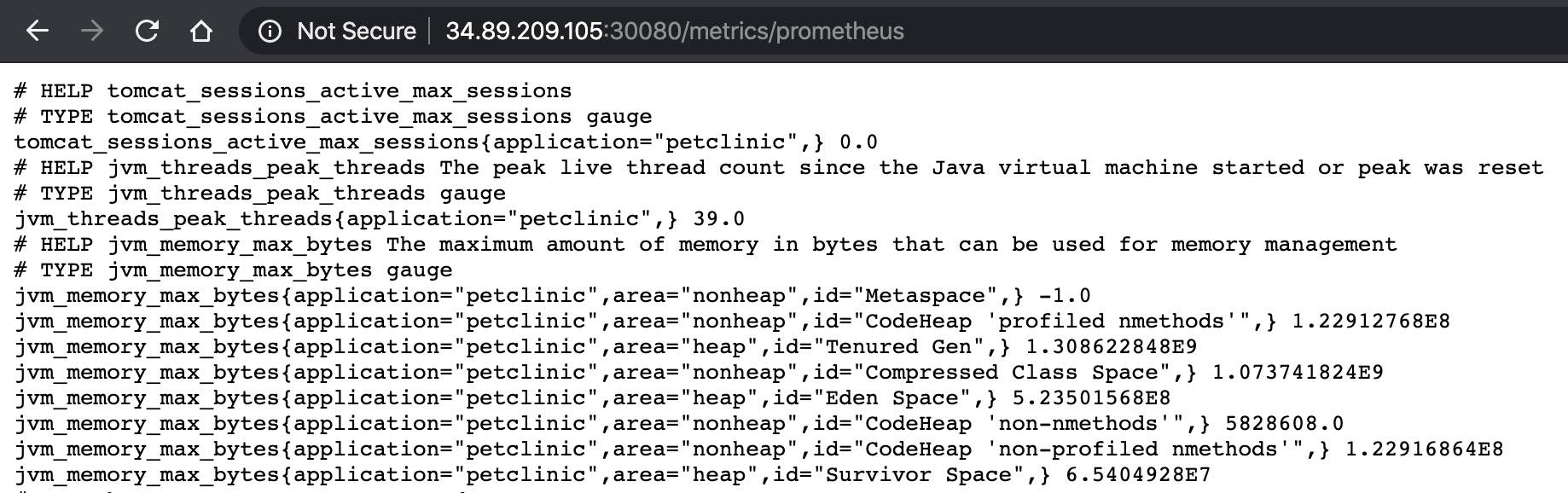
Et voici la configuration des indices dans la configuration du déploiement petclinic YAML pour dire à Metricbeat de collecter ces indicateurs en utilisant le module Prometheus. $HOME/k8s-o11y-workshop/petclinic/petclinic.yml :
template:
metadata:
labels:
app: petclinic
annotations:
co.elastic.metrics/module: prometheus
co.elastic.metrics/hosts: '${data.host}:${data.port}'
co.elastic.metrics/metrics_path: '/metrics/prometheus'
co.elastic.metrics/period: 1m
En général, Metricbeat peut augmenter ou remplacer complètement le serveur Prometheus. Si vous avez déjà déployé et que vous utilisez le serveur Prometheus, Metricbeat peut exporter les indicateurs hors du serveur en utilisant l'API Prometheus Federation, fournissant ainsi la visibilité sur plusieurs serveurs Prometheus, les espaces de nom et les clusters Kubernetes, permettant la corrélation des indicateurs Prometheus avec les événements de log, d'APM et de disponibilité. Si vous choisissez de simplifier votre architecture de monitoring, utilisez Metricbeat pour collecter les indicateurs Prometheus et les transférer directement vers Elasticsearch.
Enrichissement des métadonnées
Tous les événements collectés par Metricbeat sont enrichis par les processeurs suivants. $HOME/k8s-o11y-workshop/metricbeat/metricbeat.yml :
processors: - add_cloud_metadata: - add_host_metadata: - add_kubernetes_metadata: - add_docker_metadata:
Cela permet la corrélation des indicateurs avec les hôtes, les pods Kubernetes, les conteneurs Docker et les métadonnées d'infrastructure du fournisseur cloud, ainsi que la corrélation avec d'autres pièces du puzzle d'observabilité, comme les données et les logs de monitoring des performances applicatives.
Indicateurs dans Kibana
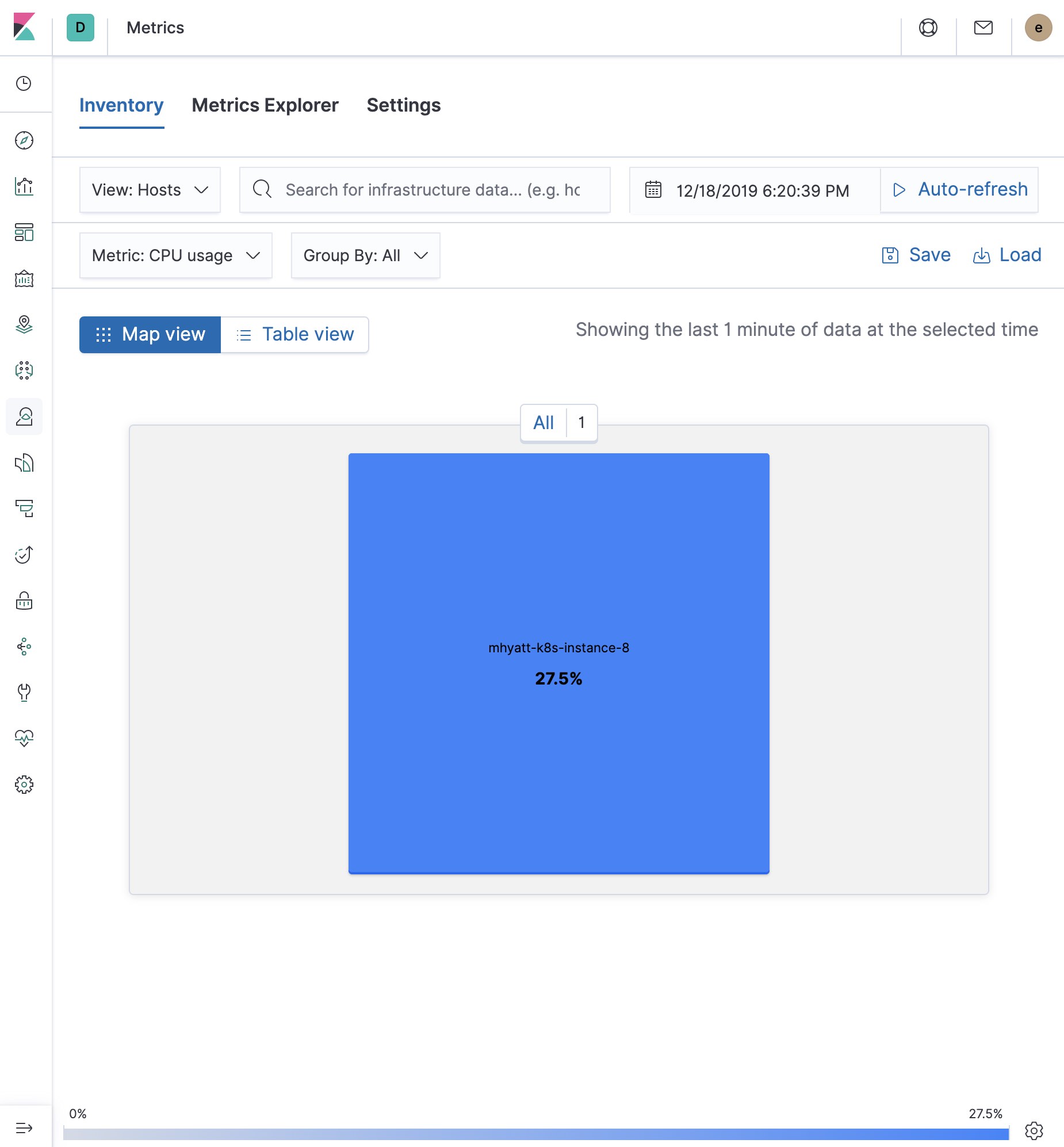
Dans notre tutoriel, notre configuration Metricbeat entraîne les différents affichages dans l'application Metrics. N'hésitez pas à cliquer et à les revoir. Remarque : où que vous alliez dans Kibana, il y a une barre de recherche qui vous permet, vous savez, de rechercher des choses. C'est une excellente façon de filtrer les affichages et de zoomer sur des choses lorsque vous cherchez cette aiguille dans une botte de foin. Dans notre tutoriel, nous avons uniquement un hôte, que voici :
Indicateurs d'infrastructure d'hôte
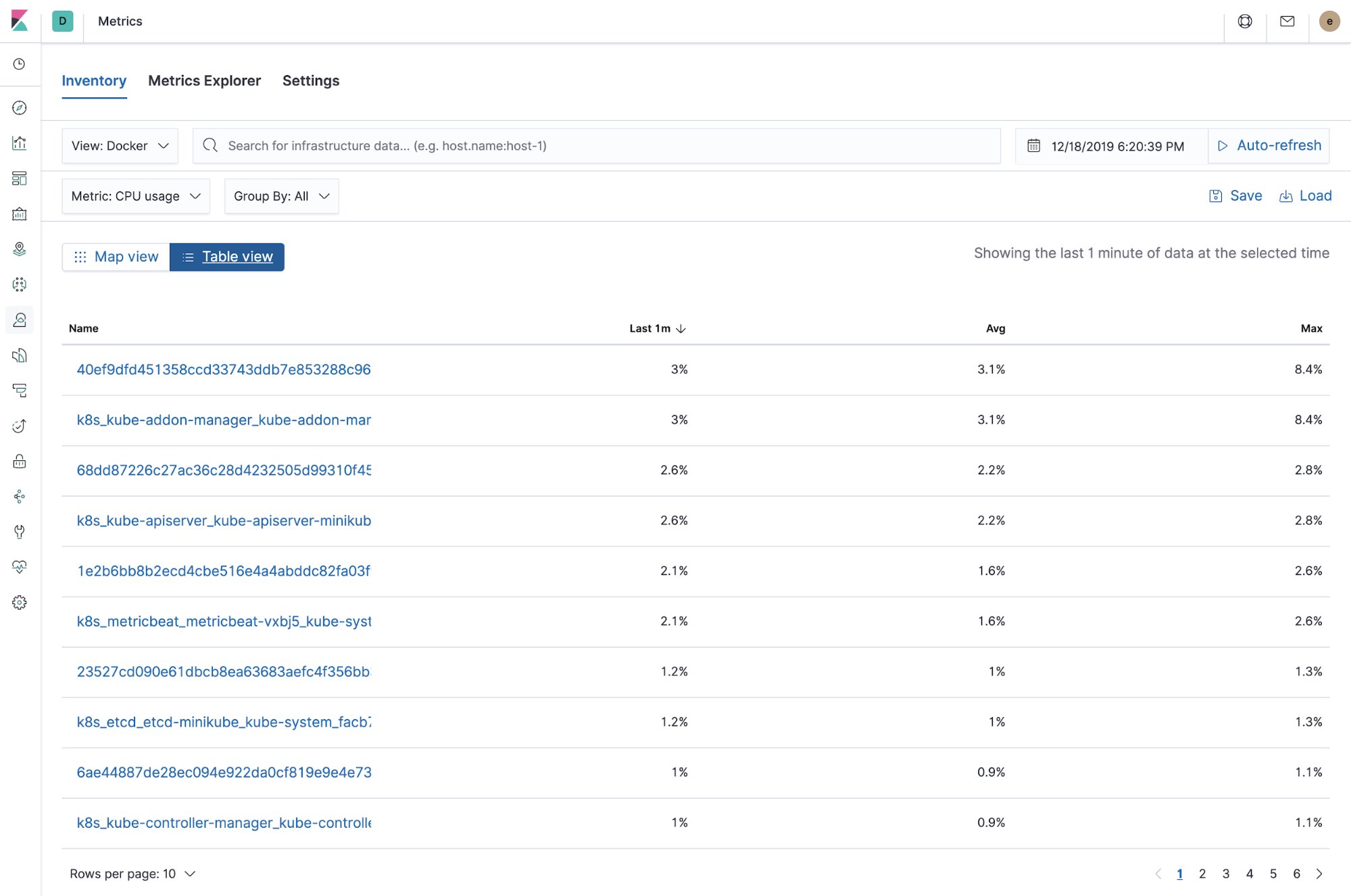
Infra et indicateurs Docker (vue en tableau)
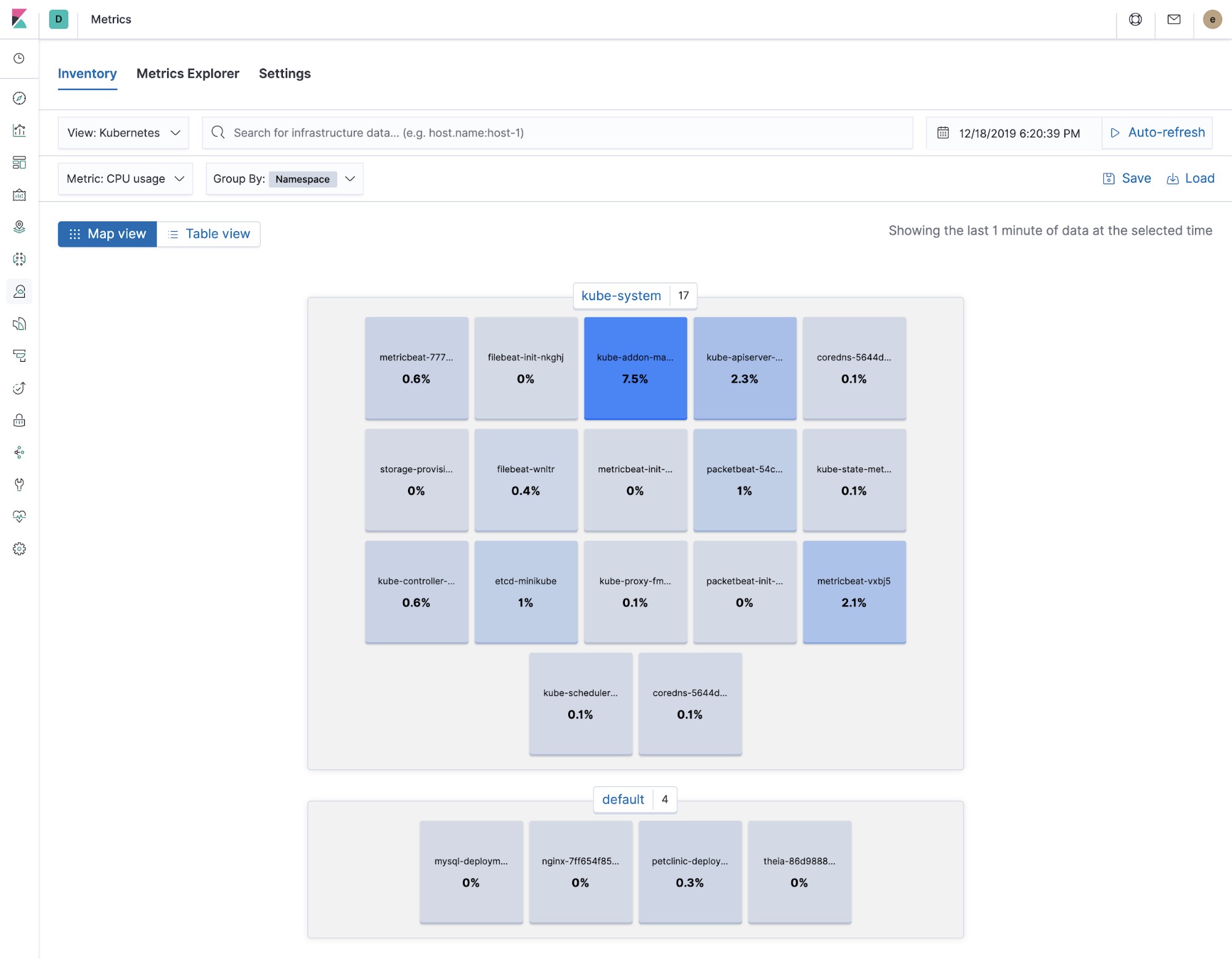
Infra et indicateurs Kubernetes
Metrics Explorer
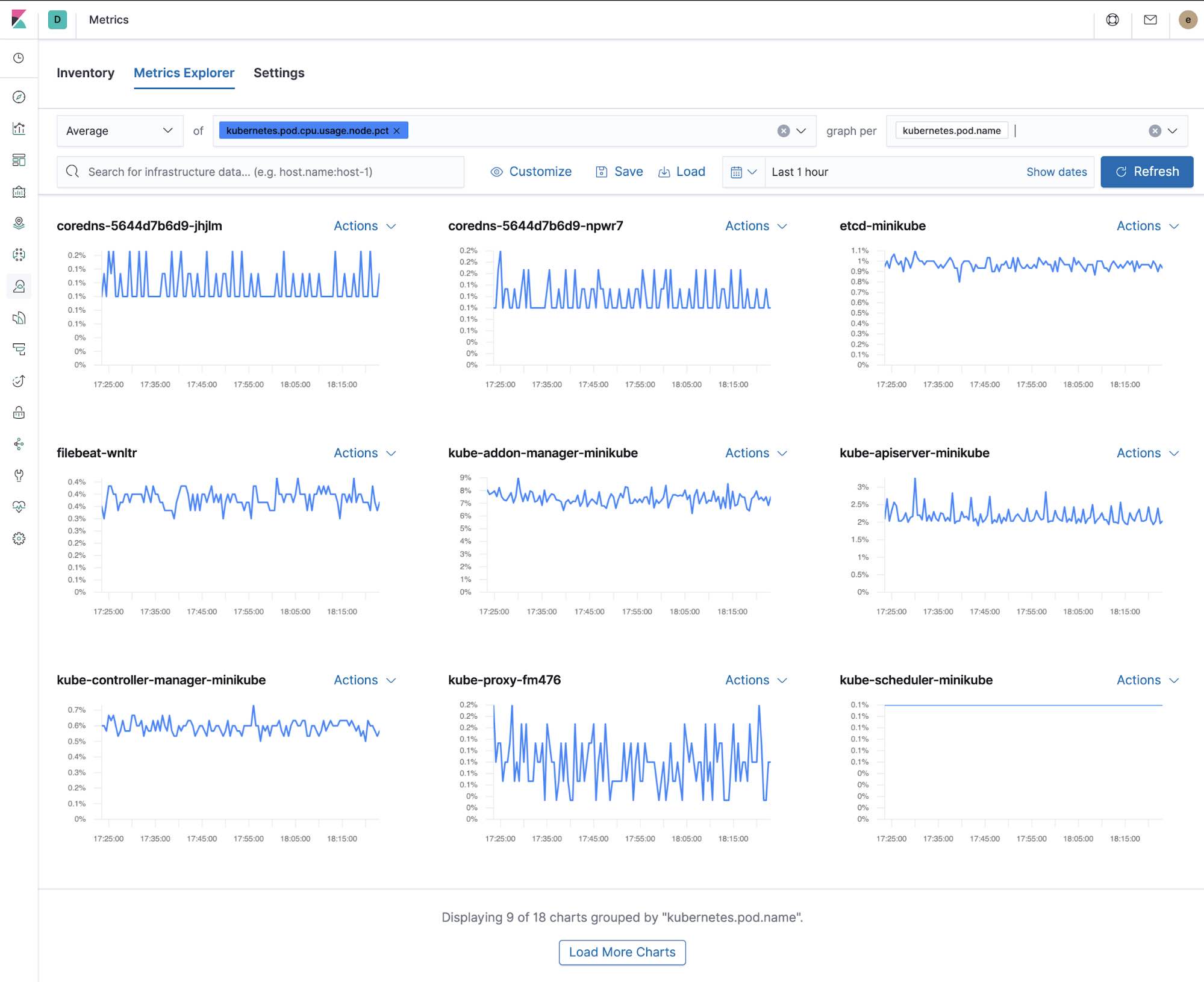
Tableaux de bord Kibana prêts à utiliser
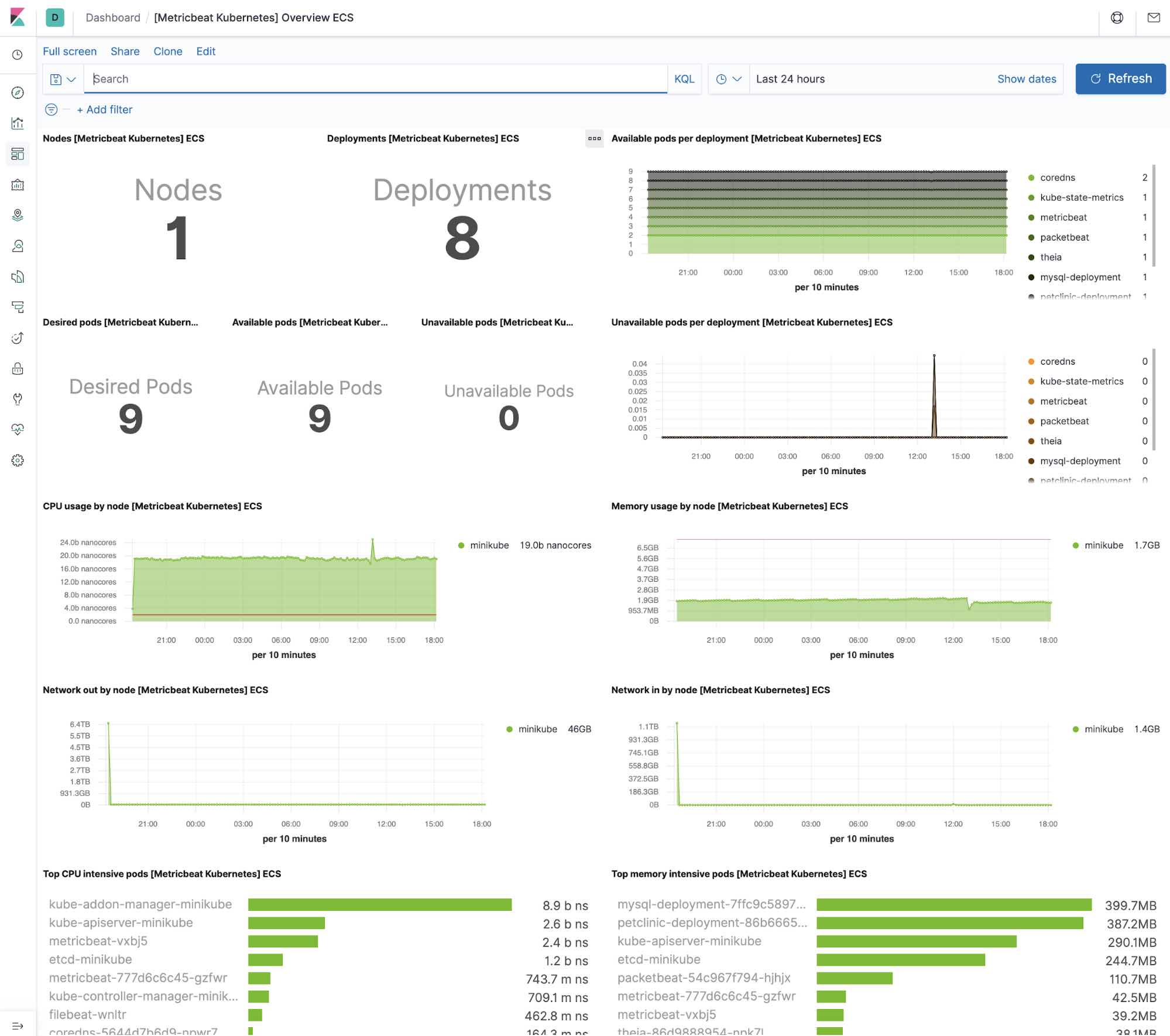
Metricbeat transfère avec une variété de tableaux de bord Kibana préintégrés qu'on peut facilement ajouter à votre cluster avec une commande unique. Vous pouvez ensuite utiliser ces tableaux de bord comme ils sont ou comme point de départ des tableaux de bord personnalisés conçus selon vos besoins. Voici les tableaux de bord qui vous aideront clairement à afficher les données depuis l'environnement de votre tutoriel.
Hôte
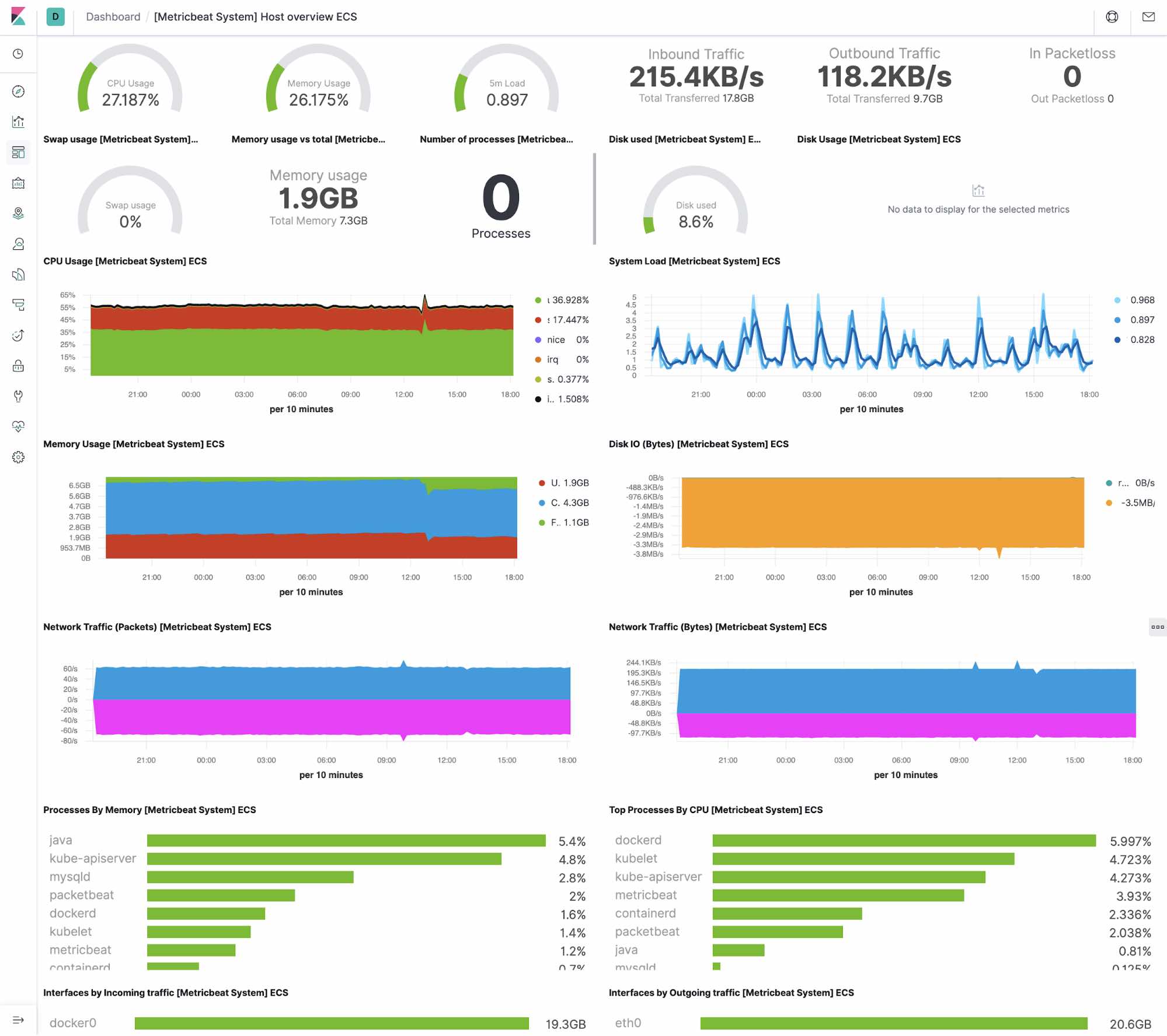
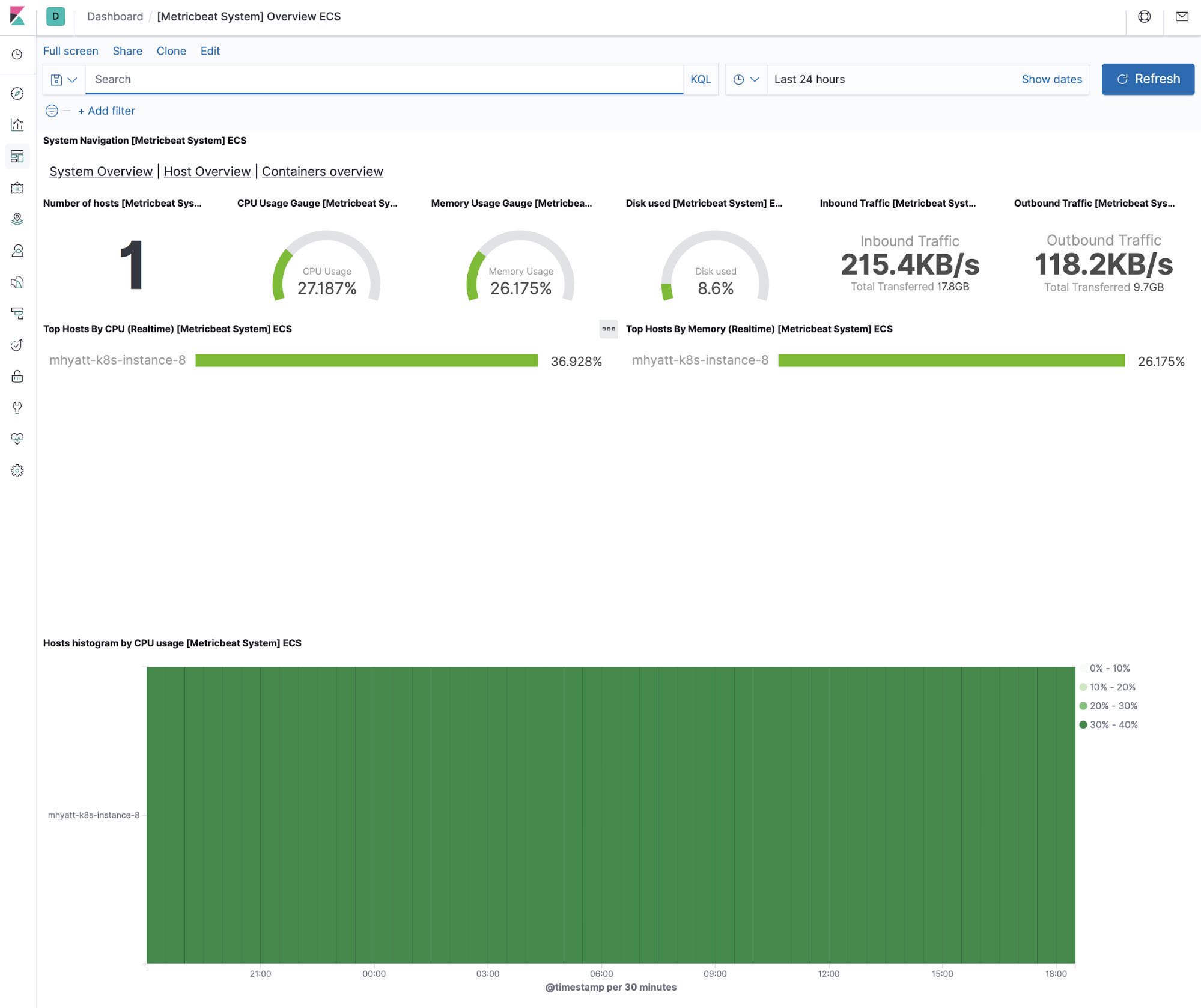
Système
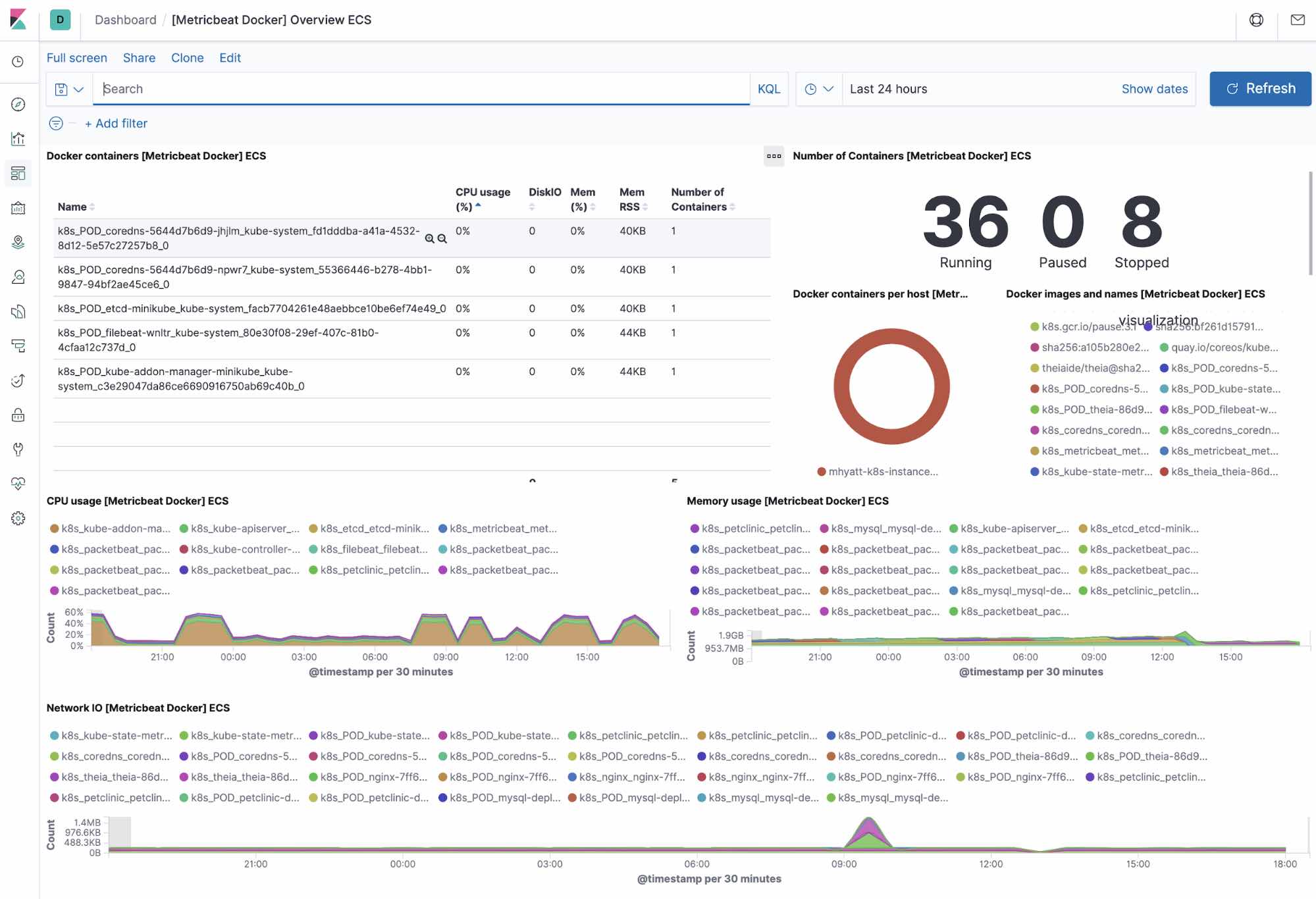
Docker
Kubernetes
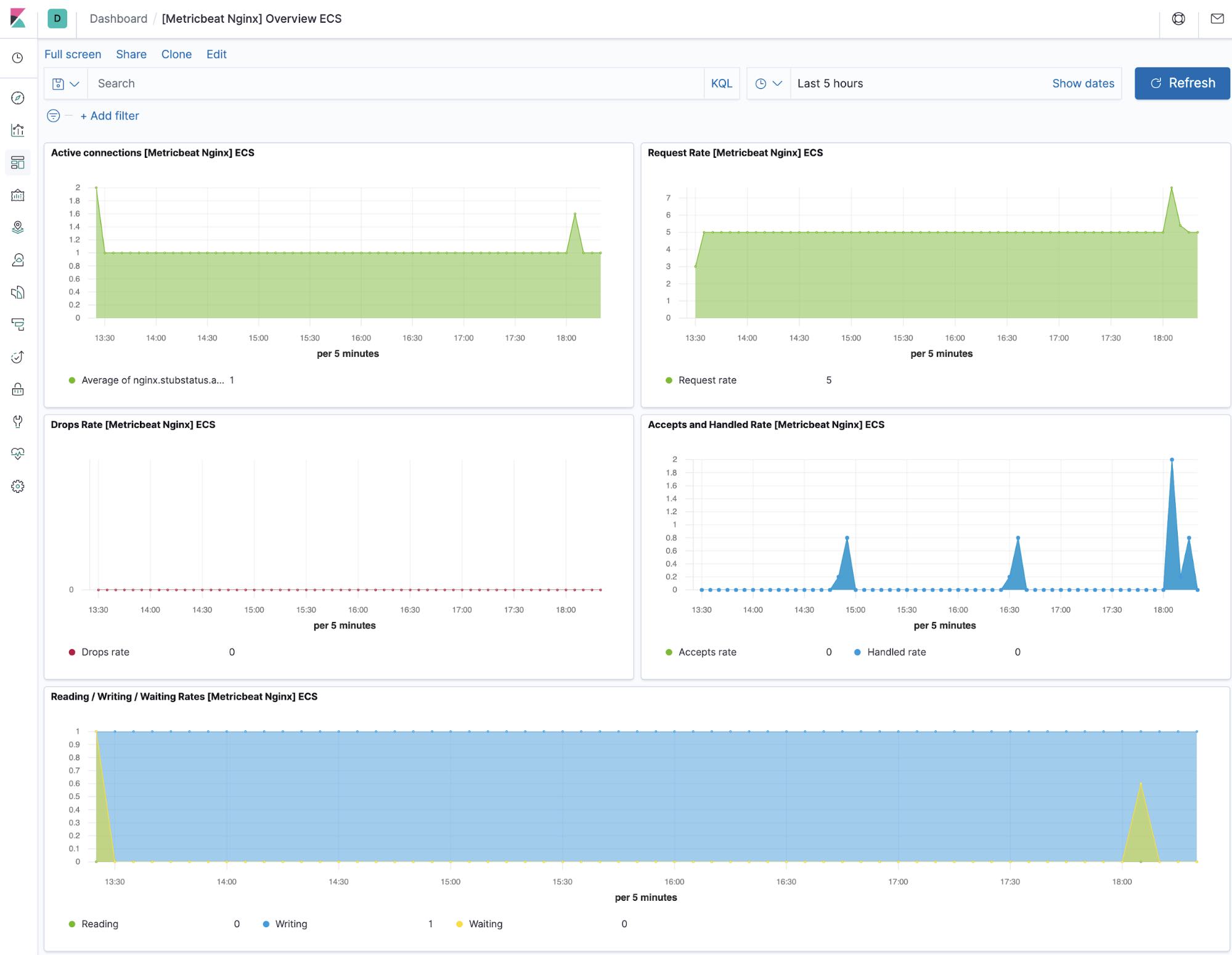
NGINX
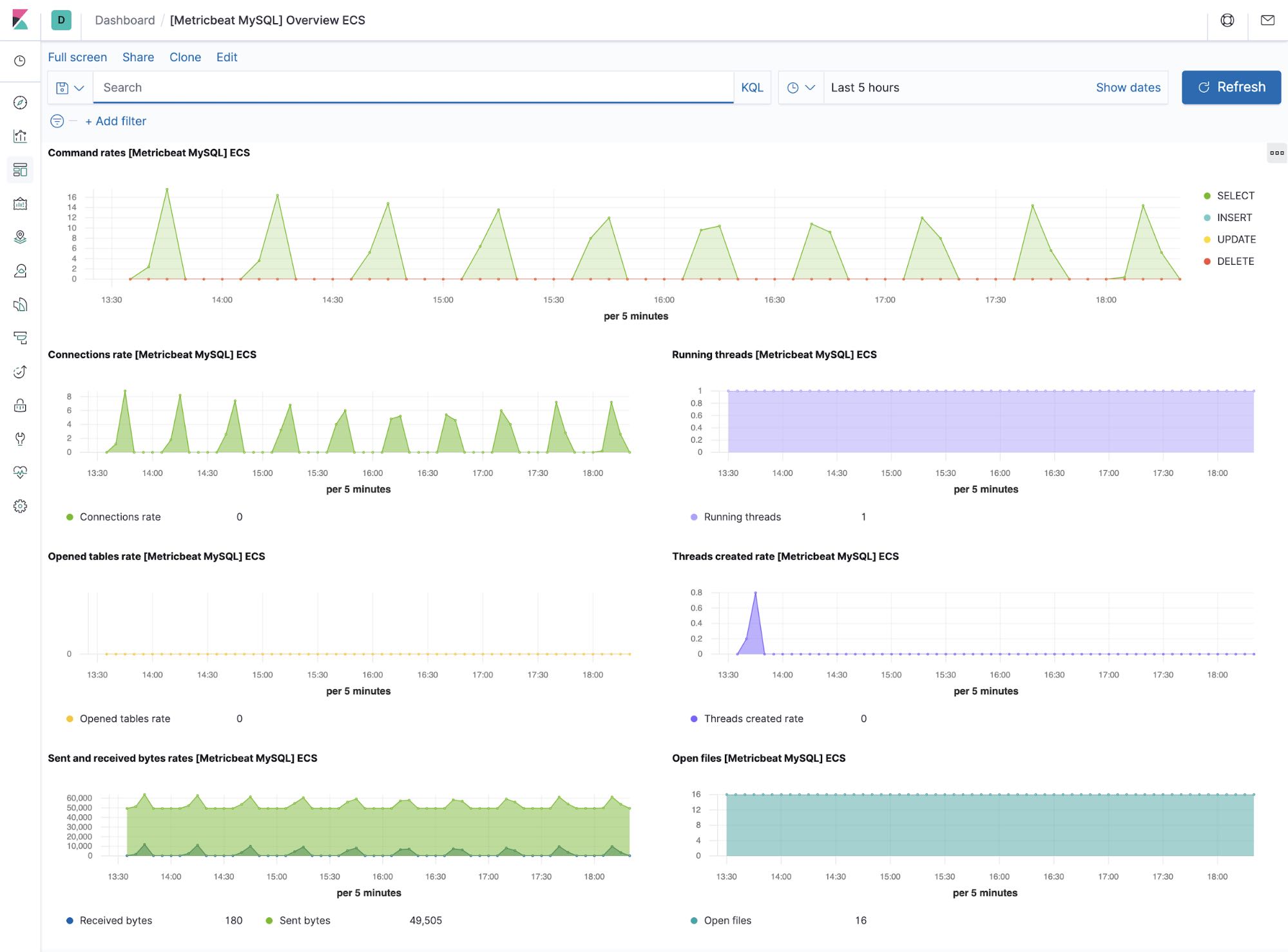
MySQL
Résumé
Dans cette partie, nous nous sommes concentrés sur la collecte des indicateurs d'application et Kubernetes avec Metricbeat. Vous pouvez commencer à monitorer vos systèmes et votre infrastructure aujourd'hui. Inscrivez-vous à un essai gratuit Elasticsearch Service sur Elastic Cloud ou téléchargez la Suite Elastic et hébergez-la vous-même.
Une fois que vous êtes opérationnel, monitorez la disponibilité de vos hôtes avec le monitoring de la disponibilité et instrumentez les applications qui s'exécutent sur vos hôtes avec Elastic APM. Vous serez en route vers un système entièrement observable, complètement intégré avec votre nouveau cluster d'indicateurs. Si vous rencontrez des difficultés ou avez des questions, allez dans nos forums de discussion, nous sommes là pour vous aider.
À suivre : Monitoring des performances applicatives avec Elastic APM