Tutoriel sur l'observabilité Kubernetes : monitoring des performances applicatives avec Elastic APM
Cet article est le troisième de notre série de tutoriels sur l'observabilité de Kubernetes, dans lesquels nous étudions comment vous pouvez monitorer tous les aspects de vos applications s'exécutant dans Kubernetes, notamment :
- Ingestion et analyse des logs
- Collecte des indicateurs de performance et d'intégrité
- Monitoring des performances applicatives avec Elastic APM
Nous discuterons de l'utilisation d'Elastic Observability pour effectuer le monitoring des performances applicatives (APM) avec Elastic APM.
| Avant de commencer : le tutoriel suivant suppose que vous disposez d'un environnement Kubernetes configuré. Nous avons créé un blog supplémentaire qui vous guide tout au long du processus de configuration d'un environnement Minikube à nœud unique avec une application de démonstration pour exécuter le reste des activités. |
Monitoring des performances applicatives
APM se concentre sur la mesure automatique des indicateurs de niveau de service (SLI) auxquels font face les utilisateurs principaux : latence des requêtes/réponses et erreurs auxquelles utilisateurs font face. En monitorant cela, vous pouvez rapidement trouver le composant (bloc de codes) responsable des problèmes comme la dégradation des performances ou une augmentation des erreurs. APM fournit un outil de tri exceptionnel de premier niveau qui peut localiser la cause d'origine du problème, réduisant le temps moyen de réponse (MTTR).
Traçage distribué avec Elastic APM
Elastic APM prend en charge le traçage distribué, ce qui permet de mesurer une latence des requêtes/réponses de bout en bout des différents composants d'application distribuée participant au service de la même requête utilisateur. L'application APM affiche la durée de traçage totale ainsi que le détail des latences liées aux composants participant au traçage distribué. Passons à l'application APM dans Kibana et regardons les traces et les transactions. Remarque : assurez-vous de générer un trafic utilisateur en cliquant d'abord dans l'application petclinic !
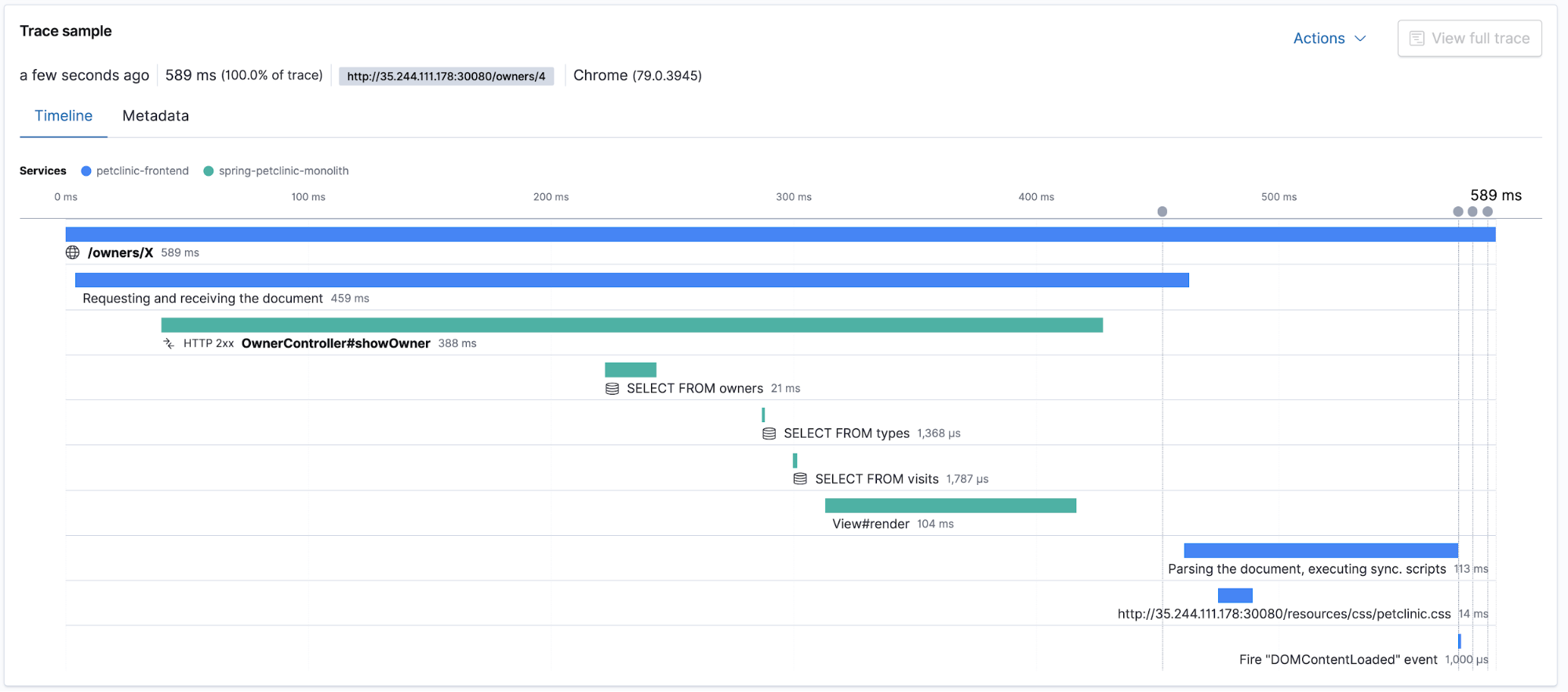
Traces dans le contexte des logs et des indicateurs
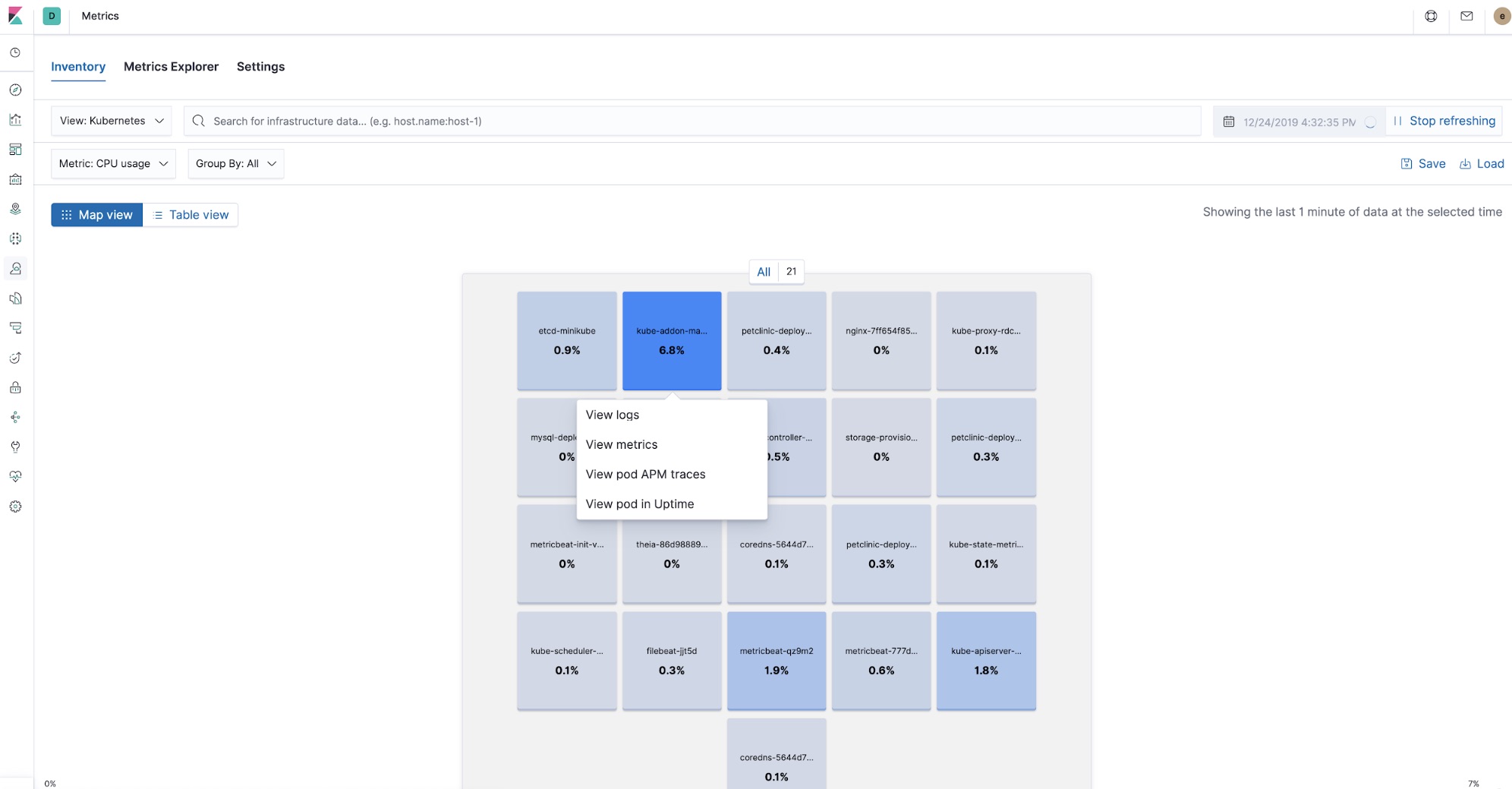
Quand il s'agit du déploiement d'une application dans Kubernetes, le traçage distribué et APM continuent de présenter l'avantage de pouvoir trier rapidement les problèmes tout en capturant et en référençant de manière croisée d'autres pièces du puzzle de l'observabilité : les logs et les indicateurs. Avec chacune des pièces au bout de vos doigts, la résolution des problèmes de pic de latence peut commencer par affiner l'étendue de la recherche à un seul composant utilisant APM, et elle peut facilement être liée aux indicateurs d'utilisation du processeur et de la mémoire, ainsi qu'aux entrées des logs d'erreurs d'un pod Kubernetes en particulier, tout cela sans quitter Kibana.
Maintenant, grâce aux processeurs dans Beats et aux métadonnées collectées par les agents APM, toutes les données d'observabilité dans Kibana sont croisées. Vous pouvez commencer à observer les traces APM, à vérifier les indicateurs des pods qui faisaient partie du traitement de cette trace et à vous concentrer sur les logs laissés par les composants qui s'exécutent au moment où la trace a été traitée, tout au même endroit.
Déploiement des agents Elastic APM
Les agents APM sont co-déployés avec les composants d'application qu'ils monitorent. Avec Kubernetes, les composants d'application font partie du code qui s'exécute dans les pods. Dans ce tutoriel, nous utilisons deux agents : l'agent JavaScript APM Real User Monitoring et l'agent APM Java.
L'agent Elastic APM Java
Il s'agit de la partie initialisation de l'agent APM Java dans le descripteur de déploiement du pod petclinic $HOME/k8s-o11y-workshop/petclinic/petclinic.yml :
env:
- name: ELASTIC_APM_SERVER_URLS
valueFrom:
secretKeyRef:
name: apm-secret
key: apm-url
- name: ELASTIC_APM_SECRET_TOKEN
valueFrom:
secretKeyRef:
name: apm-secret
key: apm-token
- name: ELASTIC_APM_SERVICE_NAME
value: spring-petclinic-monolith
- name: ELASTIC_APM_APPLICATION_PACKAGES
value: org.springframework.samplesL'agent APM est inclus comme dépendance dans le fichier pom.xml de l'application petclinic $HOME/k8s-o11y-workshop/docker/petclinic/pom.xml :
<!-- Dépendances Elastic APM -->
<dependency>
<groupId>co.elastic.apm</groupId>
<artifactId>apm-agent-attach</artifactId>
<version>${elastic-apm.version}</version>
</dependency>
<dependency>
<groupId>co.elastic.apm</groupId>
<artifactId>apm-agent-api</artifactId>
<version>${elastic-apm.version}</version>
</dependency>
<dependency>
<groupId>co.elastic.apm</groupId>
<artifactId>elastic-apm-agent</artifactId>
<version>${elastic-apm.version}</version>
</dependency>
<!-- Fin des dépendances Elastic APM -->
Ce type de déploiement est intégré dans l'agent Java comme dépendance Maven. Il existe d'autres façons de déployer les agents APM, comme pièce jointe d'exécution avec l'agent Java. Pour plus d'informations, veuillez vous reporter à la documentation sur l'agent Elastic APM Java.
L'agent Elastic APM Real User Monitoring (RUM)
L'agent RUM s'exécute dans le cadre de l'application du navigateur utilisateur et fournit tous les indicateurs auxquels fait face l'utilisateur directement depuis le navigateur. Dans ce tutoriel, il est utilisé exactement pour ça ainsi que pour le point de départ des traces distribuées. C'est l'endroit où l'agent APM est instancié dans le code côté utilisateur Javascript $HOME/k8s-o11y-workshop/docker/petclinic/src/main/resources/templates/fragments/layout.html :
<script th:inline="javascript">
...
var serverUrl = [[${apmServer}]];
elasticApm.init({
serviceName: 'petclinic-frontend',
serverUrl: serverUrl,
distributedTracingOrigins: [],
pageLoadTransactionName: pageName,
active: true,
pageLoadTraceId: [[${transaction.traceId}]],
pageLoadSpanId: [[${transaction.ensureParentId()}]],
pageLoadSampled: [[${transaction.sampled}]],
distributedTracing: true,
})
...
</script>
Petclinic est une application rendue côté serveur, Thymeleaf est une infrastructure de rendu de modèle utilisée par Spring Boot et, en tant que telle, elle génère certaines des valeurs envoyées vers le front-end, dans le code Java du contrôleur. Voici un exemple de la façon dont l'attribut du modèle de transaction est généré dans $HOME/k8s-o11y-workshop/docker/petclinic/src/main/java/org/springframework/samples/petclinic/owner/OwnerController.java :
@ModelAttribute("transaction")
public Transaction transaction() {
return ElasticApm.currentTransaction();
}
Monitoring des erreurs
Les agents APM capturent également les exceptions non gérées. Essayez de cliquer sur le menu "ERROR" (Erreur), puis vérifiez les détails des exceptions lancées de l'application APM dans Kibana.

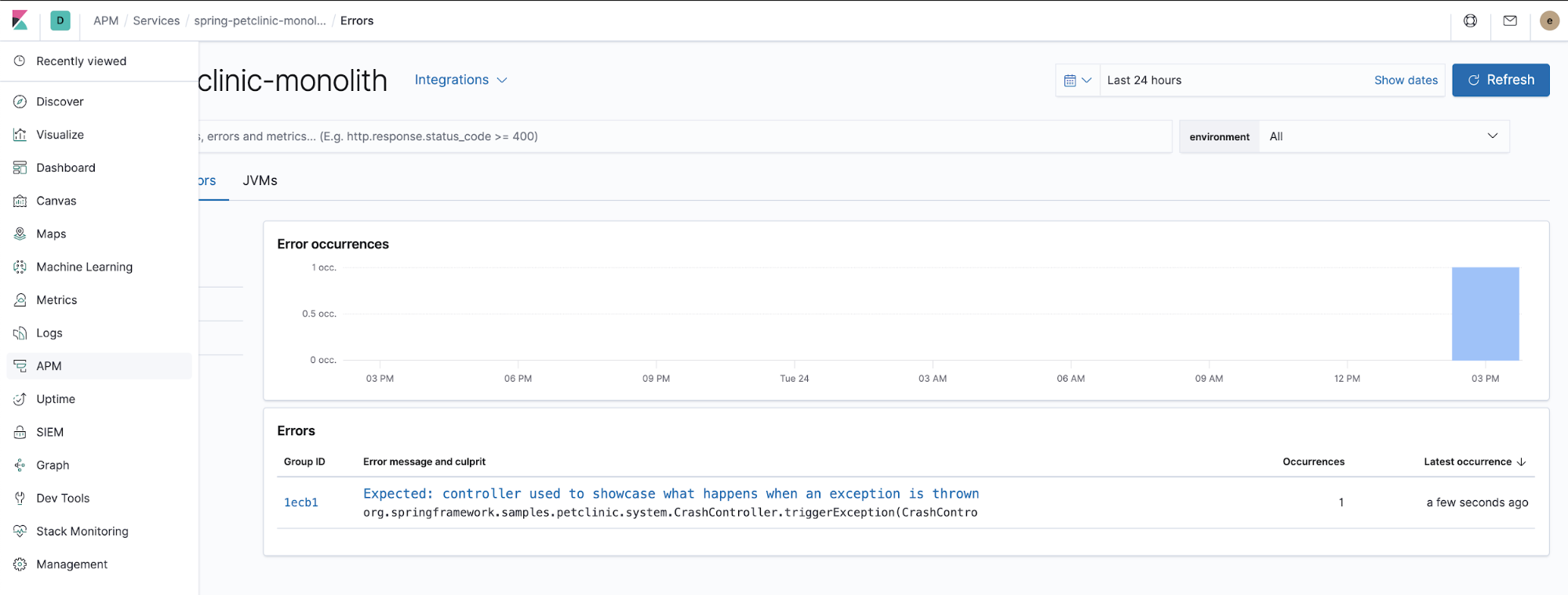
Il s'agit du code Java responsable de la façon dont l'agent APM capture les exceptions non gérées lancées par l'application. $HOME/k8s-o11y-workshop/docker/petclinic/src/main/java/org/springframework/samples/petclinic/system/CrashController.java :
@GetMapping("/oups")
public String triggerException() {
throw new RuntimeException("Expected: controller used to showcase what "
+ "happens when an exception is thrown");
}
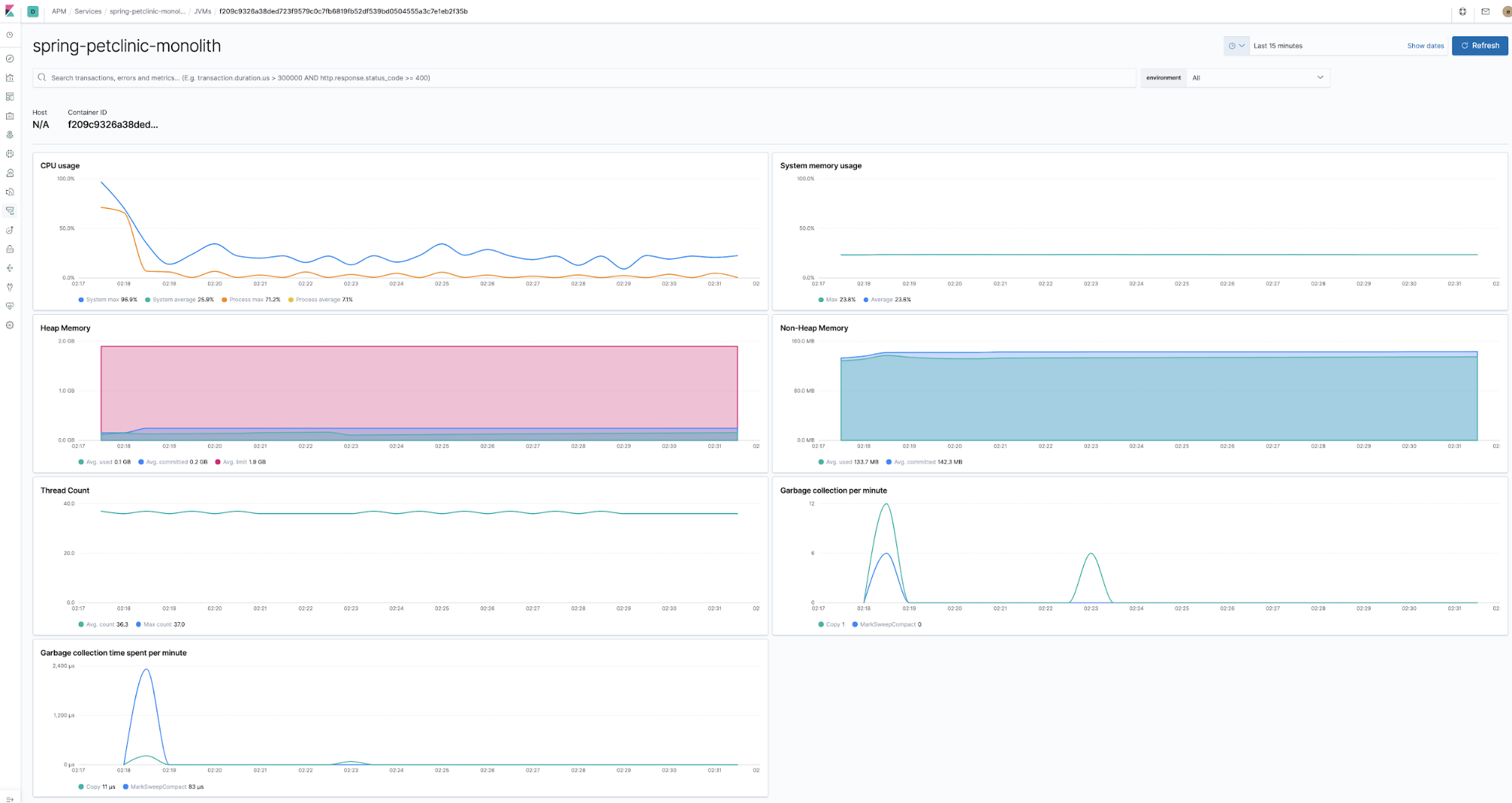
Monitoring des indicateurs d'exécution
Les agents sont co-déployés avec les composants de l'application dans l'exécution et dans la collecte des indicateurs d'exécution. Par exemple, l'agent Java les collecte directement sans qu'il soit nécessaire de fournir un code ou une configuration, outre le fait qu'il permet la collecte d'indicateurs.
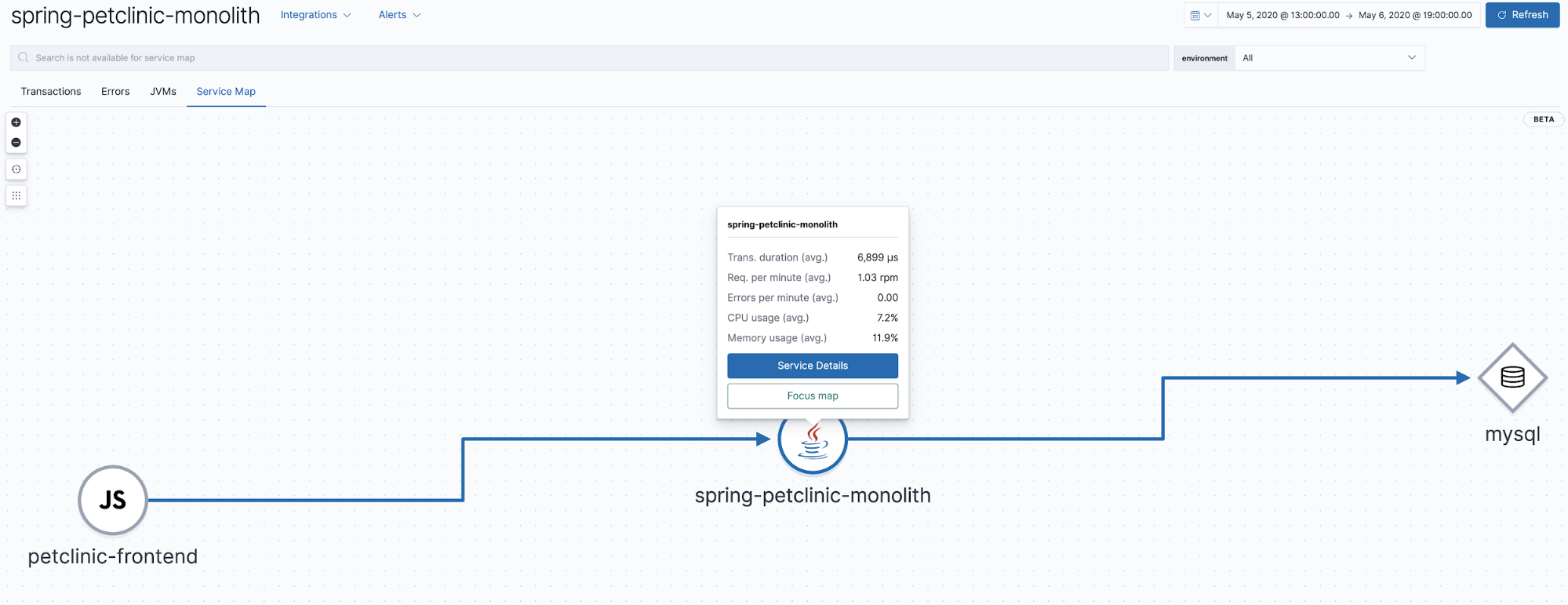
Cartes de services
Elastic APM 7.7 a introduit la version bêta des cartes de services, une représentation graphique des relations représentées dans les traces APM. Cet affichage montre quels composants sont impliqués dans les traces affichées dans l'application APM. Notre application est très simple, simplement un client navigateur avec un back-end Java et MySQL, donc la carte qui en résulte sera assez simple.
Collecte des indicateurs JMX avec un agent Elastic APM
L'agent Java peut être configuré pour collecter les indicateurs JMX exposés par l'application. Le composant Petclinic de ce tutoriel est configuré pour collecter les indicateurs suivants
$HOME/k8s-o11y-workshop/petclinic/petclinic.yml :
- name: ELASTIC_APM_CAPTURE_JMX_METRICS
value: >-
object_name[java.lang:type=GarbageCollector,name=*]
attribute[CollectionCount:metric_name=collection_count]
attribute[CollectionTime:metric_name=collection_time],
object_name[java.lang:type=Memory] attribute[HeapMemoryUsage:metric_name=heap]
Visualisation des indicateurs personnalisés avec Lens
Tous les indicateurs ne sont pas représentés dans l'application APM. Comme dans l'exemple ci-dessus, les indicateurs JMX sont très spécifiques à l'application et, par conséquent, ne peuvent pas être visualisés dans l'application APM. Aussi, parfois les indicateurs doivent faire partie d'autres visualisations ou être visualisés d'une façon différente afin qu'ils soient précieux. Les visualisations et les tableaux de bord Kibana peuvent être nativement utilisés pour visualiser ces indicateurs, mais je souhaite vous montrer une nouvelle façon excitante de le faire même plus rapidement.
Récemment, Lens a été introduit dans Kibana comme un outil de visualisation plus intuitif encouragé par les analystes. Cet exemple peut montrer comment Lens peut être utilisé pour visualiser un indicateur JMX personnalisé collecté par l'agent.
Exemple de Lens
Pour rendre les choses intéressantes, exécutons une commande hors échelle pour augmenter le nombre de pods du composant petclinic, afin d'obtenir plusieurs lignes par JVM en exécution.
$ kubectl scale --replicas=3 deployment petclinic-deployment # Le fait de valider le hors échelle a fait ce qu'on a supposé $ kubectl get pods
Vous devez voir ce qui suit :
NAME READY STATUS RESTARTS AGE mysql-deployment-7ffc9c5897-grnft 1/1 Running 0 37m nginx-7ff654f859-xjqgn 1/1 Running 0 28m petclinic-deployment-86b666567c-5m9xb 1/1 Running 0 9s petclinic-deployment-86b666567c-76pv7 1/1 Running 0 9s petclinic-deployment-86b666567c-gncsw 1/1 Running 0 30m theia-86d9888954-867kk 1/1 Running 0 43m
Maintenant, voici la puissance de Lens :
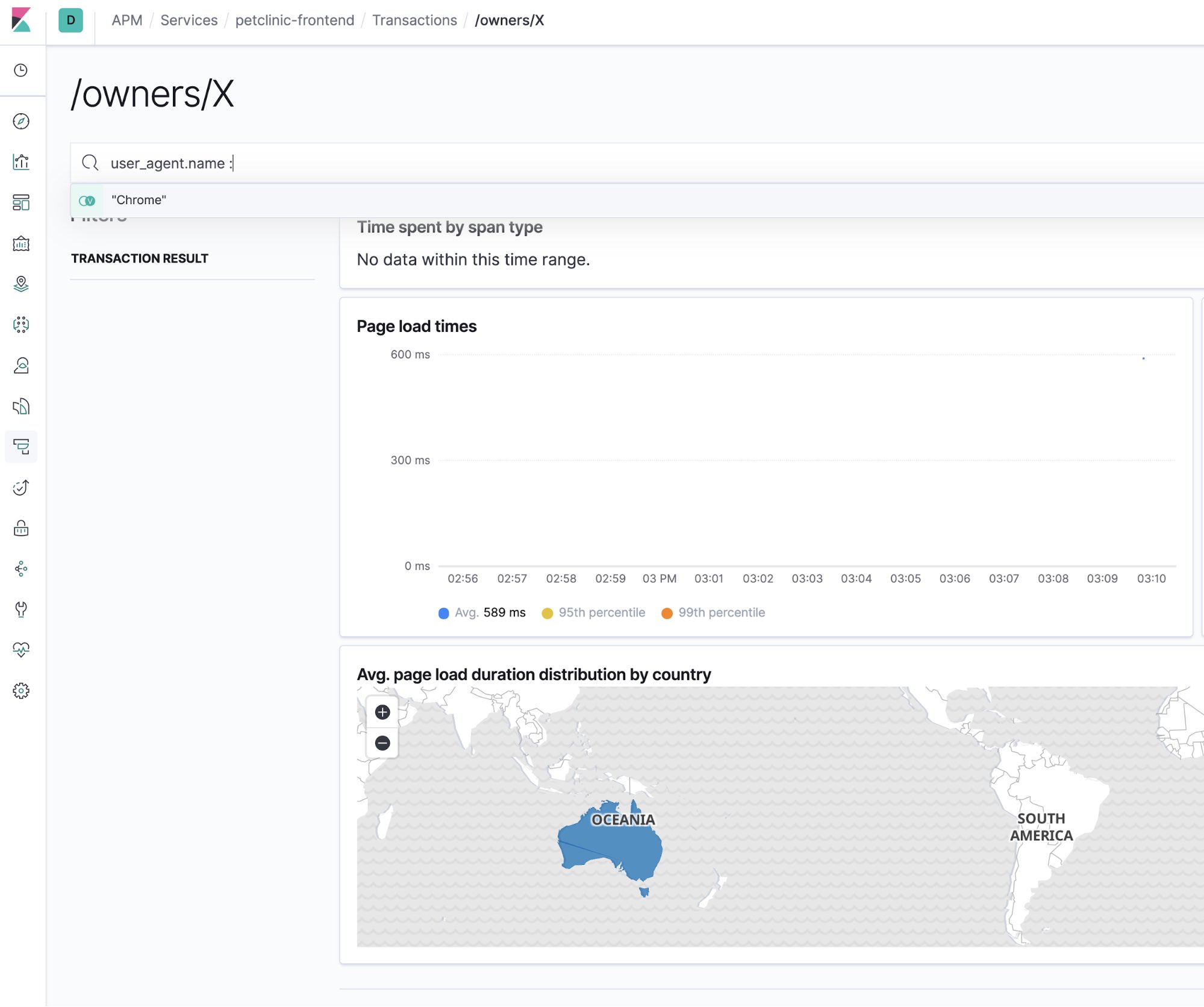
Barre de recherche. Vous savez, pour la recherche
Bien sûr, l'application Elastic APM possède une barre de recherche. Et c'est idéal pour la recherche de cette aiguille dans une botte de foin afin de limiter l'étendue du problème que vous essayez d'évaluer. Par exemple, voici comment la vue de l'interface utilisateur APM peut être limitée à un type de navigateur en particulier :
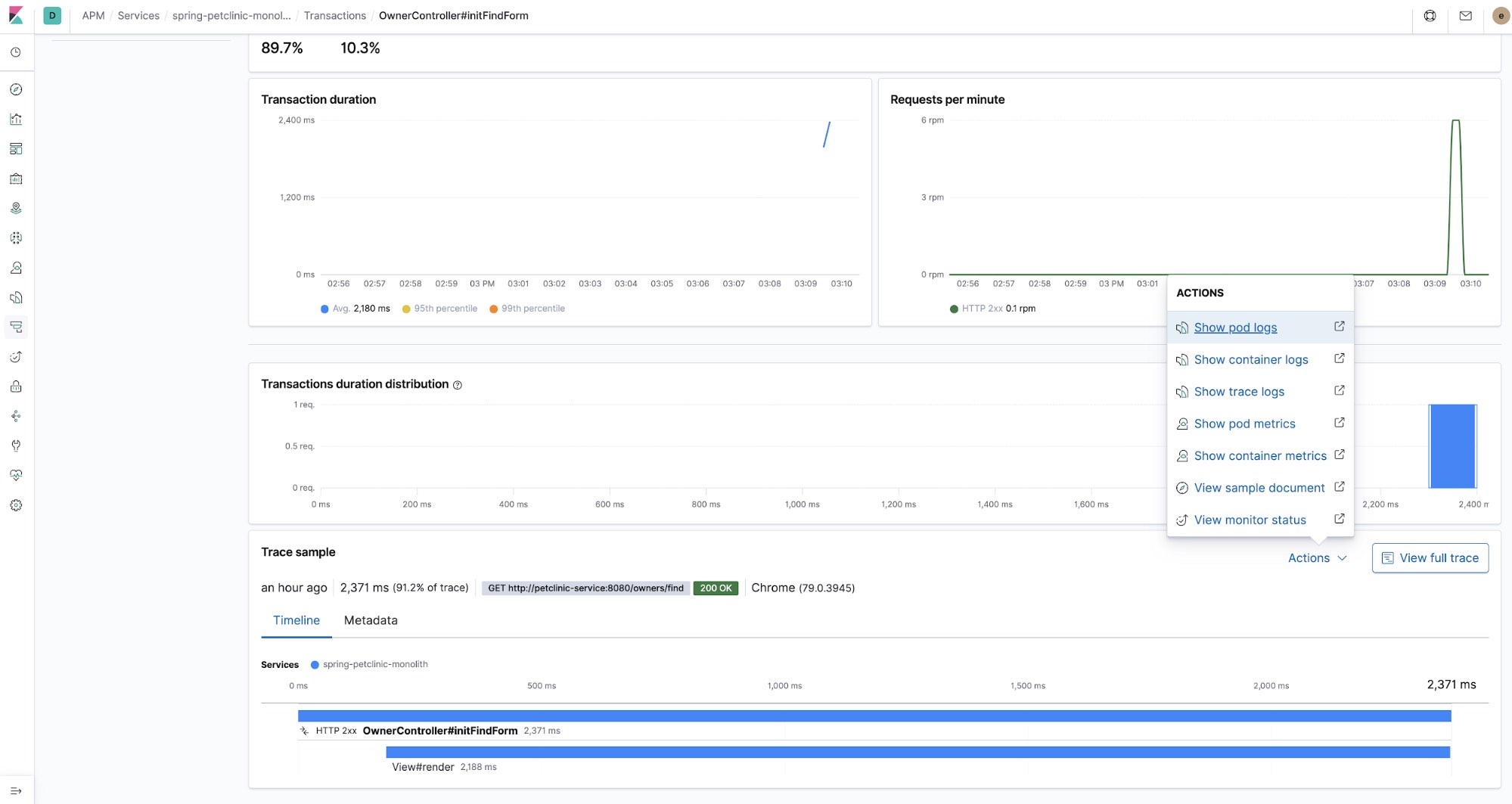
Corrélation des traces APM et des logs
Un autre exemple utile de l'ensemble qui est plus que ses composants, c'est la corrélation des traces APM avec les entrées de logs qui étaient produites par le code tracé. Les traces APM peuvent être liées aux entrées de log par leur champ trace.id<code>. Et tout cela se produit sans beaucoup d'efforts, seulement avec quelques configurations simples. Tout d'abord, voyons un exemple d'une corrélation de ce type.
Regardons une trace :
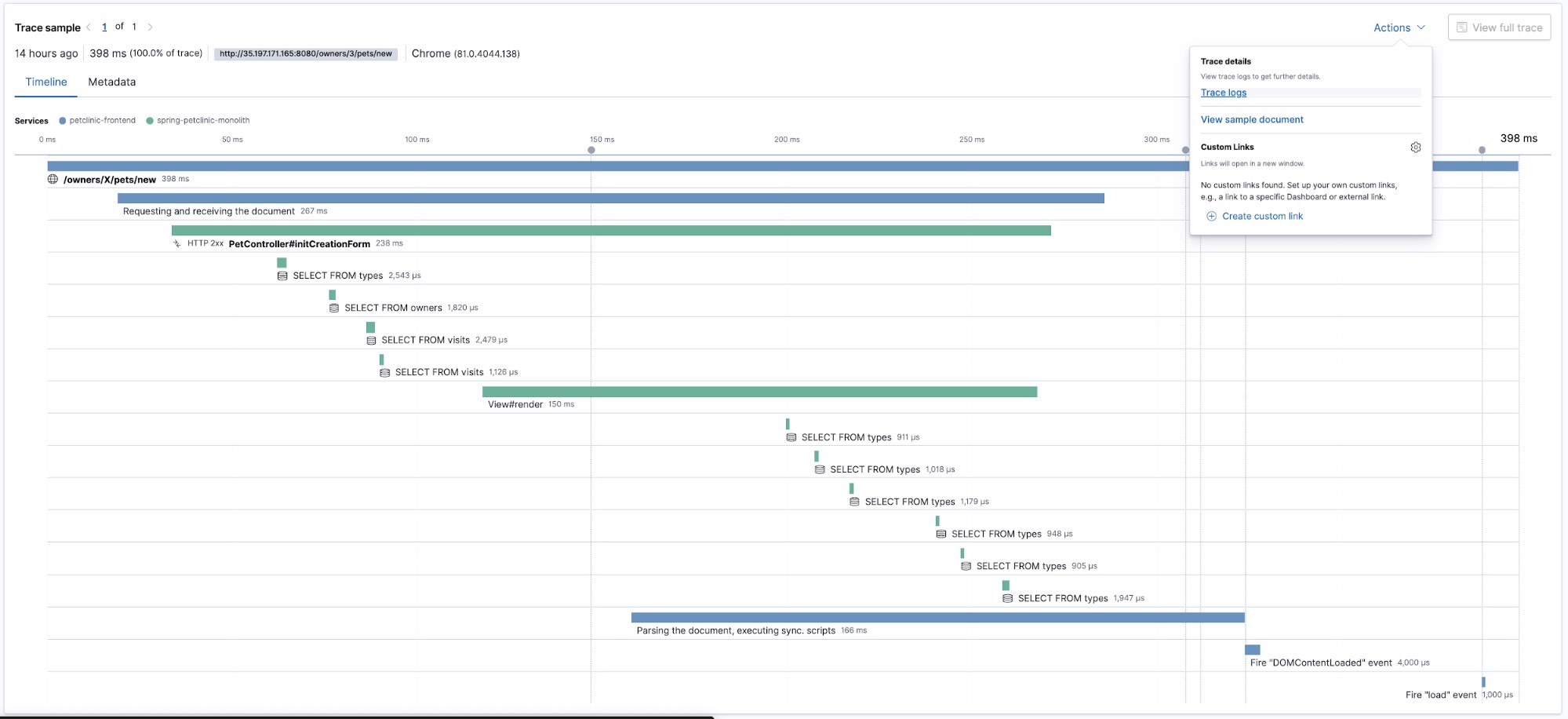
Cette trace nous montre la vue chronologique de comment différents morceaux du code ont été exécutés. Maintenant, voyons quels logs ont été produits par le code que nous avons juste tracé. Nous sélectionnerons Trace logs (Logs de trace) dans le menu Actions (Actions). Cette action nous dirigera vers l'interface utilisateur Logs présélectionnant le moment où les données de trace ont été capturées et elle utilisera le trace.id pour filtrer les données de log annotées avec le même trace.id :
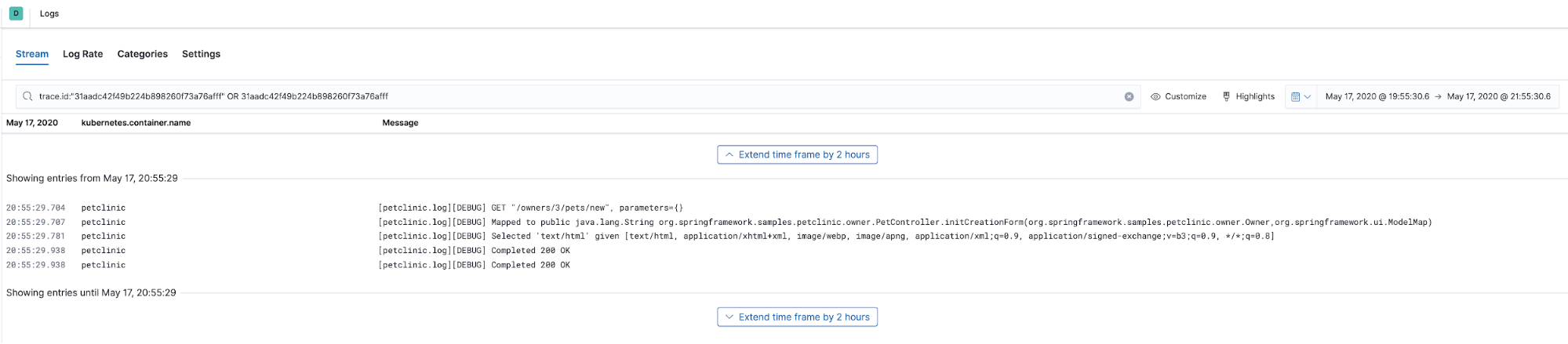
Manifestement, trace.id est inhérent aux traces APM, mais comment avons-nous géré pour enrichir les données de logs avec ça ? Tout d'abord, depuis que nous utilisons l'Agent Elastic APM Java, nous avons utilisé la fonctionnalité de corrélation de logsqu'il implémente. En substance, il génère les champs trace.id et transaction.id dans la carte de contexte MDC de l'infrastructure de logging Java (logback dans le cas de Spring Boot). Il suffit de définir une variable d'environnement dans ConfigMap petclinic petclinic/petclinic.yml :
- name: ELASTIC_APM_ENABLE_LOG_CORRELATION
value: "true"Puis, le logging de l'application petclinic est configuré avec le logging ECS qui enrichit les entrées de log envoyées vers la suite Elastic avec des champs supplémentaires correspondant au Elastic Common Schema, comme log.level, transaction.id, etc. Afin de permettre cela, nous avons inclus la dépendance suivante dans le pom.xml de l'application petclinic :
<dependency>
<groupId>co.elastic.logging</groupId>
<artifactId>logback-ecs-encoder</artifactId>
<version>${ecs-logging-java.version}</version>
</dependency>
Il y a également le fichier docker/petclinic/src/main/resources/logback-spring.xml avec le logging ECS configuré pour être établi comme JSON vers stdout :
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="co.elastic.logging.logback.EcsEncoder">
<serviceName>petclinic</serviceName>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="console"/>
</root>
Enfin, il y a l'annotation sur la ConfigMap petclinic (petclinic/petclinic.yml) qui exploite la découverte automatique des beats pour ordonner à Filebeat d'analyser le JSON qui en résulte sortant de petclinic :
container:
annotations:
...
co.elastic.logs/type: "log"
co.elastic.logs/json.keys_under_root: "true"
co.elastic.logs/json.overwrite_keys: "true"
Ainsi, pour permettre à cette corrélation de fonctionner, nous devons activer les deux, l'agent Java et l'infrastructure de logging pour logger les corrélations de trace, et nous pouvons lier les deux morceaux de données d'observabilité ensemble.
Il s'agit d'un emballage de séries
Logs, Metrics et APM...nous l'avons fait ! Dans cette série de blogs, nous avons regardé l'instrumentation d'une application pour collecter ses traces de Logs, Metrics et APM avec la Suite Elastic à l'aide de Filebeat, de Metricbeat et d'APM. Le tutoriel démontre également comment collecter les logs et les indicateurs Kubernetes utilisant les mêmes composants. Il y a des composants supplémentaires dans l'écosystème Elastic qui peut ajouter plus d'informations pour compléter l'image d'observabilité de votre environnement Kubernetes :
- Heartbeat – Une façon idéale de mesurer la disponibilité et la réactivité de votre application et l'environnement total Kubernetes. Il peut être déployé en dehors de votre cluster vers où vos utilisateurs sont. Heartbeat peut illustrer comment vos utilisateurs voient votre application, quel type de réseau et de latence de réponse ils observent, et à combien d'erreurs ils sont exposés.
- Packetbeat – Obtenez la vue du trafic du réseau du cluster Kubernetes interne, des établissements de liaison des certificats TLS, des recherches DNS, etc.
- J'ai inclus un exemple de déploiement du bloc-notes Jupyter et j'ai ajouté un exemple de bloc-notes qui illustre comment vous pouvez accéder aux données brutes d'observabilité stockées dans Elasticsearch, ceci afin que vous puissiez faire une formidable science des données :
k8s-o11y-workshop/jupyter/scripts/example.ipynb
N'hésitez pas à devenir un contributeur sur le référentiel Github ou à soulever un problème Github si quelque chose ne fonctionne pas comme prévu.
Vous pouvez commencer à monitorer vos systèmes et votre infrastructure aujourd'hui. Inscrivez-vous à un essai gratuit Elasticsearch Service sur Elastic Cloud ou téléchargez la Suite Elastic et hébergez-la vous-même. Une fois que vous êtes opérationnel, monitorez la disponibilité de vos hôtes avec Elastic Uptime et instrumentez les applications s'exécutant sur vos hôtes avec Elastic APM. Vous serez en route vers un système entièrement observable, complètement intégré avec votre nouveau cluster d'indicateurs. Si vous rencontrez des difficultés ou avez des questions, allez dans nos forums de discussion, nous sommes là pour vous aider.