Blogs
Developer insights and practical how-to articles from our experts to inspire and empower your search experience.

Your agents have been keeping receipts: turning Elastic Agent Builder's built-in OTel traces into token cost dashboards in Kibana
Your Agent Builder agents already log every LLM call as an OTel trace, and that agent tracing data can power token cost dashboards and budget alerts before one runaway conversation quietly wrecks your month.

One prompt, a complete workflow: Elastic's AI agent writes your automation for you
Elastic Workflows takes a plain-text prompt and generates YAML you can inspect, version and run against your Elasticsearch data. Now GA, with human-in-the-loop workflows in Slack, parallel execution, and 10 new connectors.

17% faster search, zero config: auto-calibrating vector quantization in Elasticsearch
Automatic calibration at merge time picks vector quantization parameters for each segment by predicting recall from a small sample. Here's how we built it into Elasticsearch's merge path.

56% faster, up to 50% better retrieval performance: What's inside Jina's new 600 million parameter listwise reranker
Jina Reranker 3.5 beats v3 by 50%+ on case law, closes the gap with models 7x its size on legal, medical, and financial benchmarks, and beats them outright on structured data. It's a drop-in replacement for v3, with no API changes.
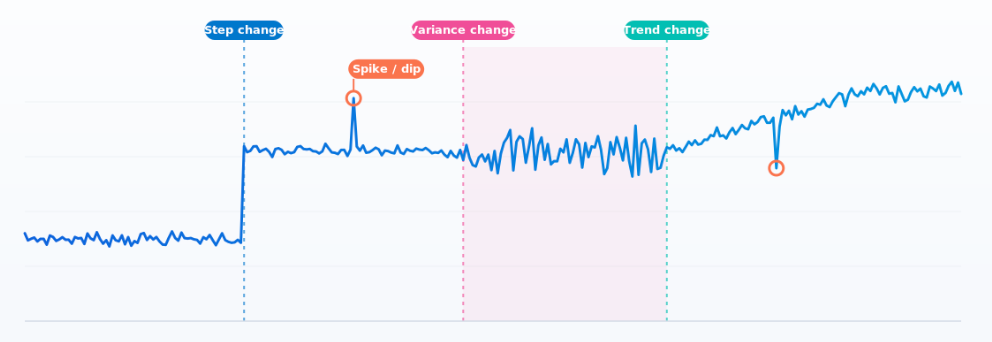
How Elasticsearch detects multiple change points in time series with 0.99 recall
ES|QL's CHANGE_POINT command finds structural shifts, variance changes and spikes in any metric in ~1ms, without tuning anything per series.
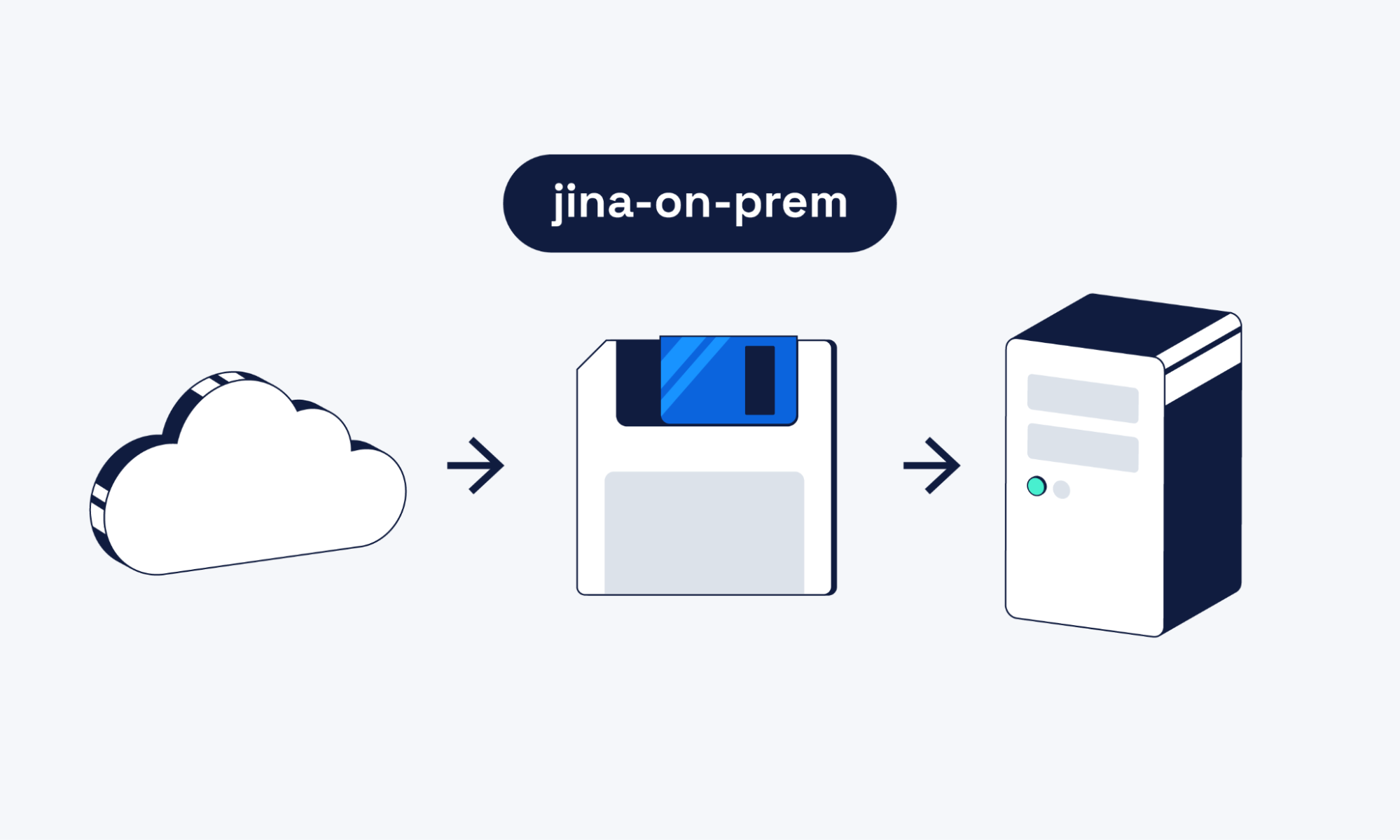
On-prem in under 5 minutes: Jina embedding models now available for on-prem deployment
All 28 Jina AI models, including rerankers, as ready-to-deploy Docker containers, with zero telemetry and no license server. Drop-in compatible with OpenAI, Cohere, Voyage AI and Elastic Inference Service APIs.
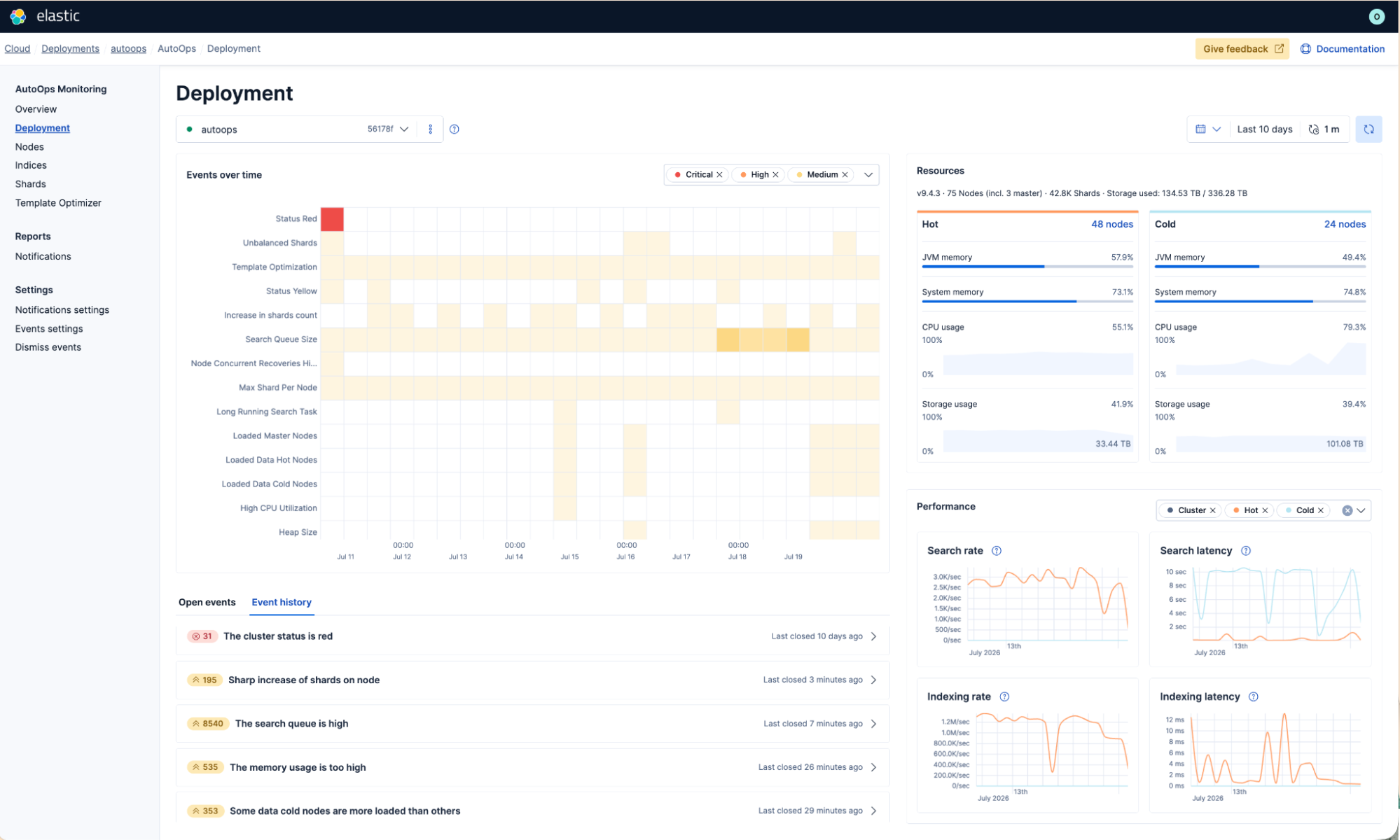
Faster Elasticsearch issue triage with redesigned AutoOps
AutoOps introduces clearer severity, updated page layouts, and simpler issue triage for Elastic Cloud Hosted deployments and Cloud Connect clusters.
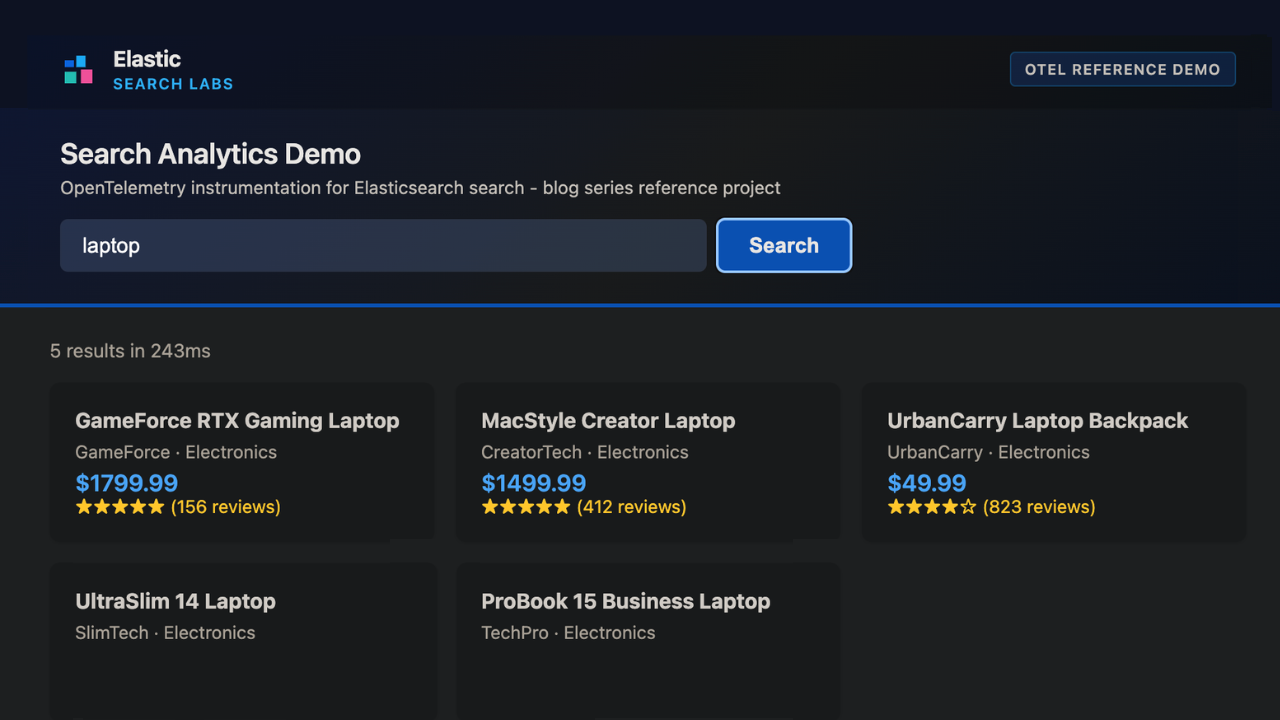
How to instrument your search API with OpenTelemetry and query it with ES|QL
Add custom attributes to OpenTelemetry spans and run six ES|QL queries that reveal your top searches, zero-result rate and slowest queries.
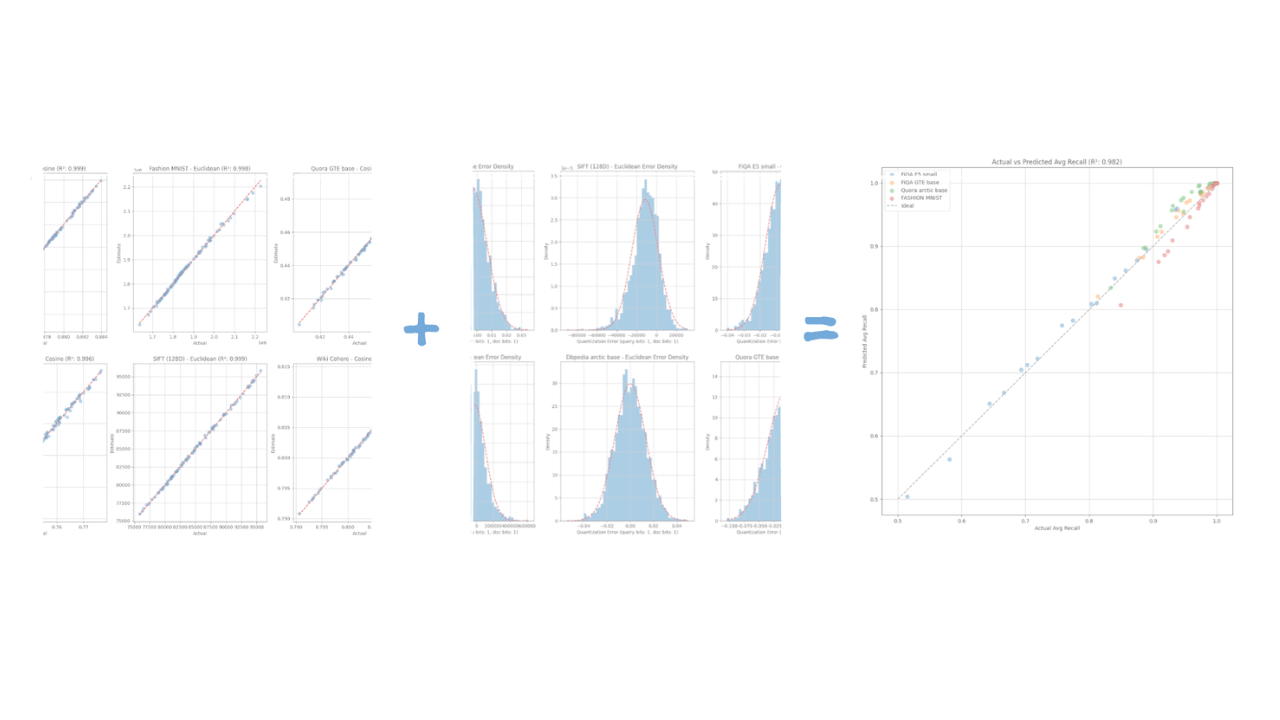
How Elasticsearch auto-tunes vector quantization to hit your recall target
Learn the geometric model that lets Elasticsearch predict recall with R² > 0.98 accuracy and auto-select vector quantization parameters from a small data sample.

4 NVIDIA AI tasks, 1 Elasticsearch API: Embeddings, chat, completion, and rerank
Set up NVIDIA hosted models in Elasticsearch with one API key and a model ID. No custom integration code needed.
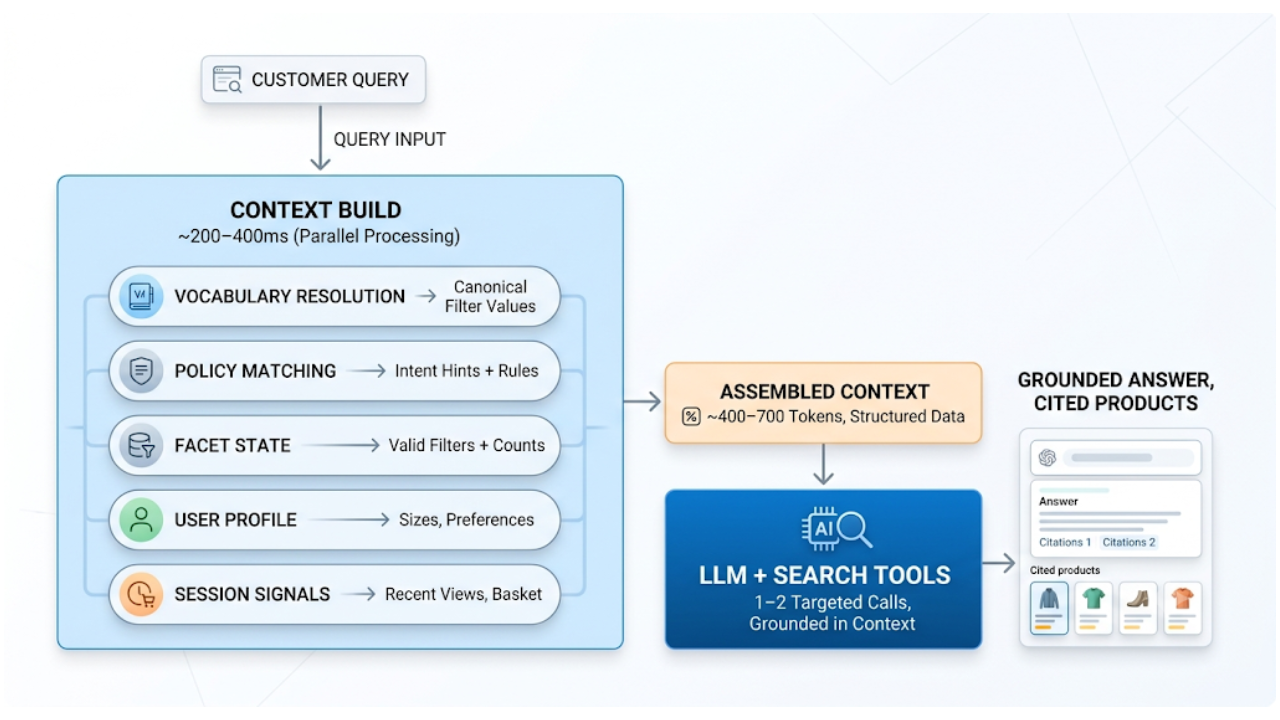
AI shopping agents: Why context comes before the query
AI shopping agents that guess at your vocabulary make expensive mistakes. Pre-computed catalog context stops the guessing before the first tool call.