Utilisation de Spring Boot avec Elastic App Search


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Dans cet article, nous verrons comment créer de toutes pièces une application Spring Boot pour interroger Elastic App Search, qui a indexé le contenu d'un site web. Nous démarrerons le cluster et configurerons l'application pas à pas.
Création d'un cluster
Pour suivre l'exemple ci-dessous, le plus simple est de cloner le référentiel GitHub proposé en exemple. Vous pourrez ainsi exécuter terraform et être opérationnel immédiatement.
git clone https://github.com/spinscale/spring-boot-app-searchPour avoir un exemple fonctionnel, nous devons créer une clé d'API dans Elastic Cloud comme décrit dans la configuration du fournisseur terraform.
Une fois la clé créée, exécutez :
terraform init
terraform validate
terraform applyPuis, prenez le temps de boire un petit café avant de vous attaquer aux choses sérieuses. Au bout de quelques minutes, vous devriez voir apparaître votre instance dans l'interface utilisateur Elastic Cloud, comme ceci :
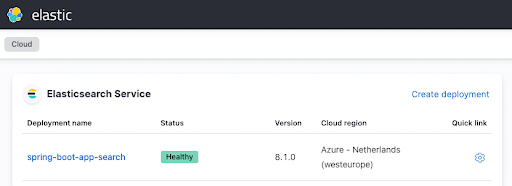
Configuration de l'application Spring Boot
Avant de continuer, vérifions que nous pouvons créer et exécuter l'application Java. Pour cela, nous avons besoin d'avoir Java 17 installé. Lorsque c'est le cas, exécutons :
./gradlew clean checkCette commande téléchargera toutes les dépendances, exécutera les tests et échouera. Oui oui, vous avez bien lu. Et c'est tout à fait normal, étant donné que nous n'avons indexé aucune donnée dans notre instance App Search.
Pour pouvoir le faire, nous devons tout d'abord modifier la configuration. Commençons par éditer le fichier src/main/resources/application.properties (l'extrait ci-dessous montre uniquement les paramètres qui nécessitent un changement) :
appsearch.url=https://dc3ff02216a54511ae43293497c31b20.ent-search.westeurope.azure.elastic-cloud.com
appsearch.engine=web-crawler-search-engine
appsearch.key=search-untdq4d62zdka9zq4mkre4vv
feign.client.config.appsearch.defaultRequestHeaders.Authorization=Bearer search-untdq4d62zdka9zq4mkre4vvSi vous ne souhaitez pas entrer de mot de passe pour vous connecter à Kibana, connectez-vous à l'instance Kibana via l'interface utilisateur Elastic Cloud, puis accédez à Enterprise Search > App Search.
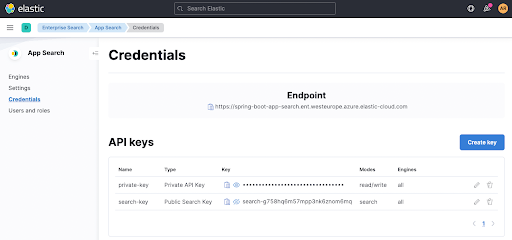
Vous pouvez extraire appsearch.key et le paramètre de recherche feign... de la page Credentials dans App Search. Il en va de même pour Endpoint, affiché en haut à droite.
Désormais, lorsque vous exécutez ./gradlew clean check, le point de terminaison App Search approprié est
atteint, mais les tests continuent à échouer étant donné que nous n'avons pas encore indexé de données. C'est ce que nous allons faire à présent !
Configuration du robot d'indexation
Avant de créer un robot d'indexation, nous devons créer un conteneur pour nos documents. C'est ce qu'on appelle engine aujourd'hui. Aussi, créons-en un. Appelez votre moteur web-crawler-search-engine, de sorte qu'il corresponde au fichier application.conf.
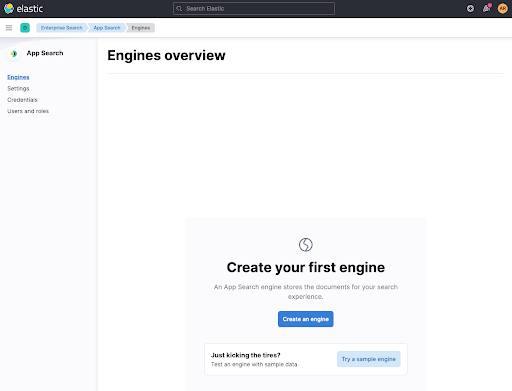
Ensuite, configurez le robot d'indexation en cliquant sur Use The Crawler.
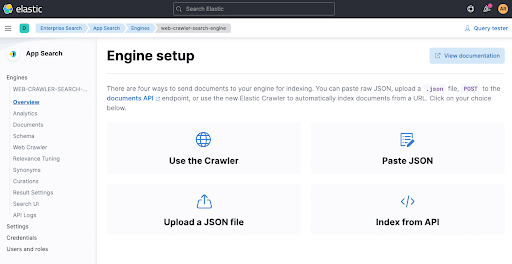
Ajoutez ensuite un domaine. Si vous le souhaitez, vous pouvez ajouter votre propre domaine. Pour ma part, j'ai utilisé mon blog personnel spinscale.de, car je sais qu'ainsi, je ne marcherai sur les plates-bandes de personne.
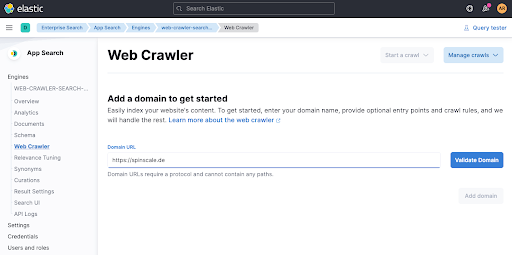
Lorsque vous cliquez sur Validate Domain, quelques vérifications sont effectuées, puis le domaine est ajouté au moteur.
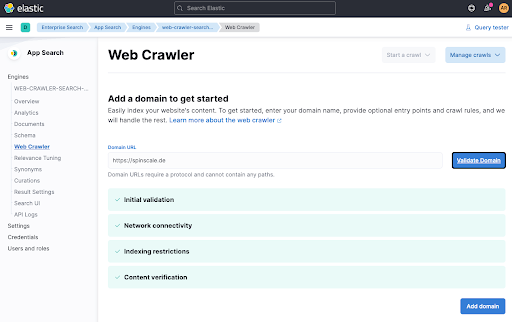
La dernière étape consiste à déclencher le robot d'indexation manuellement pour que les données puissent être indexées dans la foulée. Pour cela, cliquez sur Start a crawl.
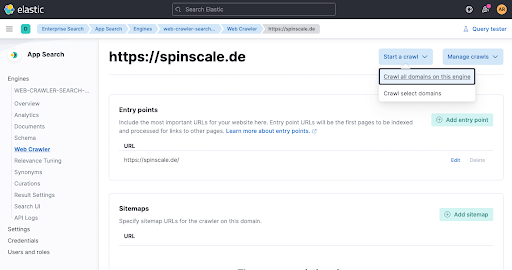
Attendez une minute, puis vérifiez dans la vue d'ensemble du moteur si des documents ont été ajoutés.
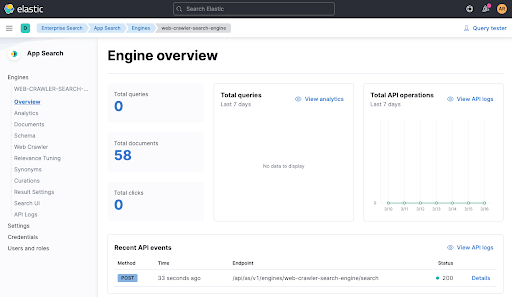
Maintenant que nous avons indexé des données dans notre moteur, exécutons à nouveau le test pour voir s'il réussit via ./gradlew check. Cela devrait être le cas désormais. Comme vous pouvez le voir, il y a également un appel API récent dans la vue d'ensemble du moteur. Cet appel vient du test (voir sur la capture ci-dessus, en bas de la fenêtre).
Avant de démarrer notre application, regardons rapidement le code de test :
@SpringBootTest(classes = SpringBootAppSearchApplication.class, webEnvironment = SpringBootTest.WebEnvironment.NONE)
class AppSearchClientTests {
@Autowired
private AppSearchClient appSearchClient;
@Test
public void testFeignAppSearchClient() {
final QueryResponse queryResponse = appSearchClient.search(Query.of("seccomp"));
assertThat(queryResponse.getResults()).hasSize(4);
assertThat(queryResponse.getResults().stream().map(QueryResponse.Result::getTitle))
.contains("Using seccomp - Making your applications more secure",
"Presentations",
"Elasticsearch - Securing a search engine while maintaining usability",
"Posts"
);
assertThat(queryResponse.getResults().stream().map(QueryResponse.Result::getUrl))
.contains("https://spinscale.de/posts/2020-10-27-seccomp-making-applications-more-secure.html",
"https://spinscale.de/presentations.html",
"https://spinscale.de/posts/2020-04-07-elasticsearch-securing-a-search-engine-while-maintaining-usability.html",
"https://spinscale.de/posts/"
);
}
}Ce test lance l'application sans l'associer à un port, injecte automatiquement la classe AppSearchClient et exécute une recherche sur seccomp.
Démarrage de l'application
L'heure est venue de vérifier si notre application démarre bien.
./gradlew bootRunVous devriez voir quelques messages de logging, et plus important, que votre application a démarré :
2022-03-16 15:43:01.573 INFO 21247 --- [ restartedMain] d.s.s.SpringBootAppSearchApplication : Started SpringBootAppSearchApplication in 1.114 seconds (JVM running for 1.291)Vous pouvez désormais ouvrir l'application dans un navigateur pour y jeter un œil. Mais pour ma part, je voudrais d'abord consulter le code Java.
Définition d'une interface uniquement pour le client de recherche
Pour pouvoir interroger le point de terminaison App Search dans Spring Boot, il est nécessaire de mettre en œuvre une interface car nous utilisons Feign. Nous n'avons pas à nous préoccuper de la sérialisation de fichiers JSON ou de la création de connexions HTTP. Nous pouvons travailler avec des fichiers POJO uniquement. Voici notre définition de notre client App Search :
@FeignClient(name = "appsearch", url="${appsearch.url}")
public interface AppSearchClient {
@GetMapping("/api/as/v1/engines/${appsearch.engine}/search")
QueryResponse search(@RequestBody Query query);
}Le client utilise les définitions de application.properties pour url et engine, afin qu'aucun de ces éléments n'ait besoin d'être précisé dans le cadre de l'appel d'API. Ce client s'appuie également sur les en-têtes définis dans le fichier application.properties. Ainsi, aucun code d'application ne contient d'URL, de noms de moteur ou d'en-têtes d'authentification personnalisés.
Les seules classes qui ont besoin d'une mise en œuvre plus poussée sont Query, pour modéliser le corps de la requête, et QueryResponse, qui modélise la réponse à la requête. J'ai choisi de ne modéliser que les fichiers absolument nécessaires dans la réponse, même si en général cette dernière comporte bien plus de fichiers JSON. Si j'ai besoin de plus de données, je peux les ajouter à la classe QueryResponse.
Pour l'instant, la classe query n'est composée que du champ query.
public class Query {
private final String query;
public Query(String query) {
this.query = query;
}
public String getQuery() {
return query;
}
public static Query of(String query) {
return new Query(query);
}
}Pour finir, exécutons quelques recherches à partir de l'application.
Interrogations côté serveur et rendu
L'exemple d'application met en œuvre trois modèles pour interroger l'instance App Search et pour l'intégrer dans l'application Spring Boot. Le premier envoie un terme de recherche à l'application Spring Boot, qui transmet la requête à App Search, puis renvoie les résultats via thymeleaf, la dépendance de rendu standard de Spring Boot. Voici le contrôleur :
@Controller
@RequestMapping(path = "/")
public class MainController {
private final AppSearchClient appSearchClient;
public MainController(AppSearchClient appSearchClient) {
this.appSearchClient = appSearchClient;
}
@GetMapping("/")
public String main(@RequestParam(value = "q", required = false) String q,
Model model) {
if (q != null && q.trim().isBlank() == false) {
model.addAttribute("q", q);
final QueryResponse response = appSearchClient.search(Query.of(q));
model.addAttribute("results", response.getResults());
}
return "main";
}
}Si nous nous penchons sur la méthode main(), nous constatons qu'il y a une vérification du paramètre q. Si celui-ci est présent, la requête est envoyée à App Search et le model est enrichi avec les résultats. Ensuite, le modèle thymeleaf main.html est rendu. Voici à quoi il ressemble :
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org"
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content">
<div>
<form action="/" method="get">
<input autocomplete="off" placeholder="Enter search terms..."
type="text" name="q" th:value="${q}" style="width:20em" >
<input type="submit" value="Search" />
</form>
</div>
<div th:if="${results != null && !results.empty}">
<div th:each="result : ${results}">
<h4><a th:href="${result.url}" th:text="${result.title}"></a></h4>
<blockquote style="font-size: 0.7em" th:text="${result.description}"></blockquote>
<hr>
</div>
</div>
</div>
</body>
</html>Le modèle recherche la variable results, et si elle est définie, il procède à une itération sur cette liste. Pour chaque résultat, le modèle rendu est le même. Voici ce à quoi il ressemble :
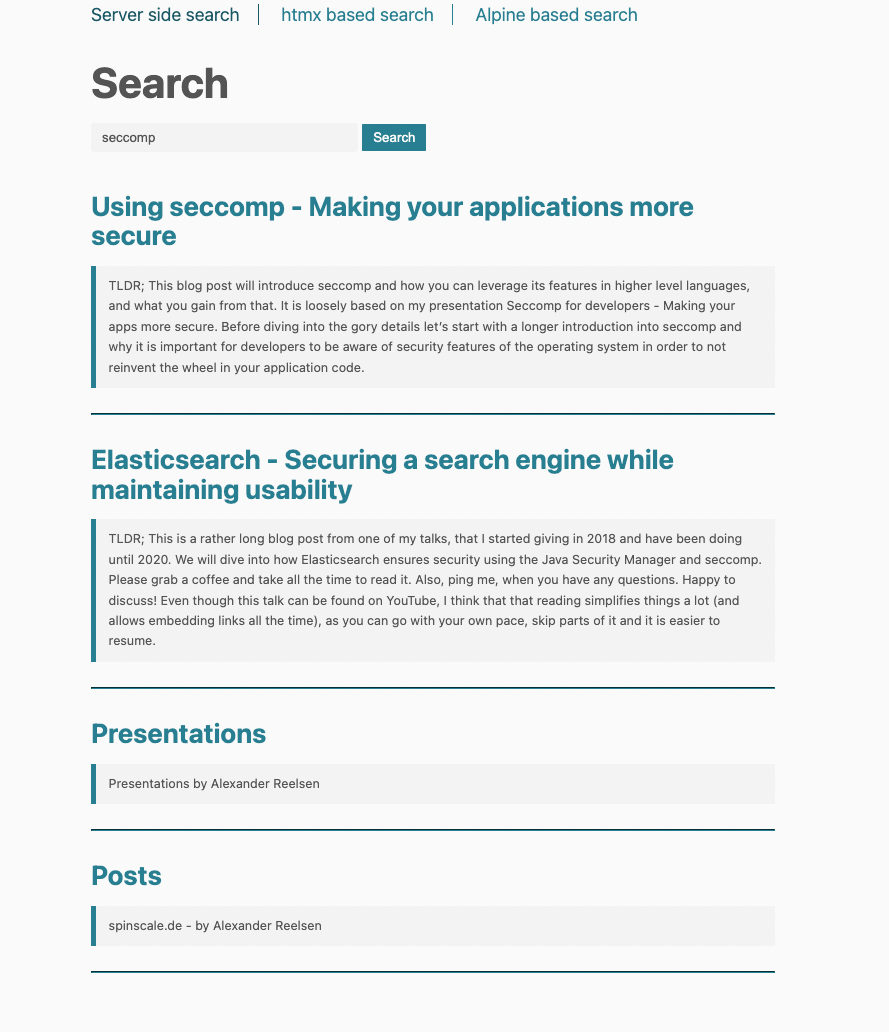
Utilisation de htmx pour les mises à jour de page dynamiques
Comme vous pouvez le voir dans la navigation du haut, nous pouvons modifier la façon d'effectuer les recherches. Trois méthodes sont à notre disposition. Lorsque nous cliquons sur la deuxième méthode, c'est-à-dire la recherche basée sur htmx, le modèle d'exécution varie légèrement.
Au lieu de recharger l'intégralité de la page, seule la partie dans laquelle les résultats sont affichés est remplacée par les éléments renvoyés par le serveur. Et la bonne nouvelle, c'est qu'il n'y a même pas besoin d'écrire en javascript. Si cela est possible, c'est grâce à la géniale bibliothèque htmx. Reprenons la citation associée > htmx vous permet d'accéder à AJAX, aux transitions CSS, aux WebSockets et aux événements envoyés par le serveur directement au format HTML, à l'aide d'attributs. Vous pouvez ainsi créer des interfaces utilisateur modernes en tirant parti de la simplicité et de la puissance de l'hypertexte.
Dans cet exemple, seul un petit sous-ensemble htmx est utilisé. Commençons par regarder les définitions des deux points de terminaison. L'un sert pour le rendu HTML, l'autre pour renvoyer uniquement l'extrait HTML requis pour mettre à jour la partie concernée de la page.
htmx vous permet d'accéder à AJAX, aux transitions CSS, aux WebSockets et aux événements envoyés par le serveur directement au format HTML, à l'aide d'attributs. Vous pouvez ainsi créer des interfaces utilisateur modernes en tirant parti de la simplicité et de la puissance de l'hypertexte.
Le premier point de terminaison effectue le rendu du modèle htmx-main, tandis que le deuxième renvoie les résultats. Voici ce à quoi ressemble le modèle htmx-main :
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org"
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content">
<div>
<form action="/search" method="get">
<input type="search"
autocomplete="off"
id="searchbox"
name="q" placeholder="Begin Typing To Search Articles..."
hx-post="/htmx-search"
hx-trigger="keyup changed delay:500ms, search"
hx-target="#search-results"
hx-indicator=".htmx-indicator"
style="width:20em">
<span class="htmx-indicator" style="padding-left: 1em;color:red">Searching... </span>
</form>
</div>
<div id="search-results">
</div>
</div>
</body>
</html>Et c'est là que la magie se produit dans les attributs hx- de l'élément HTML <input>. Plus concrètement, voici ce que cela signifie :
- déclenchez une requête HTTP uniquement s'il n'y a pas eu d'activité de saisie pendant 500 ms.
- Envoyez ensuite une requête HTTP POST à /htmx-search.
- Pendant que vous patientez, affichez l'élément .htmx-indicator.
- La réponse devrait être rendue dans l'élément avec l'ID #search-results.
Pensez à tout ce que vous devriez écrire normalement en javascript pour la logique utilisée concernant les principaux listeners, l'affichage des éléments à obtenir pour une réponse ou encore l'envoi d'une requête AJAX.
L'autre grand avantage est la possibilité d'utiliser la solution de rendu de votre choix côté serveur pour créer le HTML à renvoyer. Ce que je veux dire par là, c'est que nous pouvons poursuivre dans l'écosystème thymeleaf au lieu d'avoir à mettre en œuvre un autre langage d'utilisation de modèles côté client. Le modèle htmx-search-results est donc très simple car il suffit d'itérer sur les résultats :
<div th:each="result : ${results}">
<h4><a th:href="${result.url}" th:text="${result.title}"></a></h4>
<blockquote style="font-size: 0.7em" th:text="${result.description}"></blockquote>
<hr>
</div>Une différence par rapport au premier exemple est que l'URL de cette recherche ne change jamais. Vous ne pouvez donc pas l'enregistrer dans vos favoris. Même s'il existe une prise en charge de l'historique dans htmx, je ne vais pas l'aborder ici car il faudrait pousser davantage la mise en œuvre pour pouvoir le faire correctement.
@GetMapping("/alpine")
public String alpine() {
return "alpine-js";
}Le modèle alpine-js.html nécessite un peu plus d'explications, mais commençons par regarder ceci :
<!DOCTYPE html>
<html
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content" x-data="{ q: '', response: null }">
<div>
<form @submit.prevent="">
<input type="search" autocomplete="off" placeholder="Begin Typing To Search Articles..." style="width:20em"
x-model="q"
@keyup="client.search(q).then(resultList => response = resultList)">
</form>
</div>
<template x-if="response != null && response.info.meta != null && response.info.meta.request_id != null">
<template x-for="result in response.results">
<template x-if="result.data != null && result.data.title != null && result.data.url != null && result.data.meta_description != null ">
<div>
<h4><a class="track-click" :data-request-id="response.info.meta.request_id" :data-document-id="result.data.id.raw" :data-query="q" :href="result.data.url.raw" x-text="result.data.title.raw"></a></h4>
<blockquote style="font-size: 0.7em" x-text="result.data.meta_description.raw"></blockquote>
<hr>
</div>
</template>
</template>
</template>
<script th:inline="javascript">
var client = window.ElasticAppSearch.createClient({
searchKey: [[${@environment.getProperty('appsearch.key')}]],
endpointBase: [[${@environment.getProperty('appsearch.url')}]],
engineName: [[${@environment.getProperty('appsearch.engine')}]]
});
document.addEventListener("click", function(e) {
const el = e.target;
if (!el.classList.contains("track-click")) return;
client.click({
query: el.getAttribute("data-query"),
documentId: el.getAttribute("data-document-id"),
requestId: el.getAttribute("data-request-id")
});
});
</script>
</div>
</body>
</html>La première différence majeure concerne l'utilisation de JavaScript pour initialiser le client ElasticAppSearch, à l'aide des propriétés configurées à partir du fichier application.properties. Une fois ce client initialisé, nous pouvons l'utiliser dans les attributs HTML.
Le code initialise deux variables à utiliser :
<div layout:fragment="content" x-data="{ q: '', response: null }">La variable q contiendra la requête du formulaire d'entrée et la réponse contiendra la réponse issue d'une recherche. Voyons à présent la définition du formulaire :
<form @submit.prevent="">
<input type="search" autocomplete="off" placeholder="Search Articles..."
x-model="q"
@keyup="client.search(q).then(resultList => response = resultList)">
</form>Avec <input x-model="q"...>, la variable q est liée à l'entrée et est mise à jour au fur et à mesure de la saisie de l'utilisateur. Il y a également un événement pour `keyup` afin d'exécuter une recherche à l'aide de client.search() et d'attribuer le résultat à la variable response. Aussi, une fois que la recherche du client renvoie des résultats, la variable de réponse ne sera plus vide. Enfin, utilisez @submit.prevent="" pour faire en sorte que le formulaire ne soit pas soumis.
Toutes les balises
<div>
<h4><a class="track-click"
:data-request-id="response.info.meta.request_id"
:data-document-id="result.data.id.raw"
:data-query="q"
:href="result.data.url.raw"
x-text="result.data.title.raw">
</a></h4>
<blockquote style="font-size: 0.7em"
x-text="result.data.meta_description.raw"></blockquote>
<hr>
</div>Ce rendu est légèrement différent des deux mises en œuvre de rendu côté serveur, car il contient une fonctionnalité ajoutée permettant d'effectuer le suivi des liens sur lesquels il y a eu des clics. Pour le rendu des modèles, les propriétés importantes sont :href et x-text, car elles définissent le lien et le texte qui l'accompagne. Les autres paramètres :data permettent d'effectuer le suivi des liens.
Suivi des clics
Vous vous demandez peut-être pourquoi il peut être utile d'effectuer le suivi des clics sur les liens. La raison est simple. Il s'agit de l'une des méthodes permettant de déterminer si vos résultats de recherche sont bons en mesurant le nombre d'utilisateurs à avoir cliqué dessus. C'est pourquoi on peut voir du langage javascript dans cet extrait HTML. Jetons tout d'abord un coup d'œil à Kibana.
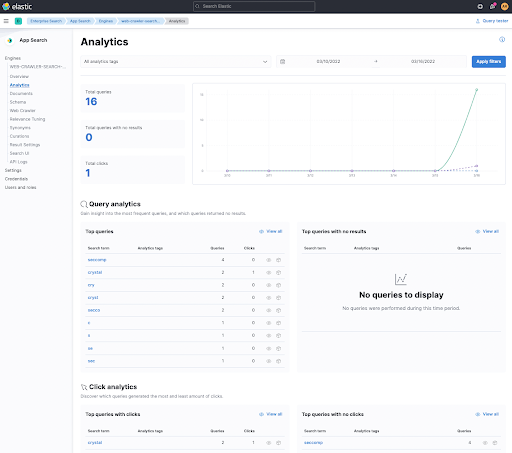
La section Click analytics en bas répertorie un clic après que j'ai fait une recherche sur crystal dans le premier lien. En cliquant sur ce terme, vous pouvez déterminer le document qui a été consulté et tout simplement suivre la piste des clics de vos utilisateurs.
La question à présent est de savoir comment cela se met en œuvre dans notre petite application ? La réponse : en utilisant un listener javascript click pour certains liens. Voici l'extrait javascript :
document.addEventListener("click", function(e) {
const el = e.target;
if (!el.classList.contains("track-click")) return;
client.click({
query: el.getAttribute("data-query"),
documentId: el.getAttribute("data-document-id"),
requestId: el.getAttribute("data-request-id")
});
});Si la classe du lien qui a été cliqué est track-click, envoyez un événement de clic avec le client ElasticAppSearch. Cet événement contient le terme de requête d'origine, ainsi que les ID documentId et requestId faisant partie de la réponse à la recherche et rendus dans l'élément dans le modèle ci-dessus.
Nous pourrions également ajouter cette fonctionnalité dans le rendu côté serveur en fournissant cette information dès qu'un utilisateur clique sur un lien. Il ne s'agit pas d'une fonctionnalité spécifique au navigateur. Par souci de simplicité, je n'ai pas abordé cette mise en œuvre ici.
Résumé
J'espère que vous avez apprécié cette présentation d'Elastic App Search du point de vue d'un développeur, ainsi que des différentes possibilités qui s'offrent à vous pour l'intégrer dans vos applications. Il est important que vous consultiez le référentiel GitHub pour suivre cet exemple.
Si vous le souhaitez, vous pouvez utiliser terraform avec le fournisseur Elastic Cloud pour être opérationnel immédiatement dans Elastic Cloud.
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer