Optimisation des performances d'Elasticsearch lors de l'ajout de nœuds à un cluster


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
En ajoutant des nœuds à un cluster Elasticsearch, ce dernier peut prendre en charge un nombre astronomique de charges de travail. Il est essentiel de connaître les méthodes optimales permettant d'élargir le cluster Elasticsearch sans engendrer aucune dégradation de performance.
Elasticsearch est une technologie de recherche puissante et rapide. À mesure de l'évolution de vos données, vous devez tirer parti de son impressionnante scalabilité. L'ajout de nœuds supplémentaires à un cluster augmente la quantité de données pouvant y être enregistrées, améliore le nombre de requêtes qui sont gérées de manière simultanée et accélère les délais d'obtention de résultats, en règle générale.
Or, vous risquez plutôt de passer un week-end horrible à comprendre pourquoi l'ajout de nœuds dans votre cluster Elasticsearch a engendré de l'instabilité, une indisponibilité, une frustration croissante et une perte de revenus. Passons donc en revue des exemples de configurations courantes dans lesquelles le scaling d'un cluster peut créer des problèmes de performances importants.
Nous mettons à votre disposition un très bon webinar intitulé Planification du dimensionnement et de la capacité Elasticsearch qui répertorie les quatre ressources matérielles fondamentales d'un cluster :
- la puissance de calcul ou le processeur, soit la rapidité d'exécution des tâches par le cluster ;
- le stockage (sur des disques HDD ou SSD), soit le volume de données enregistrées sur le long terme dans le cluster ;
- la mémoire ou RAM, soit le nombre de tâches exécutées de manière simultanée par le cluster ;
- le réseau ou la bande passante, soit la rapidité de transfert des données entre les nœuds.
La puissance de calcul et le stockage représentent les deux problèmes de performances les plus courants. Lorsqu'ils sont limités, les conséquences sont considérables pour les nœuds de données du cluster. Les autres rôles de nœuds, comme le nœud maître, d'ingestion ou de transformation, méritent d'être abordés dans un article à part.
Remarque : À des fins de simplicité, cet article se concentre sur le scaling d'un seul cluster Elasticsearch, car l'exécution de plusieurs clusters sur du matériel partagé ajoute une couche supplémentaire de complexité.
Les ressources matérielles sont réparties en fonction de la plateforme utilisée, selon s'il s'agit de nœuds, d'une machine virtuelle ou de systèmes fondés sur des conteneurs, par exemple.
Ajout de nœuds Elasticsearch pour gagner en capacité
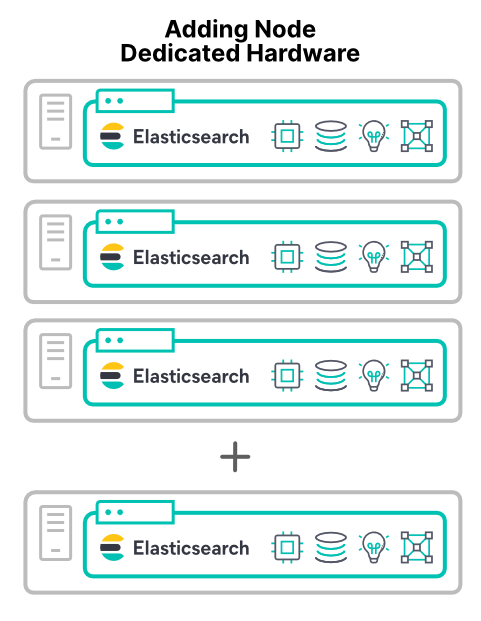
Ajout de nœuds matériels dédiés
Ajouter du matériel est la méthode la plus prévisible pour augmenter les performances d'un cluster. Ajouter un matériel dédié permet d'augmenter les quatre ressources principales. Il existe toutefois une exception (abordée plus loin dans cet article) : l'ajout de nœuds matériels améliore les performances du cluster.
Ajout de nœuds sur des machines virtuelles ou dans des conteneurs sur de nouveaux hôtes
L'ajout de nœuds en tant que conteneurs ou machines virtuelles change la donne. Lorsque de nouveaux nœuds sont attribués à de nouveaux hôtes dans le cluster, ce dernier obtient des ressources matérielles supplémentaires, mais aussi davantage de cœurs de processeur, de RAM, de stockage et de bande passante totale.
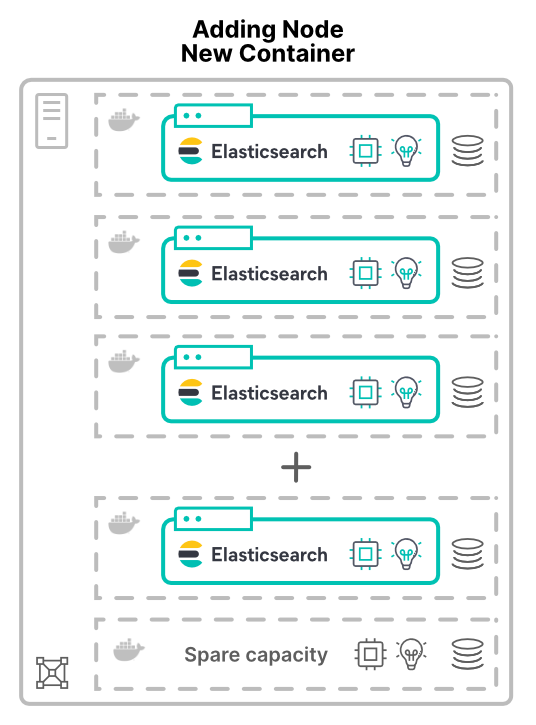
La virtualisation (ou la conteneurisation) des applications permet notamment d'améliorer l'utilisation du matériel. Dans notre exemple, l'ajout de nœuds augmentera uniquement la quantité de matériel disponible dans le cluster. L'augmentation des performances qui en résulte dépend des limites des ressources partagées.
Ajout de nœuds pour répartir la capacité
Si le matériel est réparti à l'aide de machines virtuelles ou de conteneurs, les nœuds Elasticsearch finissent par le partager. Ceci s'applique à tous les modèles de déploiement, y compris Elastic Cloud Enterprise (ECE) et Elastic Cloud sur Kubernetes (ECK).
Apparition d'un problème de puissance de calcul
En règle générale, l'utilisation de machines virtuelles pour affecter des processeurs est une opération prévisible : elle consiste à attribuer à chaque machine le nombre de cœurs à utiliser. Avec les conteneurs, la répartition des processeurs est plus compliquée.
Les systèmes de conteneur, comme Kubernetes, peuvent mesurer les ressources du processeur en millièmes ou millicores. La différence est importante entre les requêtes et les limites. En définissant seulement le processeur requis, le conteneur peut utiliser celui de l'hôte jusqu'à 100 %. Toutefois, si le processeur est trop limité, des ressources chères se retrouvent inactives.
> Conseil : Les pools de threads utilisent les cœurs de processeur comme point de départ. Avec les conteneurs, il est conseillé de vérifier que la configuration de votre pool de threads fonctionne comme prévu.
Dans Kubernetes, les limites du processeur de la totalité des conteneurs peuvent dépasser l'ensemble du matériel disponible. Cela suppose que tous les conteneurs n'utiliseront pas le processeur à pleine capacité de manière simultanée.
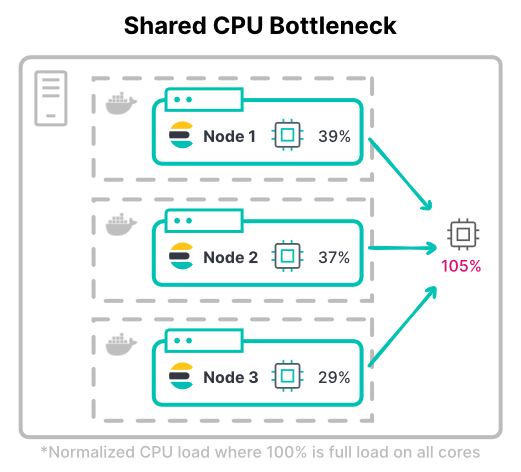
Il convient de tenir compte du débit maximal d'un cluster. Dans les charges de travail nécessitant d'importantes ressources de calcul, les nœuds ont souvent besoin de toutes les limites du processeur affecté à des fins d'indexation. La charge de travail gourmande en index la plus courante est un cluster de logging très volumineux.
> Conseil : Tenez compte de l'utilisation du processeur typique et à son maximum quand vous déterminez les limites du processeur. Déterminez aussi la quantité de régulation du processeur qui est acceptable.
Apparition d'un problème de stockage
Il peut être difficile d'éviter les problèmes de stockage, car ce dernier est attribué en fonction de l'espace et pas du débit. Lorsqu'un nœud Elasticsearch s'exécute en dehors de l'espace de stockage, il atteint le plus bas niveau de disque et arrête l'allocation des partitions.
Qu'il s'agisse d'une machine virtuelle ou d'un conteneur, la plupart des plateformes ne peuvent pas limiter facilement l'utilisation des périphériques de stockage. La plupart des environnements ne sont pas dotés de limites configurables pour les opérations d'entrées et de sorties par seconde ou le débit de lecture et d'écriture. Même le système de fichiers XFS recommandé autorise uniquement les quotas de disque en fonction de l'espace disque.
En l'absence de limites, tout conteneur doté d'une charge de travail gourmande en stockage peut saturer le matériel de ce dernier, ce qui prive d'autres nœuds se partageant ce matériel. Les déploiements à grande échelle peuvent s'avérer défaillants avec leurs répertoires de données. Lorsque plusieurs nœuds installent leur répertoire de données sur le même matériel SAN, le périphérique peut être dépassé par le débit total de l'ensemble des nœuds.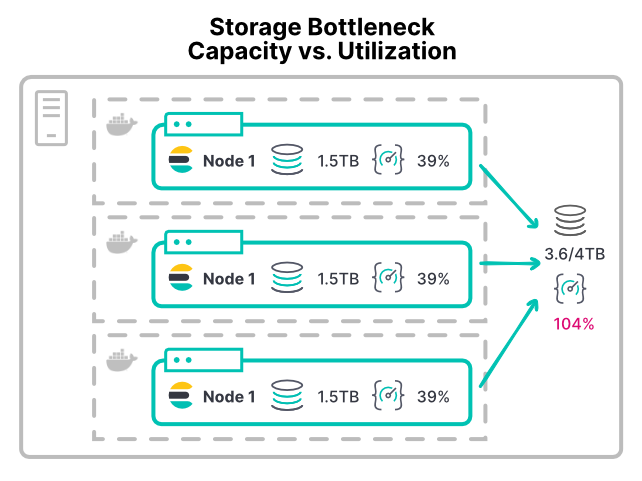
Avec une telle configuration de conteneur, l'ajout de nœuds supplémentaires affecte davantage de processeur et de mémoire au cluster. Cependant, cette opération divise le débit du stockage existant. Par conséquent, les opérations de disque s'exécutent plus lentement quand les performances s'aggravent à cause de l'ajout de nœuds.
> Conseil : Lorsque le temps d'attente des entrées et des sorties du processeur est supérieur à 10 %, cette situation est un avertissement précoce indiquant que les nœuds manquent de débit de stockage. On retrouve cela sur les hôtes des machines virtuelles ou des conteneurs, car les conteneurs individuels n'affichent pas cette mesure.
Ajout de nœuds pour atteindre la neutralité en ligne
Pour garantir un scaling efficace, il reste un dernier piège à éviter. Ce problème de configuration survient lors de l'ajout de matériel physique.
Limitation du débit de l'index avec un nombre insuffisant de partitions
L'ajout de nœuds, indépendamment de la méthode utilisée, ne modifie pas le nombre de partitions d'un index. Si un index est doté de 2 partitions principales et de 1 ensemble de répliques, il comprend 4 partitions au total. Sur un cluster à 4 nœuds, une seule partition par nœud est un excellent moyen d'optimiser le débit de l'indexation.
À mesure que le volume des données entrantes augmente, nous ajoutons 2 nœuds supplémentaires au cluster, ce qui correspond à une augmentation de 50 % du nombre total des ressources disponibles. Or, cette opération n'améliore pas du tout le taux d'ingestion. Pourquoi ?
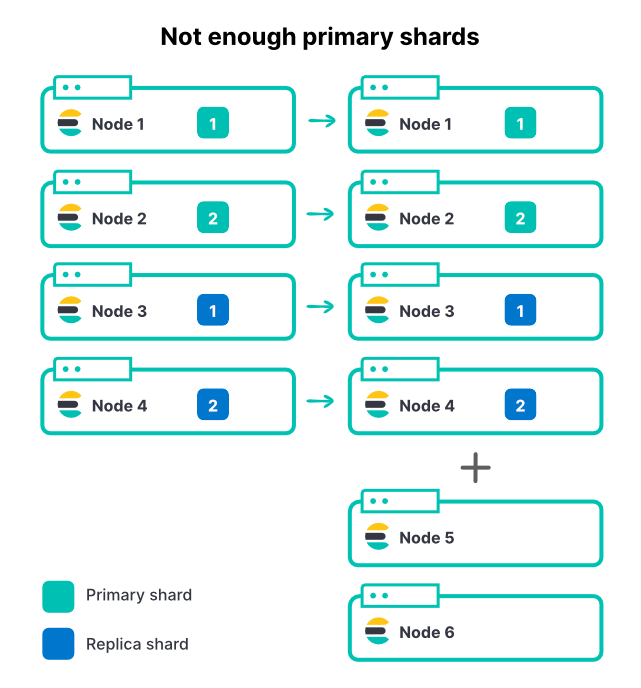
Dans cet exemple, les nouveaux nœuds ne peuvent pas contribuer à l'indexation, car toutes les partitions sont déjà attribuées. Pour qu'un index tire parti des nœuds supplémentaires, il faut aussi un plus grand nombre de partitions principales. Si un cluster comprend plusieurs index actifs (une situation courante), l'ajout de nœuds augmentera le débit total du cluster. Toutefois, la plupart des index actifs pourraient toujours faire face à des restrictions à cause du nombre limité de partitions principales. La sélection d'un nombre adéquat de partitions pour Elasticsearch est une étape importante de la planification des capacités.
Ainsi, dans l'exemple ci-dessus, si les partitions principales passent de 2 à 3 et si chaque partition comprend 1 réplique, 6 partitions au total doivent être réparties sur les 6 nœuds.
> Conseil : La configuration d'index.routing.allocation.total_shards_per_node (voir la documentation) peut être une sécurité. Toutefois, si cette limite est trop basse, certaines partitions peuvent se retrouver bloquées et ne pas être réparties.
Conclusion
L'ajout de nœuds à un cluster Elasticsearch en améliore-t-il les performances ? Ça dépend. Si les nœuds se partagent du matériel, faites attention aux problèmes liés à ces ressources communes. La surutilisation du stockage et le processeur constituent deux problèmes courants. Grâce à une planification soignée et à une bonne stratégie de partitions, l'ajout de nœuds optimisera bien les performances.
Parmi les nombreux avantages dont nous pouvons bénéficier grâce à l'exécution dans Elastic Cloud, notre équipe s'engage notamment à identifier et à gérer très précisément ce type de problèmes de performances impliquant des ressources partagées. Démarrez un essai gratuit dans le cloud dès aujourd'hui en vous rendant sur la page https://www.elastic.co/fr/cloud/.
Si vous souhaitez mieux connaître les performances d'Elasticsearch, regardez notre webinar intitulé Planification du dimensionnement et de la capacité Elasticsearch.
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer