Synchroniser Elasticsearch avec une base de données relationnelle grâce à Logstash et JDBC
Pour capitaliser sur les puissantes fonctionnalités de recherche d'Elasticsearch, bon nombre d'entreprises le déploient en parallèle de leurs bases de données relationnelles existantes. Dans ces cas-là, il faudra probablement veiller à ce qu'Elasticsearch reste synchronisé avec les données stockées dans la base de données relationnelle qui lui est associée. Dans cet article de blog, nous allons donc voir comment utiliser Logstash pour copier efficacement des enregistrements et synchroniser les mises à jour provenant d'une base de données relationnelle dans Elasticsearch . Pour tester le code et les méthodes présentées ici, nous utiliserons MySQL, mais cela doit a priori fonctionner avec n'importe quel SGBDR.
Configuration système
Pour les besoins de cet article, j'ai effectué les tests avec les composants suivants :
- MySQL : 8.0.16.
- Elasticsearch : 7.1.1
- Logstash : 7.1.1
- Java : 1.8.0_162-b12
- Plug-in d'entrée JDBC : v4.3.13
- Connecteur JDBC : Connector/J 8.0.16
Présentation détaillée des étapes de synchronisation
Dans cet article, nous allons utiliser Logstash et le plug-in d'entrée JDBC pour synchroniser Elasticsearch avec MySQL. L'idée est que le plug-in d'entrée JDBC de Logstash exécute une boucle qui interroge régulièrement les enregistrements MySQL insérés ou modifiés depuis la dernière itération de la boucle. Pour que cela fonctionne correctement, les conditions suivantes doivent être remplies :
- Les documents MySQL étant écrits dans Elasticsearch, le champ "_id" d'Elasticsearch doit être défini sur le champ "id" provenant de MySQL. Cela permet de mapper directement l'enregistrement MySQL et le document Elasticsearch. Lorsqu'un enregistrement est mis à jour dans MySQL, le document associé est intégralement remplacé dans Elasticsearch. Remarque : le remplacement d'un document dans Elasticsearch est aussi efficace qu'une opération de mise à jour. Une mise à jour consisterait à supprimer l'ancien document, puis à indexer un document totalement nouveau.
- Lorsqu'un enregistrement est inséré ou mis à jour dans MySQL, il doit comporter un champ contenant la date et l'heure de mise à jour ou d'insertion. Ce champ permet à Logstash de ne demander que les documents modifiés ou insérés depuis la dernière itération de sa boucle d'interrogation. Chaque fois que Logstash interroge MySQL, il stocke la date de mise à jour et d'insertion du dernier enregistrement qu'il a lu dans MySQL. Lors de l'itération suivante, Logstash sait qu'il ne doit interroger que les enregistrements dont la date de mise à jour ou d'insertion est plus récente que celle reçue lors de l'itération précédente de la boucle d'interrogation.
Si les conditions ci-dessus sont remplies, nous pouvons configurer Logstash pour qu'il demande régulièrement à MySQL tous les enregistrements modifiés ou nouvellement créés, et qu'il les écrive ensuite dans Elasticsearch. Nous présenterons plus bas le code Logstash utilisé pour assurer cette synchronisation.
Configuration de MySQL
Pour configurer la base de données et la table MySQL, vous pouvez procéder comme suit :
CREATE DATABASE es_db; USE es_db; DROP TABLE IF EXISTS es_table; CREATE TABLE es_table ( id BIGINT(20) UNSIGNED NOT NULL, PRIMARY KEY (id), UNIQUE KEY unique_id (id), client_name VARCHAR(32) NOT NULL, modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, insertion_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP );
La configuration MySQL ci-dessus comporte quelques paramètres intéressants :
es_table: c'est le nom de la table MySQL depuis laquelle les enregistrements seront lus puis synchronisés dans Elasticsearch.id: il s'agit de l'identifiant unique de cet enregistrement. Remarquons que "id" est défini comme "PRIMARY KEY" (clé principale) et "UNIQUE KEY" (clé unique). Cela permet d'assurer que chaque "id" n'apparaît qu'une seule fois dans la table actuelle. Pour mettre à jour ou insérer le document dans Elasticsearch, "id" sera converti en "_id".client_name: ce champ représente les données qui seront stockées dans chaque enregistrement, telles que définies par l'utilisateur. Pour simplifier, nous n'utiliserons dans cet article qu'un seul champ contenant des données définies par l'utilisateur, mais vous pouvez facilement en ajouter d'autres. C'est ce champ que nous modifierons pour montrer que les enregistrements MySQL nouvellement insérés et les enregistrements mis à jour sont copiés vers Elasticsearch.modification_time: toute insertion ou mise à jour d'un enregistrement dans MySQL modifie la valeur de ce champ, afin qu'elle corresponde à la date et à l'heure de la modification. La date et l'heure de modification nous permettent d'extraire les enregistrements modifiés depuis la dernière demande de documents envoyée par Logstash vers MySQL.insertion_time: nous utilisons ce champ à des fins de démonstration. Il n'est pas strictement nécessaire au bon fonctionnement de la synchronisation. Il va nous permettre de vérifier la date et l'heure auxquelles un enregistrement a été inséré dans MySQL pour la première fois.
Opérations MySQL
Étant donné la configuration ci-dessus, l'écriture des enregistrements dans MySQL peut se faire comme suit :
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name>);
Pour mettre à jour les enregistrements MySQL, vous pouvez utiliser la commande suivante :
UPDATE es_table SET client_name = <new client name> WHERE id=<id>;
Les upserts MySQL peuvent quant à eux être effectués comme suit :
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name when created> ON DUPLICATE KEY UPDATE client_name=<client name when updated>;
Code de synchronisation
Le pipeline Logstash ci-dessous permet d'implémenter le code de synchronisation décrit dans la section précédente :
input {
jdbc {
jdbc_driver_library => "<path>/mysql-connector-java-8.0.16.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://<MySQL host>:3306/es_db"
jdbc_user => <my username>
jdbc_password => <my password>
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"
}
}
filter {
mutate {
copy => { "id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}
output {
# stdout { codec => "rubydebug"}
elasticsearch {
index => "rdbms_sync_idx"
document_id => "%{[@metadata][_id]}"
}
}
Revenons sur certains éléments du pipeline ci-dessus :
tracking_column: ce champ spécifie le champ "unix_ts_in_secs" (décrit ci-dessous), qui sert à effectuer le suivi du dernier document lu par Logstash depuis MySQL, celui-ci étant stocké sur le disque dans .logstash_jdbc_last_run. Cette valeur sert à définir la valeur de départ des documents que Logstash demandera lors de l'itération suivante de sa boucle d'interrogation. La valeur stockée dans .logstash_jdbc_last_run est accessible dans le statement (c'est-à-dire l'instruction) "SELECT", où elle apparaît en tant que ":sql_last_value".unix_ts_in_secs: ce champ est généré par l'instruction "SELECT" ci-dessus. Il contient le paramètre "modification_time" comme timestamp Unix (ou heure Unix) standard, exprimé en secondes écoulées depuis l'époque Unix. Comme nous venons de le voir, ce champ est référencé par "tracking_column". On utilise un timestamp Unix pour effectuer le suivi du temps écoulé plutôt qu'un système d'horodatage normal, car ce dernier risquerait d'entraîner des erreurs en raison de la complexité des conversions entre temps métrique universel (UMT, "Universal Metric Time") et fuseau horaire local.sql_last_value: ce paramètre intégré contient le point départ de l'itération de la boucle d'interrogation Logstash en cours d'exécution. Il est référencé dans la ligne d'instruction "SELECT" de la configuration de l'entrée JDBC ci-dessus. Il est défini sur la valeur "unix_ts_in_secs" la plus récente, qui est lue depuis .logstash_jdbc_last_run. Il sert de point de départ pour les documents devant être renvoyés par la requête MySQL exécutée dans la boucle d'interrogation Logstash. L'ajout de cette variable à la requête garantit que les insertions ou mises à jour déjà répercutées dans Elasticsearch ne soient pas envoyées de nouveau.schedule: ce champ utilise la syntaxe cron pour spécifier la fréquence à laquelle Logstash doit interroger MySQL. Ici, la valeur"*/5 * * * * *"indique à Logstash qu'il doit contacter MySQL toutes les 5 secondes.modification_time < NOW(): cette partie de l'instruction "SELECT" fait partie des concepts les plus difficiles à expliquer. Nous l'aborderons donc à la section suivante, qui lui est consacrée.filter: ici, nous copions simplement la valeur "id" de l'enregistrement MySQL dans un champ de métadonnées nommé "_id", que nous référencerons plus bas dans la sortie, afin que chaque document écrit dans Elasticsearch comporte la bonne valeur "_id". Le champ de métadonnées permet d'éviter que cette valeur temporaire n'entraîne la création d'un nouveau champ. Nous supprimons aussi les champs "id", "@version" et "unix_ts_in_secs" du document, étant donné que nous ne voulons pas les écrire dans Elasticsearch.output: dans cette section du code, nous indiquons que chaque document doit être écrit dans Elasticsearch et doit être associé à un "_id" extrait du champ de métadonnées que nous avons créé dans la section "filter". Nous avons ajouté une sortie rubydebug commentée, qui peut être activée pour aider au débogage.
Analyse de l'instruction "SELECT" et de son exactitude
Dans cette section, nous allons voir pourquoi il est important d'ajouter modification_time < NOW() à l'instruction "SELECT". Nous commencerons par quelques contre-exemples, qui démontrent pourquoi les approches les plus intuitives ne fonctionnent pas. Nous expliquerons ensuite comment l'ajout de modification_time < NOW() permet de surmonter les problèmes rencontrés dans les approches intuitives.
1er scénario intuitif
Que se passe-t-il si la clause "WHERE" ne comporte pasmodification_time < NOW() et qu'elle spécifie uniquement UNIX_TIMESTAMP(modification_time) > :sql_last_value ? C'est ce que nous allons voir ici. Dans ce scénario, l'instruction "SELECT" serait la suivante :
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value) ORDER BY modification_time ASC"
À première vue, l'approche ci-dessus devrait fonctionner correctement. Mais dans certains cas limites, elle risque de manquer des documents. Imaginons un exemple où MySQL insérerait 2 documents par seconde, et où Logstash exécuterait son instruction "SELECT" toutes les 5 secondes. Ce scénario est illustré dans le diagramme ci-dessous, où les valeurs T0 à T10 représentent les secondes, et les valeurs R1 à R22 représentent les enregistrements MySQL. Supposons que la première itération de la boucle d'interrogation de Logstash ait lieu à T5, et qu'elle lise les documents R1 à R11 (en turquoise ci-dessous). La valeur stockée dans sql_last_value est maintenant T5, puisqu'il s'agit du timestamp présent sur le dernier enregistrement lu (R11). Supposons aussi que juste après que Logstash ait lu les documents depuis MySQL, un autre document (R12) soit inséré dans MySQL, et qu'il comporte un timestamp de T5.
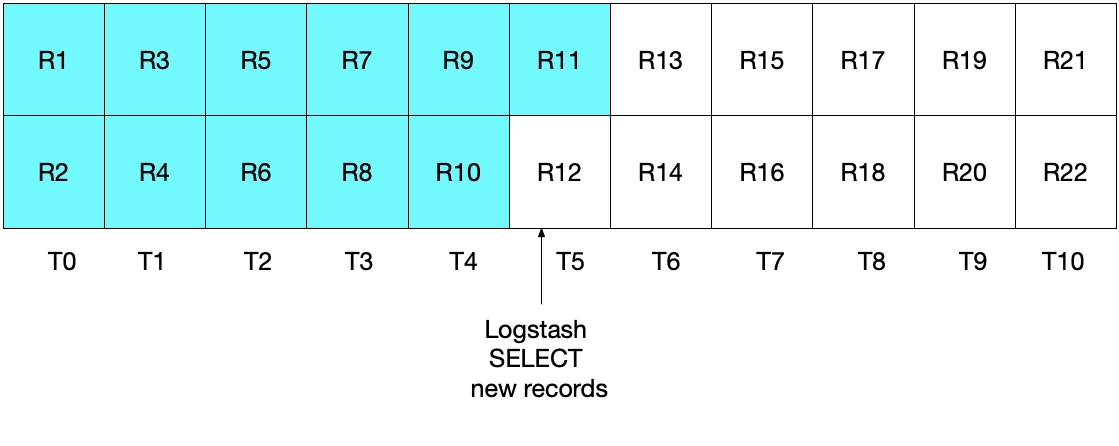
À la prochaine itération de l'instruction "SELECT" ci-dessus, nous n'extrairons que les documents dont l'heure est WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value)), ce qui signifie que l'enregistrement R12 sera ignoré. C'est ce que montre le diagramme ci-dessous, dans lequel les cases turquoise représentent les enregistrements lus par Logstash dans l'itération en cours d'exécution, et les cases grises, les enregistrements déjà lus par Logstash au cours de l'itération précédente.
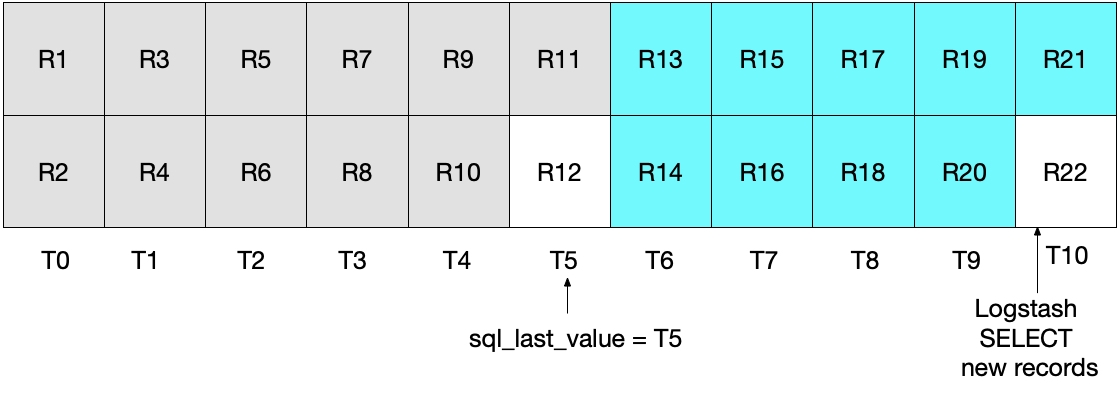
Remarquez que dans l'instruction "SELECT" de ce scénario, l'enregistrement R12 n'est jamais écrit dans Elasticsearch.
2e scénario intuitif
Pour remédier au problème ci-dessus, on peut décider de modifier la clause "WHERE" pour la définir sur
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) >= :sql_last_value) ORDER BY modification_time ASC"
Cependant, cette implémentation n'est pas non plus idéale. Dans ce cas, le problème qui se pose est le suivant : le ou les documents les plus récents lus depuis MySQL au cours de l'intervalle de temps le plus récent seront de nouveaux envoyés vers Elasticsearch. Bien que cela n'ait aucun impact négatif sur l'exactitude des résultats, cela implique des tâches non nécessaires. Comme après l'itération d'interrogation initiale au paragraphe précédent, le diagramme ci-dessous montre quels documents ont été lus depuis MySQL.
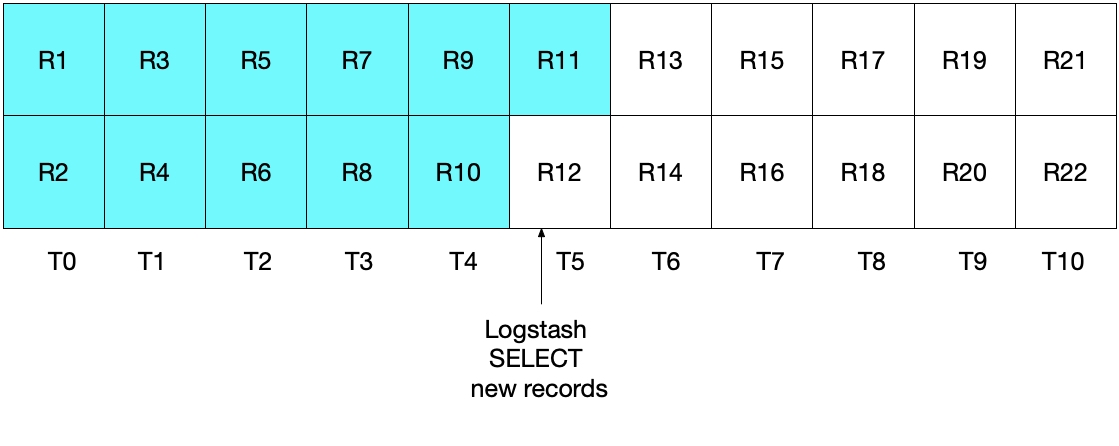
Lorsque nous exécutons l'itération d'interrogation de ce scénario, nous extrayons tous les documents dont le timestamp est supérieur
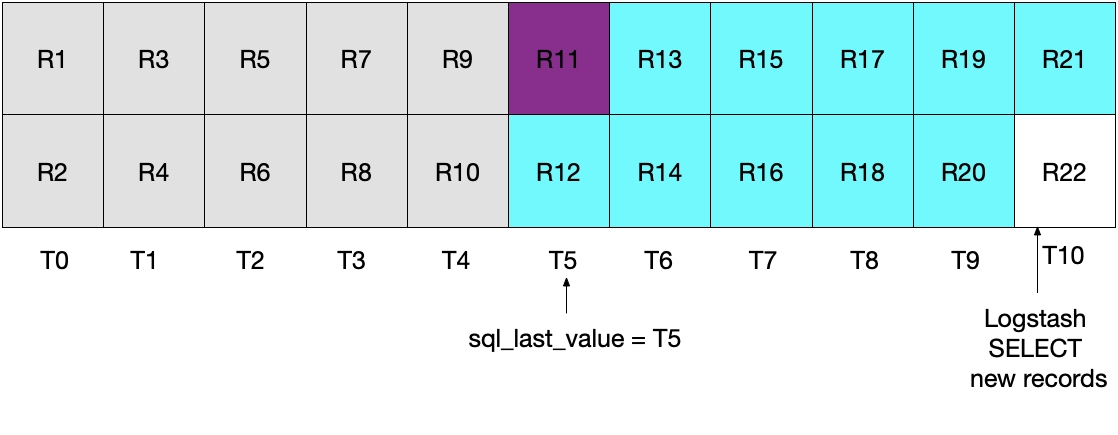
Aucun de ces deux scénarios n'est parfait. Dans le premier, nous risquons de perdre des données, et dans le second, les données sont lues depuis MySQL et envoyées à Elasticsearch plusieurs fois.
Comment résoudre les problèmes que posent ces approches intuitives
Aucun des deux scénarios précédents n'étant parfait, nous devons trouver une autre approche. Si nous spécifions (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()), nous n'envoyons chaque document vers Elasticsearch qu'une seule et unique fois.
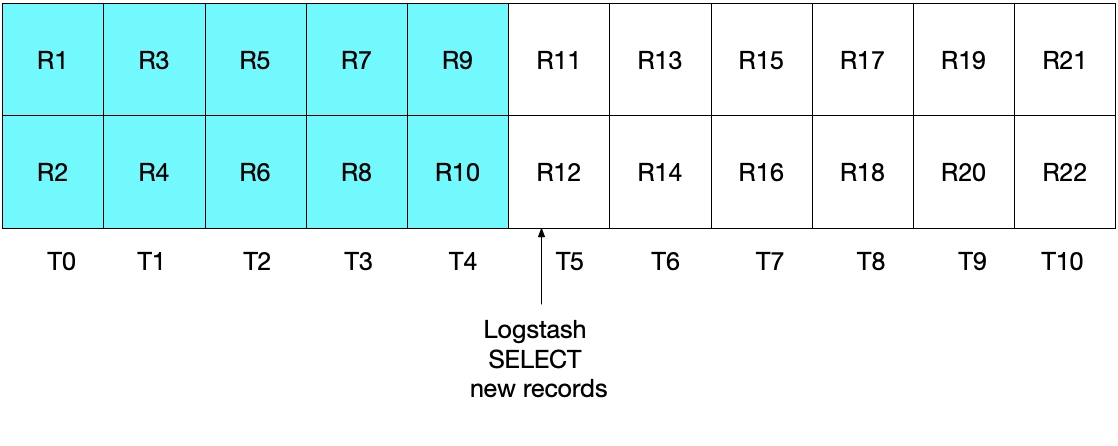
C'est ce qu'illustre le diagramme ci-dessous, dans lequel Logstash interroge MySQL à T5. Remarque : la condition modification_time < NOW() devant être remplie, seuls les documents allant jusqu'à la période T5, mais non compris dans cette période, seront lus depuis MySQL. Puisque nous avons récupéré tous les documents de T4 et aucun document de T5, nous savons que sql_last_value sera ensuite défini sur T4 à la prochaine itération d'interrogation de Logstash.
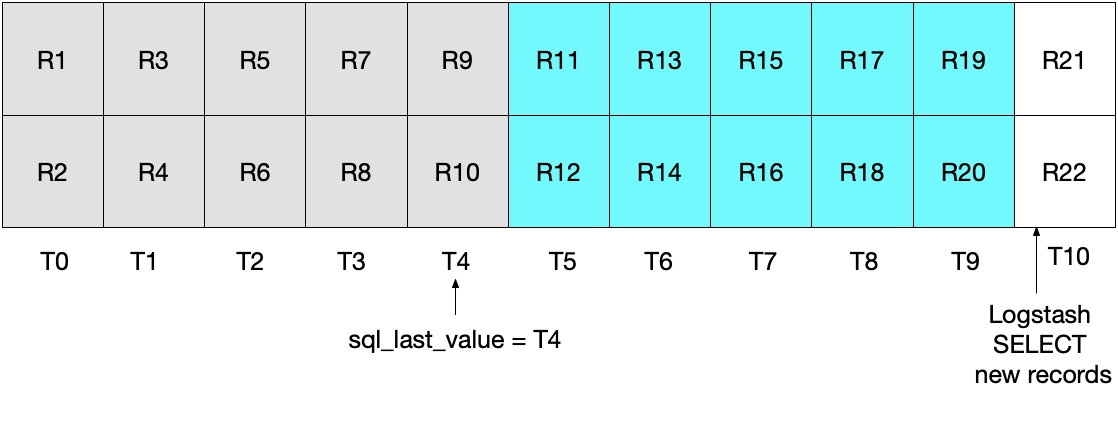
Le diagramme ci-dessous illustre la prochaine itération de l'interrogation Logstash. Puisque UNIX_TIMESTAMP(modification_time) > :sql_last_value, et parce que sql_last_value est défini sur T4, nous savons que nous ne récupérons que les documents à partir de T5. De plus, puisque nous ne récupérons que les documents remplissant la condition modification_time < NOW(), seuls les documents allant jusqu'à T9 et compris dans cette période seront récupérés. Ici encore, cela signifie que nous récupérons tous les documents compris dans T9 et que sql_last_value sera défini sur T9 pour la prochaine itération. Nous voyons donc que cette approche nous évite de ne récupérer qu'une partie des documents MySQL dans un intervalle de temps donné.
Tester le système
Pour vérifier que notre implémentation fonctionne comme prévu, nous pouvons effectuer des tests simples. Nous pouvons écrire des enregistrements dans MySQL, comme suit :
INSERT INTO es_table (id, client_name) VALUES (1, 'Jim Carrey'); INSERT INTO es_table (id, client_name) VALUES (2, 'Mike Myers'); INSERT INTO es_table (id, client_name) VALUES (3, 'Bryan Adams');
Une fois que la planification de l'entrée JDBC a déclenché la lecture d'enregistrements depuis MySQL et leur écriture dans Elasticsearch, nous pouvons exécuter la requête Elasticsearch suivante pour afficher les documents dans Elasticsearch :
GET rdbms_sync_idx/_search
ce qui renvoie une réponse semblable à celle-ci :
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"insertion_time" : "2019-06-18T12:58:56.000Z",
"@timestamp" : "2019-06-18T13:04:27.436Z",
"modification_time" : "2019-06-18T12:58:56.000Z",
"client_name" : "Jim Carrey"
}
},
Etc …
Nous pouvons alors mettre à jour le document correspondant à _id=1 dans MySQL, comme suit :
UPDATE es_table SET client_name = 'Jimbo Kerry' WHERE id=1;
ce qui met à jour le document identifié par un _id de 1. Pour afficher le document directement dans Elasticsearch, nous exécutons la commande suivante :
GET rdbms_sync_idx/_doc/1
ce qui renvoie ce document :
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"insertion_time" : "2019-06-18T12:58:56.000Z",
"@timestamp" : "2019-06-18T13:09:30.300Z",
"modification_time" : "2019-06-18T13:09:28.000Z",
"client_name" : "Jimbo Kerry"
}
}
Remarque : la _version est maintenant définie sur 2, modification_time ne correspond plus à insertion_time, et le champ client_name a été correctement mis à jour avec la nouvelle valeur. Le champ @timestamp ne présente pas d'intérêt particulier dans notre exemple : Logstash l'ajoute par défaut.
Pour effectuer un upsert dans MySQL, procédez comme suit – vous pouvez ensuite vérifier que vous retrouvez les bonnes informations dans Elasticsearch :
INSERT INTO es_table (id, client_name) VALUES (4, 'Bob is new') ON DUPLICATE KEY UPDATE client_name='Bob exists already';
Et les documents supprimés ?
Comme rien ne vous échappe, vous avez probablement remarqué que lorsqu'on supprime un document de MySQL, sa suppression n'est pas répercutée dans Elasticsearch. Pour résoudre ce problème, vous pouvez adopter les approches suivantes :
- Les enregistrements MySQL peuvent comprendre un champ "is_deleted", indiquant qu'ils ne sont plus valides. C'est ce qu'on appelle une "suppression réversible". Comme pour toutes les autres mises à jour d'enregistrements MySQL, ce champ "is_deleted" est répercuté dans Elasticsearch via Logstash. Si vous adoptez cette approche, les requêtes Elasticsearch et MySQL doivent être écrites de manière à exclure les enregistrements ou les documents dans lesquels "is_deleted" = "true". Enfin, des tâches en arrière-plan peuvent supprimer ces documents de MySQL et d'Elastic.
- Autre possibilité : s'assurer que lorsqu'un système supprime des enregistrements dans MySQL, il doit aussi exécuter une commande pour supprimer directement les documents correspondants dans Elasticsearch.
Pour conclure
Dans cet article de blog nous avons vu comment utiliser Logstash pour synchroniser Elasticsearch avec une base de données relationnelle. Pour tester le code et les méthodes présentées ici, nous avons utilisé MySQL, mais cela doit a priori fonctionner avec n'importe quel SGBDR.
Des questions au sujet de Logstash ? Des questions sur Elasticsearch ? Jetez un œil à nos forums de discussion : vous y trouverez des idées et de précieuses informations. N'oubliez pas non plus d'essayer Elasticsearch Service, la seule offre Elasticsearch et Kibana hébergée, mise à votre disposition par les créateurs d'Elasticsearch.