L’authentification et l’autorisation dans Elasticsearch en toute simplicité
Cela fait maintenant plus de 4 ans que j’ai intégré Elastic. Pendant 3 ans et demi, j’ai travaillé au support technique et au conseil, et ces derniers mois, aux ventes. Quel que soit le département où j’exerce, les questions qui reviennent régulièrement de la part des utilisateurs concernent la sécurisation d’Elasticsearch. Quel type d’authentification est pris en charge par Elasticsearch ? Comment le configurer ? Comment s’assurer que les utilisateurs n’aient pas accès à des données qui ne les concernent pas ? Dans ce blog, je souhaiterais apporter des réponses à ces questions, ainsi que donner des conseils pour résoudre certains problèmes courants qui se posent lors de la configuration de la sécurité.
Pour commencer, un peu d’histoire. Si vous utilisez Elasticsearch depuis un petit moment, vous vous rappellerez sans doute que la sécurité était assurée à une époque par un plug-in appelé Shield, qui était proposé par X-Pack. Aujourd’hui, la fonctionnalité de sécurité a été transférée dans la Suite Elastic (avec le reste de X-Pack). Les fonctions les plus courantes sont disponibles gratuitement dans la distribution par défaut. Concrètement, quand on parle de sécurité, qu’est-ce que cela implique en termes de fonctionnalités ? La réponse, la voilà : le chiffrement des communications (TLS/SSL), l’authentification (native, LDAP, SSO, etc.), l’autorisation (RBAC, ABAC, etc.), le filtrage IP, le logging d'audit, et bien plus encore. Dans ce blog, nous allons étudier les deux formes d’authentification.
L’authentification dans Elasticsearch
Pour faire simple, si un utilisateur ou une API souhaite accéder à Elasticsearch, il ou elle doit d’abord s’authentifier.
Elasticsearch est nativement compatible avec plusieurs méthodes de sécurité, telles que :
- Authentification utilisateur native
- Authentification utilisateur Active Directory
- Authentification utilisateur basée sur un fichier
- Authentification utilisateur LDAP
- Authentification utilisateur PKI
- Authentification SAML
- Authentification Kerberos
Vous pouvez même créer votre propre intégration si aucune de ces méthodes ne convient. Toutefois, nous vous recommandons d’utiliser l’une des intégrations existantes, tout simplement parce qu’il s’agit d’intégrations validées et que nous continuons nos développements en nous basant sur ces intégrations pour pouvoir assurer un support technique optimal.
Le composant le plus basique en matière de sécurité dans Elasticsearch, c’est le domaine, qui sert à identifier et authentifier les utilisateurs. Toutes les méthodes d’authentification répertoriées ci-dessus peuvent être considérées comme des domaines. Elasticsearch fonctionne comme une chaîne de domaines. Une chaîne de domaines est une liste hiérarchisée de domaines configurés (de 1 à N domaines), dans l’ordre croissant de préférence. Lorsqu’un utilisateur essaie d’accéder à Elasticsearch, la requête parcourt la liste dans l’ordre jusqu’à ce que l’authentification aboutisse ou jusqu’à ce qu’il n’y ait plus de domaines.
Pour résumer, le processus essaie le premier domaine configuré dans la liste. En cas d’échec, il passe au deuxième, et ainsi de suite, jusqu’à ce qu’il trouve le domaine approprié ou qu’il ait parcouru toute la liste sans succès. Pour accéder à Elasticsearch, la première étape consiste à s’authentifier.
Lorsqu’un utilisateur est authentifié, Elasticsearch essaie alors de lui attribuer un ou plusieurs rôles. Ceux-ci peuvent être attribués de manière statique ou dynamique pendant l’authentification, selon certaines propriétés de l’utilisateur. En fonction du domaine qui a authentifié l’utilisateur, les propriétés servant à l’attribution des rôles peuvent correspondre à l’appartenance à un groupe dans un système externe, au suffixe du nom de l’utilisateur dans Elasticsearch, ou à autre chose encore. En outre, Elasticsearch propose également une fonctionnalité run as, qui permet à un utilisateur de soumettre une requête au nom d’un autre utilisateur sans avoir à s’authentifier de nouveau.
Une fois l’étape d’authentification terminée, c’est au tour de l’autorisation. Le processus est représenté dans le graphique ci-dessous :
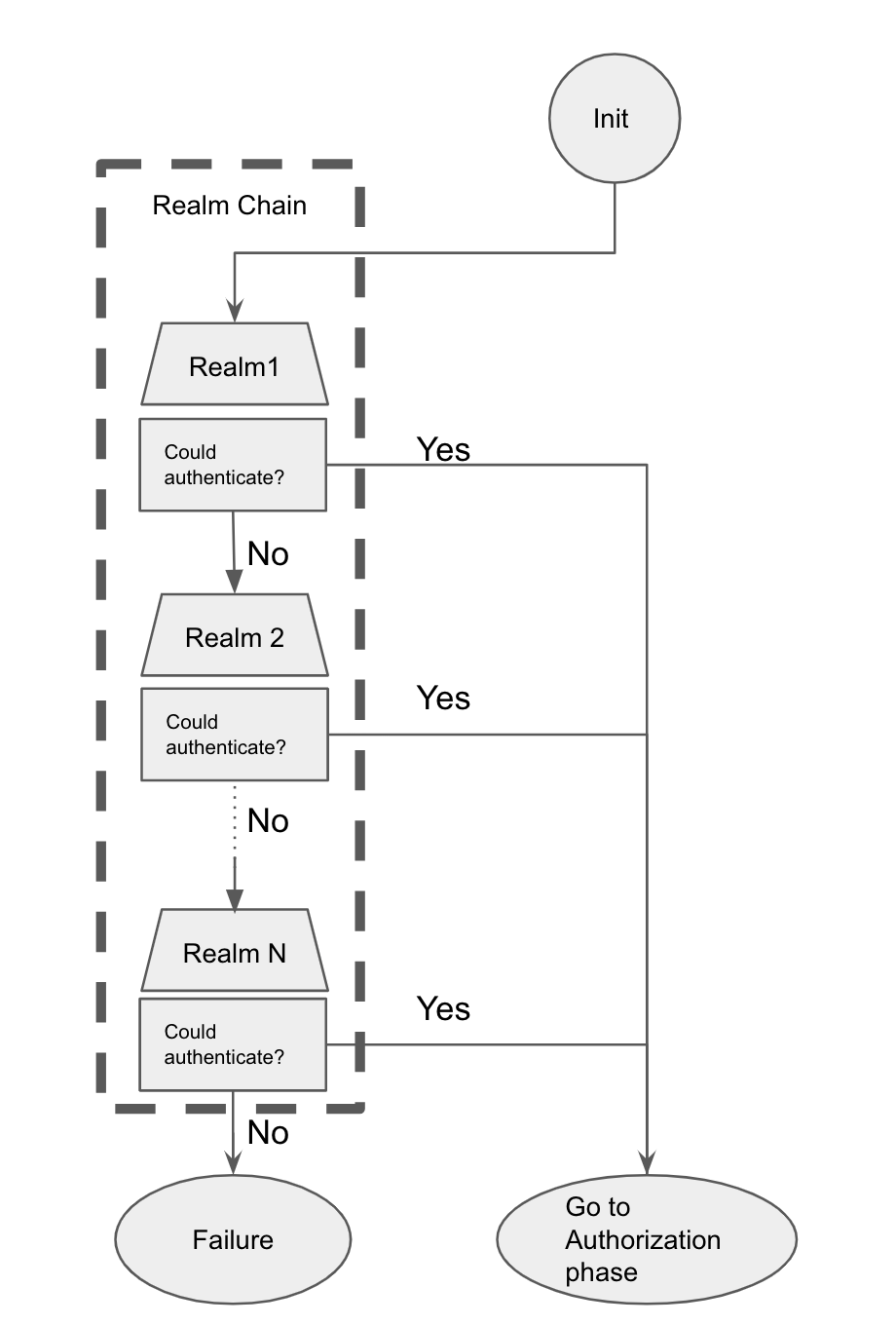
L’autorisation dans Elasticsearch
Une fois l’authentification réussie, l’utilisateur passe alors au deuxième point de contrôle de sécurité : l’autorisation. L’autorisation est le processus qui consiste à déterminer si un utilisateur peut exécuter une requête ou non. Dans cette optique, les utilisateurs sont mappés à des rôles prédéfinis et/ou définis par l’utilisateur. Des rôles sont proposés par défaut dans Elasticsearch. Mais vous pouvez très bien créer des rôles spécifiques en fonction de votre cas d'utilisation.
Un rôle est constitué des éléments suivants :
- Une liste des utilisateurs qui disposent d’un accès
- Des privilèges de cluster
- Des privilèges globaux
- Des privilèges relatifs à des index
- Des privilèges relatifs à des applications
Pour cette deuxième étape, Elasticsearch se servira de l’un des éléments suivants :
- L’API role_mapping API, qui constitue la méthode recommandée car vous pouvez y gérer les mappings de chaque rôle de manière centralisée. C’est la seule méthode pour configurer des mappings de rôle dans Elasticsearch Service sur Elastic Cloud.
- Le fichier role-mapping (role_mapping.yml), qui réside dans chaque nœud du dossier de configuration.
L’API role_mapping doit être appelée par un utilisateur disposant des droits appropriés de gestion des rôles. C’est le cas du rôle superuser, par exemple, dont l’utilisateur Elastic dispose. Mais vous pouvez également créer un rôle spécifique en la matière.
Les domaines et les rôles sont totalement différents par définition. Les domaines et les chaînes de domaines sont les éléments dont nous nous servons pour l’authentification, et c’est seulement après que l’authentification a abouti que nous utilisons les rôles mappés aux utilisateurs. Un utilisateur sera authentifié uniquement par un domaine unique de la chaîne de domaines. Il peut, en revanche, disposer d’un ou de plusieurs rôles. C’est ce que l’on appelle le contrôle d'accès basé sur les rôles.
Résolution des problèmes d’authentification et d’autorisation
Maintenant que nous avons vu les concepts de base de l’authentification et de l’autorisation, voyons comment procéder si vous êtes confronté à un problème.
401 Unauthorized
Si aucun domaine ne permet de vous authentifier, vous obtiendrez un message avec le code 401 Unauthorized. La manière la plus simple de tester vos informations d’identification par rapport à la liste des domaines configurés, c’est d’utiliser cURL avec un indicateur permettant l’inspection (par exemple, -v). Vous devriez obtenir une réponse de ce type :
curl https://xxxxxx:9200 -u test:test -v
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 401 Unauthorized
< Content-Type: application/json; charset=UTF-8
< Date: Tue, 10 Sep 2019 15:59:33 GMT
< Www-Authenticate: Bearer realm="security"
< Www-Authenticate: ApiKey
< Www-Authenticate: Basic realm="security" charset="UTF-8"
< Content-Length: 455
< Connection: keep-alive
<
* Connection #0 to host 06618318cff64c829af1cd5a2beb91a5.us-east-1.aws.found.io left intact
{"error":{"root_cause":[{"type":"security_exception","reason":"unable to authenticate user [test] for REST request [/]","header":{"WWW-Authenticate":["Bearer realm=\"security\"","ApiKey","Basic realm=\"security\" charset=\"UTF-8\""]}}],"type":"security_exception","reason":"unable to authenticate user [test] for REST request [/]","header":{"WWW-Authenticate":["Bearer realm=\"security\"","ApiKey","Basic realm=\"security\" charset=\"UTF-8\""]}},"status":401}%
Ce message d’erreur vous aidera à déterminer la cause première de votre problème. Par exemple, certains domaines, comme SAML, nécessitent Kibana ou une application Web personnalisée pour réaliser l’interaction avec Elasticsearch et le fournisseur d’identité.
Activation du logging d’erreur
Après avoir configuré les domaines, la chaîne de domaines, les rôles et les mappings de rôles, si les problèmes persistent, vous pouvez configurer un logging supplémentaire pour obtenir davantage d’informations sur les étapes d’authentification et d’autorisation abordées précédemment.
Avec la configuration de logging de l’API de paramètres du cluster, vous pouvez définir le niveau de logging que vous souhaitez pour n’importe quel domaine.
Prenons l’exemple d’un domaine LDAP. Si l’authentification ou l’autorisation d’un utilisateur échoue, vous pouvez définir le niveau de logging comme suit pour en savoir plus :
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.xpack.security.authc.ldap":"DEBUG",
"logger.org.elasticsearch.xpack.security.authz":"DEBUG"
}
}
En procédant ainsi, le logging du package LDAP passera du niveau par défaut au niveau DEBUG. Vous pouvez également activer le niveau TRACE pour obtenir encore plus d’informations, par exemple sur chaque appel LDAP passé au serveur et la réponse obtenue. Vous trouverez le nom du package à activer pour chaque DOMAINE spécifique dans notre référentiel GitHub. Par exemple, voici le code pour le domaine LDAP. Sur la première ligne de code, vous pouvez voir le package à utiliser pour le niveau de logging :
package org.elasticsearch.xpack.security.authc.ldap;
Une fois le package activé, vous obtiendrez un certain nombre de lignes de log, comme dans l’exemple suivant :
[2019-09-12T08:41:20,628][DEBUG][o.e.x.s.a.l.LdapRealm ] [xxxxxxx] user not found in cache, proceeding with normal authentication
[2019-09-12T08:41:21,180][TRACE][o.e.x.s.a.l.s.LdapUtils ] LDAP Search SearchRequest(baseDN='dc=xxx,dc=xxxx,dc=domain,dc=com', scope=SUB, deref=NEVER, sizeLimit=0, timeLimit=5, filter='(cn=vchatzig)', attrs={1.1}) => SearchResult(resultCode=0 (success), messageID=2, entriesReturned=1, referencesReturned=0) ([SearchResultEntry(dn='cn=xxxxxxx,ou=xxxxx,dc=intc,dc=xxxx,dc=domain,dc=com', messageID=2, attributes={}, controls={})])
Ici, nous voyons que le domaine LDAP essaie d’identifier l’utilisateur à partir du cache (qui est peut-être obsolète), puis qu’il émet une requête LDAP Search au serveur à l’aide des configurations spécifiques que nous avons fournies. Avec cet exemple, vous avez désormais une idée du nombre de lignes de log renvoyées.
|
Remarque : L’activation du logging est idéale à des fins de diagnostic. Mais elle nuit aux performances. Nous vous recommandons donc de rétablir le niveau de logging sur sa valeur par défaut dès que le problème est résolu, en procédant comme suit : PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.xpack.security.authc.ldap": null,
"logger.org.elasticsearch.xpack.security.authz": null
}
}
|
À noter : certains packages peuvent varier d’une version à l’autre. Nous vous recommandons donc de vérifier à deux fois les liens de documentation correspondant à la version Elasticsearch dont vous disposez, ainsi que les liens vers les classes GitHub applicables à cette version.
Problèmes SAML courants
Le domaine SAML nécessite un fournisseur d’identité (comme Okta ou Auth0) et une application Web (Kibana par défaut) qui font office de fournisseur de service avec Elasticsearch. Vous trouverez ci-dessous quelques-uns des problèmes fréquemment rencontrés :
- Paramètre Assertion Consumer Service URL incorrect dans la configuration du fournisseur d’identité. Le point de terminaison que vous devez généralement configurer au niveau du fournisseur d’identité est https://kibana.xxxx.com/api/security/v1/saml
- Les métadonnées du fournisseur d’identité ne sont pas accessibles par Internet. La valeur de la configuration idp.metadata.path dans Elasticsearch (sur site ou dans Elastic Cloud) devrait être accessible par le réseau sur lequel Elasticsearch et Kibana s’exécutent. Si ce n’est pas le cas, vous devez télécharger les métadonnées à partir d’un hôte qui peut y accéder, ou demander à un administrateur du fournisseur d’identité de vous fournir ces métadonnées pour les ajouter en tant que fichier local dans Elasticsearch et les référencer. L’erreur que vous obtiendrez sera similaire à celle-ci :
Caused by: net.shibboleth.utilities.java.support.resolver.ResolverException: net.shibboleth.utilities.java.support.resolver.ResolverException: Non-ok status code 404 returned from remote metadata source https://xxxx.xxxx/xxx/yyyyyyyy/sso/saml/metadata - Un utilisateur peut être authentifié et pourtant ne pas réussir à ouvrir Kibana. Si la situation se produit, nous recommandons généralement de vérifier les mappings de rôle affecté à l’utilisateur afin de déterminer si au moins l’un de ses rôles lui permet d’accéder à Kibana.
La configuration du fournisseur d’identité est aussi importante que celle d’Elasticsearch et de Kibana. Il est essentiel de rechercher systématiquement les éventuelles coquilles ou absences de correspondance entre les paramètres attendus et les paramètres configurés. Même si chaque fournisseur d’identité dispose de ses propres paramètres, nous vous recommandons de bien lire la documentation de chaque paramètre spécifique nécessaire.
Si vous souhaitez consulter d’autres problèmes fréquents et méthodes de résolution pour SAML, consultez notre documentation relative à la résolution. Il y en a une pour chaque version.
Pour conclure
L’authentification dans Elasticsearch est vraiment ultra simple à configurer à partir du moment où l’on comprend les concepts qui la sous-tendent. Il est parfois difficile de savoir ce qui fonctionne, ce qui ne fonctionne pas, et pourquoi. Mais dans cet article, nous avons vu plusieurs possibilités pour approfondir le sujet. N’hésitez pas à vous appuyer sur notre documentation pour vous familiariser avec la sécurité dans Elasticsearch ou à utiliser notre guide relatif à la résolution pour en savoir plus. Écoutez notre Chef de produit senior pour Elastic Security expliquer en détail la prise en main de la sécurité.
N’hésitez pas non plus à consulter régulièrement notre page Abonnements pour en savoir plus sur les fonctionnalités incluses dans chaque niveau. Pour finir, si vous avez des questions spécifiques, contactez notre représentant du support technique ou rendez-vous sur nos forums de discussion.
À vous de jouer !