July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.


July 2, 2026
A simdvec deep-dive: How Elasticsearch uses neural-net and video-codec CPU instructions for vector search
Four ways Elasticsearch's vector search engine reuses neural-network, video-codec and cryptography CPU instructions for up to 6x speedups; with the math, the failed attempts and the benchmarks.

June 24, 2026
Elasticsearch DiskBBQ delivers 7x faster vector search than Qdrant on network-attached storage
Elasticsearch DiskBBQ achieves up to 7x higher vector search throughput than Qdrant at comparable recall on network-attached storage. Explore the benchmark methodology and full results.

June 18, 2026
Jingra: A Reproducible Framework for Vector Search Benchmarking
Jingra is an open source benchmarking framework that runs the same vector search workload across Elasticsearch, OpenSearch and Qdrant so you can compare engines under identical, reproducible conditions.
June 16, 2026
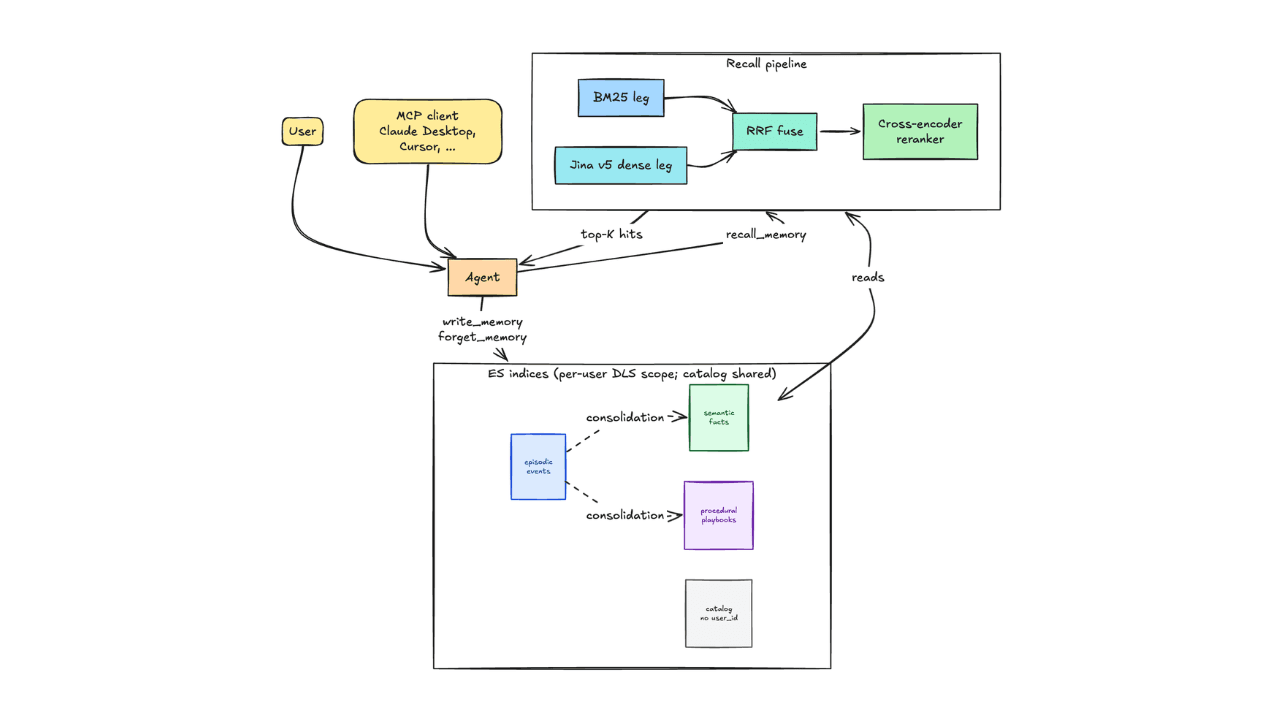
How we built a persistent agent memory layer on Elasticsearch with 0.89 recall and zero tenant leaks
Discover the architecture behind a persistent, multi-tenant agent memory layer on Elasticsearch: three indices, hybrid retrieval with RRF and a reranker, supersession, decay, and per-user DLS isolation. R@10 0.89 across 168 questions. Full open-source implementation included.
June 10, 2026
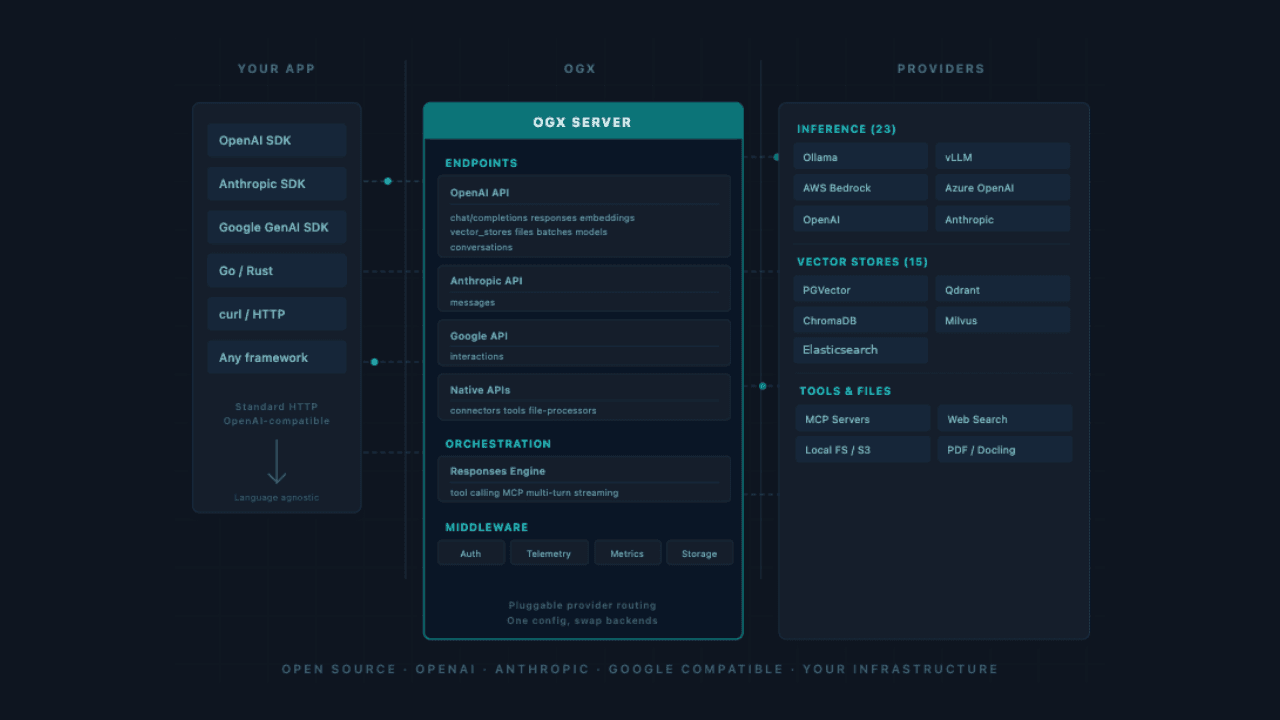
Your AI agent reads the fine print: building a RAG pipeline over EU regulations with Elasticsearch and OGX
Learn how to configure Elasticsearch as an OGX vector store, ingest EU regulation PDFs and build a Python RAG agent that runs hybrid BM25 and vector search with source-level citations.

June 9, 2026
Best practices for building a modern app with vector search
Exploring six vector search tips for building modern AI search applications entirely on Elasticsearch, with an opinionated rationale at each architectural decision.

June 8, 2026
Elasticsearch simdvec deep-dive: Walking the memory tightrope to 2x better vector throughput
A deep dive into four optimizations (cascade unrolling, batch prefetching, dim-axis unrolling, a structural refactor) that pushed Elasticsearch simdvec to 2x vector throughput by working with the CPU, not against it.
June 2, 2026
Elasticsearch DiskBBQ: 40% faster vector scoring with native SIMD Blocks
A deep dive into how DiskBBQ's block layout, doc ID compression modes and native SIMD kernels combine to deliver 40% improved vector scoring throughput for DiskBBQ in 9.4.