4. Mai 2026
So messen und verbessern Sie den Elasticsearch-Suchabruf: von 0,43 auf 0,75 mit Hybridsuche
Erfahren Sie, wie Sie den Suchabruf in Elasticsearch messen und verbessern können, indem Sie die lexikalische BM25-Suche mit Jina AI-Vektoreinbettungen kombinieren und dabei die rank_eval-API nutzen, um die Verbesserung mit realen Zahlen zu validieren.


23. April 2026
Wie wir Elasticsearch simdvec entwickelten, um die Vektorsuche zu einer der schnellsten weltweit zu machen
Wie wir Elasticsearch simdvec entwickelten, die von Hand optimierte SIMD-Kernel-Bibliothek hinter jeder Vektorsuchanfrage in Elasticsearch.

2. April 2026
Wenn TSDS auf ILM trifft: Gestaltung von Zeitreihendatenströmen, die verspätete Daten nicht ablehnen
Interaktion zwischen den Zeitgrenzen von TSDS und den ILM-Phasen und Erstellung von Richtlinien, die verspätet eintreffende Metriken tolerieren.

1. April 2026
LINQ to Elasticsearch ES|QL: C# schreiben, Elasticsearch abfragen
Erkundung des neuen LINQ to Elasticsearch ES|QL-Providers im Elasticsearch .NET-Client, mit dem Sie C#-Code schreiben können, der automatisch in ES|QL-Abfragen übersetzt wird.

20. März 2026
Schnell vs. genau: Messung der Recall-Rate bei der quantisierten Vektorsuche
Eine Erklärung, wie der Recall für die Vektorsuche in Elasticsearch mit minimalem Aufwand gemessen werden kann.
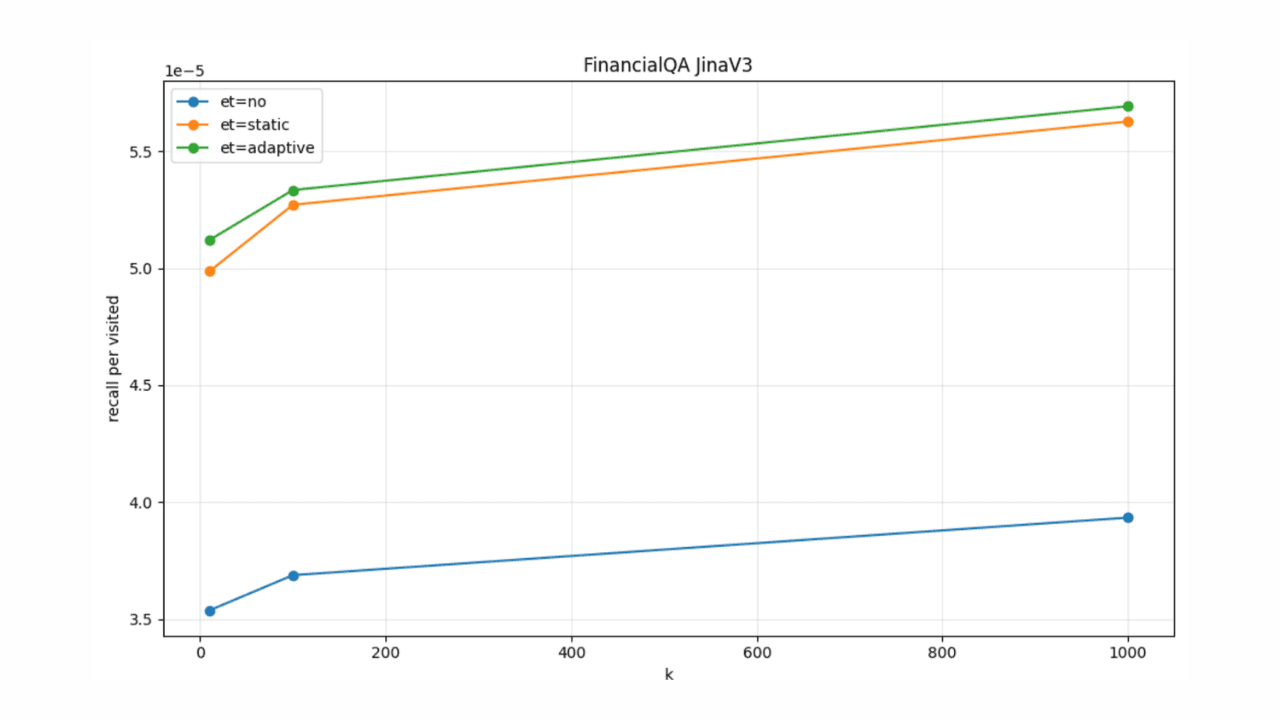
2. März 2026
Adaptive vorzeitige Beendigung für HNSW in Elasticsearch
Einführung einer neuen adaptiven Strategie zur vorzeitigen Beendigung von HNSW in Elasticsearch.
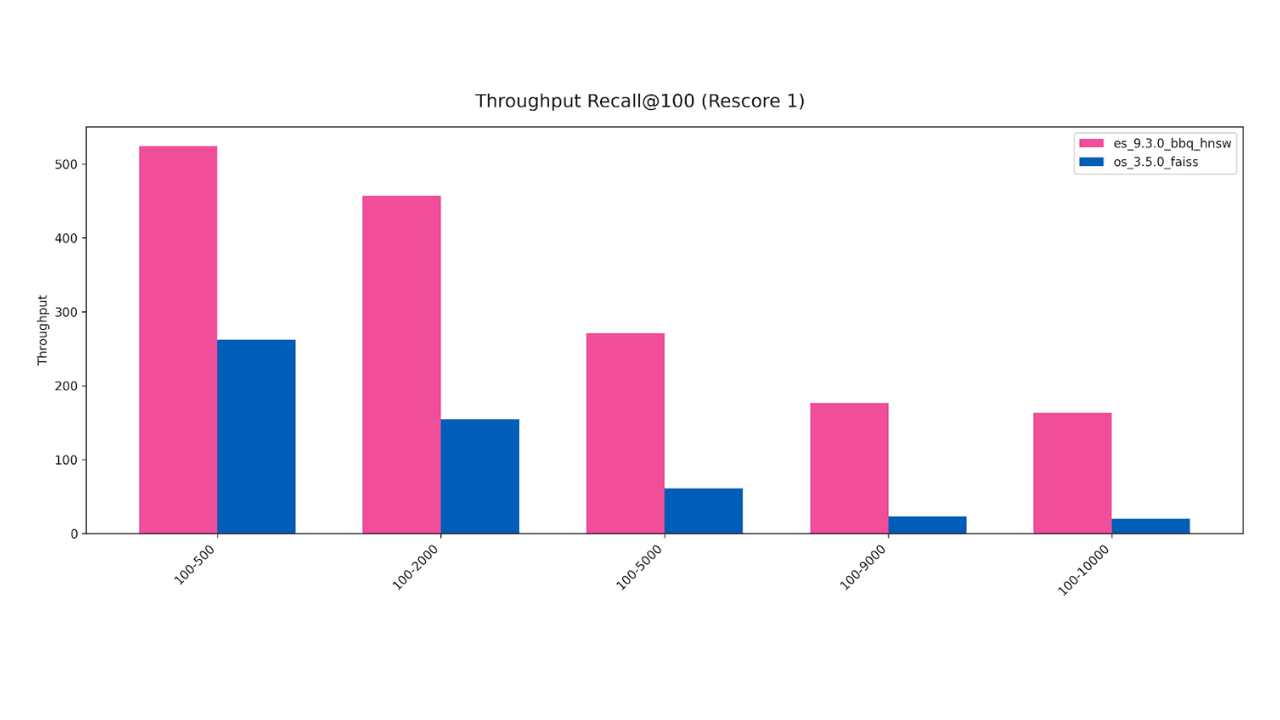
25. Februar 2026
Die Vektorsuche in Elasticsearch ist bis zu 8-mal schneller als in OpenSearch
Analyse von Benchmarks zum gefilterten Vektorsuchen: OpenSearch und Elasticsearch im Vergleich – und warum die Performance des Vektorsuchens für kontextoptimierte Systeme entscheidend ist.

3. Dezember 2025
Bis zu 12 Mal schnellere Vektorindizierung in Elasticsearch mit NVIDIA cuVS: GPU-Beschleunigung Kapitel 2
Entdecken Sie, wie Elasticsearch mit GPU-beschleunigter Vektorindizierung und NVIDIA cuVS einen fast 12-mal höheren Indizierungsdurchsatz erzielt.

4. November 2025
Multimodale Suche nach Berggipfeln mit Elasticsearch und SigLIP-2
Lernen Sie, wie Sie die multimodale Suche von Text zu Bild und von Bild zu Bild mithilfe von SigLIP-2-Einbettungen und der Elasticsearch kNN-Vektorsuche implementieren. Projektschwerpunkt: Auffinden von Fotos des Gipfels des Mount Ama Dablam während einer Everest-Trekkingtour.