Wollten Sie schon immer einmal Ihr Fotoalbum nach Bedeutung durchsuchen? Versuchen Sie Suchanfragen wie „Zeig mir meine Bilder, auf denen ich eine blaue Jacke trage und auf einer Bank sitze“, „Zeig mir Bilder vom Mount Everest“ oder „Sake und Sushi“. Schnapp dir eine Tasse Kaffee (oder dein Lieblingsgetränk) und lies weiter. In diesem Blog zeigen wir Ihnen, wie Sie eine multimodale hybride Suchanwendung erstellen. Multimodal bedeutet, dass die App verschiedene Arten von Eingaben verstehen und durchsuchen kann – Text, Bilder und Audio – und nicht nur Wörter. Hybrid bedeutet, dass Techniken wie Keyword-Matching, kNN-Vektorsuche und Geofencing kombiniert werden, um präzisere Ergebnisse zu liefern.

Um dies zu erreichen, verwenden wir Googles SigLIP-2, um Vektoreinbettungen sowohl für Bilder als auch für Texte zu generieren und diese in der Elasticsearch-Vektordatenbank zu speichern. Zum Zeitpunkt der Abfrage wandeln wir die Sucheingabe, Text oder Bild, in Einbettungen um und führen schnelle kNN-Vektorsuchen durch, um Ergebnisse abzurufen. Diese Konfiguration ermöglicht eine effiziente Text-zu-Bild- und Bild-zu-Bild-Suche. Eine Streamlit-Benutzeroberfläche erweckt dieses Projekt zum Leben, indem sie uns ein Frontend zur Verfügung stellt, mit dem wir nicht nur textbasiert nach passenden Fotos aus dem Album suchen und diese anzeigen können, sondern auch den Berggipfel auf dem hochgeladenen Bild identifizieren und weitere Fotos dieses Berges im Fotoalbum anzeigen können.
Wir beschreiben außerdem die Schritte, die wir zur Verbesserung der Suchgenauigkeit unternommen haben, und geben praktische Tipps und Tricks. Zur weiteren Erkundung stellen wir ein GitHub-Repository und ein Colab-Notebook zur Verfügung.
Wie alles begann
Dieser Blogbeitrag entstand auf Anregung eines 10-Jährigen, der mich bat, ihm alle Bilder des Mount Ama Dablam von meiner Everest-Basislager-Trekkingtour zu zeigen. Während wir das Fotoalbum durchsahen, wurde ich auch gebeten, mehrere andere Berggipfel zu identifizieren, von denen ich einige nicht benennen konnte.
Das brachte mich auf die Idee, dass dies ein unterhaltsames Computer-Vision-Projekt werden könnte. Was wir erreichen wollten:
- Finde Bilder eines Berggipfels anhand seines Namens
- Errate den Namen des Berggipfels anhand eines Bildes und finde ähnliche Gipfel im Fotoalbum.
- Konzeptabfragen zum Laufen bringen (Person, Fluss, Gebetsfahnen usw.)

Mount Ama Dablam
Zusammenstellung des Dreamteams: SigLIP-2, Elasticsearch & Streamlit
Es wurde schnell klar, dass wir, um dies zu ermöglichen, sowohl den Text („Ama Dablam“) als auch die Bilder (Fotos aus meinem Album) in Vektoren umwandeln müssten, die sinnvoll verglichen werden können, d. h. im selben Vektorraum. Sobald wir das getan haben, besteht die Suche nur noch darin, „die nächstgelegenen Nachbarn zu finden“.

SigLIP-2, das kürzlich von Google veröffentlicht wurde, passt hier gut hinein. Es kann Einbettungen ohne aufgabenspezifisches Training generieren (eine Zero-Shot -Einstellung) und eignet sich hervorragend für unseren Anwendungsfall: unbeschriftete Fotos und Gipfel mit unterschiedlichen Namen und Sprachen. Da es für die Zuordnung von Text zu Bild trainiert wurde, werden ein Bergbild von der Wanderung und eine kurze Texteingabeaufforderung als Einbettungen sehr ähnlich dargestellt, selbst wenn die Abfragesprache oder die Rechtschreibung variiert.
SigLIP-2 bietet ein gutes Verhältnis von Qualität zu Geschwindigkeit, unterstützt mehrere Eingangsauflösungen und läuft sowohl auf der CPU als auch auf der GPU. Der SigLIP-2 ist im Vergleich zu Vorgängermodellen wie dem ursprünglichen CLIP robuster für Außenaufnahmen. Während unserer Tests lieferte SigLIP-2 durchweg zuverlässige Ergebnisse. Es wird zudem sehr gut unterstützt, was es zur naheliegenden Wahl für dieses Projekt macht.
Als nächstes benötigen wir eine Vektordatenbank zum Speichern der Einbettungen und zur Durchführung der Power-Suche. Es sollte nicht nur die Cosinus-kNN-Suche über Bildeinbettungen unterstützen, sondern auch Geofencing und Textfilter in einer einzigen Abfrage anwenden. Elasticsearch passt hier gut: Es verarbeitet Vektoren (HNSW kNN auf dense_vector-Feldern) sehr gut, unterstützt die hybride Suche, die Text-, Vektor- und Geo-Abfragen kombiniert, und bietet standardmäßig Filter- und Sortierfunktionen. Es ist außerdem horizontal skalierbar, sodass man problemlos von einer Handvoll Fotos auf Tausende wachsen kann. Der offizielle Elasticsearch Python-Client hält die Infrastruktur einfach und lässt sich nahtlos in das Projekt integrieren. Schließlich benötigen wir noch ein schlankes Frontend, in dem wir Suchanfragen eingeben und Ergebnisse anzeigen können. Für eine schnelle, Python-basierte Demo ist Streamlit hervorragend geeignet. Es bietet die grundlegenden Funktionen, die wir benötigen – Datei-Upload, ein responsives Bildraster und Dropdown-Menüs zum Sortieren und Geofencing. Es lässt sich leicht klonen und lokal ausführen und funktioniert auch in einem Colab-Notebook.
Implementierung
Elasticsearch-Indexierungsdesign und Indexierungsstrategie
Für dieses Projekt verwenden wir zwei Indizes: peaks_catalog und photos.
Peaks_Katalogindex
Dieser Index dient als kompakter Katalog markanter Berggipfel, die während der Everest-Basislager-Trekkingtour sichtbar sind. Jedes Dokument in diesem Index entspricht einem einzelnen Berggipfel, wie zum Beispiel dem Mount Everest. Für jedes Berggipfeldokument speichern wir Namen/Aliasse, optionale Breiten- und Längengradkoordinaten sowie einen einzelnen Prototypvektor, der durch die Kombination von SigLIP-2-Texteingabeaufforderungen (+ optionalen Referenzbildern) erstellt wird.
Indexzuordnung:
| Feld | Typ | Beispiel | Zweck/Anmerkungen | Vektor-/Indexierung |
|---|---|---|---|---|
| Ausweis | Stichwort | ama-dablam | Stabiler Slug/ID | — |
| Namen | Text + Stichwort-Unterfeld | ["Ama Dablam","Amadablam"] | Aliase / mehrsprachige Namen; names.raw für genaue Filter | — |
| Breitengrad | Geopunkt | {"lat":27.8617,"lon":86.8614} | GPS-Koordinaten des Gipfels als Kombination aus Breitengrad und Längengrad (optional) | — |
| elev_m | ganze Zahl | 6812 | Höhenangabe (optional) | — |
| text_embed | dense_vector | 768 | Kombinierter Prototyp (Aufforderungen und optional 1–3 Referenzbilder) für diesen Peak | index:true, similarity:"cosine", index_options:{type:"hnsw", m:16, ef_construction:128} |
Dieser Index wird vor allem für Bild-zu-Bild-Suchen verwendet, beispielsweise zur Identifizierung von Berggipfeln anhand von Bildern. Wir verwenden diesen Index auch, um die Ergebnisse der Text-zu-Bild-Suche zu verbessern.
Zusammenfassend lässt sich sagen, dass die peaks_catalog die Frage „Welcher Berg ist das?“ in ein fokussiertes Nächste-Nachbar-Problem umwandelt und so das konzeptionelle Verständnis effektiv von der Komplexität der Bilddaten trennt.
Indexierungsstrategie für den peaks_catalog-Index: Wir beginnen mit der Erstellung einer Liste der markantesten Gipfel, die während der EBC-Trekkingtour sichtbar sind. Für jeden Gipfel speichern wir seine geografische Position, seinen Namen, Synonyme und seine Höhe in einer YAML-Datei. Im nächsten Schritt wird für jeden Peak die Einbettung generiert und im Feld text_embed gespeichert. Um robuste Einbettungen zu erzeugen, verwenden wir die folgende Technik:
- Erstellen Sie einen Textprototyp mit folgendem Werkzeug:
- Namen der Gipfel
- Prompt-Ensemble (Verwendung mehrerer unterschiedlicher Prompts, um dieselbe Frage zu beantworten), zum Beispiel:
- „Ein Naturfoto des Berggipfels {name} im Himalaya, Nepal“
- „ {name} markanter Gipfel in der Khumbu-Region, alpine Landschaft“
- „ {name} Berggipfel, Schnee, felsiger Grat“
- optionales Anti-Konzept (sagt SigLIP-2, wonach nicht gematcht werden soll): einen kleinen Vektor für „Gemälde, Illustration, Poster, Karte, Logo“ abziehen, um eine Bevorzugung von echten Fotos zu erreichen.
- Optional kann ein Bildprototyp erstellt werden, falls Referenzbilder des Gipfels vorhanden sind.
Anschließend verschmelzen wir den Text- und Bildprototyp , um die endgültige Einbettung zu erzeugen. Abschließend wird das Dokument mit allen erforderlichen Feldern indexiert :
Beispieldokument aus dem Index peaks_catalog :

Fotoindex
Dieser Hauptindex speichert detaillierte Informationen über alle Fotos im Album. Jedes Dokument stellt ein einzelnes Foto dar und enthält folgende Informationen:
- Relativer Pfad zum Foto im Fotoalbum. Dies kann verwendet werden, um das passende Bild anzuzeigen oder das Bild in die Suchoberfläche zu laden.
- GPS- und Zeitinformationen des Bildes.
- Dichter Vektor für die Bildkodierung, generiert durch SigLIP-2.
predicted_peaksDas ermöglicht es uns, nach Gipfelnamen zu filtern.
Indexzuordnung
| Feld | Typ | Beispiel | Zweck/Anmerkungen | Vektor-/Indexierung |
|---|---|---|---|---|
| Weg | Stichwort | data/images/IMG_1234.HEIC | Wie die Benutzeroberfläche das Miniaturbild/Vollbild öffnet | — |
| Bildausschnitt | dense_vector | 768 | SigLIP-2 Bildeinbettung | index:true, similarity:"cosine", index_options:{type:"hnsw", m:16, ef_construction:128} |
| vorhergesagte_Spitzen | Stichwort | ["ama-dablam","pumori"] | Top-K-Vorhersagen zur Indexierungszeit (kostengünstiger UX-Filter / Facette) | — |
| GPS | Geopunkt | {"lat":27.96,"lon":86.83} | Aktiviert Geofilter | — |
| Schusszeit | date | 2023-10-18T09:41:00Z | Aufnahmezeit: Sortieren/Filtern | — |
Indexierungsstrategie für den Fotoindex: Für jedes Foto im Album gehen wir wie folgt vor:
Extrahieren Sie die Bildinformationen shot_time und gps aus den Bildmetadaten.
- SigLIP-2 Bildeinbettung: Das Bild wird durch das Modell geleitet und der Vektor anschließend L2-normalisiert. Speichere die Einbettung im Feld
clip_image. - Die Peaks werden vorhergesagt und im Feld
predicted_peaksgespeichert. Dazu nehmen wir zunächst den im vorherigen Schritt erzeugten Bildvektor des Fotos und führen dann eine schnelle kNN-Suche im Feld text_embed im Indexpeaks_catalogdurch. Wir behalten die obersten 3-4 Spitzen bei und ignorieren den Rest. - Wir berechnen das Feld
_id, indem wir einen Hashwert aus Bildname und Pfad erstellen. Dadurch wird sichergestellt, dass nach mehreren Durchläufen keine Duplikate entstehen.
Sobald alle Felder für das Foto ermittelt wurden, werden die Fotodokumente mithilfe der Massenindizierung stapelweise indexiert:
Beispieldokument aus dem Fotoindex:
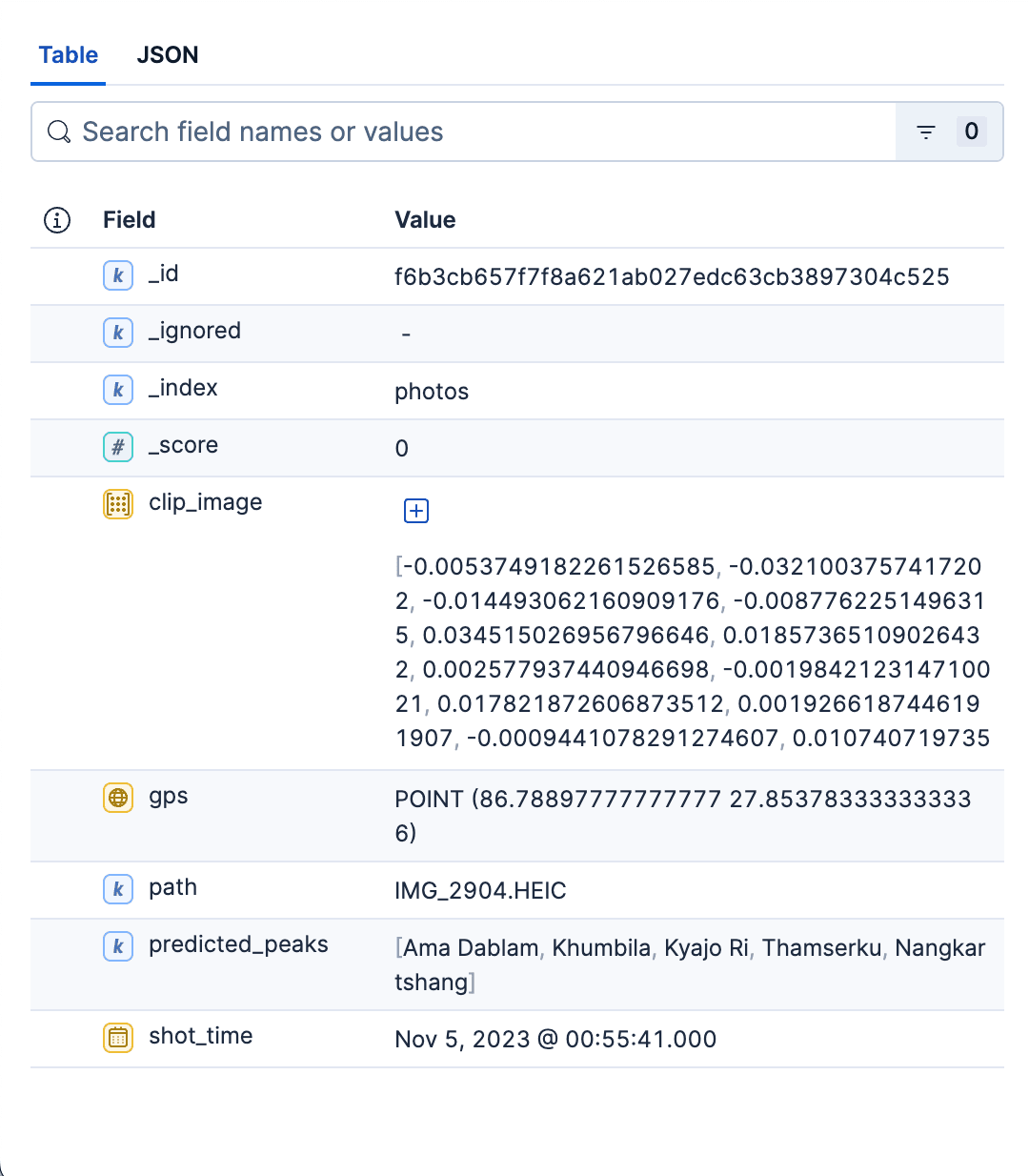
Zusammenfassend lässt sich sagen, dass der Fotoindex ein schneller, filterbarer und kNN-fähiger Speicher aller Fotos im Album ist. Die Kartierung ist bewusst minimalistisch gehalten – gerade so strukturiert, dass die Ergebnisse schnell abgerufen, übersichtlich dargestellt und nach Raum und Zeit unterteilt werden können. Dieser Index dient beiden Suchanwendungsfällen. Das Python-Skript zur Erstellung beider Indizes finden Sie hier.
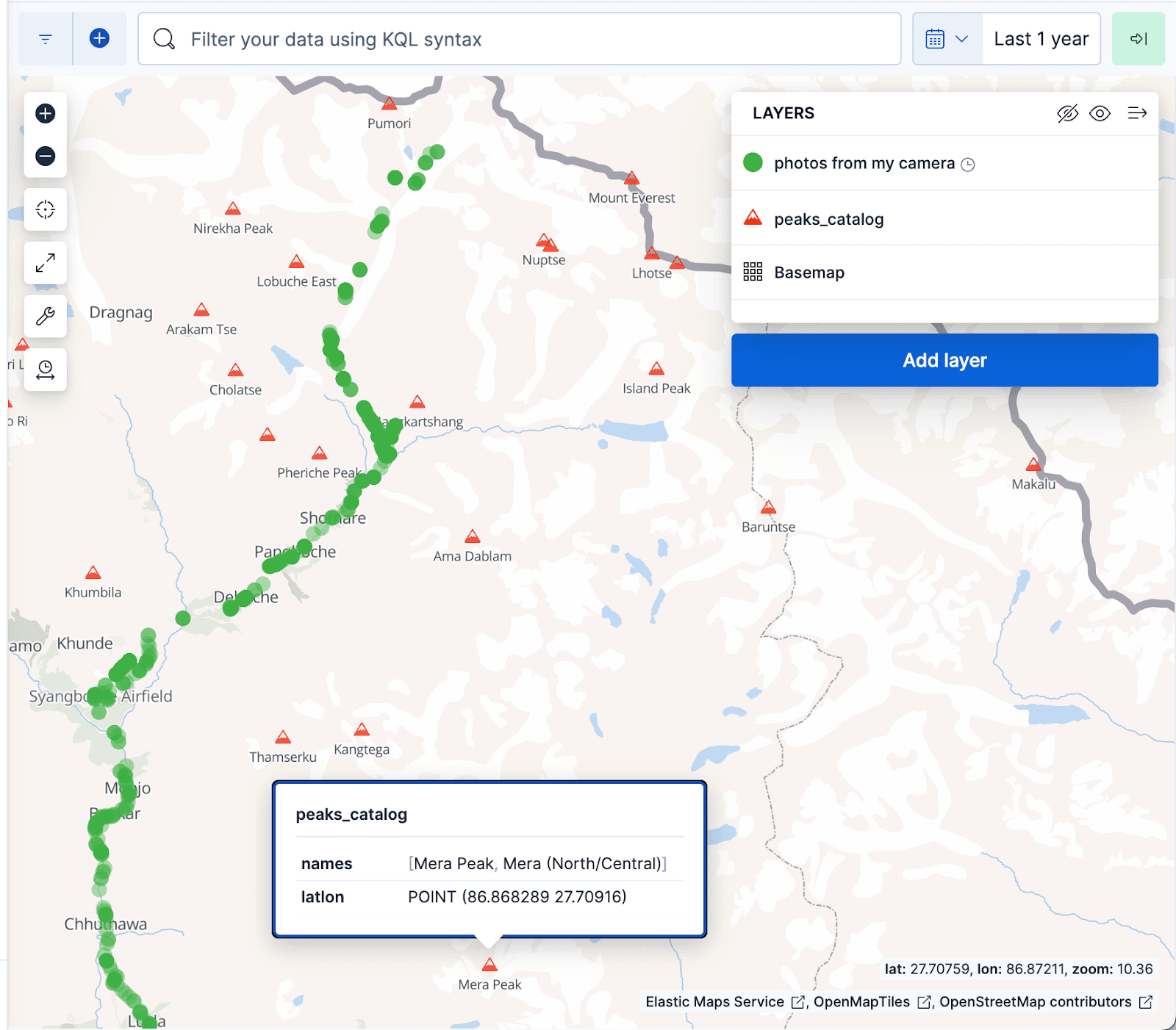
Die untenstehende Visualisierung der Kibana-Karten zeigt Dokumente aus dem Fotoalbum als grüne Punkte und Berggipfel ab dem Index peaks_catalog als rote Dreiecke an, wobei die grünen Punkte gut mit dem Wanderweg zum Everest-Basislager übereinstimmen.
Suchanwendungsfälle
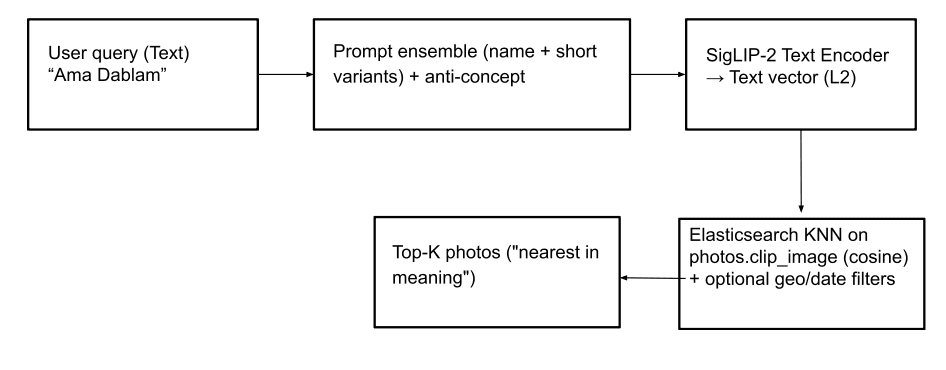
Namenssuche (Text-zu-Bild): Mit dieser Funktion können Benutzer mithilfe von Textanfragen Fotos von Berggipfeln (und sogar abstrakten Konzepten wie „Gebetsfahnen“) finden. Um dies zu erreichen, wird die Texteingabe mithilfe von SigLIP-2 in einen Textvektor umgewandelt . Für eine robuste Textvektorgenerierung verwenden wir die gleiche Strategie wie für die Erstellung von Text-Embeddings im peaks_catalog -Index: Kombination der Texteingabe mit einem kleinen Prompt-Ensemble, Subtraktion eines minor Anti-Concept-Vektors und Anwendung der L2-Normalisierung zur Erzeugung des endgültigen Abfragevektors. Anschließend wird eine kNN- Abfrage auf dem Feld photos.clip_image ausgeführt, um die am besten übereinstimmenden Peaks auf Basis der Kosinusähnlichkeit zu ermitteln und so die ähnlichsten Bilder zu finden. Optional können die Suchergebnisse relevanter gestaltet werden, indem Geo- und Datumsfilter und/oder ein photos.predicted_peaks -Termfilter als Teil der Abfrage angewendet werden (siehe Abfragebeispiele unten). Dadurch werden ähnlich aussehende Gipfel ausgeschlossen, die auf der Wanderung gar nicht sichtbar sind.
Elasticsearch-Abfrage mit Geofilter:
Bildsuche (Bild-zu-Bild): Mit dieser Funktion können wir einen Berg auf einem Bild identifizieren und weitere Bilder desselben Berges innerhalb des Fotoalbums finden. Beim Hochladen eines Bildes wird dieses vom SigLIP-2-Bildcodierer verarbeitet, um einen Bildvektor zu erzeugen. Anschließend wird eine kNN-Suche im Feld peaks_catalog.text_embed durchgeführt, um die am besten passenden Peaknamen zu identifizieren. Anschließend wird aus diesen übereinstimmenden Peaknamen ein Textvektor generiert und eine weitere kNN-Suche im Fotoindex durchgeführt, um entsprechende Bilder zu finden.

Elasticsearch-Abfrage:
Schritt 1: Finde die passenden Peaknamen
Schritt 2: Führen Sie eine Suche im Index photos durch, um die passenden Bilder zu finden (dieselbe Abfrage wie im Anwendungsfall der Text-zu-Bild-Suche):
Streamlit-Benutzeroberfläche
Um alles zusammenzuführen, haben wir eine einfache Streamlit-Benutzeroberfläche entwickelt, die es uns ermöglicht, beide Suchanwendungsfälle durchzuführen. In der linken Spalte wird eine scrollbare Liste von Gipfeln (aggregiert aus photos.predicted_peaks) mit Kontrollkästchen und einem Mini-Karten-/Geofilter angezeigt. Ganz oben befinden sich ein Suchfeld für den Namen und eine Schaltfläche zum Hochladen eines Fotos zur Identifizierung . Im mittleren Bereich befindet sich ein responsives Miniaturraster mit kNN-Werten, vorhergesagten Spitzenwerten und Erfassungszeiten. Jedes Bild enthält eine Schaltfläche „Bild anzeigen“ für Vorschauen in voller Auflösung.
Suche durch Hochladen eines Bildes: Wir prognostizieren den Peak und finden übereinstimmende Peaks aus dem Fotoalbum.
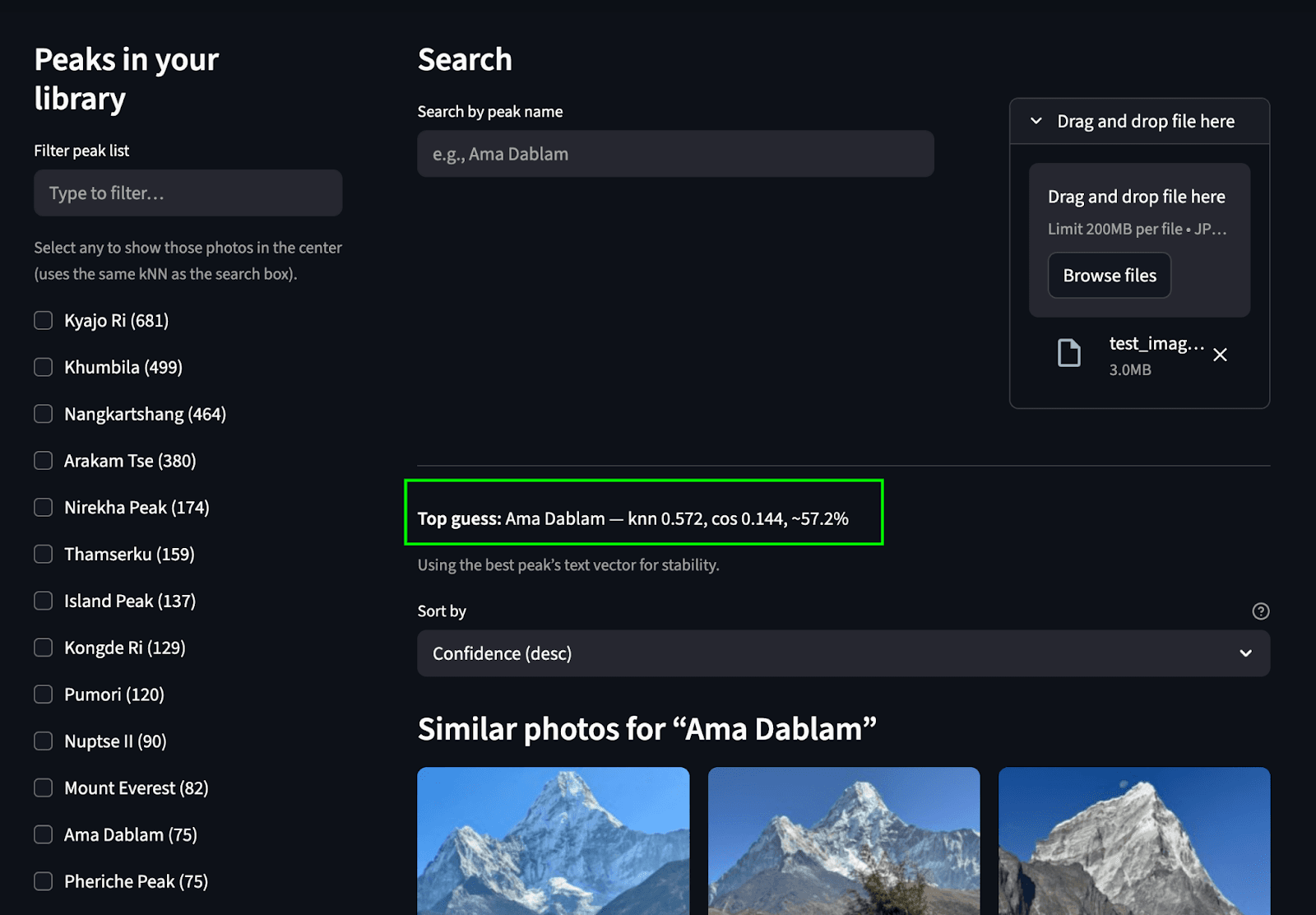
Suche nach Text: Finde die passenden Höhepunkte im Album anhand des Textes
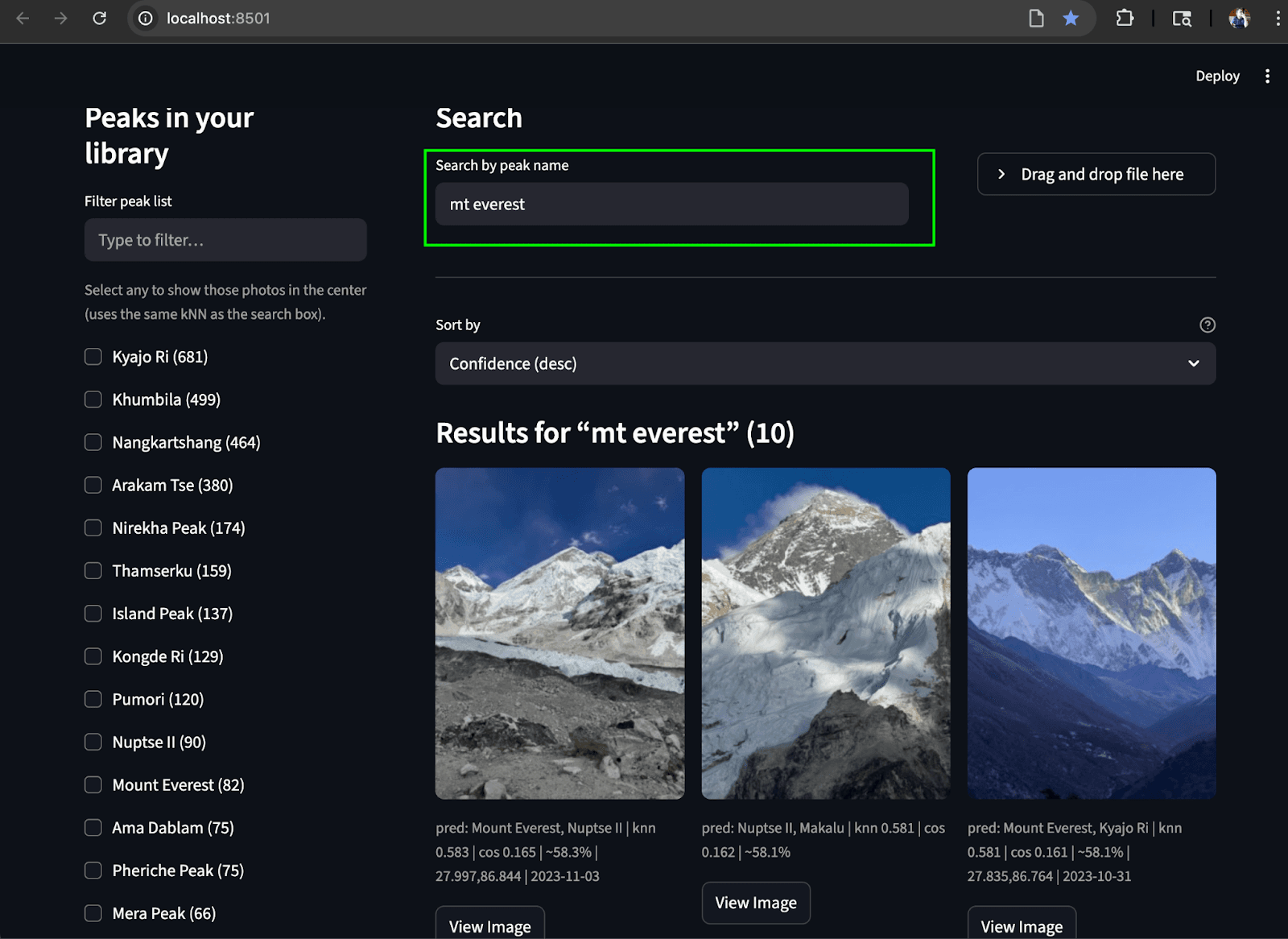
Fazit
Was mit der Frage begann: Können wir bitte die Bildervon Ama Dablamsehen? entwickelte sich zu einem kleinen, funktionierenden multimodalen Suchsystem . Wir haben Rohdaten von Trekkingfotos aufgenommen, diese in SigLIP-2-Einbettungen umgewandelt und Elasticsearch verwendet, um ein schnelles kNN über Vektoren durchzuführen, sowie einfache Geo-/Zeitfilter, um die richtigen Bilder anhand ihrer Bedeutung anzuzeigen. Dabei haben wir die Belange mithilfe zweier Indizes getrennt: einem winzigen peaks_catalog Index von kombinierten Prototypen (zur Identifizierung) und einem skalierbaren photos Index von Bildvektoren und EXIF-Daten (zum Abruf). Es ist praktisch, reproduzierbar und leicht erweiterbar.
Falls Sie es feinabstimmen möchten, gibt es einige Einstellungen, mit denen Sie experimentieren können:
- Einstellungen für die Abfragezeit:
k(wie viele Nachbarn Sie zurückbekommen möchten) undnum_candidates(wie breit die Suche vor der endgültigen Bewertung sein soll). Diese Einstellungen werden hier im Blog besprochen. - Indexzeiteinstellungen:
m(Graphkonnektivität) undef_construction(Genauigkeit der Build-Zeit vs. Speicher). Experimentieren Sie bei Abfragen auch mitef_search– ein höherer Wert bedeutet in der Regel eine bessere Trefferquote, allerdings mit einem gewissen Nachteil bei der Latenz. Weitere Einzelheiten zu diesen Einstellungen finden Sie in diesem Blog .
Zukünftig werden native Modelle/Reranker für multimodale und mehrsprachige Suche in Kürze im Elastic-Ökosystem verfügbar sein. Dies dürfte die Bild-/Textsuche und das hybride Ranking von Haus aus noch weiter verbessern. ir.elastic.co+1
Wenn Sie das selbst ausprobieren möchten:
- GitHub-Repository: https://github.com/navneet83/multimodal-mountain-peak-search
- Colab-Schnellstartanleitung: https://github.com/navneet83/multimodal-mountain-peak-search/blob/main/notebooks/multimodal_mountain_peak_search.ipynb
Damit ist unsere Reise zu Ende, und es ist Zeit, zurückzufliegen. Ich hoffe, das war hilfreich, und falls etwas kaputtgeht (oder verbessert wird), würde ich gerne erfahren, was Sie geändert haben.

Zugehörige Inhalte

Beschreiben statt zeichnen: KI-native Kibana-Dashboards über MCP und ES|QL
Vom Prompt zum Dashboard. Erfahren Sie, wie Sie Kibana-Dashboards in natürlicher Sprache mit example-mcp-dashbuilder erstellen: eine Open-Source-MCP-Anwendung, die ES|QL-Abfragen schreibt, interaktive Diagramme erstellt und voll funktionsfähige Dashboards direkt in Kibana exportiert.

23. April 2026
Wie wir Elasticsearch simdvec entwickelten, um die Vektorsuche zu einer der schnellsten weltweit zu machen
Wie wir Elasticsearch simdvec entwickelten, die von Hand optimierte SIMD-Kernel-Bibliothek hinter jeder Vektorsuchanfrage in Elasticsearch.

4. Mai 2026
So messen und verbessern Sie den Elasticsearch-Suchabruf: von 0,43 auf 0,75 mit Hybridsuche
Erfahren Sie, wie Sie den Suchabruf in Elasticsearch messen und verbessern können, indem Sie die lexikalische BM25-Suche mit Jina AI-Vektoreinbettungen kombinieren und dabei die rank_eval-API nutzen, um die Verbesserung mit realen Zahlen zu validieren.

2. April 2026
Wenn TSDS auf ILM trifft: Gestaltung von Zeitreihendatenströmen, die verspätete Daten nicht ablehnen
Interaktion zwischen den Zeitgrenzen von TSDS und den ILM-Phasen und Erstellung von Richtlinien, die verspätet eintreffende Metriken tolerieren.

1. April 2026
LINQ to Elasticsearch ES|QL: C# schreiben, Elasticsearch abfragen
Erkundung des neuen LINQ to Elasticsearch ES|QL-Providers im Elasticsearch .NET-Client, mit dem Sie C#-Code schreiben können, der automatisch in ES|QL-Abfragen übersetzt wird.