Elasticsearch verwendet den Hierarchical Navigable Small World (HNSW)-Algorithmus, um eine Vektorsuche in einem Proximity-Graphen durchzuführen. HNSW ist bekannt dafür, einen guten Kompromiss zwischen der Qualität der k-Nearest-Neighbor (KNN) Ergebnisse und den damit verbundenen Kosten zu bieten.
In HNSW erfolgt die Suche durch das iterative Erweitern von Kandidatenknoten im Graphen, wobei eine begrenzte Menge der bisher entdeckten nächsten Nachbarn gepflegt wird. Jede Erweiterung hat Kosten zur Folge (Vektorabläufe, zufällige Suchaktionen zur Festplatte und mehr), wobei der marginale Vorteil dieser Kosten tendenziell abnimmt, je weiter die Suche voranschreitet.
Eine Möglichkeit, die Durchquerung von HNSW-Graphen zu optimieren, besteht darin, die Suche zu beenden, wenn die marginale Wahrscheinlichkeit, neue echte Nachbarn zu finden, nicht steigt. Aus diesem Grund haben wir in Elasticsearch 9.2 einen neuen Mechanismus zur vorzeitigen Beendigung eingeführt. Das stoppt den Suchvorgang, wenn der Besuch von Graphknoten nicht genug neue nächste Nachbarn für eine feste Anzahl hintereinander liefert.
In diesem Artikel erfahren Sie, wie wir den erwähnten Mechanismus zur vorzeitigen Beendigung in HNSW verbessert haben, damit er sich für verschiedene Datensätze und Datenverteilungen besser eignet.
Vorzeitige Beendigung in HNSW
In HNSW erfolgt die Suche durch das iterative Erweitern von Kandidatenknoten im Proximity-Graphen, wobei eine begrenzte Menge der bisher entdeckten nächsten Nachbarn gepflegt wird, bis entweder der gesamte Graph besucht wurde oder ein frühes Abbruchkriterium erfüllt ist.
Die vorzeitige Beendigung ist daher nicht unbedingt immer eine Optimierung, sondern Teil des Suchalgorithmus selbst. Der Moment, in dem wir beschließen aufzuhören, bestimmt das Gleichgewicht zwischen Effizienz und Abruf. In Elasticsearch gibt es bereits eine Reihe von Möglichkeiten, um Abfragen auf HNSW vorzeitig zu beenden:
- Eine festgelegte maximale Anzahl von Knoten wird besucht.
- Ein festgelegtes Zeitlimit ist erreicht.
Diese Regeln sind zwar einfach und vorhersehbar, verhalten sich aber weitgehend unabhängig von dem, was die Suche tatsächlich bewirkt. Außerdem werden sie hauptsächlich verwendet, um sicherzustellen, dass die Abfrage für den Endnutzer in angemessener Zeit abgeschlossen wird.
In einem früheren Blogbeitrag haben wir das Konzept der Redundanz im HNSW vorgestellt. Kurz gesagt, redundante Berechnungen treten auf, wenn HNSW weiterhin neue Kandidatenknoten auswertet, ohne dabei weitere nächste Nachbarn zu finden.
Geduld: Fortschritt statt Anstrengung messen
Der Begriff der Geduld stellt die frühe Beendigung auf Fortschritt statt Anstrengung um.
Anstatt zu fragen:
„Wie viele Schritte haben wir unternommen?“
Die neue Frage lautet:
„Wie viel Rechenleistung sind wir bereit zu verschwenden, bis wir die Hoffnung verlieren?“
Während der HNSW-Suche führt eine frühe Exploration in der Regel zu Spitzenverbesserungen der Gruppe der Top-k-Kandidaten. Während der ersten Schritte der HNSW-Graph-Exploration wird die Menge der Nachbarn kontinuierlich aktualisiert, da der Algorithmus immer nähere Nachbarn zum Abfragevektor entdeckt. Mit der Zeit werden diese Verbesserungen immer seltener, da die Suche konvergiert. Die auf Geduld basierende Beendigung überwacht dieses Muster und beendet die Suche, sobald die Verbesserungen für längere Zeit weniger werden.
In der Praxis berechnen wir beim Besuchen des HNSW-Graphen auch das Sättigungsverhältnis der Warteschlange, während wir Kandidatenknoten durchgehen. So wird der Prozentsatz der nächstgelegenen Nachbarn gemessen, die beim Besuch des letzten Graphknoten unverändert blieben (oder der Kehrwert der Anzahl der während der letzten Iteration eingeführten neuen Nachbarn). Wenn ein solches Verhältnis für zu viele aufeinanderfolgende Iterationen zu groß wird, hören wir auf, den Graphen zu besuchen.
Konzeptionell betrachtet Geduld die HNSW-Suche als einen Prozess mit abnehmendem Ertrag. Wenn sich die Erträge einpendeln, bringt die weitere Exploration des Graphen wenig Nutzen.
Dieses Framing ist wirkungsvoll, weil es die Beendigung direkt an beobachtbare Ergebnisse bindet, anstatt an willkürlich festgelegte Grenzwerte.
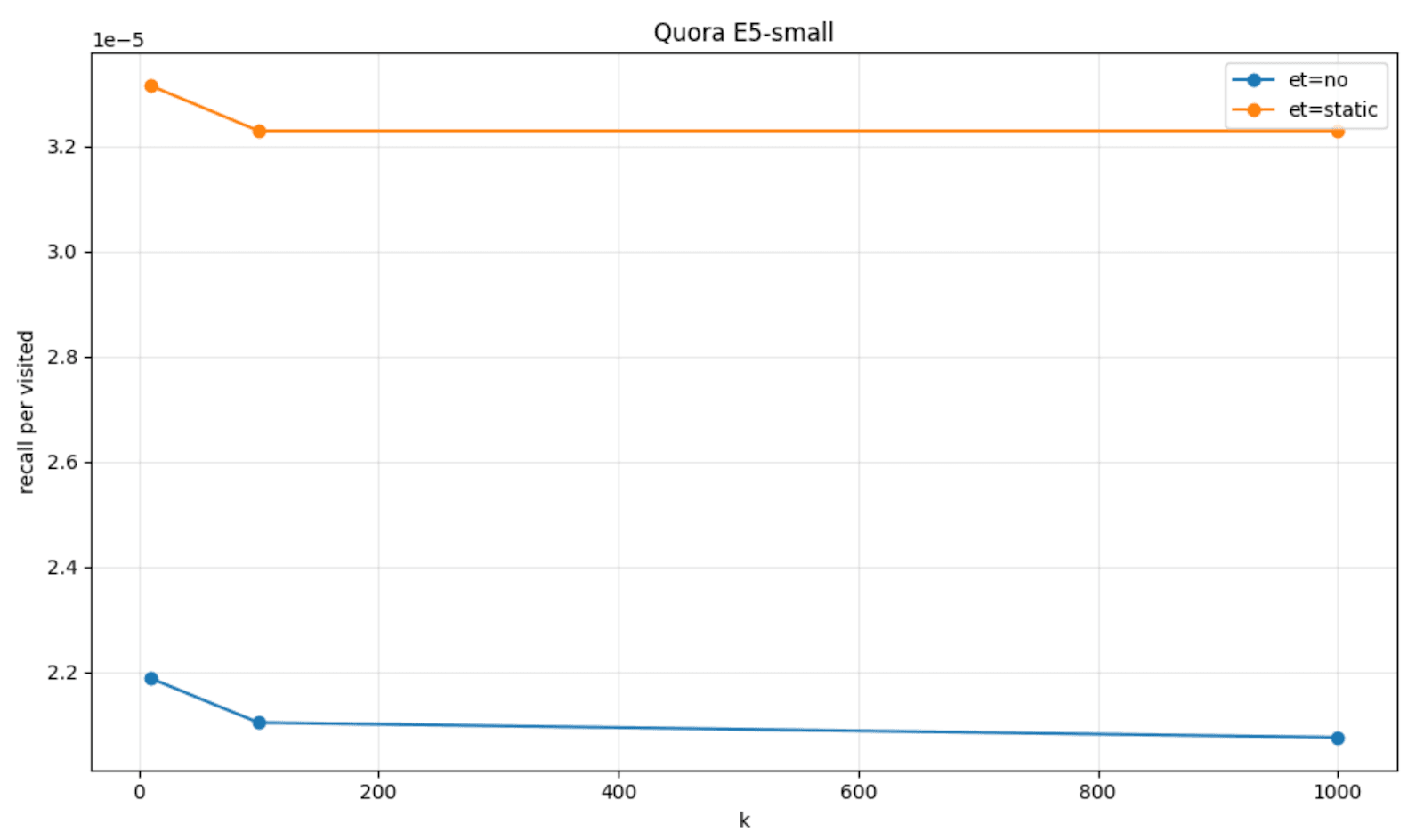
Der Vorteil dieser intelligenten Technik zur vorzeitigen Beendigung liegt darin, dass HNSW-Graph-Explorationen tendenziell eine geringere Anzahl von Graphknoten besuchen und dabei eine nahezu perfekte relative Abrufquote beibehalten.
Um dies zu visualisieren, können wir die Abrufquote pro besuchtem Knoten aufzeichnen, die wir mit der geduldsbasierten frühzeitigen Beendigung (gekennzeichnet als et=static) im Vergleich zum standardmäßigen HNSW-Verhalten (gekennzeichnet als et=no) bei einigen Datensätzen, FinancialQA und Quora, und Modellen, JinaV3 und E5-small, erhalten haben.

Statische Schwellenwerte und HNSW-Dynamik
In der Praxis wird dies in Elasticsearch mithilfe statischer Schwellenwerte umgesetzt. Ein Schwellenwert bezieht sich auf den Sättigungsschwellenwert, also das Sättigungsverhältnis, das wir für suboptimal halten. Der andere Schwellenwert bezieht sich auf die Anzahl aufeinanderfolgender Graphknoten, die wir zum Besuch zulassen, während wir dennoch eine suboptimale Warteschlangenauslastung erreichen, also der Geduldsschwellenwert.
Als wir diese Strategie zur vorzeitigen Beendigung in Elasticsearch 9.2 einführten, entschieden wir uns für konservative Standardeinstellungen, um den Abruf so weit wie möglich zu erhalten und gleichzeitig die Latenz und den Speicherverbrauch zu verbessern. Aus diesem Grund legten wir den Sättigungsschwellenwert auf 100 % und den Geduldsschwellenwert auf einen (begrenzten) Wert von 30 % des num_candidates in der KNN-Abfrage fest.
In vielen Szenarien erwiesen sich diese Einstellungen als gut geeignet, es kann aber sein, dass zwei Anfragen, die die gleiche Anzahl von Nachbarn anfordern, ein völlig unterschiedliches Konvergenzverhalten aufweisen. Einige Abfragen stoßen auf dichte lokale Nachbarschaften und sind schnell gesättigt, andere müssen lange, spärliche Pfade durchqueren, bevor sie wettbewerbsfähige Kandidaten finden. Letztgenanntes erwies sich als besonders schwierig effektiv zu handhaben.
Dabei fiel uns folgendes auf:
- Übermäßige Exploration bei einfachen Abfragen.
- Vorzeitige Beendigung bei schwierigen Abfragen.
Daher kamen wir zu dem Schluss, dass feste Schwellenwerte globale Annahmen über die Konvergenz kodieren, während wir HNSW besser an unterschiedliche Dynamiken anpassen könnten.
Die vorzeitige Beendigung von HNSW adaptiv gestalten
Ein adaptiver Ansatz zur vorzeitigen Beendigung geht dieses Problem aus einem anderen Blickwinkel an. Anstatt vordefinierte Stoppschwellenwerte durchzusetzen, leitet der Algorithmus aus den Suchdynamiken selbst ab, wann gestoppt werden soll.
Anstatt also das Verhältnis der Warteschlangensättigung zwischen zwei aufeinanderfolgenden Kandidaten zu vergleichen, beschlossen wir, sowohl eine direkt ausgeglichene (wie viele neue Nachbarn für eine Abfrage q beim letzten Besuch i eingeführt wurden) sowie den fortlaufenden Mittelwert und die Standardabweichung dieser Entdeckungsrate während des Graphbesuchs (unter Verwendung von Welfords Algorithmus) einzuführen. Diese Statistiken zur Entdeckungsrate werden pro Abfrage berechnet, sodass diese Informationen genutzt werden können, um für jede Abfrage unterschiedliche Geduldsgrade festzulegen.
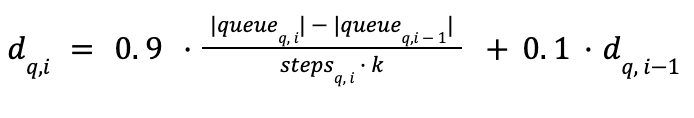
Die zuvor statischen Schwellenwerte werden an die Statistik der Entdeckungsrate angepasst: Die Sättigungsschwelle wird zum gleitenden Mittelwert und mit der Standardabweichung addiert, während wir die Geduld anpassen und umgekehrt mit der Standardabweichung skalieren.
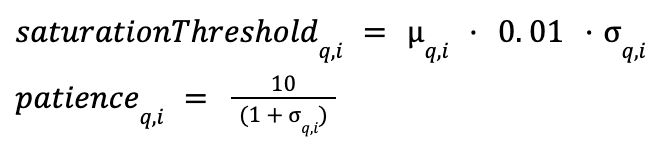
Die Regeln für die vorzeitige Beendigung bleiben gleich: Die Sättigung tritt ein, wenn die sofortige Entdeckungsrate niedriger ist als der adaptive Sättigungsgrenzwert. Der Graph-Besuch stoppt, wenn die Sättigung für eine Anzahl aufeinanderfolgender Kandidatenbesuche anhält, die größer ist als die adaptive Geduld.
So erhalten wir ein Verhalten, das nicht vom num_candidates-Parameter in der KNN-Abfrage abhängt (der immer als Standard gesetzt oder belassen werden kann, unabhängig von der vorzeitigen Beendigung) und sich dynamisch besser an jede Abfrage und Vektorverteilung anpasst.
Die Abrufquote pro besuchtem Knoten auf FinancialQA und Quora mit der adaptiven Strategie (gekennzeichnet als et=adaptive) ist höher als bei der statischen Strategie (et=static) und dem Standardverhalten von HNSW (et=no).


Die adaptive vorzeitige Beendigung ist in Elasticsearch 9.3 standardmäßig für HNSW-dichte Vektorfelder aktiviert (und kann schließlich über die gleiche Index-Level-Einstellung deaktiviert werden).
Zugehörige Inhalte

23. April 2026
Wie wir Elasticsearch simdvec entwickelten, um die Vektorsuche zu einer der schnellsten weltweit zu machen
Wie wir Elasticsearch simdvec entwickelten, die von Hand optimierte SIMD-Kernel-Bibliothek hinter jeder Vektorsuchanfrage in Elasticsearch.

4. Mai 2026
So messen und verbessern Sie den Elasticsearch-Suchabruf: von 0,43 auf 0,75 mit Hybridsuche
Erfahren Sie, wie Sie den Suchabruf in Elasticsearch messen und verbessern können, indem Sie die lexikalische BM25-Suche mit Jina AI-Vektoreinbettungen kombinieren und dabei die rank_eval-API nutzen, um die Verbesserung mit realen Zahlen zu validieren.

2. April 2026
Wenn TSDS auf ILM trifft: Gestaltung von Zeitreihendatenströmen, die verspätete Daten nicht ablehnen
Interaktion zwischen den Zeitgrenzen von TSDS und den ILM-Phasen und Erstellung von Richtlinien, die verspätet eintreffende Metriken tolerieren.

1. April 2026
LINQ to Elasticsearch ES|QL: C# schreiben, Elasticsearch abfragen
Erkundung des neuen LINQ to Elasticsearch ES|QL-Providers im Elasticsearch .NET-Client, mit dem Sie C#-Code schreiben können, der automatisch in ES|QL-Abfragen übersetzt wird.

26. März 2026
Ankündigung von Leseberechtigungen für Kibana-Dashboards
Einführung von schreibgeschützten Dashboards in Kibana, die den Erstellern von Dashboards granulare Freigabekontrollen bieten, um die Ergebnisse korrekt zu halten und vor unerwünschten Änderungen zu schützen.