Elasticsearchは、Hierarchical Navigable Small World(HNSW)アルゴリズムを使用して、近接グラフ上でベクトル検索を実行します。HNSWは、k近傍法(KNN) の結果の品質と関連コストの間で適切なトレードオフを提供することが知られています。
HNSWでは、グラフ内の候補ノードを反復的に拡張し、これまでに発見された最も近い近傍の制限されたセットを維持することで検索が進行します。各拡張にはコスト(ベクトル演算、ディスクへのランダムシークなど)がかかり、そのコストに対する限界効用は検索が進むにつれて減少する傾向があります。
HNSWグラフのトラバーサルを最適化する1つの方法は、新しい真の近傍を見つける周辺尤度が増加しない場合に検索を停止することです。このため、Elasticsearch 9.2では、新しい早期終了メカニズムを導入しました。これは、グラフノードを訪問しても一定回数連続して十分な数の新しい最近傍が提供されない場合に、検索プロセスを停止するものです。
この記事では、HNSWの前述の早期終了メカニズムを改良して、さまざまなデータセットやデータ分布に適したものにする方法について説明します。
HNSWでの早期終了
HNSW では、近接グラフ内の候補ノードを反復的に拡張し、これまでに発見された最も近い近傍の制限されたセットを維持して、グラフ全体を訪問するか、早期終了基準を満たすまで、検索が続行されます。
したがって、早期終了は必ずしも最適化ではなく、検索アルゴリズム自体の一部です。停止を決定する瞬間が、効率性と再現率のバランスを決定します。Elasticsearchでは、HNSWのクエリを早期終了させる方法がすでにいくつか存在します。
- 固定された最大数のノードが訪問されます。
- 一定のタイムアウトに達した場合。
これらのルールは単純かつ予測可能ですが、検索が実際に何をしているかにはほとんど関係がありません。また、これらは主に、クエリがエンドユーザーにとって妥当な時間内に完了することを確認するために使用されます。
前回のブログ投稿ではHNSWにおける冗長性の概念を紹介しました。つまり、HNSWが新しい候補ノードを評価し続けても、さらに最も近い近傍が見つからない場合、冗長な計算が発生します。
忍耐度:努力ではなく進歩を測る
忍耐度という概念は、努力ではなく進歩を中心に早期終了を再構築します。
次のように尋ねる代わりに
「何ステップ進んだ?」
新たに次のように問いかけます。
「希望を失うまでに受け入れられる無駄な計算はどれだけかな?」
HNSW検索では、通常、初期の探索によっ上位k候補セットの最高の改善がもたらされます。HNSWグラフ探索の最初のステップでは、アルゴリズムがクエリベクトルにますます近い近傍を検出し続けるため、近傍のセットは継続的に更新されます。時間が経ち、検索が収束するにつれて、これらの改善はまれになります。忍耐度ベースの終了はこのパターンを監視し、改善が一定期間停止した時点で検索を終了します。
実際には、HNSWグラフを訪問する際、候補ノードをホップしながらキューの飽和比も計算します。これは、最新のグラフノードを訪問中に変更されなかった最も近い近傍の割合(または最後の反復中に導入された新しい近傍の数の逆数)を測定します。このような比率が連続した反復処理で大きくなりすぎると、グラフの訪問を停止します。
概念的には、忍耐度はHNSWの検索を収穫逓減プロセスとして扱います。リターンが平坦になると、グラフの調査を継続してもほとんど利益は得られません。
この枠組みは、終了を恣意的な固定された制限ではなく、観察可能な結果に直接結び付けるため、強力です。
このスマートな早期終了手法を使用する利点は、HNSWグラフ探索では、ほぼ完璧な相対再現率を維持しながら、より少数のグラフノードを訪問する傾向があることです。
これを視覚化するために、FinancialQAとQuoraという2つのデータセットと、JinaV3とE5-smallというモデルで、忍耐度に基づく早期終了( et=staticとラベル付け)で取得した訪問ノードあたりの再現量を、デフォルトのHNSW動作( et=noとラベル付け)と比較してプロットすることができます。

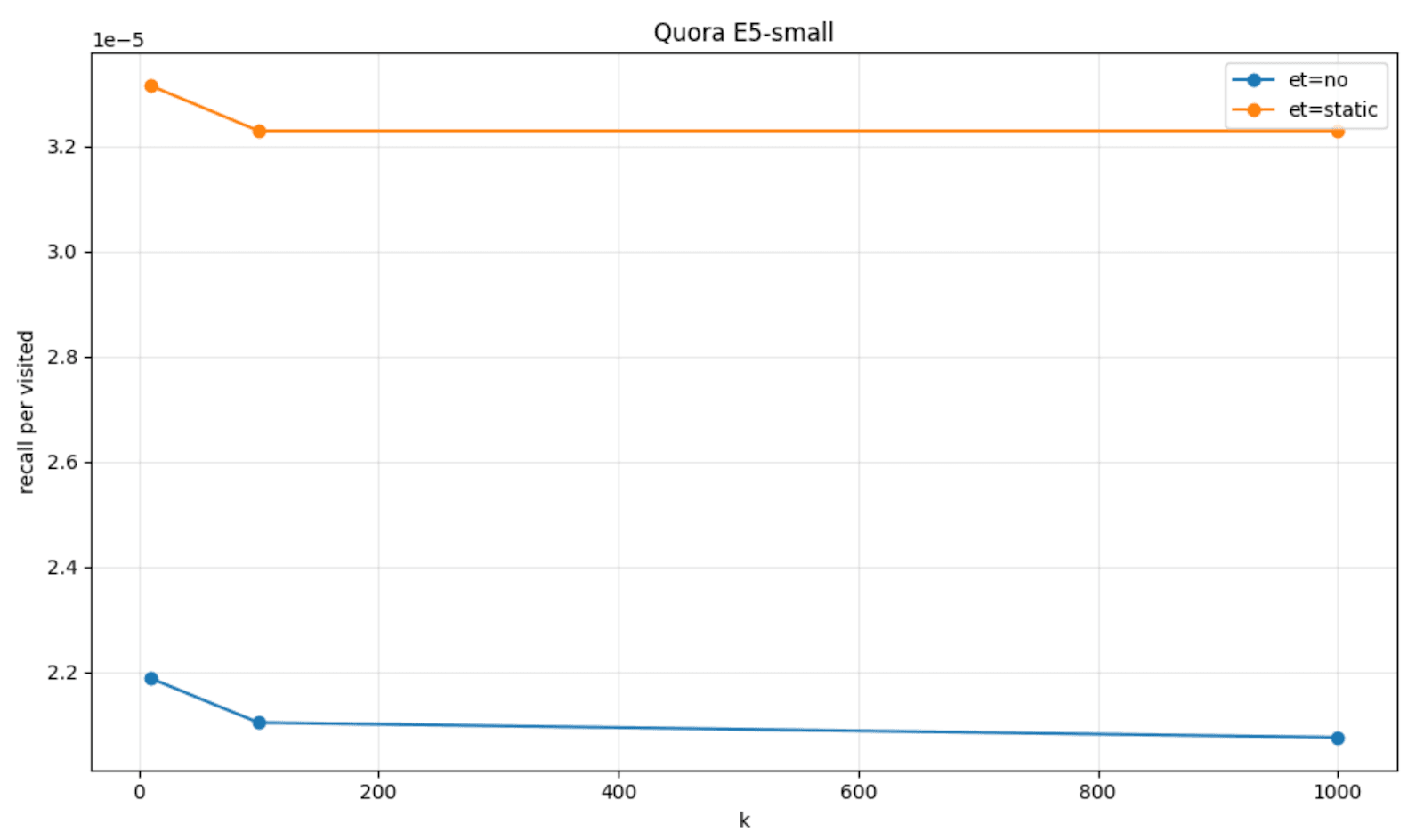
静的しきい値とHNSWのダイナミクス
実際には、Elasticsearchでは静的しきい値を使用してこれが実装されます。1つのしきい値は、飽和しきい値、つまり、最適ではないと判断される飽和度の比率を指します。もう1つのしきい値は、最適ではないキュー飽和を維持しながら連続して訪問できるグラフノードの数、つまり忍耐しきい値を指します。
Elasticsearch 9.2でこの早期終了戦略を導入したとき、レイテンシーとメモリ消費の面でメリットを得ながら再現率を可能な限り高められるように、保守的なデフォルトを選択することにしました。このため、KNNクエリでは飽和しきい値を100%に、忍耐しきい値を num_candidates の(有界の)30%に設定しています。
多くのシナリオでは、これらの設定はうまく機能しますが、同じ数の近傍を要求する2つのクエリでは、収束動作が根本的に異なる可能性があります。あるクエリは密集した局所的な近傍に遭遇し、すぐに飽和します。他のクエリは競争力のある候補を見つけるまでに、長くまばらな経路を通過しなければなりません。後者は、効果的に処理するのが最も困難であることが判明しました。
その結果、次のようなことに気付くことがありました。
- 簡単なクエリに対する過度の探索。
- 難しいクエリに対する時期尚早の終了。
したがって、固定されたしきい値は収束に関する全体的な仮定をエンコードしますが、HNSWをさまざまなダイナミクスに適応させることができると考えました。
HNSWの早期終了を適応的に
適応的早期終了は、この問題に異なる角度からアプローチします。事前に定義された停止しきい値を強制する代わりに、アルゴリズムが検索のダイナミクス自体からいつ停止するかを推測します。
したがって、2つの連続した候補間のキュー飽和比を比較する代わりに、即時平滑化発見率 (クエリqの最後の訪問iで導入された新しい隣接ノードの数)と、グラフ訪問中のそのような発見率の移動平均と標準偏差を導入することにしました(ウェルフォードのアルゴリズムを使用)。これらの発見率に関する統計はクエリごとに計算されるため、この情報をもとに各クエリの忍耐度を判断できます。
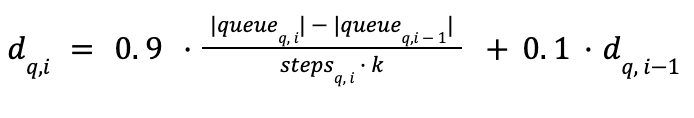
以前は静的であったしきい値は、発見率の統計に対して適応的になります。飽和しきい値はローリング平均と標準偏差の合計になり、一方で忍耐力は標準偏差に反比例して適応およびスケーリングされます。
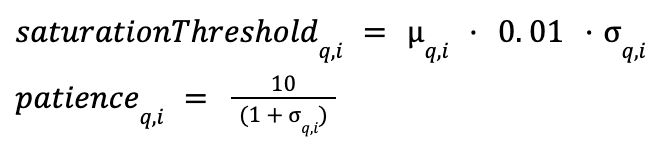
早期終了ルールは変わらず、飽和は即時発見率が適応飽和しきい値より低い場合に発生します。適応的忍耐度よりも大きい連続候補訪問回数にわたって飽和が継続する場合、グラフ訪問は停止します。
こうすることで、KNNクエリの num_candidates パラメーターに依存しない動作(早期終了に関係なく、常に設定されるか、デフォルトのままになる場合がある)が得られ、各クエリとベクトル分布に動的に適応しやすくなります。
適応型戦略( et=adaptiveとラベル付け)を使用したFinancialQAおよびQuoraでの訪問ノードあたりの再現率は、静的戦略( et=static )およびデフォルトのHNSW動作( et=no )と比較した場合、高くなっています。


適応的早期終了はElasticsearch 9.3ではHNSWの高密度ベクトルフィールドに対してデフォルトでオンになっています(最終的には同じインデックスレベルの設定でオフにすることができます)。
関連記事

2026年4月23日
ベクトル検索を世界最速のものにするためにElasticsearch simdvecを構築した方法
Elasticsearchのすべてのベクトル検索クエリの基盤となる、手作業で調整されたSIMDカーネルライブラリElasticsearch simdvecの構築方法。

2026年5月4日
Elasticsearchの検索再現率を測定・改善する方法:ハイブリッド検索で0.43から0.75へ
Elasticsearchにおける検索再現率を測定および改善する方法を学びましょう。BM25の語彙検索とJina AIのベクトル埋め込みを組み合わせ、rank_eval APIを使用して実際の数値で改善効果を検証します。

2026年4月10日
Elasticsearch + Jina埋め込みによる教師なし文書クラスタリング
ElasticsearchとJina埋め込みを使用した教師なし文書クラスタリングへの実用的で再現可能なアプローチ。

2026年4月2日
TSDSとILMが出会うとき:遅延データを拒否しない時系列データストリームの設計
TSDSの時間制限はILMフェーズとどのように相互作用するのか、そして遅れて到着するメトリクスを許容するポリシーを設計する方法。

2026年4月1日
LINQ to Elasticsearch ES|QL:C#を記述してElasticsearchをクエリ
Elasticsearch .NETクライアントに新しく追加されたLINQ to Elasticsearch ES|QLプロバイダをご紹介します。C#コードを自動的にES|QLクエリに変換できます。