Elasticsearch utiliza el algoritmo Hierarchical Navigable Small World (HNSW) para realizar búsquedas de vectores en un grafo de proximidad. Se sabe que HNSW ofrece un buen equilibrio entre la calidad de los resultados del método k vecino más cercano (KNN) y el costo asociado.
En HNSW, la búsqueda avanza expandiendo iterativamente los nodos candidatos en el grafo, lo que mantiene un conjunto acotado de vecinos más cercanos descubiertos hasta ahora. Cada expansión tiene un costo (operaciones vectoriales, búsquedas aleatorias en el disco y más), y el beneficio marginal de ese costo tiende a disminuir a medida que avanza la búsqueda.
Una forma de optimizar el recorrido de grafos de HNSW es dejar de buscar cuando la probabilidad marginal de encontrar nuevos vecinos verdaderos no aumenta. Por esta razón, en Elasticsearch 9.2, introdujimos un nuevo mecanismo de terminación temprana. Esto detiene el proceso de búsqueda cuando visitar nodos del grafo no proporciona suficientes vecinos más cercanos nuevos, consecutivamente, para un número fijo de veces.
En este artículo, te orientamos sobre cómo mejoramos el mecanismo de terminación temprana mencionado en HNSW para hacerlo más adecuado para diferentes sets de datos y distribuciones de datos.
Terminación temprana en HNSW
En HNSW, la búsqueda avanza expandiendo iterativamente nodos candidatos en el grafo de proximidad, lo que mantiene un conjunto limitado de vecinos más cercanos descubiertos hasta el momento, hasta que haya visitado todo el grafo o cumpla con algunos criterios de terminación temprana.
Por lo tanto, la terminación temprana no siempre es necesariamente una optimización, sino que es parte del algoritmo de búsqueda en sí. El momento en que decidimos detenernos determina el equilibrio entre eficiencia y recuperación. En Elasticsearch, ya hay varias formas en que una consulta en HNSW puede terminar de forma temprana:
- Se visita una cantidad máxima fija de nodos.
- Se alcanza un tiempo de espera fijo.
Si bien son simples y previsibles, estas reglas son, en gran medida, independientes de lo que realmente está haciendo la búsqueda. También se emplean, principalmente, para garantizar que la búsqueda finalice en un tiempo razonable para el usuario final.
En una entrada anterior del blog, presentamos el concepto de redundancia en HNSW. En resumen, los cálculos redundantes ocurren cuando HNSW continúa evaluando nuevos nodos candidatos que no dan como resultado la búsqueda de más vecinos más cercanos.
Paciencia: medir el progreso en lugar del esfuerzo
La noción de paciencia replantea la terminación temprana en torno al progreso, en lugar del esfuerzo.
En lugar de preguntar:
“¿Cuántos pasos hemos dado?”
La nueva pregunta es:
“¿Qué cantidad de cómputo aceptamos desperdiciar hasta que perdemos la esperanza?”
Durante la búsqueda de HNSW, por lo general, la exploración temprana produce mejoras máximas en el conjunto de candidatos top-k. Durante los primeros pasos de la exploración de grafos de HNSW, el conjunto de vecinos se actualiza continuamente a medida que el algoritmo sigue descubriendo vecinos cada vez más cercanos al vector de búsqueda. Con el tiempo, estas mejoras se vuelven más raras a medida que la búsqueda converge. La terminación basada en la paciencia monitorea este patrón y finaliza la búsqueda una vez que las mejoras han cesado durante un período prolongado.
En la práctica, al visitar el grafo de HNSW, también calculamos la relación de saturación de la cola al saltar entre nodos candidatos. Esto mide el porcentaje de vecinos más cercanos que se dejaron sin cambios al visitar el nodo del grafo más reciente (o el inverso del número de nuevos vecinos introducidos durante la última iteración). Cuando esa proporción se vuelve demasiado grande para demasiadas iteraciones consecutivas, dejamos de visitar el grafo.
Conceptualmente, la paciencia trata la búsqueda de HNSW como un proceso de rendimientos decrecientes. Cuando los rendimientos se estabilizan, seguir analizando el grafo aporta pocos beneficios.
Esta estructura es poderosa porque vincula la terminación directamente a resultados observables, en lugar de a límites fijos arbitrarios.
El beneficio de usar esta técnica inteligente de terminación temprana es que las exploraciones del grafo de HNSW tienden a visitar un número menor de nodos del grafo, mientras mantienen una recuperación relativa casi perfecta.
Para visualizar esto, podemos graficar la cantidad de recuperación por nodo visitado que obtuvimos con la terminación temprana basada en la paciencia (etiquetada como et=static), en comparación con el comportamiento predeterminado de HNSW (etiquetado como et=no) en un par de sets de datos, FinancialQA y Quora, y modelos, JinaV3 y E5-small.

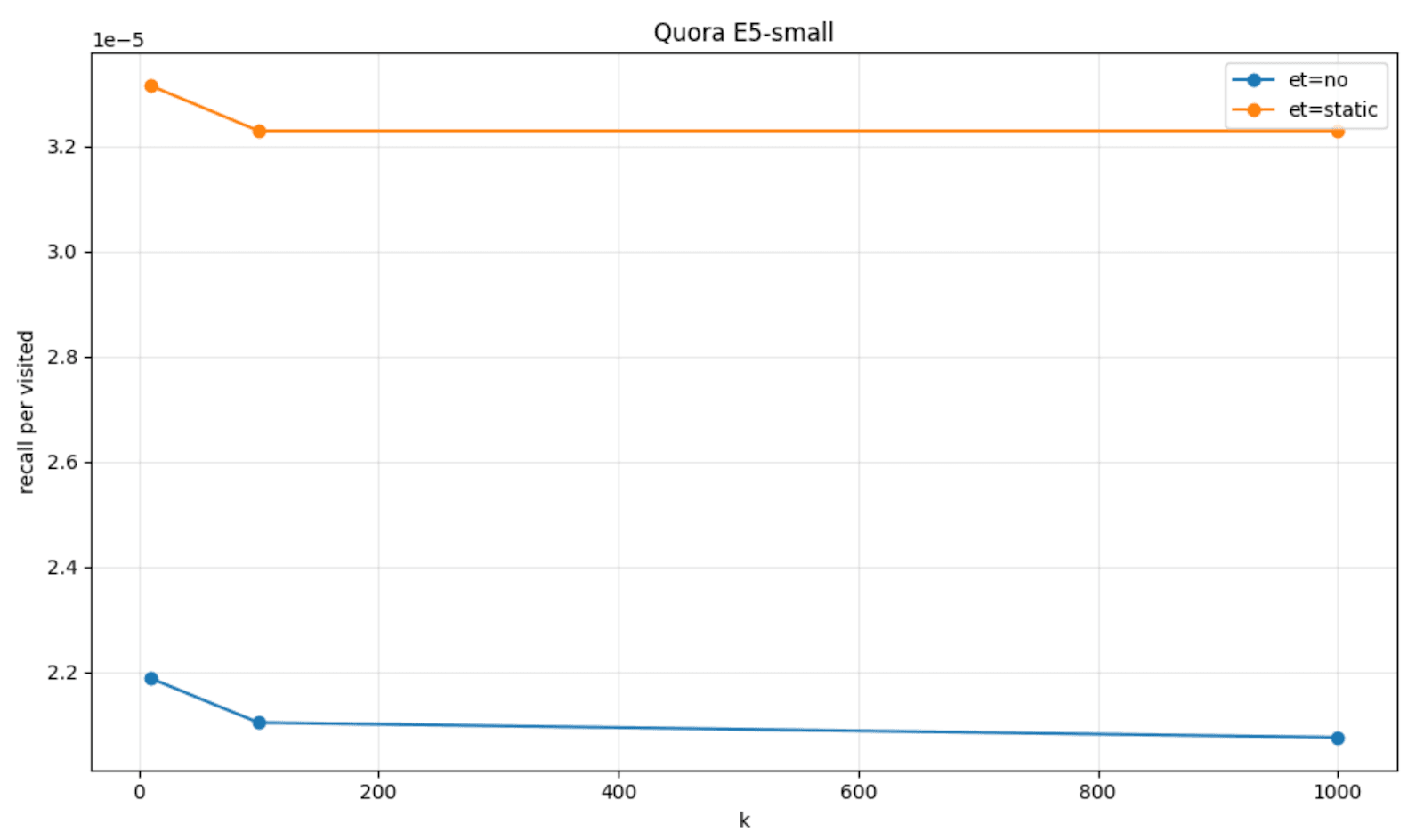
Umbrales estáticos y dinámicas de HNSW
En la práctica, en Elasticsearch esto se implementa utilizando umbrales estáticos. Un umbral se refiere al umbral de saturación, es decir, la proporción de saturación que consideramos subóptima. El otro umbral se refiere al número de nodos del grafo consecutivos que permitimos que se visiten sin dejar de tener una saturación de cola subóptima: es decir, el umbral de paciencia.
Cuando introdujimos esta estrategia de terminación temprana en Elasticsearch 9.2, decidimos optar por valores predeterminados conservadores, para permitir la recuperación tanto como fuera posible, mientras se mejora la latencia y el consumo de memoria. Por esta razón, establecemos el umbral de saturación al 100 % y el umbral de paciencia se establece como un 30 % (limitado) del num_candidates en la búsqueda de KNN.
En muchas situaciones, estas configuraciones resultaron funcionar bien; sin embargo, dos búsquedas que solicitan el mismo número de vecinos podrían tener comportamientos de convergencia radicalmente diferentes. Algunas búsquedas encuentran vecindarios locales densos y se saturan rápidamente; otras deben atravesar caminos largos y dispersos antes de encontrar candidatos competitivos. Estas últimas resultaron ser las más difíciles de manejar con eficacia.
Como resultado, a veces notamos lo siguiente:
- Sobreexploración para búsquedas sencillas.
- Terminación prematura para búsquedas difíciles.
Por lo tanto, consideramos que los valores de umbral fijos codifican suposiciones globales sobre la convergencia, mientras que podríamos hacer que HNSW se adapte mejor a diferentes dinámicas.
Hacer que la terminación temprana de HNSW sea adaptativa
La terminación temprana adaptativa aborda este problema desde otro ángulo. En lugar de imponer umbrales de parada predefinidos, el algoritmo infiere cuándo detenerse de la propia dinámica de búsqueda.
Entonces, en lugar de comparar la proporción de saturación de cola entre dos candidatos consecutivos, decidimos introducir una tasa de descubrimiento suavizada instantánea (cuántos vecinos nuevos se introdujeron para una búsqueda q en la última visita i) junto con el promedio móvil y la desviación estándar de tal tasa de descubrimiento durante la visita del grafo (usando el algoritmo de Welford). Estas estadísticas sobre la tasa de descubrimiento se calculan por búsqueda, de modo que esta información pueda utilizarse para decidir diferentes grados de paciencia para cada búsqueda.
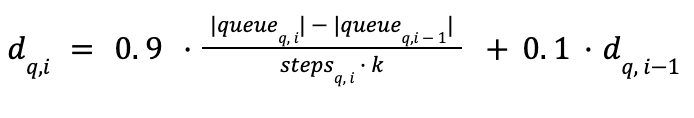
Los umbrales anteriormente estáticos se vuelven adaptativos a las estadísticas de tasa de descubrimiento: el umbral de saturación se convierte en el promedio móvil más la desviación estándar; mientras tanto, hacemos que la paciencia se adapte y escale inversamente con la desviación estándar.
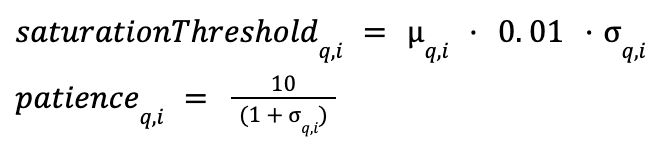
Las reglas de salida anticipada siguen siendo las mismas; la saturación se produce cuando la tasa de descubrimiento instantáneo es menor que el umbral de saturación adaptativa. La visita al grafo se detiene si la saturación persiste durante un número de visitas consecutivas de candidatos que es mayor que la paciencia adaptativa.
De este modo, obtenemos un comportamiento que no depende del parámetro num_candidates en la búsqueda de KNN (que puede estar siempre establecido o dejado como predeterminado, independientemente de si sale pronto) y que se adapta mejor dinámicamente a cada consulta y distribución vectorial.
La recuperación por nodo visitado en FinancialQA y Quora con la estrategia adaptativa (etiquetada como et=adaptive) reporta una mayor recuperación por nodo visitado, en comparación con la estrategia estática (et=static) y el comportamiento predeterminado de HNSW (et=no).


La terminación temprana adaptativa está activada de manera predeterminada en Elasticsearch 9.3 para los campos vectoriales densos de HNSW (y, eventualmente, se puede desactivar a través de la misma configuración de nivel de índice).
Contenido relacionado

23 de abril de 2026
Cómo creamos Elasticsearch simdvec para hacer una de las búsquedas vectoriales más rápidas del mundo
Cómo construimos Elasticsearch SIMDvec, la biblioteca del kernel SIMD ajustada a mano detrás de cada consulta de búsqueda vectorial en Elasticsearch.

4 de mayo de 2026
Cómo medir y mejorar la recuperación de búsqueda de Elasticsearch: de 0,43 a 0,75 con búsqueda híbrida
Aprende a medir y mejorar la recuperación de búsqueda en Elasticsearch combinando la búsqueda léxica BM25 con incrustaciones vectoriales de Jina AI, usando la API rank_eval para validar la mejora con cifras reales.

10 de abril de 2026
Agrupación no supervisada de documentos con Elasticsearch + incrustaciones de Jina
Un enfoque práctico y reproducible para la agrupación no supervisada de documentos con Elasticsearch y embeddings de Jina.

2 de abril de 2026
Cuando TSDS se une a ILM: diseñar flujos de datos temporales que no rechazan los datos tardíos
Cómo los límites de tiempo de TSDS interactúan con las fases de ILM; y cómo diseñar políticas que toleren métricas tardías.

1 de abril de 2026
LINQ a Elasticsearch ES|QL: escribir en C#, buscar en Elasticsearch
Explorar el nuevo proveedor de LINQ a Elasticsearch ES|QL en el cliente .NET de Elasticsearch, que te permite escribir código en C# que se traduce automáticamente en búsquedas ES|QL.