Elasticsearch는 근접 그래프상에서 벡터 검색을 수행하기 위해 계층적으로 탐색 가능한 작은 세계(HNSW) 알고리즘을 사용합니다. HNSW는 k-최근접 이웃(KNN) 결과의 품질과 그에 수반되는 비용 사이에서 훌륭한 절충안을 제공하는 것으로 알려져 있습니다.
HNSW에서 검색은 그래프 내의 후보 노드들을 반복적으로 확장하며, 현재까지 발견된 최근접 이웃의 제한된 집합을 유지하는 방식으로 진행됩니다. 각 확장 단계마다 비용(벡터 연산, 디스크 임의 탐색 등)이 발생하며, 검색이 진행될수록 그 비용 대비 얻게 되는 한계 이익은 점차 감소하는 경향이 있습니다.
HNSW 그래프 탐색을 최적화하는 한 가지 방법은, 새로운 진짜 이웃을 찾을 한계 확률이 더 이상 증가하지 않을 때 탐색을 중단하는 것입니다. 이러한 이유로, Elasticsearch 9.2에서는 새로운 조기 종료 메커니즘을 도입했습니다. 이 방식은 그래프 노드를 방문해도 새로운 최근접 이웃을 충분히 찾지 못하는 상태가 고정된 횟수만큼 연속으로 발생하면 검색 프로세스를 중단합니다.
이 글은 다양한 데이터 세트와 데이터 분포에 더 잘 대응할 수 있도록, HNSW의 조기 종료 메커니즘을 개선한 방법을 안내합니다.
HNSW의 조기 종료
HNSW에서 검색은 근접 그래프 내의 후보 노드들을 반복적으로 확장하며, 현재까지 발견된 근접 이웃의 제한된 집합을 유지하는 방식으로 진행됩니다. 이는 그래프 전체를 방문하거나 특정 조기 종료 기준을 충족할 때까지 계속됩니다.
따라서 조기 종료는 반드시 항상 최적화를 위한 선택 사항인 것만은 아닙니다. 검색 알고리즘 그 자체의 일부입니다. 탐색을 중단하기로 결정하는 그 순간이 효율성과 재현율 사이의 균형을 결정합니다. Elasticsearch에는 이미 HNSW 쿼리가 조기 종료될 수 있는 몇 가지 방법이 존재합니다.
- 방문하는 노드의 최대 개수는 정해져 있습니다.
- 정해진 제한 시간에 도달했습니다.
이러한 규칙들은 단순하고 예측 가능하지만, 검색이 실제로 어떻게 진행되고 있는지에 대해서는 대체로 무관심합니다. 또한, 이러한 규칙들은 주로 최종 사용자에게 적절한 시간 내에 쿼리가 완료되도록 하기 위한 용도로 사용됩니다.
이전 블로그 게시물에서 HNSW의 중복성이라는 개념을 소개한 바 있습니다. 요약하자면, HNSW가 새로운 최근접 이웃을 찾아내지 못하는 새로운 후보 노드들을 계속해서 평가할 때 중복 계산이 발생합니다.
인내심: 노력이 아닌 진척도를 측정하기
인내심이라는 개념은 조기 종료의 기준을 노력이 아닌 진전을 중심으로 재정의합니다.
다음과 같은 질문을 던지는 대신:
“우리가 몇 걸음을 걸었습니까?”
새로운 질문은 다음과 같습니다:
“더 나은 결과를 찾을 가망이 없다고 판단하기까지, 얼마만큼의 연산 낭비를 감수할 수 있을까요?"
HNSW 검색 과정에서, 초기 탐색은 일반적으로 top-k 후보 집단에 대해 가장 비약적인 개선을 만들어냅니다. HNSW 그래프 탐색의 첫 단계에서는, 알고리즘이 쿼리 벡터에 점점 더 가까운 이웃들을 계속해서 발견함에 따라 이웃 집합이 계속해서 업데이트됩니다. 시간이 흐름에 따라, 검색이 수렴하면서 이러한 개선은 점차 드물어집니다. 인내심 기반 종료는 이러한 패턴을 모니터링하며, 개선이 일정 기간 지속적으로 발생하지 않으면 검색을 종료합니다.
실제로 HNSW 그래프를 방문하는 동안, 후보 노드들을 거쳐 가며 큐 포화도를 함께 계산합니다. 이는 가장 최근의 그래프 노드를 방문하는 동안 변경되지 않고 그대로 남은 근접 이웃의 비율(또는 마지막 반복 과정에서 새로 추가된 이웃 수의 역수)을 측정합니다. 이러한 비율이 너무 많은 연속된 반복 과정 동안 과도하게 높아지면, 더 이상의 그래프 방문을 중단합니다
개념적으로 볼 때, 인내심은 HNSW 검색을 수익 체감의 과정으로 취급합니다. 수익이 정체되는 시점에 도달하면, 그래프를 계속해서 탐색하는 것은 실질적인 이익을 거의 주지 못합니다.
이러한 프레이밍은 강력합니다. 종료 시점을 임의로 정해진 고정된 한계치가 아니라, 관찰 가능한 결과에 직접 연결하기 때문입니다.
이러한 스마트 조기 종료 기술을 사용하면, 거의 완벽한 상대적 재현율을 유지하면서도 HNSW 그래프 탐색 과정에서 방문하는 노드 수를 줄일 수 있다는 장점이 있습니다.
이를 시각화하기 위해, 몇 가지 데이터 세트인 FinancialQA, Quora과 모델인 JinaV3, E5-small 조합을 대상으로 인내심 기반 조기 종료(et=static와 HNSW 기본 작동 방식(et=no)을 비교하여, 방문한 노드 수에 따른 재현율의 변화량을 그래프로 그려볼 수 있습니다.

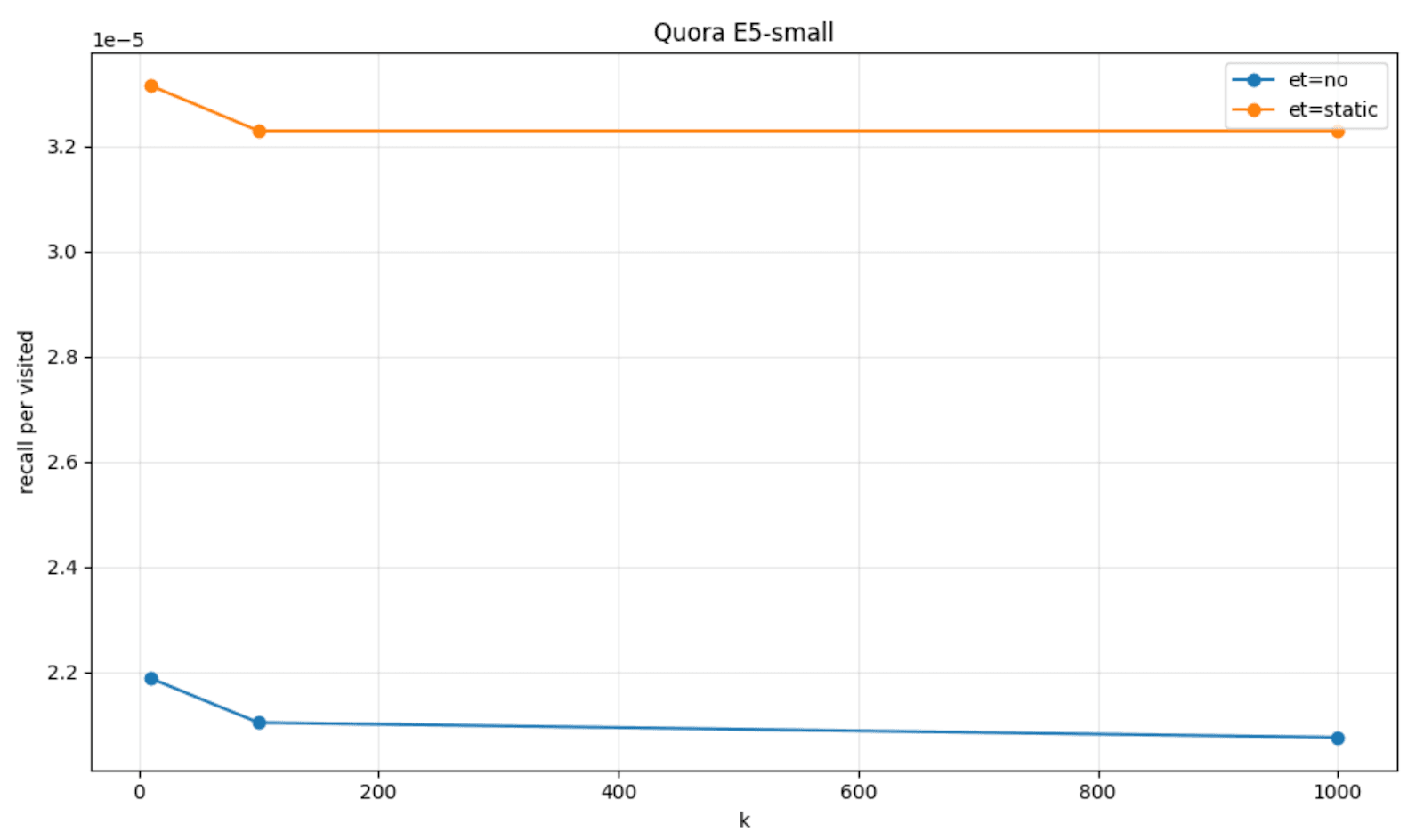
정적 임계값 및 HNSW 동역학
실제로, Elasticsearch는 이를 정적 임계값을 사용하여 구현했습니다. 하나의 임계값은 포화 임계값입니다. 이는 우리가 차선이라고 간주하는 포화 비율을 의미합니다. 또 다른 임계값은 인내심 임계값입니다. 이는 큐 포화도가 여전히 낮은 상태임에도, 방문을 계속 허용할 연속적인 그래프 노드 방문 횟수를 의미합니다.
Elasticsearch 9.2에 이 조기 종료 전략을 도입할 당시, 지연 시간과 메모리 소모 측면에서 이득을 보면서도 재현율은 최대한 유지할 수 있도록 보수적인 기본값을 선택하기로 결정했습니다. 이러한 이유로, 포화 임계값을 100%로 설정하고, 인내심 임계값은 KNN 쿼리에서 num_candidates의 30% 수준(상한선 제한 있음)으로 설정했습니다.
많은 시나리오에서 이러한 설정들이 잘 작동하기도 했지만, 동일한 수의 이웃을 요청하는 두 쿼리라도 그 수렴 동작은 근본적으로 다를 수 있습니다. 어떤 쿼리는 밀집된 지역 이웃을 만나 빠르게 포화 상태에 도달하는 반면, 다른 쿼리는 경쟁력 있는 후보군을 찾기까지 길고 희소한 경로를 통과해야만 합니다. 후자가 효과적으로 처리하기 가장 어려운 것으로 나타났습니다.
그 결과, 때때로 다음과 같은 현상들이 관찰되었습니다:
- 쉬운 쿼리에 대한 과도한 탐색.
- 까다로운 쿼리에 대한 조기 종료.
따라서 고정된 임계값이 수렴에 대한 일괄적인 가정을 전제로 하는 반면, HNSW가 다양한 동역학에 더 잘 적응하도록 만들 수 있다는 점을 깨달았습니다.
HNSW 조기 종료 적응형 구현
적응형 조기 종료는 이 문제에 대해 기존과는 다른 각도에서 접근합니다. 미리 정의된 중단 임계값을 강제하는 대신, 알고리즘은 검색 역학 자체로부터 언제 멈춰야 할지를 추론합니다.
따라서 연속된 두 후보 사이의 큐 포화율을 비교하는 대신, 그래프 방문 중의 (웰포드 알고리즘을 사용한) 이동 평균 및 표준 편차 와(과) 함께, 순간 평활 발견율 (마지막 방문 i에서 쿼리 q에 대해 도입된 새로운 이웃의 수)를 도입하기로 결정했습니다. 발견율에 관한 이러한 통계치들은 각 쿼리당 개별적으로 계산됩니다. 이 정보를 사용하여 각 쿼리의 특성에 맞춰 서로 다른 수준의 인내심을 적용할 수 있습니다.
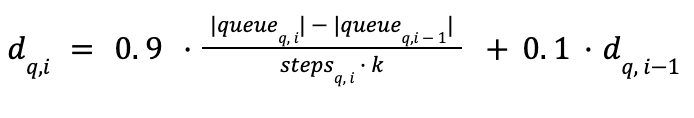
이전의 정적 임계값들은 이제 발견율 통계에 따라 적응형으로 변합니다. 포화 임계값은 이동 평균에 표준 편차를 더한 값이 되며, 인내심 수치는 표준 편차에 반비례하여 적응하고 확장되도록 만들었습니다.
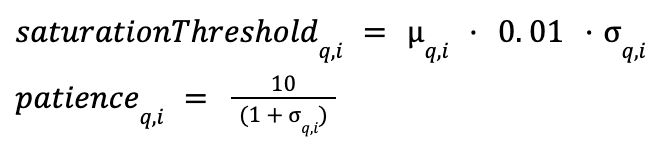
조기 종료 규칙은 기존과 동일하게 유지됩니다. 즉, 순간 발견율이 적응형 포화 임계값보다 낮아질 때 포화가 발생합니다. 포화 상태가 적응형 인내심보다 더 많은 횟수의 연속적인 후보 방문 동안 지속되면, 그래프 방문이 중단됩니다
이러한 방식을 통해, KNN 쿼리의 num_candidates 매개변수(조기 종료 여부와 상관없이 항상 설정되어 있거나 기본값으로 남겨지는 값)에 의존하지 않으면서도, 각 쿼리와 벡터 분포에 맞춰 동적으로 더 잘 적응하는 동작을 구현할 수 있습니다.
FinancialQA 및 Quora에서 적응형 전략(et=adaptive)의 방문 노드당 재현율은 정적 전략(et=static) 및 기본 HNSW 동작(et=no)과 비교했을 때 더 높은 수치를 나타냅니다.


적응형 조기 종료는 Elasticsearch 9.3부터 HNSW 밀집 벡터 필드에 기본으로 활성화되며, 동일한 인덱스 수준 설정을 통해 나중에 비활성화할 수도 있습니다.
관련 콘텐츠

2026년 4월 23일
세계에서 가장 빠른 벡터 검색을 위해 Elasticsearch simdvec을 구축한 방법
Elasticsearch의 모든 벡터 검색 쿼리 뒤에 있는 수동 조정 SIMD 커널 라이브러리인 Elasticsearch simdvec을 어떻게 구축했는지 알아보세요.

Elasticsearch 검색 리콜을 측정하고 개선하는 방법: 하이브리드 검색을 통해 0.43에서 0.75로 향상하기
BM25 어휘 검색과 Jina AI 벡터 임베딩을 결합하여 Elasticsearch에서 검색 회상률을 측정하고 개선하는 방법을 알아보고, rank_eval API를 사용해 실제 숫자로 개선 효과를 검증하세요.

Elasticsearch와 Jina 임베딩을 활용한 비지도형 문서 클러스터링
Elasticsearch와 Jina 임베딩을 활용한 비지도형 문서 클러스터링을 위한 실용적이고 재현 가능한 접근 방식.

TSDS와 ILM의 만남: 늦게 도착하는 데이터를 거부하지 않는 시계열 데이터 스트림 설계
TSDS 시간 제한이 ILM 단계와 상호 작용하는 방법과 늦게 도착하는 메트릭을 처리할 수 있는 정책 설계 방법

LINQ to Elasticsearch ES|QL: C# 작성, Elasticsearch 쿼리
Elasticsearch .NET 클라이언트의 새로운 LINQ to Elasticsearch ES|QL 제공자를 살펴보세요. 이 제공자를 사용하면 C# 코드를 작성하여 ES|QL 쿼리로 자동 변환할 수 있습니다.