Elasticsearch simdvec은 Elasticsearch의 모든 벡터 거리 계산의 기반이 되는 엔진입니다. Elasticsearch가 지원하는 모든 벡터 유형에 대해 수동 조정 AVX-512 및 NEON 커널을 제공합니다. 벌크 스코어링 아키텍처는 x86에서는 명시적 프리페칭을 통해, ARM에서는 인터리브 로딩을 통해 메모리 지연 시간을 숨기며 데이터가 CPU 캐시를 초과할 때 FAISS 및 jvector와 같은 라이브러리보다 최대 4배까지 성능이 향상됩니다. 이 글에서는 simdvec을 구축한 이유와 내부 구성 요소, 그리고 이 라이브러리가 어떻게 Elasticsearch 벡터 검색을 세계에서 가장 빠른 검색으로 만드는지 설명합니다.
Elasticsearch simdvec을 어떻게 구축했는지
Elasticsearch의 모든 벡터 검색 쿼리는 Hierarchical Navigable Small World(HNSW) 순회, 역파일(IVF) 스캔, 순위 재지정 단계 등 어떤 방식이든 동일한 문제, 즉 쿼리당 수백만 번씩 벡터 간의 거리를 계산하는 작업으로 귀결됩니다. Elasticsearch는 float32, int8, bfloat16, 바이너리, 그리고 Better Binary Quantization(BBQ) 등 다양한 데이터 유형과 양자화 전략을 지원합니다. 각 전략은 메모리, 처리량, 재현율 측면에서 서로 다른 장단점이 있습니다. 이 모든 것을 가능하게 하는 것은 바로 simdvec이라는 단일 엔진입니다.
하드웨어 성능을 최대한 활용하여 모든 거리 계산을 빠르게 수행하기 위해 simdvec을 개발했습니다. 이 글에서는 simdvec을 구축한 이유, 내부 구성 요소, 그리고 가장 큰 효과를 발휘하는 부분에 대해 설명합니다.
레이싱카처럼 구축
Formula 1 애호가들로서, 그리고 이중 한 명이 이전에 Ferrari Formula 1 팀에서 근무했던 경험을 바탕으로, 저희는 분명한 공통ㄴ점을 발견했습니다. Formula 1 자동차는 단 하나의 목적, 즉 최고의 랩 타임을 달성하는 것을 위해 설계됩니다. 엔진 출력, 공기역학, 섀시 설계는 오직 그 결과에 기여하는 한에서만 중요합니다. 벡터 데이터베이스도 마찬가지로, 인덱싱 처리량, 쿼리 지연 시간, 그리고 재현율이 성공을 좌우합니다.
최종 결과가 중요하지만, 최고 수준의 성능을 달성하려면 각 구성 요소가 최상의 성능을 발휘해야 합니다. 단순히 충분히 좋은 정도가 아니라, 해당 범주에서 최고여야 합니다. simdvec은 이러한 사고방식을 바탕으로 시스템의 핵심 요소인 엔진에 집중하여 개발되었습니다. 단일 명령어 다중 데이터(SIMD)에 최적화된 특수 목적 커널 라이브러리로, Java에서 Panama F외부 함수 인터페이스(FFI)를 통해 호출되는 수동 조정 네이티브 C++ 거리 함수를 제공합니다. 벌크 스코어링, 캐시 라인 프리페칭, 그리고 Elasticsearch에서 사용되는 모든 벡터 유형 및 레이아웃을 지원합니다.
모든 쿼리 뒤에 있는 엔진입니다.
왜 저희가 직접 구축했는지
2023년에 Apache Lucene의 Panama Vector API로 시작했습니다. float32 내적에는 잘 작동했지만, Elasticsearch의 요구 사항은 빠르게 충족할 수 있는 범위를 넘어섰습니다. Elasticsearch는 int8, int4, bfloat16, 단일 비트, 비대칭 BBQ 등 다양한 양자화 벡터 유형을 지원합니다. 각 유형은 서로 다른 SIMD 전략, 패킹 레이아웃, 누산기 요구 사항을 가지고 있습니다. 유형 지원 외에도 Elasticsearch의 스코어링 경로는 단일 쌍 처리량 이상의 것을 요구합니다. HNSW는 한 번의 단계로 여러 그래프 이웃을 스코어링해야 하고, IVF는 프리페칭을 통해 수천 개의 후보를 벌크 스코어링해야 하며, 디스크 기반 스코어링은 복사 없이 mmap된 메모리에서 직접 작동해야 합니다. 사용 가능한 기존 라이브러리를 살펴보았지만, 모든 요구 사항을 충족하는 것은 없었습니다.
그래서 simdvec을 구축했습니다. simdvec은 FFI를 통해 Java에서 호출되는 수동 조정 네이티브 C++ 커널로, 벌크 스코어링, 프리페칭, 그리고 Elasticsearch에서 사용하는 모든 벡터 유형을 지원합니다. 라이브러리를 직접 소유함으로써 전체 스택을 제어할 수 있습니다. BBQ와 같은 새로운 양자화 유형을 추가하면 시스템 전체에 걸쳐 최적화된 SIMD 커널이 연결됩니다. 상위 라이브러리의 지원을 기다리지 않으며, 어떤 유형에 대해서도 성능이 저하되지 않습니다. Elasticsearch의 모든 벡터 쿼리(HNSW, IVF, 순위 재지정 또는 하이브리드)는 실제로 사용하는 연산 및 유형을 중심으로 구축된 이 엔진에서 실행됩니다.
simdvec은 x86 및 ARM용으로 별도의 네이티브 라이브러리를 제공하며, 각 라이브러리는 시작 시 여러 명령어 세트 아키텍처(ISA) 계층을 선택할 수 있습니다. FFI를 통한 Java의 호출 오버헤드는 한 자릿수 나노초로 매우 낮습니다.
환경
SIMD 최적화 벡터 거리 커널을 개발하는 곳은 저희뿐만이 아닙니다. 생태계는 매우 풍부하며, 저희는 simdvec의 성능을 이해하고 싶었습니다. 프로젝트 순위를 매기려는 것이 아니라 컨텍스트를 제공하고 Elasticsearch 엔진의 위치를 설명하기 위해서입니다. 각기 다른 접근 방식을 대표하는 세 가지 프로젝트를 참조 대상으로 선정했습니다.
- jvector: x86에서 네이티브 C 가속 옵션과 함께 벡터화된 거리 계산을 위해 Panama Vector API를 사용하는 Java 근사 최근접 이웃(ANN) 라이브러리입니다.
- FAISS: 널리 배포된 오픈 소스 벡터 검색 프레임워크로, 수동 조정 AVX2/AVX-512 커널을 사용합니다.
- NumKong (이전 SimSIMD): 거리 함수, 행렬 연산 및 지리 공간 계산을 아우르는 2,000개 이상의 수동 조정 SIMD 커널로 구성된 종합적인 제품군입니다.
각 프로젝트는 서로 다른 목적을 가지고 있으며 각기 다른 절충점을 고려합니다. Elasticsearch에서 필요한 특정 연산에 대한 simdvec의 성능을 이해하는 데 도움이 되도록 각 프로젝트의 참조 번호를 제공합니다.
측정 방법
simdvec 및 jvector 벤치마크는 표준 JVM 마이크로벤치마크 도구인 JMH를 사용하여 Java로 작성되었으며, FFI 오버헤드가 포함되어 있습니다. NumKong 벤치마크와 FAISS 벤치마크의 경우, 표준 C++ 마이크로벤치마크 프레임워크인 Google Benchmark를 사용하여 소규모 C/C++ 하네스를 작성했습니다. 두 프레임워크 모두 웜업 및 반복 보정을 거쳐 연산당 나노초 단위의 시간을 보고합니다. 하드웨어 성능 카운터를 통해 모든 라이브러리가 두 플랫폼 모두에서 SIMD를 사용하고 있음을 확인했습니다. 모든 벤치마크 코드는 링크된 GitHub 리포지토리(그리고 simdvec의 경우 elasticsearch 리포지토리)에서 공개적으로 사용할 수 있습니다.

소프트웨어: JDK 25.0.2, JMH 1.37, GCC 14, Google Benchmark(최신).
한 번에 하나의 벡터
벡터 검색에서 가장 기본적인 연산은 두 벡터 사이의 거리를 계산하는 것입니다. 모든 HNSW 이웃 평가, 모든 IVF 후보 점수, 모든 순위 재지정 비교는 이 내부 루프로 축소됩니다.
두 플랫폼 모두에서 1024 차원의 단일 쌍 처리량을 측정했으며, 기준 유형이자 생태계 경쟁이 가장 치열한 float32부터 시작했습니다. simdvec을 FAISS 및 jvector와 비교했습니다. NumKong은 float32에 float64 누산기를 사용하기 때문에 (플랫폼에 따라) 처리량보다 수치 정밀도를 우선시하여 3.2배에서 5.3배 느리므로 비교 대상에서 제외했습니다. 공정한 비교를 위해 NumKong은 simdvec과 동일한 누산기 전략을 사용하는 int8에서 벤치마킹했습니다.
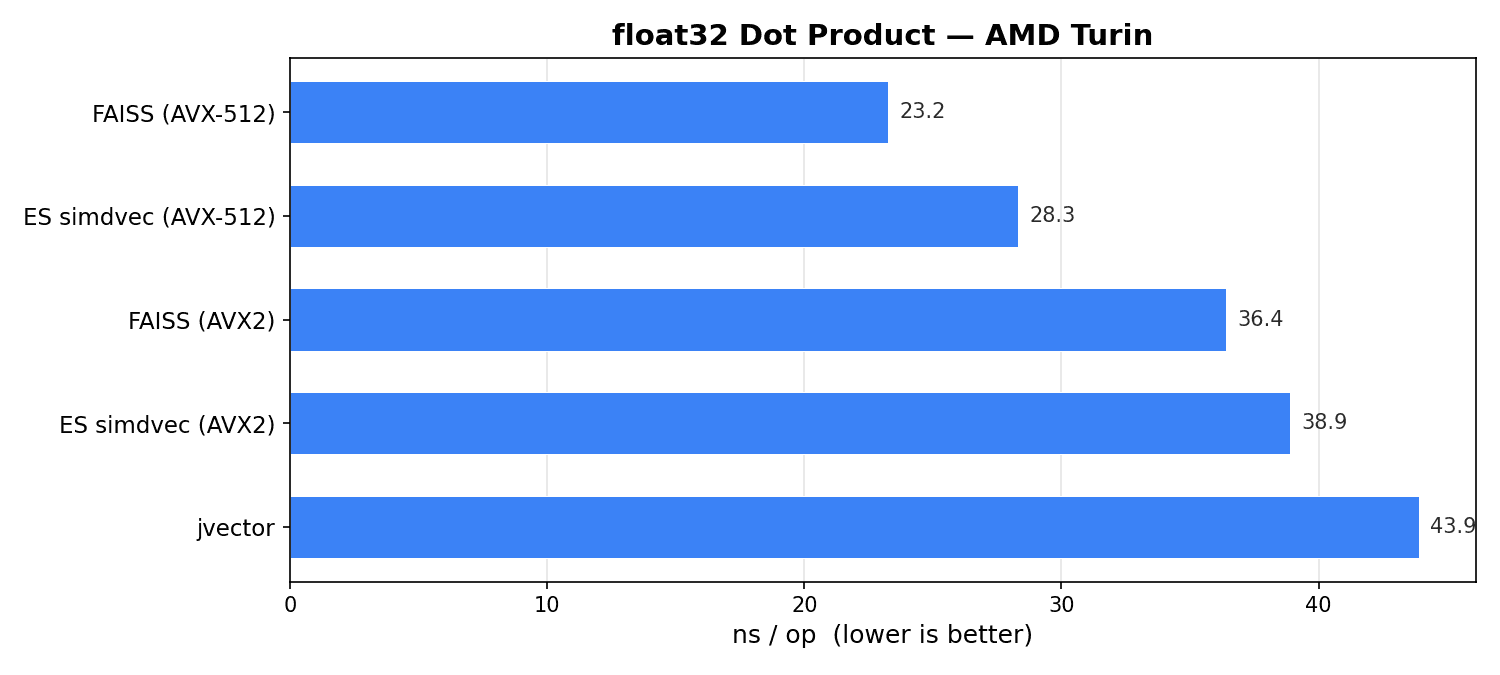
x86에서 FAISS AVX-512는 23ns로 가장 빠른 단일 쌍 커널입니다. simdvec AVX-512는 28ns로 그 뒤를 잇는데, 이 차이는 FFI 호출 오버헤드를 반영합니다. 두 구현 모두 멀티 누산기 언롤링을 사용하는 512비트 FMA를 사용합니다. AVX2 수준에서는 두 구현의 속도가 각각 36ns와 39ns로 훨씬 더 근접하며, 두 구현 모두 256비트 레지스터 및 메모리 로드 폭의 제약을 받습니다. jvector는 Java Panama Vector API를 사용하여 44ns의 성능을 보였습니다. Panama는 우수한 SIMD 코드를 생성하지만, 수동 조정 C++ 내장 함수가 여전히 우위를 점하고 있습니다.
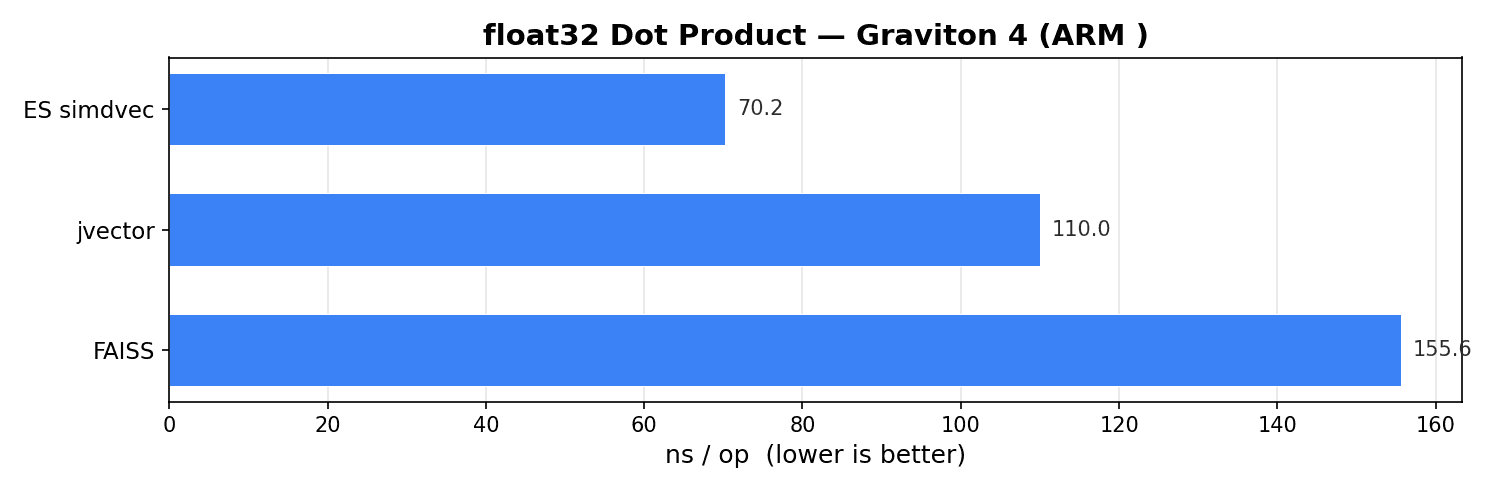
ARM에서는 simdvec은 70ns로 jvector(110ns)와 FAISS(156ns)를 크게 앞서고 있습니다. simdvec은 aarch64용으로 수동 조정 NEON 커널을 사용합니다. jvector는 네이티브 ARM 코드가 없으며 Panama에 의존합니다. FAISS는 명시적인 NEON 내장 함수 대신 컴파일러의 자동 벡터화에 의존하기 때문에 성능 차이가 더 큽니다. 이는 커널 라이브러리를 소유함으로써 얻을 수 있는 실질적인 이점을 반영합니다. Elasticsearch가 Graviton으로 확장되었을 때, NEON 전용 커널을 추가했습니다. jvector나 FAISS는 ARM 네이티브 코드에 이처럼 우선순위를 두지 않았습니다.
하지만 Elasticsearch는 float32만 지원하는 것이 아닙니다. Int8 양자화는 메모리 사용량을 4배, bfloat16은 2배, BBQ는 32배 줄여줍니다. 각 유형에는 고유한 SIMD 전략이 필요하며, simdvec은 모든 유형에 대해 수동 조정 네이티브 커널을 제공합니다.
비교한 라이브러리 중 int8에 대해 유사한 커널을 제공하는 것은 NumKong뿐입니다. 1024 차원에서 int8 내적, 제곱 유클리드, 코사인을 측정했습니다.
Int8 단일 쌍 스코어링(1,024차원, ns/vec op ― 낮을수록 좋음)
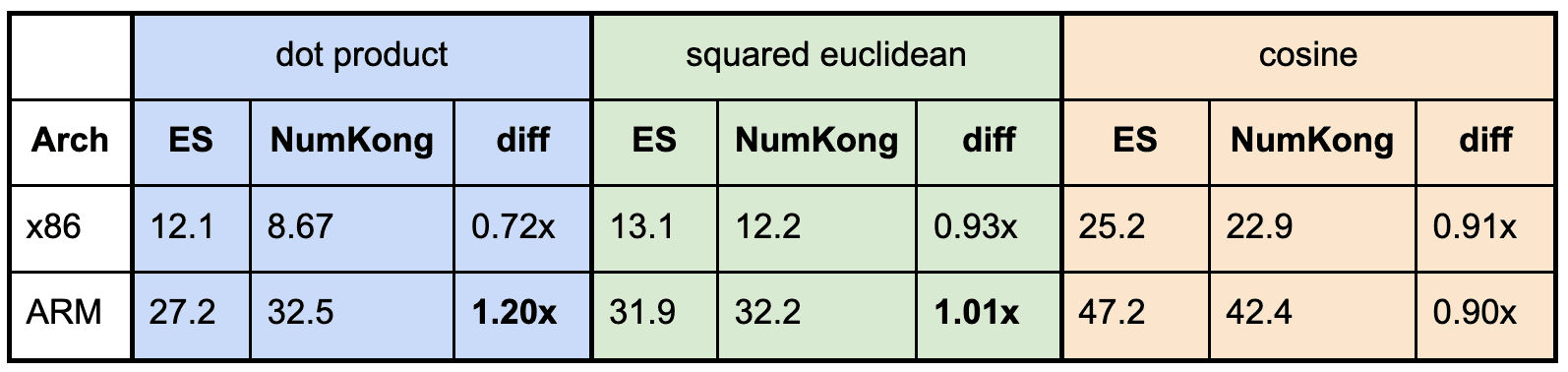
두 아키텍처 모두에서 NumKong은 중소 차원까지는 동일하거나 더 빠르며, 그 차이는 주로 호출 오버헤드(직접 C 호출 vs. Java FFI)가 더 낮기 때문입니다. 더 큰 크기에서는 simdvec이 따라잡는데, 이는 더 효율적인 커널 구현(캐스케이드 언롤링 사용)이 호출 비용을 분산시키기 때문입니다. 차원이 증가함에 따라 이 격차는 줄어들고 결국 역전됩니다. 교차점은 함수와 아키텍처에 따라 768에서 1536 사이의 차원에서 발생합니다.
Java FFI의 오버헤드가 약간 더 높지만, simdvec은 고도로 최적화된 C/C++ 라이브러리와 동등한 수준입니다. float32 및 int8 모두에 대해 최적화된 커널을 제공하는 유일한 라이브러리일 뿐만 아니라, ARM에서는 가장 우수한 성능을 보이며 x86에서는 FAISS에 비해 약간 뒤처지고(float32의 경우), int8의 경우 두 아키텍처 모두에서 NumKong과 매우 유사한 성능을 보입니다. bfloat16, int4, 바이너리, BBQ의 경우에도 대안이 존재하지만, simdvec은 각 유형의 데이터 레이아웃에 맞춰 수동 조정 SIMD를 통해 차별화된 성능을 제공합니다.
하지만 프로덕션 검색 엔진은 한 번에 하나의 벡터를 점수화하는 것이 아니라 쿼리당 수천 개의 벡터를 점수화합니다. 이제 관건은 이러한 규모에서 실제로 어떤 일이 벌어지는가 하는 점입니다.
한 번에 수천 개씩
단일 쌍 성능은 전체 그림의 일부일 뿐입니다. 실제로 중요한 것은 시스템이 부하 상태에서 어떻게 작동하는지입니다. 단일 HNSW 쿼리는 수백 개의 그래프 이웃에 점수를 매길 수 있습니다. IVF 스캔은 수천 개의 게시 목록 항목에 점수를 매길 수 있습니다. 순위 재지정 단계는 수만 개의 후보에 점수를 매길 수 있습니다. 단일 쌍 처리량도 중요하지만, 더 중요한 것은 많은 벡터를 얼마나 빨리 점수화할 수 있는지, 그리고 작업 세트가 CPU 캐시 범위를 벗어날 때 성능이 얼마나 완만하게 떨어지는지입니다.
simdvec은 모든 데이터 유형에 대해 벌크 스코어링을 제공합니다. 이는 단순히 단일 쌍 커널에 대한 루프가 아니라 차원 스트라이드당 한 번씩 쿼리 벡터를 로드하고 여러 문서 벡터에 걸쳐 공유하는 다중 누적기 내부 루프를 사용하며, 다음 배치에 대한 명시적인 캐시 라인 프리페칭을 제공합니다. jvector와 FAISS는 (작성 시점 기준으로) 이와 동등한 기능을 제공하지 않습니다. jvector는 벌크 API가 없으므로 호출자는 루프에서 한 번에 한 쌍씩 점수를 매깁니다. FAISS는 fvec_inner_products_ny을(를) 노출하는데, 작성 시점 기준으로 이는 쿼리 상각이나 프리페칭 없이 단일 쌍 거리 함수에 대한 루프로 구현되어 있습니다.
Float32. 커널 수준에서의 영향을 측정하기 위해, HNSW와 유사한 산포 그래프 이웃 조회를 시뮬레이션하는 무작위 접근 패턴을 사용하여 1024 차원 float32 문서 벡터의 개수를 늘려가며 단일 쿼리에 대한 점수를 매겼습니다. 세 가지 데이터 세트 크기(32, 625, 32,500개 벡터)는 작업 세트가 각각 L1, L2, L3 캐시를 초과합니다.
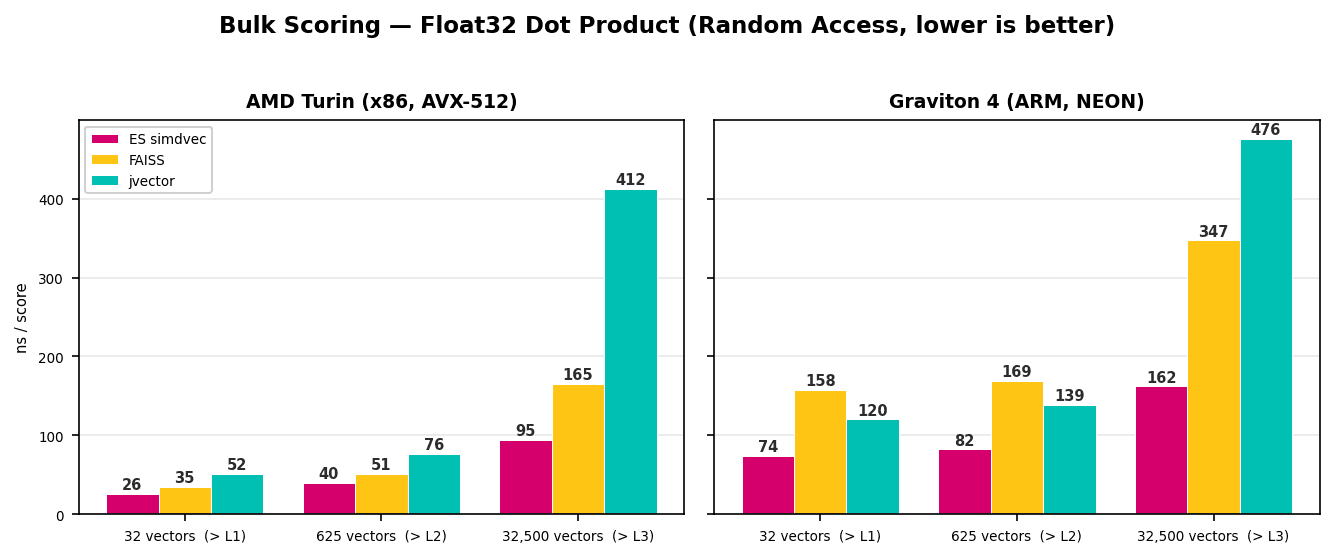
데이터가 캐시에 모두 수용될 때, simdvec이 두 플랫폼 모두에서 가장 빠르지만, 커널 산술이 우세하기 때문에 차이는 크지 않습니다. 실제 성능 차이는 작업 세트가 L3를 넘어 커질수록 나타납니다. x86에서 simdvec은 벡터당 95ns를 기록하는 반면, FAISS는 165ns, jvector는 412ns가 필요합니다. ARM에서도 패턴은 동일합니다. simdvec은 162ns를 유지하는 반면, FAISS는 347ns, jvector는 476ns까지 증가합니다. simdvec의 프리페칭 및 쿼리 상각은 단일 쌍 커널에 대한 단순 루프로는 따라잡을 수 없는 방식으로 메모리 지연 시간을 숨겨주며, 이러한 이점은 실제 검색 워크로드가 작동하는 메인 메모리 깊숙한 곳에서 더욱 두드러집니다.
Int8. 양자화된 유형에서도 동일한 패턴이 나타납니다. 동일한 L1, L2 및 L3 캐시 경계를 초과하도록 선택된 데이터 세트 크기로 1024 차원에서 int8 내적 벌크 스코어링을 측정하여 루프 내에서 simdvec의 벌크 스코어링과 NumKong의 단일 쌍 스코어링을 비교했습니다.
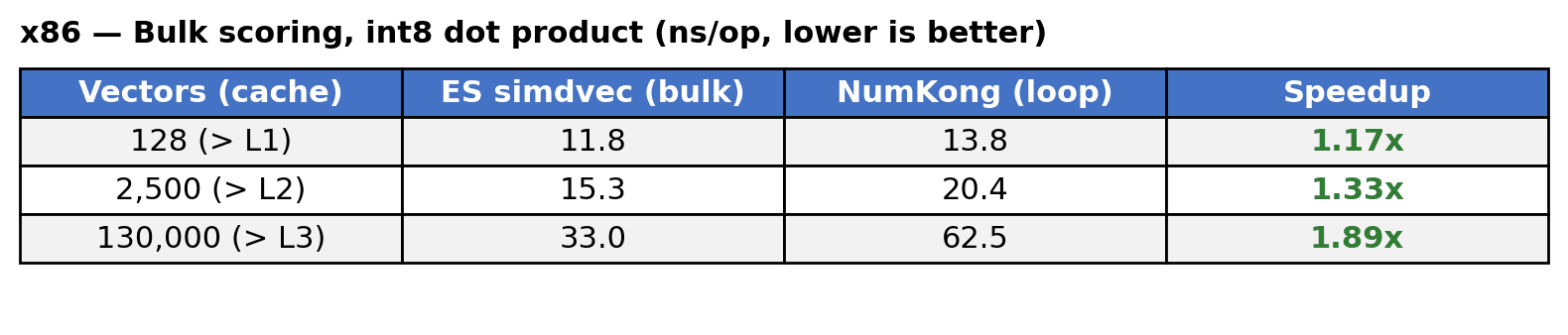
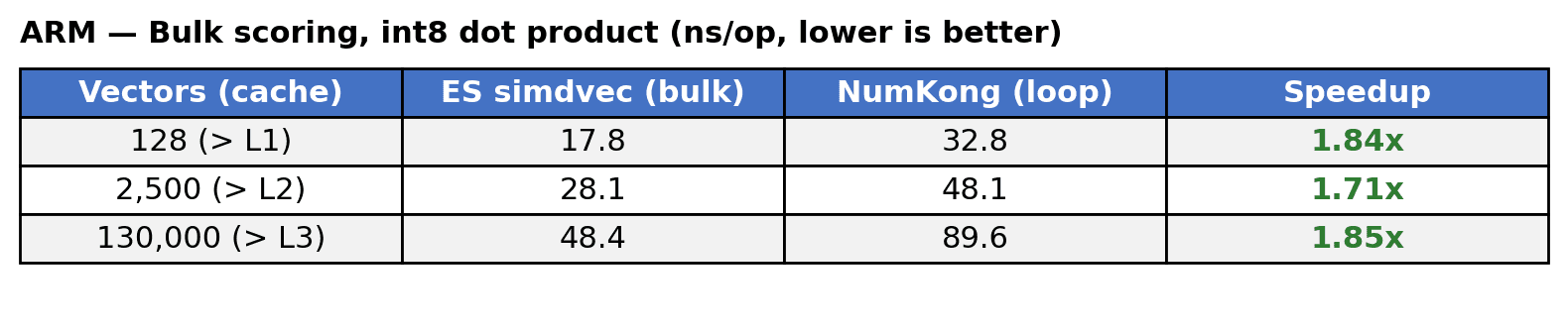
x86에서는 명시적 프리페칭과 배치 처리의 조합으로 simdvec이 1.2배~1.9배 더 빠릅니다. ARM에서도 simdvec은 모든 데이터 세트 크기에서 1.7~1.9배 더 빠른 성능을 보입니다. 이러한 이점은 한 번에 네 개의 벡터를 배치 처리하여 인터리브 액세스 패턴을 통해 메모리 수준의 병렬 처리를 제공하는 데서 비롯됩니다. 두 경우 모두 가장 두드러진 결과는 가장 중요하고 가장 데이터 세트 크기에서 나타납니다.
제곱 거리 및 코사인에 대한 결과도 유사한 패턴을 보이며, ARM의 경우 1.4~1.8배, x86의 경우 1.3~3.0배의 속도 향상을 보입니다(자세한 내용은 여기를 참조).
메모리가 중요한 경우
프로덕션 벡터 인덱스는 일반적으로 CPU 캐시에 적합하지 않습니다. 1024 차원의 10M 벡터 int8 인덱스는 10GB입니다. 후보를 스코어링하려면 DRAM에서 데이터를 스트리밍해야 하는데, 바로 이 부분에서 벌크 스코어링 아키텍처가 중요한 역할을 합니다.
일괄 스코어링 중 CPU 내부에서 발생하는 일을 측정하기 위해 하드웨어 성능 카운터를 사용했으며, 메모리 지연 시간을 숨기려면 아키텍처별로 하나씩, 근본적으로 다른 두 가지 전략이 필요하다는 것을 발견했습니다.
x86에서는 명시적 프리페칭을 통해 캐시 미스를 방지할 수 있습니다. 벌크 커널은 벡터를 순차적으로 처리하며, 다음 배치에 대한 프리페칭 명령어를 발행하면서 이전 배치가 완전히 계산된 후에 다음 배치를 처리합니다. 따라서 CPU가 데이터를 필요로 하기 전에 미래에 쓰일 데이터를 미리 L1 캐시로 끌어옵니다.

ARM에서는 프리페칭을 사용하더라도 동일한 순차적 접근 방식의 성능이 저조했습니다. 대신 벌크 커널은 매 스트라이드 위치마다 4개의 벡터에서 로드를 인터리브하여 순서에 상관없이 실행되는 엔진에 4개의 독립적인 메모리 스트림을 제공합니다. CPU는 데이터를 더 빠르게 가져오는 것이 아니라 메모리 요청이 처리되는 동안 항상 다른 계산 작업을 수행할 수 있으므로 대기 시간을 줄입니다. 자세한 분석은 이 GitHub 이슈에서 확인할 수 있습니다.

수치는 두 가지 다른 이야기를 들려줍니다.
- x86에서는 프리페칭을 통해 139,000개의 캐시 미스가 19,000개로 줄어들고, 사이클당 명령어 수(IPC)는 두 배 이상 증가합니다. 프리페칭은 점점 더 비용이 많이 드는 DRAM 왕복을 숨겨주기 때문에 데이터 세트 크기가 커질수록 이러한 이점은 더욱 커져 L2 캐시에서는 1.2배, L3 이상에서는 2.8배에 이릅니다.
- ARM에서는 캐시 미스는 거의 변하지 않습니다. 달라지는 것은 활용률입니다. 인터리브 액세스 패턴 덕분에 파이프라인에 데이터가 지속적으로 공급되어 백엔드 스톨이 40% 감소합니다. 데이터가 캐시에서 오든 DRAM에서 오든 메모리 수준 병렬 처리가 적용되므로 이러한 이점은 데이터 세트 크기와 관계없이 1.8배로 일관되게 유지됩니다.
두 가지 아키텍처, 두 가지 전략, 하나의 결과: 프로덕션 규모에서 simdvec은 벡터가 메인 메모리에 분산되어 있더라도 CPU 파이프라인을 계속 바쁘게 유지합니다.
Elasticsearch 사용자에게 의미하는 바
이러한 커널 수준 기능은 복합적으로 작용합니다. 단일 벡터 검색 쿼리는 수백만 개의 거리 연산(HNSW 그래프 탐색, 후보 스코어링, 순위 재지정)을 수행할 수 있습니다. 수천 개의 동시 쿼리에서 연산당 나노초 단위의 차이는 쿼리 지연 시간과 클러스터 처리량에 직접적인 영향을 미칩니다. float32, int8, bfloat16 또는 BBQ를 사용하든, 인덱스가 메모리에 있든 디스크에 있든, simdvec은 그 기반 엔진이며, 이러한 모든 연산은 마지막 나노초까지 최적화된 동일한 엔진을 통해 실행됩니다.
핵심은 프로덕션 규모에서 벡터 검색 성능이 주로 원시 SIMD 처리량에 의해 결정되는 것이 아니라는 점입니다. 시스템이 얼마나 효율적으로 메모리 지연 시간을 숨기면서 수백만 개의 소규모 연산에 걸쳐 컴퓨팅을 유지하느냐에 따라 결정됩니다.
simdvec 커널은 거의 모든 Elasticsearch 릴리즈에서 개선됩니다. 새로운 양자화 유형과 하드웨어 플랫폼이 등장하면 첫날부터 최적화된 커널이 제공됩니다. 또한 기존 유형은 이미 출시된 구현을 개선하면서 계속해서 빨라집니다.
관련 콘텐츠

Elasticsearch 검색 리콜을 측정하고 개선하는 방법: 하이브리드 검색을 통해 0.43에서 0.75로 향상하기
BM25 어휘 검색과 Jina AI 벡터 임베딩을 결합하여 Elasticsearch에서 검색 회상률을 측정하고 개선하는 방법을 알아보고, rank_eval API를 사용해 실제 숫자로 개선 효과를 검증하세요.

Elasticsearch와 Jina 임베딩을 활용한 비지도형 문서 클러스터링
Elasticsearch와 Jina 임베딩을 활용한 비지도형 문서 클러스터링을 위한 실용적이고 재현 가능한 접근 방식.

TSDS와 ILM의 만남: 늦게 도착하는 데이터를 거부하지 않는 시계열 데이터 스트림 설계
TSDS 시간 제한이 ILM 단계와 상호 작용하는 방법과 늦게 도착하는 메트릭을 처리할 수 있는 정책 설계 방법

LINQ to Elasticsearch ES|QL: C# 작성, Elasticsearch 쿼리
Elasticsearch .NET 클라이언트의 새로운 LINQ to Elasticsearch ES|QL 제공자를 살펴보세요. 이 제공자를 사용하면 C# 코드를 작성하여 ES|QL 쿼리로 자동 변환할 수 있습니다.

2026년 3월 26일
Kibana 대시보드 읽기 전용 권한 출시 안내
Kibana에 읽기 전용 대시보드 기능이 도입되었습니다. 이제 대시보드 작성자는 세분화된 공유 제어 기능을 통해 분석 결과의 정확성을 유지하고 의도치 않은 변경으로부터 데이터를 안전하게 보호할 수 있습니다.