Elasticsearch 使用分层可导航小世界 (HNSW) 算法对邻近图进行矢量搜索。众所周知,HNSW 算法在 k 近邻 (KNN) 搜索结果的质量与相关计算成本之间实现了良好的平衡。
在 HNSW 中,搜索过程是通过在图中迭代扩展候选节点来推进的,同时维护一个迄今为止已发现的、规模受限的最近邻节点集合。每次扩展都会带来一定的影响(包括向量运算、磁盘随机寻址等操作),并且随着搜索的推进,这种影响所带来的边际效益往往会逐渐降低。
优化 HNSW 图遍历的一种方法是,当发现新真实邻近节点的边际概率不再提升时,立即停止搜索。因此,在 Elasticsearch 9.2 中,我们引入了新提前终止机制。当连续访问图节点的次数达到固定数量,但仍无法提供足够的新最近邻节点时,搜索过程就会停止。
本文将指导您了解我们如何改进 HNSW 中提到的提前终止机制,使其更适合不同的数据集和数据分布。
HNSW 中的提前终止
在 HNSW 中,搜索过程是通过在近邻图中迭代扩展候选节点来推进的,同时持续维护一个迄今已发现、规模受限的最近邻节点集合,直至搜索遍历完整个图,或者满足某些提前终止条件为止。
因此,提前终止不一定总是性能优化,它本身就是搜索算法不可或缺的组成部分。决定终止搜索的时机,直接决定了效率与召回率之间的权衡关系。在 Elasticsearch 中,针对 HNSW 图的查询已内置多种提前终止机制:
- 访问节点的最大数量固定不变。
- 已达到固定的超时时间。
这些规则虽然简单且可预测,但在很大程度上与搜索的实际操作无关。此外,它们主要用于确保最终用户在合理的时间内完成查询。
在上一篇博文中,我们介绍了 HNSW 冗余的概念。简而言之,当 HNSW 持续评估那些无法带来更多最近邻节点的新候选节点时,就会产生冗余计算。
耐心:衡量进展而非过程
“耐心”这一概念将提前终止的判定标准重新定义为“衡量进展而非过程”。
而不是问:
“我们走了多少步?”
新的问题变成了:
"在我们彻底丧失希望之前,我们能够接受浪费多少计算量?"
在 HNSW 搜索过程中,早期探索阶段通常能显著提升前 k 个候选结果集的质量。在 HNSW 图探索的初始阶段,随着算法不断发现与查询向量距离更近的邻近节点,邻近节点集会持续更新。随着搜索逐步收敛,这类质量提升会逐渐减少。基于“耐心”机制的终止策略会监测这一变化模式,当持续一段时间内未再出现显著改进时,即终止搜索过程。
在实际操作中,我们在遍历 HNSW 图的过程中,每跳转到一个候选节点时,都会计算队列饱和度。该指标用于衡量在访问最近一个图节点期间,未发生变化的最近邻节点所占的百分比(或者说,是上一轮迭代中引入的新邻节点数量的倒数)。若连续多次迭代中,这一比率持续过高,我们便会停止对图的遍历。
从概念层面来看,“耐心”机制将HNSW搜索视为一个收益递减的过程。当搜索收益趋于平稳时,继续遍历图结构所带来的增益将微乎其微。
这种框架之所以强大,是因为它将终止与可观察到的结果直接联系起来,而不是与任意的固定限制联系起来。
采用这种智能提前终止技术的优势在于,HNSW 图探索过程在保持近乎完美的相对召回率的同时,往往会访问更少数量的图节点。
为了直观地说明这一点,我们可以在几个数据集(FinancialQA 和 Quora)和模型(JinaV3 和 E5-small)上绘制基于耐心的提前终止(标注为 et=static)与默认 HNSW 行为(标注为 et=no)的对比图。

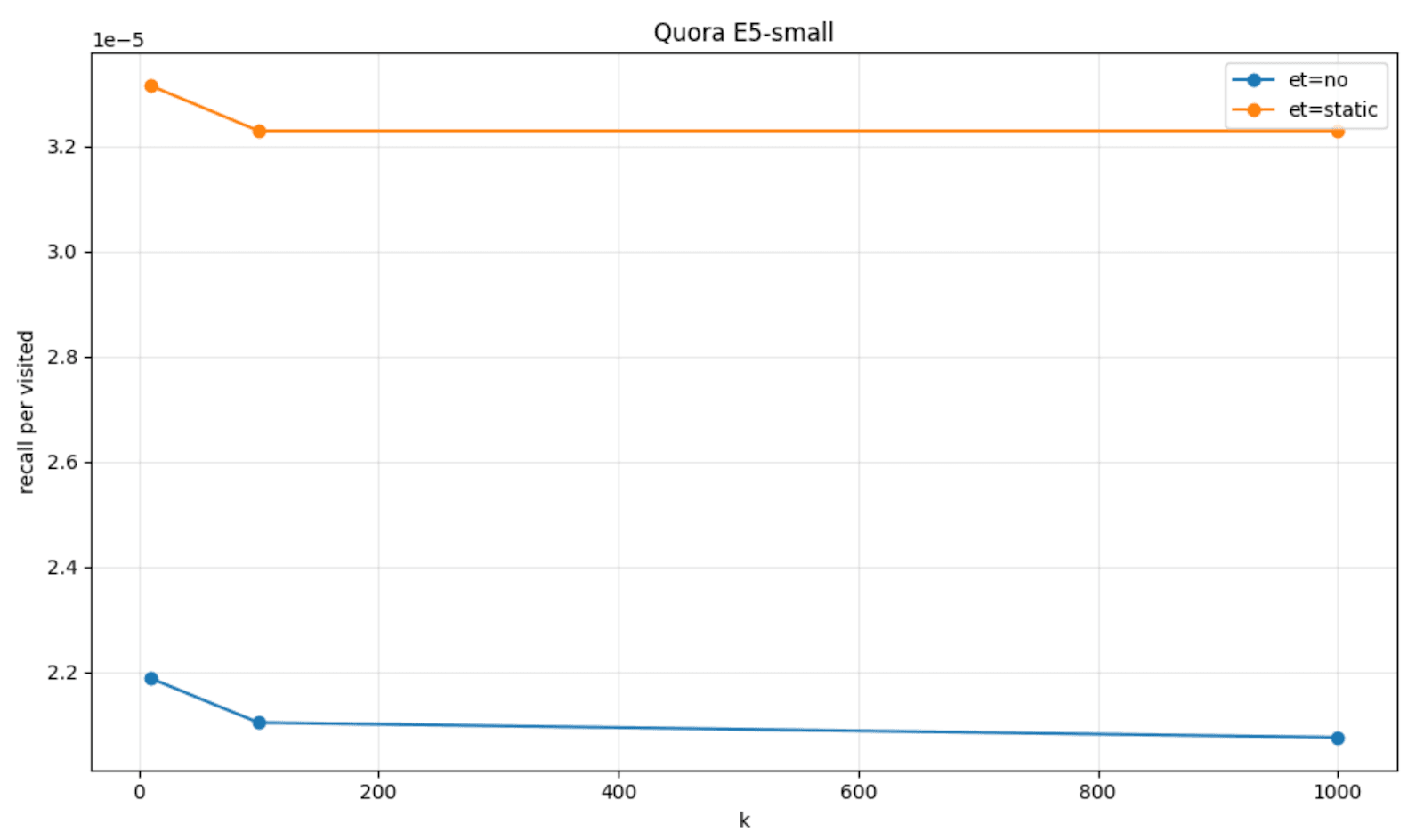
静态阈值和 HNSW 动态
实际上,Elasticsearch 使用静态阈值来实现这一点。其中一个阈值指的是饱和阈值,即我们认为次优的饱和度比率。另一个阈值指的是,在队列达到次优饱和度的情况下,我们允许访问的连续图节点数,即耐心阈值。
当我们在 Elasticsearch 9.2 中引入这种提前终止策略时,我们决定选择保守的默认设置,以便在延迟和内存消耗方面仍能达到效果的同时,尽可能多地让系统召回。因此,我们将饱和阈值设为 100%,耐心阈值设为 KNN 查询中 num_candidates 的(有界)30%。
在很多情况中,这些设置能取得不错的效果;然而,对于请求相同数量邻节点的两个查询而言,它们的收敛行为可能存在极大差异。有些查询会遇到密集的局部邻域,能迅速达到饱和状态;而有些查询则必须遍历漫长且稀疏的路径,才能找到具有竞争力的候选节点。事实证明,后一种情况最难以有效处理。
因此,我们有时会发现:
- 简单查询的过度探索。
- 复杂查询的过早终止。
因此,我们认为固定阈值编码了关于收敛的全局假设,而我们可以使 HNSW 更好地适应不同的动态。
实现 HNSW 的提前终止自适应
自适应提前终止从另一个角度解决了这个问题。该算法不是强制执行预定义的停止阈值,而是从搜索动态本身推断何时停止。
因此,我们不再比较连续两个候选节点间的队列饱和度比率,而是决定引入即时平滑发现率 (即最近一次访问 i 中,针对查询 q 新发现的邻近节点数量),同时结合图遍历过程中该发现率的滑动均值 和标准差(采用韦尔福德算法计算)。这些关于发现率的统计量按每个查询独立计算,从而可根据不同查询的特性动态调整其“耐心”阈值。
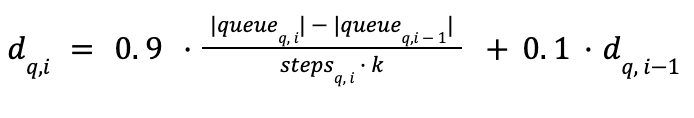
先前静态设定的阈值将根据发现率统计数据实现自适应调整:饱和阈值调整为滚动均值加上标准差;同时,我们将耐心值设为与标准差呈反比变化的动态参数。
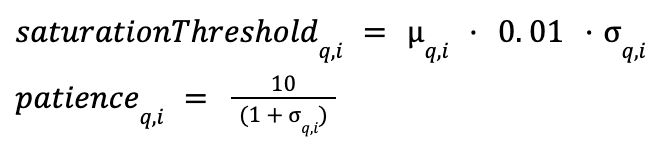
提前退出的规则保持不变;当瞬时发现率低于自适应饱和阈值时,即判定达到饱和状态。如果在连续访问的候选节点数量超过自适应耐心值所设定的次数后,饱和状态仍持续存在,则停止对图的遍历。
如此一来,我们实现了搜索行为不再依赖于 KNN 查询中的 num_candidates 参数(该参数可能始终被设定为固定值或保留默认值,而与提前终止机制无关),同时能够根据每个查询和向量分布进行动态适配。
在 FinancialQA 和 Quora 数据集上,采用自适应策略(标记为 et=adaptive)时,每个访问节点的召回率相较于静态策略( et=static)和默认 HNSW 行为(et=no)均有显著提升。


在 Elasticsearch 9.3 中,HNSW 密集向量字段的自适应提前终止默认处于启用状态(最终可以通过相同的索引级别设置将其关闭)。
相关内容

2026年4月23日
我们如何构建 Elasticsearch simdvec,使其成为世界上速度最快的向量搜索之一
我们如何打造 Elasticsearch simdvec——这是 Elasticsearch 中每一次向量搜索查询背后的手动调优 SIMD 内核库。

如何衡量和提升 Elasticsearch 搜索召回率:通过混合搜索将召回率从 0.43 提升至 0.75
了解如何通过将 BM25 词汇搜索与 Jina AI 向量嵌入相结合来测量和提高 Elasticsearch 中的搜索召回率,并使用 rank_eval API 以实际数据验证改进效果。

基于 Elasticsearch + Jina 嵌入的无监督文档集群
一种使用 Elasticsearch 和 Jina 嵌入进行无监督文档集群的实用、可复现方法。


LINQ to Elasticsearch ES|QL:编写 C# 代码,查询 Elasticsearch
探索 Elasticsearch .NET 客户端中全新的 LINQ to Elasticsearch ES|QL 提供程序。借助该程序,您可以编写会自动转换为 ES|QL 查询的 C# 代码。