最近,我将客户的指标集群从“所有内容都在热层”迁移到了热层/冷层/冻结层架构。这是我以前已执行过几十次的更改。几分钟内,Logstash 就完全停止了数据传输。
Elasticsearch 拒绝了延迟到达的指标。这些拒绝导致管道滞后,导致更多的延迟数据,从而引发了更多的拒绝。最终,该管道彻底停滞了。
我们不得不从快照中恢复数据,重新索引数据,并重新设计摄取管道以恢复数据。
根本原因并非索引生命周期管理 (ILM) 本身。而是时序数据流 (TSDS) 以及它们如何执行有时间限制的后备索引。
TSDS 可以将指标的存储需求减少 40——70%,但使 TSDS 高效的架构更改也改变了索引随时间推移的行为方式。这些变化在设计 ILM 策略或数据摄取管道可能会产生延迟到达的数据时非常重要。
简要说明
使用 TSDS 时:
- 后备索引仅接受特定时间窗口内的文档。
- 如果在索引移动到冷冻或冻结状态后有延迟的数据到达,Elasticsearch 将拒绝接受这些文档,或将其路由到故障存储(如果已配置)。
设计规则:
什么是时序数据流?
时序数据流 (TSDS) 是针对指标数据进行了优化的专用数据流。对数据进行路由,使相关文档位于同一分片内,从而优化它们以进行查询和检索。下面介绍 Elasticsearch 如何实现这一操作:
每个文档包含:
- 时间戳。
- 用于识别时间序列的维度字段。
- 表示测量值的度量字段。
示例包括:
- 每台主机的 CPU 使用率。
- 每项服务的请求延迟。
- 每个传感器的温度读数。
维度 确定了我们要测量的内容,而度量 则代表了随时间变化的值。
尺寸
维度描述被测量的实体。
示例:
我们在映射中按以下方式定义它们:
指标
指标代表数值,并使用以下方式定义:
常用指标类型:
- 计量:数值会上升和下降。
- 计数器:数值不断增加,直至重置。
Elastic Agent 主要收集指标和日志数据,因此,即使您没有手动启用任何 TSDS 索引,集群中仍可能包含这些索引。
_tsid 字段
Elasticsearch 内部会根据维度字段生成 _tsid 值。这样,具有相同尺寸的文档就可以路由到相同的分区,从而改进:
- 压缩。
- 查询位置。
- 聚合性能。
关键区别:有时间限制的后备索引
传统数据流始终写入最新的支持索引,称为 写索引,但 TSDS 的行为有所不同。
每个 TSDS 后备索引都有一个定义的时间窗口,并且仅接受 @timestamp 值在该窗口内的文档:
为文档编制索引时,Elasticsearch 会将其路由到负责该时间戳的后备索引,这意味着与传统索引不同,TSDS 可以同时写入多个后备索引。
例如:
- 实时数据 → 最新索引。
- 较晚的数据 → 覆盖该时间范围的较早索引。

为延迟到达的数据进行设计
真正的摄取管道很少能完美地按时提供指标。指标可能会由于网络中断、传输过程中的积压、批量摄取以及边缘设备的丢失而延迟,这些设备重新连接后会开始追赶进度。
传统索引会悄然吸收这些延迟。TSDS 不会。
如果文档的时间戳超出了可写后备索引的范围,Elasticsearch 将拒绝该文档,这意味着您的 ILM 策略必须考虑延迟数据。
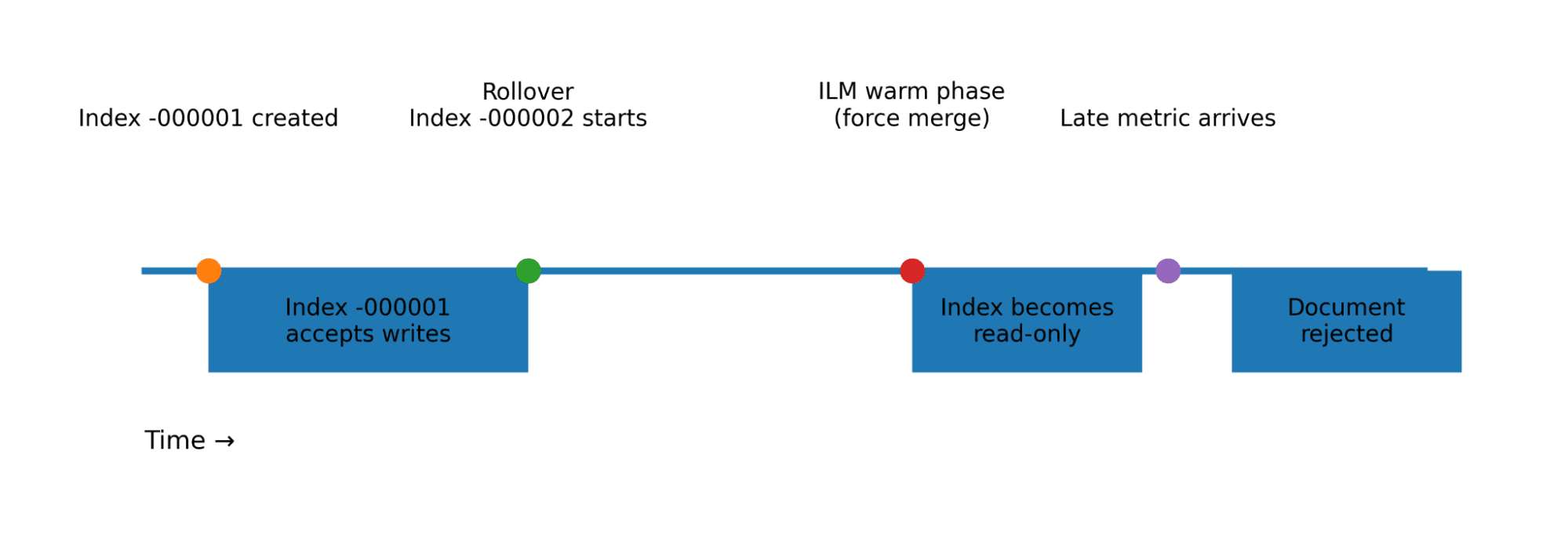
关键制约因素
后备索引必须保持足够长的可写时间,以接受延迟数据。
实际上:
由于 ILM 衡量的是从滚动更新开始算起的年限,因此操作规则变为:
例如,如果指标最多可能延迟六小时到达,则索引在滚动更新后必须保持至少六小时的可写状态。
正是由于没有考虑到这一限制,才导致了前面所述的摄取失败。延迟到达的数据被定向到一个早期索引,该索引已经处于冷层并因此被写入阻塞。
处理被拒绝的文档
当 TSDS 拒绝文档时,Elasticsearch 返回一个错误,表明时间戳不在可写索引的范围内。您的摄取管道如何处理该错误,决定了是丢失数据还是停止摄取。
处理被拒绝文档的主要机制是故障存储。
故障存储(在 Elasticsearch 9.1+ 中推荐)
Elasticsearch 9.1 引入了失败存储,它能自动捕获被拒绝的文档。Elasticsearch 不会将错误返回给客户端,而是将失败的文档写入数据流中的专用失败索引。
您可以使用以下方法检查故障:
使用故障存储可防止摄取管道因拒绝错误而阻塞,同时保留失败的数据以供分析或重新索引。
监测拒绝问题
延迟到达问题通常首先表现为摄取异常。您可能会先注意到它们:
- 索引速率突然下降。
- 拒绝的文档激增。
- 越来越多的故障存储条目。
- 管道输入和输出计数不匹配。
通过对这些信号发出警报,操作人员可以在管道停滞之前检测问题。工作流、机器学习作业和其他机制可用于自动检测和通知。
TSDS + ILM 迁移检查清单
如果要将指标集群迁移到 TSDS、引入 ILM 分层,或升级到指标默认为 TSDS 的 Elasticsearch 版本,请先查看这些项目。
1. 测量摄取延迟
在更改 ILM 策略之前,请确定:
- 正常摄取延迟。
- 事件期间的最坏延迟情况。
- 批量管道造成的延迟。
您的 ILM 设计必须适应最大实际延迟。
2. 验证索引时间窗口
检查您的 TSDS 支持索引:
寻找:
time_series.start_timetime_series.end_time
这些界限决定了哪些索引可以接受文档。了解这些时间窗口有助于您确定数据最多可以延迟多久才不会被拒绝。
3. 为延迟到达的数据调整热层的大小
确保后备索引保持可写状态的时间足够长,以便写入延迟到达的数据。
操作规则:
warm_min_age > rollover_max_age + maximum_expected_lateness
请记住,如果指标可能晚到六个小时,那么索引必须至少在六个小时内保持可写状态。
4. 决定如何处理被拒绝的文档
在启用 TSDS 之前选择策略:
- 故障存储(在 Elasticsearch 9.1+ 中推荐)。
- Logstash 死信队列。
- 为延迟到达的数据提供后备索引。
- 接受有限的数据丢失。
5. 监测摄取健康状况
为以下内容添加警报:
- 索引速率下降。
- 已拒绝的文档。
- 故障存储增长。
- 管道输入/输出不匹配。
数据延迟问题通常首先表现为摄取异常。
总结
时序数据流为指标工作负载提供重大的存储和性能改进,但它们引入了重要的架构变更:后备索引是时间绑定的,这影响了 ILM 的行为。
使用 TSDS 时:
- 索引必须保持足够长的可写时间,以接受延迟数据。
- 摄取管道应安全处理被拒绝的文档。
要记住的关键规则是:
如果围绕这一约束条件设计 ILM 策略,TSDS 就能很好地处理指标工作负载。
但若忽视这一限制,您的摄取管道可能会很难发现这些时间界限。
相关内容

2026年4月23日
我们如何构建 Elasticsearch simdvec,使其成为世界上速度最快的向量搜索之一
我们如何打造 Elasticsearch simdvec——这是 Elasticsearch 中每一次向量搜索查询背后的手动调优 SIMD 内核库。

如何衡量和提升 Elasticsearch 搜索召回率:通过混合搜索将召回率从 0.43 提升至 0.75
了解如何通过将 BM25 词汇搜索与 Jina AI 向量嵌入相结合来测量和提高 Elasticsearch 中的搜索召回率,并使用 rank_eval API 以实际数据验证改进效果。

基于 Elasticsearch + Jina 嵌入的无监督文档集群
一种使用 Elasticsearch 和 Jina 嵌入进行无监督文档集群的实用、可复现方法。

LINQ to Elasticsearch ES|QL:编写 C# 代码,查询 Elasticsearch
探索 Elasticsearch .NET 客户端中全新的 LINQ to Elasticsearch ES|QL 提供程序。借助该程序,您可以编写会自动转换为 ES|QL 查询的 C# 代码。
