Recentemente, migrei o cluster de métricas de um cliente de "tudo na camada ativa" para uma arquitetura hot/cold/frozen. Era uma mudança que eu já havia feito dezenas de vezes antes. Em poucos minutos, o Logstash parou completamente de avançar os dados.
O Elasticsearch estava rejeitando métricas de chegada tardia. Essas rejeições fizeram o pipeline ficar atrasado, resultando em dados mais tardios, o que desencadeou ainda mais rejeições. Com o tempo, o pipeline parou completamente.
Tivemos que restaurar a partir do snapshot, reindexar os dados e redesenhar o pipeline de ingestão para recuperar.
A causa raiz não era a gestão de ciclo de vida de índices (ILM) em si. Tratava-se de fluxos de dados de séries temporais (TSDS) e como eles aplicam índices de apoio com limite temporal.
O TSDS pode reduzir os requisitos de armazenamento para métricas em 40–70%, mas as mudanças na arquitetura que tornam o TSDS eficiente também alteram a forma como os índices se comportam ao longo do tempo. Essas mudanças são importantes ao projetar políticas de ILM ou quando seus pipelines de ingestão podem produzir dados tardios.
TL;DR
Ao usar o TSDS:
- Índices de suporte aceitam apenas documentos dentro de uma janela de tempo específica.
- Se dados tardios chegarem após um índice se tornar frio ou congelado, o Elasticsearch rejeitará esses documentos ou os encaminhará para o armazenamento de falhas, caso esteja configurado.
Regra de design:
O que é um fluxo de dados de séries temporais?
Um fluxo de dados de série temporal (TSDS) é um fluxo de dados especializado otimizado para dados métricos. Os dados são roteados de modo que documentos relacionados fiquem localizados dentro dos mesmos fragmentos, otimizando-os para consulta e recuperação. Como o Elasticsearch faz isso:
Cada documento contém:
- Um registro de data e hora.
- Campos dimensionais que identificam a série de tempo.
- Campos métricos representando valores medidos.
Alguns exemplos:
- Uso da CPU por host.
- Solicitar latência por serviço.
- Leituras de temperatura por sensor.
As dimensões identificam o que queremos medir, enquanto as métricas representam valores que mudam com o tempo.
Dimensões
Dimensões descrevem a entidade medida.
Exemplos:
Definimos eles em mapeamentos com:
Métricas
Métricas representam valores numéricos e são definidas usando:
Tipos comuns de métricas:
- Indicador: Valores que sobem e descem.
- Contador: valores que aumentam até serem reiniciados.
O Elastic Agent coleta principalmente métricas e dados de log. Mesmo que você não tenha habilitado manualmente nenhum índice TSDS, ainda pode tê-los no seu cluster.
O campo _tsid
O Elasticsearch gera internamente um valor _tsid a partir dos campos de dimensão. Isso permite que documentos com dimensões idênticas sejam roteados para o mesmo shard, melhorando:
- Compressão.
- Local da consulta.
- Desempenho de agregações.
A principal diferença: índices de apoio com prazo definido
Os fluxos de dados tradicionais sempre gravam no índice de suporte mais recente, chamado índice de gravação, mas o TSDS se comporta de maneira diferente.
Cada índice de apoio TSDS tem uma janela de tempo definida e aceita apenas documentos com @timestamp valores que se encaixam nessa janela:
Quando um documento é indexado, o Elasticsearch encaminha o documento para o índice de suporte responsável por aquele timestamp, o que significa que, ao contrário dos índices tradicionais, um TSDS pode gravar em vários índices de suporte simultaneamente.
Por exemplo:
- Dados em tempo real → índice mais recente.
- Dados tardios → índice anterior cobrindo esse intervalo de tempo.

Projetando para dados tardios
Os pipelines de ingestão reais raramente entregam métricas perfeitamente no prazo. As métricas podem ser atrasadas por interrupções de rede, acúmulos no caminho, ingestão em lote e perda de dispositivos de borda, que se reconectam e começam a recuperar o atraso.
Índices tradicionais absorvem silenciosamente esses atrasos. O TSDS não.
Se o carimbo de data/hora de um documento estiver fora da faixa de índices de apoio graváveis, o Elasticsearch o rejeitará, o que significa que sua política de ILM deve considerar os dados tardios.
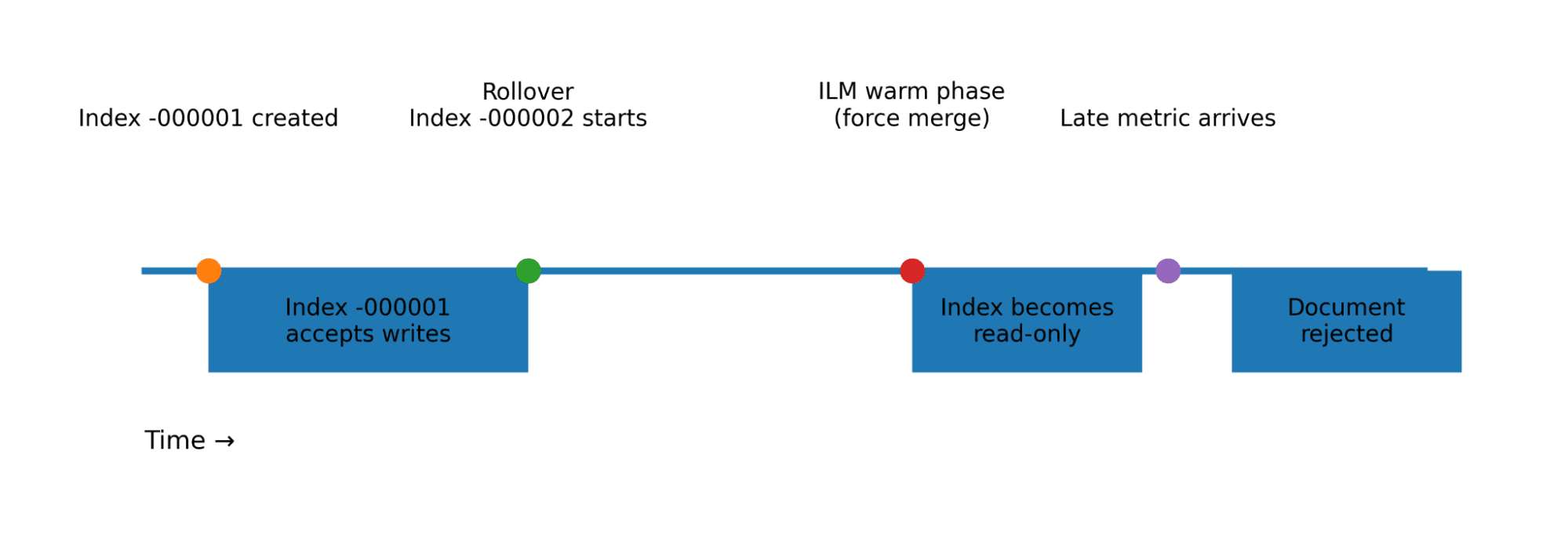
A restrição crítica
Os índices de suporte precisam permanecer com permissão de escrita por tempo suficiente para receber dados com atraso.
Em termos práticos:
Como o ILM mede o tempo de existência a partir do rollover, a regra operacional passa a ser:
Por exemplo, se as métricas podem chegar até seis horas atrasadas, os índices devem permanecer graváveis pelo menos seis horas após o rollover.
Desconsiderar essa restrição foi exatamente o que causou a falha de ingestão descrita anteriormente. Os dados tardios eram direcionados para um índice anterior, que já estava na camada cold e, portanto, era bloqueado para escrita.
Tratamento de documentos rejeitados
Quando o TSDS rejeita um documento, o Elasticsearch retorna um erro, indicando que o carimbo de data e hora não está dentro da faixa de índices graváveis. Como seu pipeline de ingestão lida com esse erro determina se você perde dados ou trava a ingestão de dados.
O principal mecanismo para lidar com documentos rejeitados é o armazenamento de falhas.
Repositório de falhas (recomendado no Elasticsearch 9.1+)
O Elasticsearch 9.1 introduziu o armazenamento de falhas, que captura automaticamente documentos rejeitados. Em vez de retornar erros aos clientes, o Elasticsearch grava documentos rejeitados em um índice dedicado de falhas dentro do fluxo de dados.
Você pode inspecionar falhas usando:
O uso do armazenamento de falhas impede que os pipelines de ingestão travem devido a erros de rejeição, enquanto preserva os dados com falha para análise ou reindexação.
Monitoramento de questões de rejeição
Os problemas de chegada tardia geralmente aparecem primeiro como anomalias de ingestão. Você pode notá-los primeiro como:
- Quedas repentinas na taxa de indexação.
- Picos nos documentos rejeitados.
- Um número crescente de entradas de lojas que falham.
- Diferenças de incompatibilidade entre entradas e saídas do pipeline contagem.
Alertas nesses sinais permitem que os operadores detectem problemas antes que os pipelines parem. Fluxos de trabalho, trabalhos de Machine Learning e outros mecanismos podem ser usados para automatizar a detecção e notificação.
Lista de verificação de migração para TSDS + ILM
Se você estiver migrando um cluster de métricas para o TSDS, introduzindo a hierarquização do ILM ou atualizando para uma versão do Elasticsearch em que as métricas são TSDS por padrão, revise esses itens primeiro.
1. Medir a latência de ingestão
Antes de mudar as políticas de ILM, determine:
- Atraso normal na ingestão de dados.
- Pior caso de atraso durante os incidentes.
- Atrasos causados por pipelines em lote.
O projeto do seu ILM deve acomodar o máximo de atraso realista.
2. Verificar as janelas de tempo do índice
Inspecione seus índices de respaldo de TSDS:
Analise:
time_series.start_timetime_series.end_time
Esses limites determinam quais índices podem aceitar documentos. Entender essas janelas pode ajudar a determinar o quanto os dados podem estar atrasados antes de serem rejeitados.
3. Dimensione o nível hot para chegadas tardias
Garanta que os índices backing permaneçam graváveis por tempo suficiente para os dados tardios.
Regra operacional:
warm_min_age > rollover_max_age + maximum_expected_lateness
Lembre-se, os índices devem permanecer graváveis por pelo menos seis horas se as métricas chegarem com seis horas de atraso.
4. Decida o que fazer com documentos rejeitados
Escolha uma estratégia antes de ativar o TSDS:
- Armazenamento de falhas (recomendado no Elasticsearch 9.1+).
- Fila de dead letter do Logstash.
- Índice de contingência para chegadas tardias.
- Aceitar a perda limitada de dados.
5. Monitorar a saúde da ingestão
Adicionar alertas para:
- A taxa de indexação cai.
- Documentos rejeitados.
- Crescimento do armazenamento de falhas.
- Desajustes de entrada/saída do pipeline.
Problemas de dados tardios geralmente aparecem primeiro como anomalias de ingestão.
Resumo
Fluxos de dados de séries temporais oferecem grandes melhorias de armazenamento e desempenho para cargas de trabalho de métricas, mas introduzem uma mudança arquitetônica importante: os índices de suporte têm limite temporal, o que afeta o comportamento do ILM.
Ao usar o TSDS:
- Os índices devem permanecer graváveis tempo suficiente para aceitar dados tardios.
- Os pipelines de ingestão devem lidar com documentos rejeitados com segurança.
A regra fundamental a lembrar é:
Se você projetar políticas de ILM em torno dessa restrição, o TSDS funcionará extremamente bem para cargas de trabalho de métricas.
Se ignorar isso, seu pipeline de ingestão pode descobrir esses limites de tempo da pior forma.
Conteúdo relacionado

23 de abril de 2026
Como criamos o Elasticsearch simdvec para que a busca vetorial seja uma das mais rápidas do mundo
Como criamos o Elasticsearch simdvec, a biblioteca do kernel SIMD ajustada manualmente por trás de cada consulta de busca vetorial no Elasticsearch.

4 de maio de 2026
Como medir e melhorar o recall das buscas no Elasticsearch: de 0,43 a 0,75 com a busca híbrida
Aprenda a medir e melhorar o recall das buscas no Elasticsearch combinando a busca léxica BM25 com embeddings vetoriais do Jina AI, usando a API rank_eval para validar a melhoria com números reais.

10 de abril de 2026
Clustering não supervisionado de documentos com Elasticsearch + embeddings Jina
Uma abordagem prática e reproduzível para clustering não supervisionado de documentos com Elasticsearch e embeddings Jina.

1 de abril de 2026
LINQ para Elasticsearch ES|QL: escreva Consultas em C# e Consulte o Elasticsearch
Explorando o novo provedor LINQ para Elasticsearch ES|QL no cliente Elasticsearch .NET, que permite escrever código C# automaticamente traduzido para consultas ES|QL.

20 de março de 2026
Rapidez x precisão: medindo o recall da busca vetorial quantizada
Uma explicação de como medir o recall para busca vetorial no Elasticsearch com configuração mínima.