Die lexikalische Suche mit dem BM25-Ranking-Algorithmus ist günstig, schnell und sehr effektiv für eine breite Palette von Abfragen. Sie hat jedoch einen blinden Fleck: Abfragen, die keine Tokens mit Ihren Dokumenten teilen. In diesem Artikel messen Sie genau, wo BM25 auf der Strecke bleibt. Wir werden die Ranking-Evaluations-API von Elasticsearch (rank_eval) verwenden und diese Lücke schließen, indem wir Jina AI Einbettungen über den Elastic Inference Service (EIS) hinzufügen. Sie erfahren, wie der Abruf-Score von 0.43 auf 0.75 steigt und verstehen, warum er dies tut.
Was ist ein Abruf?
Der Abruf misst auf einer Skala von 0 bis 1, wie viele der Dokumente, die Ihre Nutzer tatsächlich haben möchten, irgendwo in Ihren Suchergebnissen erscheinen. Wenn eine Abfrage drei Produkte anzeigen sollte und Ihre Suche nur zwei davon in den Top 10 zurückgibt, gilt recall@10 = 0.67 für diese Abfrage. Es ist eine mengenbasierte Metrik: Die Position der relevanten Dokumente innerhalb dieser k Ergebnisse spielt keine Rolle. Ein relevantes Dokument auf Position 10 zählt genauso wie eines auf Position 1. Ein hoher Abruf-Wert bedeutet, dass Sie keine relevanten Ergebnisse verlieren.
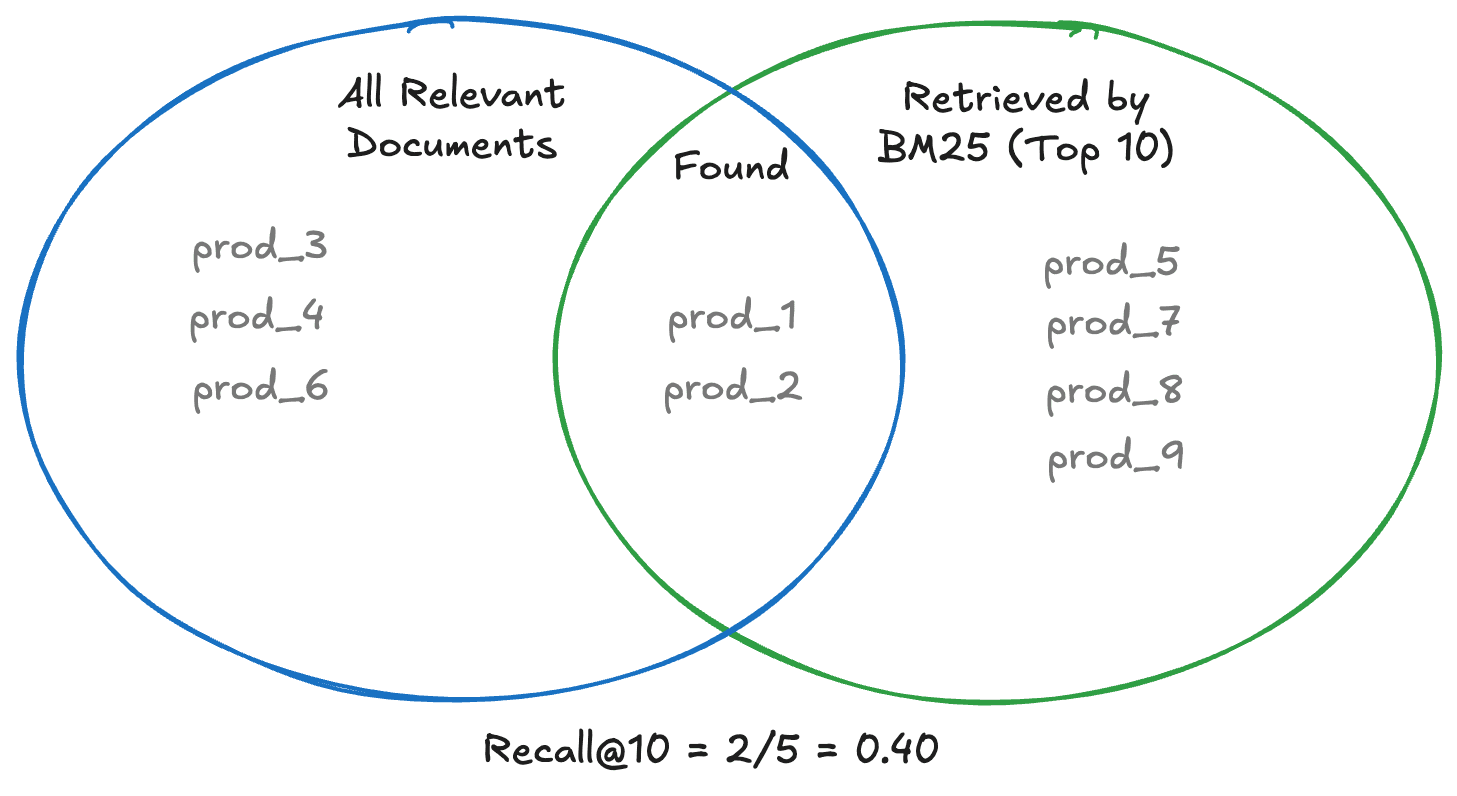
Das Diagramm zeigt zwei Mengen: alle relevanten Dokumente (links) und die Top 10, die BM25 tatsächlich abgerufen hat (rechts). Nur die Schnittmenge zählt für den Rückruf: prod_1 und prod_2 wurden gefunden, während prod_3, prod_4 und prod_6 vollständig übersehen wurden. Ergebnis: Recall@10 = 2/5 = 0.40.
Voraussetzungen
Lassen Sie uns zur Sache kommen, um besser zu verstehen, wie das Abrufverfahren funktioniert. Diese Demonstration verwendet Python. Sie können es im begleitenden Notebook verfolgen (notebook.ipynb), wo jeder Codeblock eine ausführbereite Zelle darstellt.
Der bereitgestellte Code verwendet Folgendes:
- Elasticsearch 9.3+
- Python 3.10+
- Eine
.env-Datei mit Ihren Elasticsearch-Zugangsdaten
Der Datensatz
Wir verwenden einen Produktkatalog mit 1.000 Produkten, der Kategorien wie Schuhe, Elektronik, Werkzeuge und mehr umfasst.
Jedes Dokument hat vier Felder:
| Feld | Typ |
|---|---|
| `Titel` | Text |
| `Beschreibung` | Text |
| `Marke` | Keyword |
| `Kategorie` | Keyword |
Der Datensatz wird aus dataset.csv geladen.
Die Stärken und Grenzen der lexikalischen Suche
BM25 ist der Standard-Ranking-Algorithmus in Elasticsearch und den meisten Suchmaschinen. Er bewertet Dokumente danach, wie oft Ihre Abfragebegriffe darin erscheinen, angepasst an die Dokumentlänge und die Häufigkeit dieser Begriffe im gesamten Index. Sie erhalten zusätzlich Analyzer: Kleinschreibungsnormalisierung, Stemming und Stoppwort-Entfernung. Eine Suchanfrage nach „Laufschuhen“ liefert Treffer für „Laufschuhe“ und wahrscheinlich auch für „Laufen“.
Dies funktioniert gut für eine große Gruppe von Abfragen:
- „Laufschuhe“ findet sofort Produkte, die genau diesen Begriff im Titel enthalten.
- „Bluetooth-Lautsprecher“ taucht bei tragbaren Audioprodukten auf, weil die Token wortwörtlich erscheinen.
Die Ergebnisse sind deterministisch und erklärbar: Ein Dokument rangiert hoch, weil die Abfragebegriffe darin erscheinen. Die Relevanzprüfung ist unkompliziert.
Wo es fehlschlägt
Nun probieren wir diese Abfragen mit demselben Katalog aus:
- „Hautpflege-Routine“: Das Wort „Routine“ kommt in keinem Produkttitel vor. BM25 kann teilweise mit „Hautpflege“ abgestimmt werden, aber Gesichtsseren, Körperöle und Feuchtigkeitscremes werden mit Begriffen wie „Vitamin C“, „Retinol“ oder „Strahlkraft“ beschrieben, von denen sich keine mit der Abfrage überschneidet. Produkte, die eine vollständige Hautpflegeroutine darstellen, sind über den Index verstreut, ohne ein gemeinsames verankerndes Token.
- „Reisezubehör für Haustiere“: Dies ist eine Anwendungsfall-Gruppierung, keine Produktkategorie. Eine Hundetragetasche, ein Autositz für Haustiere und eine Transportbox sind alle relevant, aber in ihren Beschreibungen geht es eher um Tragbarkeit, Sicherheit und Komfort als um „Reisezubehör“. BM25 stimmt weitgehend mit „Haustier“ überein, hat aber kein Signal, um reisespezifische Produkte vom Rest des Haustierkatalogs zu unterscheiden.
Das ist ein Abrufproblem. Die relevanten Dokumente finden sich in Ihrem Index. BM25 kann sie einfach nicht finden, weil die Wörter des Nutzers und die Wörter des Dokuments nicht genau genug übereinstimmen.
Das Hinzufügen von Synonymen hilft bei bekannten Fällen. Man kann aber nicht alle Möglichkeiten aufzählen, wie ein Nutzer seine Absicht ausdrücken könnte. An dieser Stelle kommen Vektoren ins Spiel.
Warum Sie die Abruf-Rate messen sollten
Bevor Sie ein Problem beheben, müssen Sie es quantifizieren.
Recall@k misst, wie viele der Dokumente, die Ihre Nutzer tatsächlich suchen, tatsächlich in Ihren Suchergebnissen erscheinen. Formell:
Precision@k misst die besten k-Ergebnisse und wie viele tatsächlich relevant sind:
Hohe Präzision bedeutet, dass die Ergebnisse gut sind. Im E-Commerce ist es oft schlimmer, ein relevantes Produkt zu übersehen (niedrige Abruf-Werte), als ein nicht ganz perfektes Ergebnis anzuzeigen (geringere Präzision), denn ein verstecktes Produkt ist ein verlorener Verkauf.
Mit der rank_eval-API von Elasticsearch können Sie beides systematisch messen. Sie stellen eine Liste von Abfragen mit jeweils einer Reihe von bewerteten Dokumenten zur Verfügung, und Elasticsearch berechnet für Sie die Metriken für alle Abfragen.
Die Bewertung einrichten
Die rank_eval API benötigt einen Bewertungsdatensatz: ein Mapping von Abfragen zu den Dokumenten, die jeweils relevant sind, zusammen mit einer Relevanznote (0 = nicht relevant, 1 = relevant, 2 = sehr relevant).
Im Notebook ist dies die Bewertungsliste:
Die Mischung ist beabsichtigt: q1 ist eine Abfrage, die BM25 gut verarbeiten kann (exakte Tokens in Produkttiteln), während q2, q3 und q4 absichtsbasierte Abfragen sind, bei denen die Absicht des Nutzers als Konzept und nicht als spezifische Produktschlüsselwörter ausgedrückt wird.
Messung des BM25-Baseline-Abrufs
Richten Sie zuerst den Elasticsearch-Client ein und indexieren Sie die Rohtextdaten:
Erstellen Sie nun die rank_eval-Abfrage für BM25. Jede Abfrage in der Liste kombiniert eine Abfrage mit ihren Bewertungen:
Ergebnis:
0.43 Das bedeutet, dass BM25 bei allen vier Abfragen nur 43 % der Dokumente findet, die es finden sollte. Das Defizit konzentriert sich auf die absichtsbasierten Suchanfragen: Bei der Suche nach „Hautpflegeroutine“ werden Gesichtsseren und Körperöle nicht erfasst, da „Routine“ nie in den Produkttiteln vorkommt, und bei der Suche nach „Reisezubehör für Haustiere“ werden themenfremde Haustierprodukte gefunden, während Transportboxen und -käfige, die eher im Hinblick auf Tragbarkeit und Sicherheit als auf „Reisezubehör“ beschrieben werden, nicht erfasst werden.
Dies ist unsere Referenzgrundlage. Jetzt haben wir eine Zahl, die es zu übertreffen gilt.
Vektorsuche mit Jina-Embeddings hinzufügen
Vector search Dokumente und Abfragen werden als hochdimensionale Vektoren kodiert, eine Art von Vektor, der aus Hunderten oder Tausenden numerischer Werte besteht, wobei jeder Wert ein spezifisches Feature der dargestellten Daten kodiert. Dokumente mit ähnlicher Bedeutung befinden sich im Vektorraum nahe beieinander, selbst wenn sie keine gemeinsamen Wörter enthalten. „Fitnessgeräte“ und „Hantelset“ werden sich in unmittelbarer Nähe befinden, da die Konzepte miteinander verwandt sind. Ich habe Elasticsearch als meine Vektordatenbank gewählt, da es die hybride Suche unterstützt und mir sowohl semantisches Verständnis als auch präzise Stichwortsuche direkt bietet.
EIS bietet eine fertige Unterstützung für das Einbetten von Modellen über seine Inferenz-API.
Schritt 1: Verwendung von Jina-Embeddings v5 als Inferenz-Endpoint
Wenn Ihr Cluster GPU-Ressourcen hat (verfügbar in Elastic Cloud und Elasticsearch 9.3+), werden die Einbettungen auf GPU generiert, was deutlich schneller ist als die CPU-Inferenz und den Leistungskompromiss beseitigt, der Vektoren historisch im großen Maßstab teuer gemacht hat.
Warum genau Jina-Einbettungen? jina-embeddings-v5-text ist ein mehrsprachiges Modell (über 119 Sprachen) mit einem Kontextfenster von 32.000 Token und Unterstützung für aufgabenspezifische Low-Rank Adaptation (LoRA) Adapter. Es eignet sich hervorragend für kurze Produktbeschreibungen. Erfahren Sie mehr über das jina-embeddings-v5-text-Modell hier.
Schritt 2: Erstellen Sie den Index mit einem semantischen Feld
Der semantic_text-Feldtyp ist hier der Schlüssel. Es handelt sich um eine Abstraktion auf höherer Ebene über dense_vector: Sie verweisen auf einen Inferenz-Endpoint, und Elasticsearch kümmert sich automatisch um die Generierung von Einbettungen.
Die copy_to-Eigenschaft auf title und description bedeutet, dass Inhalte aus beiden Feldern in semantic_field zur Einbettung fließen, sodass ein einzelner Vektor die vollständige Produktdarstellung erfasst.
Schritt 3: Produkte indexieren
Zur Indexzeit ruft Elasticsearch für jedes Dokument den Inferenz-Endpoint auf und speichert die resultierende Einbettung in semantic_field. Kein zusätzlicher Code für Sie erforderlich.
Hybridsuche: Kombination von BM25 und Vektoren mit RRF
Das Hinzufügen von Vektoren verbessert den Abruf, aber die Verwendung von Vektoren allein birgt das Risiko, dass die Präzision bei exakten Übereinstimmungen auf der Strecke bleibt. „Laufschuhe“ sollten immer noch wortwörtliche Übereinstimmungen an erster Stelle einordnen. Die Hybridsuche behält die lexikalische Komponente bei, um diese Präzision zu erhalten.
Hybride Suche mit Reciprocal Rank Fusion (RRF) kombiniert das Beste von beidem:
- BM25 verarbeitet exakte und nahezu exakte Abfragen mit hoher Präzision.
- Die semantische Suche bewältigt absichtsbasierte und mehrsprachige Abfragen mit hoher Trefferquote.
- RRF kombiniert die beiden Ranglisten zu einer einzigen Rangliste.
Die RRF-Formel weist jedem Dokument eine Bewertung basierend auf seinem Rang in jeder Ergebnisliste zu:
Ein Dokument, das in beiden Listen einen hohen Rang einnimmt, erhält eine höhere kombinierte Punktzahl. rank_constant steuert, wie viel Gewicht Dokumente mit niedrigerem Rang erhalten.
Ergebnis:
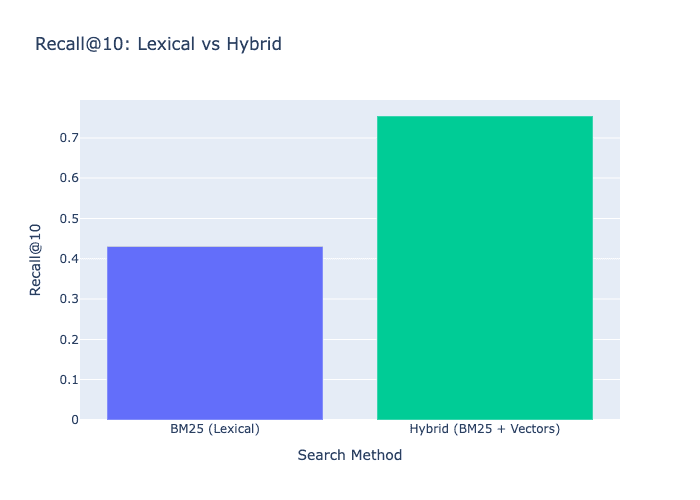
Hybrid verbessert sich erheblich gegenüber BM25 (0.43) und erhält die Präzision für exakte Treffer bei Abfragen wie „Laufschuhe“ bei.
Ergebnisse: Vorher und Nachher
Hier der vollständige Vergleich aller drei Ansätze:
Ergebnis:
| Methode | Recall@10 |
|---|---|
| BM25 (Lexikalisch) | 0,43 |
| Hybrid (BM25 + Vektoren) | 0,75 |
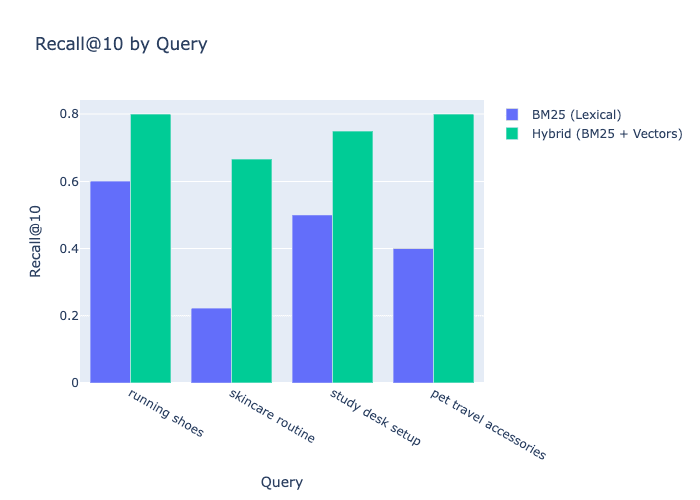
Aufschlüsselung nach Abfragen:
Fazit
Im Laufe dieses Beitrags haben wir erfahren, dass die lexikalische BM25-Suche zuverlässig ist, wenn Nutzer exakte Suchanfragen eingeben, aber an Treffsicherheit verliert, wenn sie nach Suchintention statt nach Schlüsselwörtern suchen. Mit rank_evalhaben wir eine reproduzierbare Basislinie festgelegt, um diese Lücke mit reellen Zahlen zu messen. Von dort aus haben wir ein semantic_text Feld hinzugefügt, das von Jina-Einbettungen unterstützt wird, und die Bewertung erneut durchgeführt. Das Ergebnis: Die Hybridsuche verbesserte die Trefferquote von 0.43 auf 0.75, während die Genauigkeit bei exakten Suchabfragen erhalten blieb. Die tatsächliche Verbesserung hängt jedoch von der Zusammensetzung Ihrer Suchabfragen ab.
Das Muster lässt sich über dieses Beispiel hinaus skalieren: Sammeln Sie Relevanzurteile aus den tatsächlichen Abfragen Ihrer Nutzer, führen Sie rank_eval als Baseline aus, fügen Sie semantic_text hinzu und messen Sie erneut. Sie wissen genau, was sich verbessert hat und um wie viel.
Wie geht es weiter?
- Tauchen Sie tiefer in Abruf und Vektorsuche ein: Recall and Vector Search Quantization von Jeff Vestal
- Fügen Sie ein Reranking hinzu, um die besten Ergebnisse noch präziser zu ermitteln
- Erkunden Sie die Elasticsearch-Dokumentation zur Hybridsuche
- Erfahren Sie mehr über
rank_evalAPI
Zugehörige Inhalte

23. April 2026
Wie wir Elasticsearch simdvec entwickelten, um die Vektorsuche zu einer der schnellsten weltweit zu machen
Wie wir Elasticsearch simdvec entwickelten, die von Hand optimierte SIMD-Kernel-Bibliothek hinter jeder Vektorsuchanfrage in Elasticsearch.

2. April 2026
Wenn TSDS auf ILM trifft: Gestaltung von Zeitreihendatenströmen, die verspätete Daten nicht ablehnen
Interaktion zwischen den Zeitgrenzen von TSDS und den ILM-Phasen und Erstellung von Richtlinien, die verspätet eintreffende Metriken tolerieren.

1. April 2026
LINQ to Elasticsearch ES|QL: C# schreiben, Elasticsearch abfragen
Erkundung des neuen LINQ to Elasticsearch ES|QL-Providers im Elasticsearch .NET-Client, mit dem Sie C#-Code schreiben können, der automatisch in ES|QL-Abfragen übersetzt wird.

20. März 2026
Schnell vs. genau: Messung der Recall-Rate bei der quantisierten Vektorsuche
Eine Erklärung, wie der Recall für die Vektorsuche in Elasticsearch mit minimalem Aufwand gemessen werden kann.

13. März 2026
Entitätsauflösung mit Elasticsearch, Teil 4: Die ultimative Herausforderung
Lösung und Bewertung von Herausforderungen bei der Entitätsauflösung in einem äußerst vielfältigen Datensatz zur „ultimativen Herausforderung“, der entwickelt wurde, um Abkürzungen zu verhindern.