Einleitung
In einer Welt globaler Nutzer ist die sprachübergreifende Informationswiedergewinnung (CLIR) von entscheidender Bedeutung. Anstatt die Suche auf eine einzige Sprache zu beschränken, ermöglicht CLIR das Auffinden von Informationen in jeder beliebigen Sprache, verbessert so die Benutzerfreundlichkeit und optimiert die Abläufe. Stellen Sie sich einen globalen Markt vor, auf dem E-Commerce-Kunden in ihrer Sprache nach Artikeln suchen können und die passenden Ergebnisse angezeigt werden, ohne dass die Daten vorher lokalisiert werden müssen. Oder, um akademischen Forschern die Möglichkeit zu geben, in ihrer Muttersprache nach wissenschaftlichen Artikeln zu suchen, inklusive aller Nuancen und Komplexitäten, selbst wenn die Quelle in einer anderen Sprache verfasst ist.
Mehrsprachige Text-Embedding-Modelle ermöglichen uns genau das. Einbettungen sind eine Möglichkeit, die Bedeutung von Text als numerische Vektoren darzustellen. Diese Vektoren sind so konzipiert, dass Texte mit ähnlicher Bedeutung in einem hochdimensionalen Raum nahe beieinander liegen. Multilinguale Text-Embedding-Modelle sind speziell dafür entwickelt worden, Wörter und Phrasen mit der gleichen Bedeutung in verschiedenen Sprachen in einen ähnlichen Vektorraum abzubilden.
Modelle wie das Open-Source-Multilingual E5 werden mit riesigen Mengen an Textdaten trainiert, oft unter Verwendung von Techniken wie dem kontrastiven Lernen. Bei diesem Ansatz lernt das Modell, zwischen Textpaaren mit ähnlicher Bedeutung (positive Paare) und solchen mit unähnlicher Bedeutung (negative Paare) zu unterscheiden. Das Modell wird so trainiert, dass die von ihm erzeugten Vektoren so angepasst werden, dass die Ähnlichkeit zwischen positiven Paaren maximiert und die Ähnlichkeit zwischen negativen Paaren minimiert wird. Bei mehrsprachigen Modellen umfassen diese Trainingsdaten Textpaare in verschiedenen Sprachen, die Übersetzungen voneinander sind, wodurch das Modell einen gemeinsamen Repräsentationsraum für mehrere Sprachen erlernen kann. Die resultierenden Einbettungen können dann für verschiedene NLP-Aufgaben verwendet werden, darunter die sprachübergreifende Suche, bei der die Ähnlichkeit zwischen Texteinbettungen genutzt wird, um relevante Dokumente unabhängig von der Sprache der Anfrage zu finden.
Vorteile der mehrsprachigen Vektorsuche
- Nuance: Die Vektorsuche zeichnet sich durch ihre Fähigkeit aus, semantische Bedeutungen zu erfassen und geht über die reine Stichwortsuche hinaus. Dies ist von entscheidender Bedeutung für Aufgaben, die das Verständnis von Kontext und sprachlichen Feinheiten erfordern.
- Sprachübergreifendes Verständnis: Ermöglicht einen effektiven Informationsabruf über verschiedene Sprachen hinweg, selbst wenn die Suchanfrage und die Dokumente unterschiedliches Vokabular verwenden.
- Relevanz: Liefert relevantere Ergebnisse durch Fokussierung auf die konzeptionelle Ähnlichkeit zwischen Suchanfragen und Dokumenten.
Nehmen wir beispielsweise einen akademischen Forscher, der den „Einfluss sozialer Medien auf den politischen Diskurs“ in verschiedenen Ländern untersucht. Mit der Vektorsuche können sie Suchanfragen wie „l'impatto dei social media sul discorso politico“ (Italienisch) oder „ảnh hưởng của mạng xã hội đối với diễn ngôn chính trị“ (Vietnamesisch) eingeben und relevante Artikel auf Englisch, Spanisch oder einer anderen Sprache finden indizierte Sprache. Dies liegt daran, dass die Vektorsuche Artikel identifiziert, die das Konzept des Einflusses sozialer Medien auf die Politik diskutieren, und nicht nur solche, die die exakten Schlüsselwörter enthalten. Dies erweitert und vertieft die Bandbreite ihrer Forschung erheblich.
Erste Schritte
Hier erfahren Sie, wie Sie CLIR mit Elasticsearch einrichten – mit dem E5-Modell, das standardmäßig mitgeliefert wird. Wir verwenden den Open-Source-Datensatz COCO, der Bildunterschriften in mehreren Sprachen enthält, um zwei Arten von Suchanfragen zu visualisieren:
- Suchanfragen und Suchbegriffe in anderen Sprachen für einen englischen Datensatz, und
- Abfragen in mehreren Sprachen auf einem Datensatz, der Dokumente in mehreren Sprachen enthält.
Anschließend werden wir die Leistungsfähigkeit der hybriden Suche und des Rerankings nutzen, um die Suchergebnisse noch weiter zu verbessern.
Voraussetzungen
- Python 3.6+
- Elasticsearch 8+
- Elasticsearch Python-Client: pip install elasticsearch
Datensatz
Der COCO-Datensatz ist ein umfangreicher Datensatz zur Untertitelung. Jedes Bild im Datensatz ist in mehreren verschiedenen Sprachen beschriftet, wobei für jede Sprache mehrere Übersetzungen verfügbar sind. Zur Veranschaulichung werden wir jede Übersetzung als einzelnes Dokument indexieren, zusammen mit der ersten verfügbaren englischen Übersetzung als Referenz.
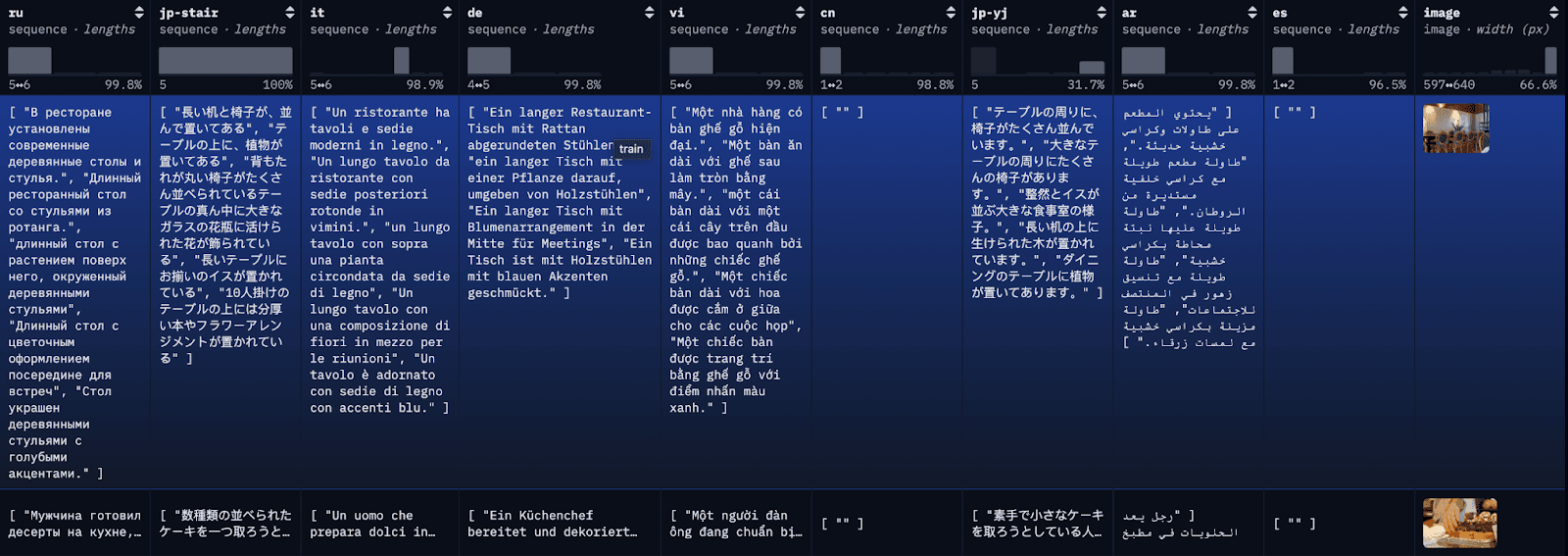
Schritt 1: Laden Sie den mehrsprachigen COCO-Datensatz herunter
Um den Blog zu vereinfachen und das Nachvollziehen zu erleichtern, laden wir hier die ersten 100 Zeilen der Restval-Tabelle mit einem einfachen API-Aufruf in eine lokale JSON-Datei. Alternativ können Sie die Datensätze der HuggingFace-Bibliothek verwenden, um den vollständigen Datensatz oder Teilmengen des Datensatzes zu laden.
Wenn die Daten erfolgreich in eine JSON-Datei geladen wurden, sollte die Ausgabe in etwa so aussehen:
Data successfully downloaded and saved to multilingual_coco_sample.json
Schritt 2: (Elasticsearch starten) und die Daten in Elasticsearch indizieren
a) Starten Sie Ihren lokalen Elasticsearch-Server.
b) Starten Sie den Elasticsearch-Client.
c) Indexdaten
Sobald die Daten indexiert sind, sollte etwa Folgendes angezeigt werden:
Successfully bulk indexed 4840 documents
Indexing complete!
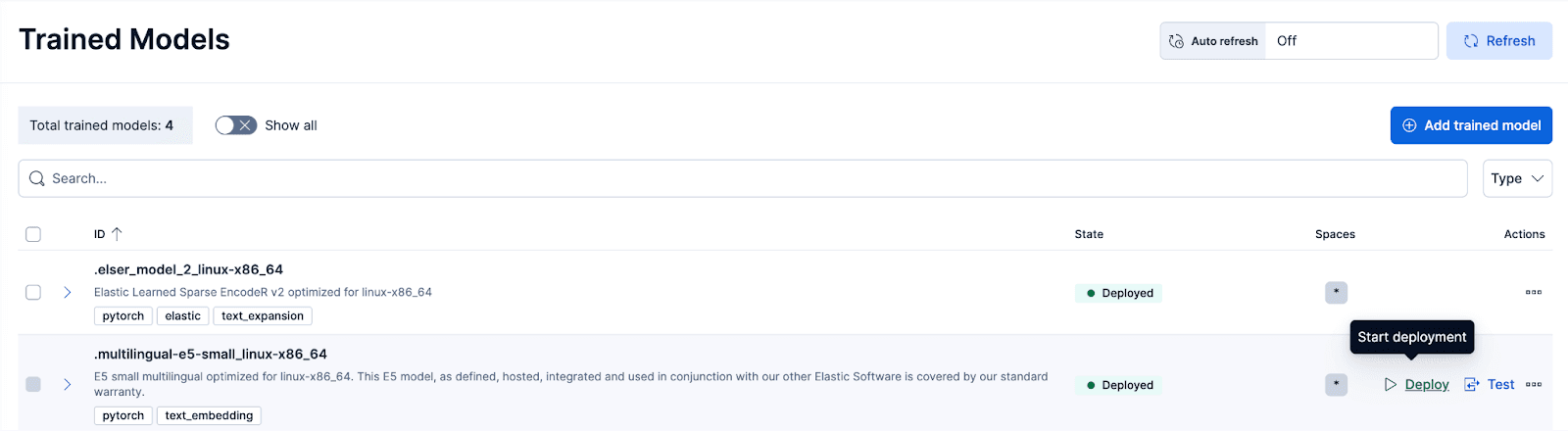
Schritt 3: Das mit E5 trainierte Modell bereitstellen
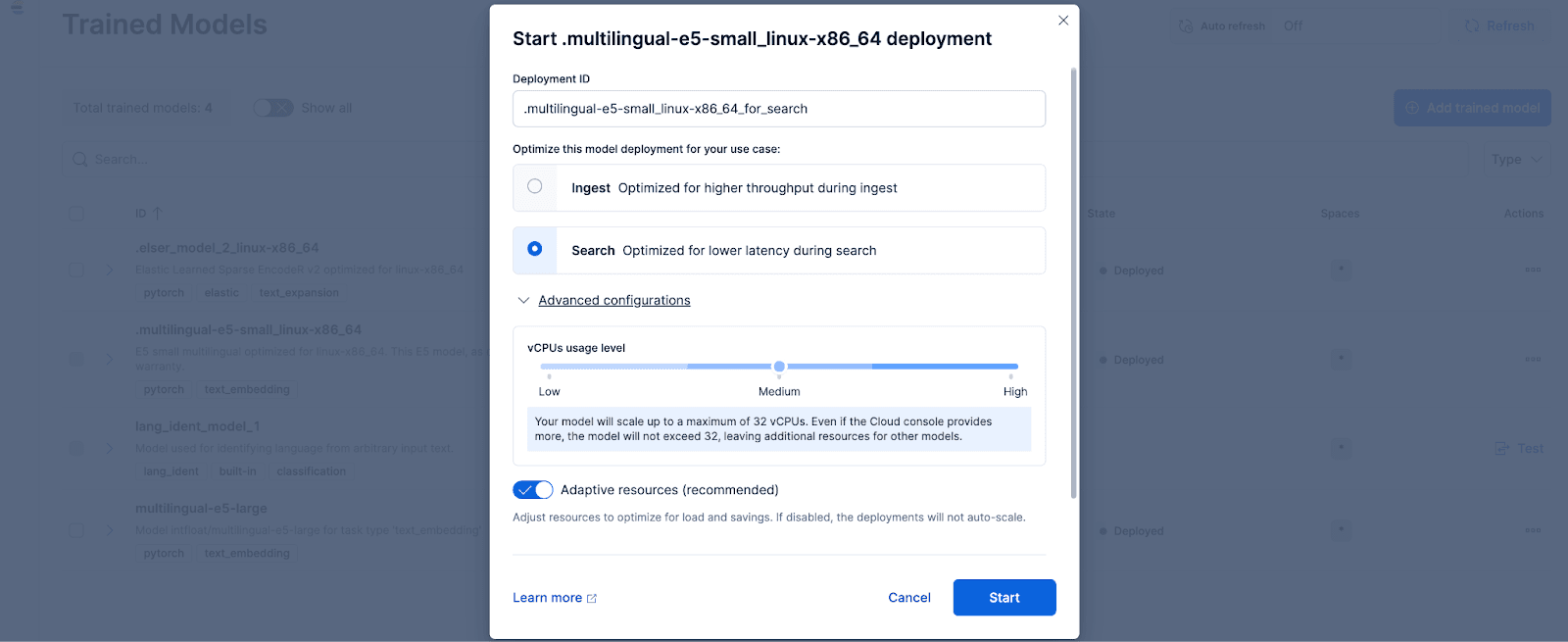
Navigieren Sie in Kibana zur Seite „Stack-Verwaltung > Trainierte Modelle“ und klicken Sie für das Modell „.multilingual-e5-small_linux-x86_64“ auf „Bereitstellen“ . Option. Dieses E5-Modell ist ein kleines, mehrsprachiges Gerät, das für linux-x86_64 optimiert ist und sofort einsatzbereit ist. Durch Klicken auf „Bereitstellen“ wird ein Bildschirm angezeigt, auf dem Sie die Bereitstellungseinstellungen oder vCPU-Konfigurationen anpassen können. Der Einfachheit halber verwenden wir die Standardoptionen mit der Auswahl adaptiver Ressourcen, wodurch unsere Bereitstellung je nach Nutzung automatisch skaliert wird.
Optional können Sie auch andere Text-Embedding-Modelle verwenden. Um beispielsweise BGE-M3 zu verwenden, können Sie den Eland Python-Client von Elastic verwenden, um das Modell von HuggingFace zu importieren.
Navigieren Sie anschließend zur Seite „Trainierte Modelle“, um das importierte Modell mit den gewünschten Konfigurationen bereitzustellen.
Schritt 4: Vektorisieren oder Einbettungen für die Originaldaten mit dem bereitgestellten Modell erstellen
Um die Einbettungen zu erstellen, müssen wir zunächst eine Ingest-Pipeline erstellen, die es uns ermöglicht, den Text zu nehmen und ihn durch das Inferenz-Texteinbettungsmodell laufen zu lassen. Dies ist über die Benutzeroberfläche von Kibana oder über die API von Elasticsearch möglich.
Um dies über die Kibana-Oberfläche zu tun, klicken Sie nach dem Bereitstellen des trainierten Modells auf die Schaltfläche „Testen “. Dies ermöglicht es Ihnen, die generierten Einbettungen zu testen und eine Vorschau anzuzeigen. Erstellen Sie eine neue Datenansicht für coco Index, Datenansicht auf die neu erstellte Coco-Datenansicht setzen und Feld auf description setzen, da dies das Feld ist, für das wir Einbettungen generieren möchten.
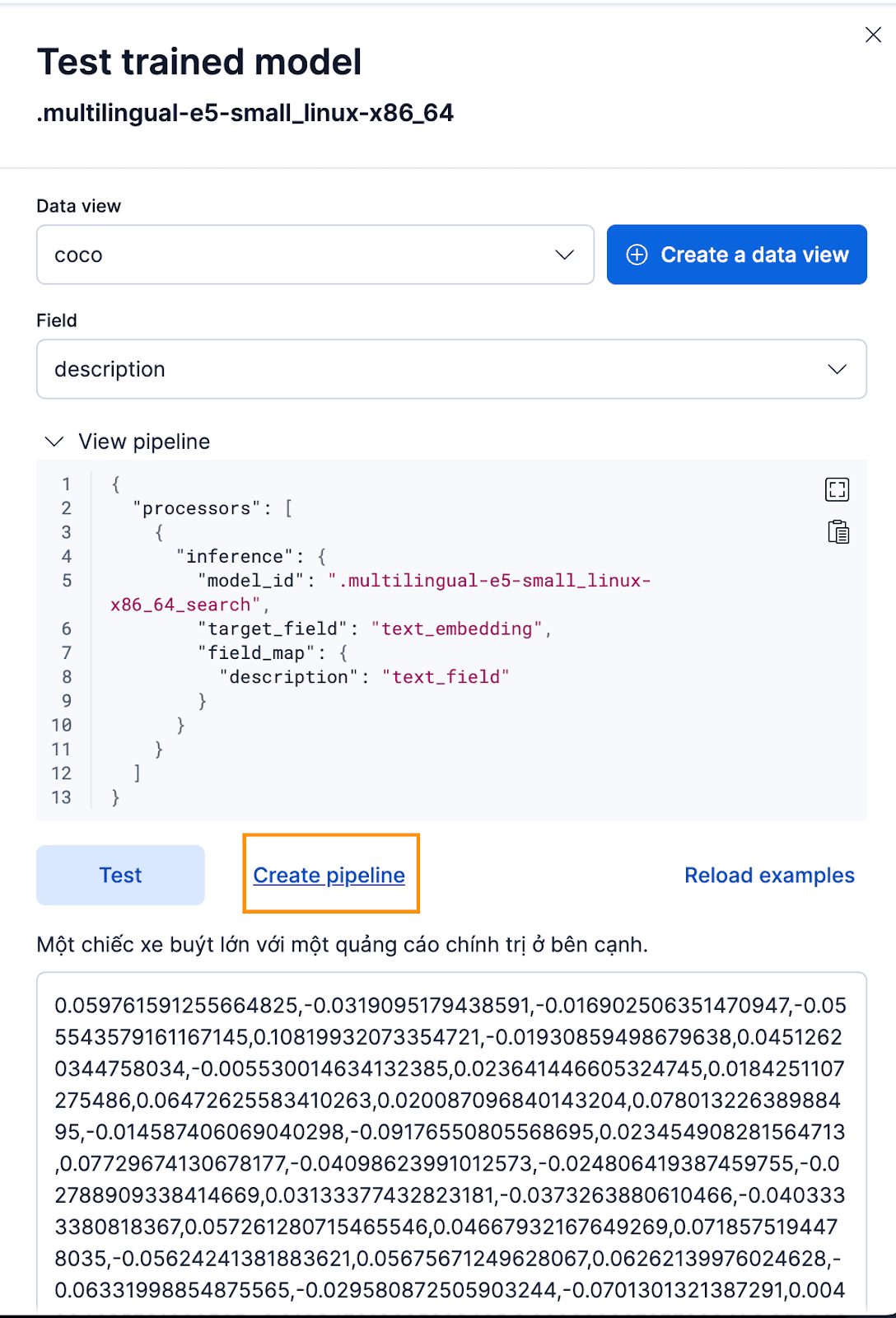
Das funktioniert hervorragend! Nun können wir mit der Erstellung der Ingest-Pipeline fortfahren und unsere Originaldokumente neu indizieren, sie durch die Pipeline leiten und einen neuen Index mit den Einbettungen erstellen. Dies erreichen Sie durch Klicken auf „Pipeline erstellen“. Sie werden dann durch den Erstellungsprozess der Pipeline geführt, wobei automatisch die benötigten Prozessoren zur Erstellung der Einbettungen bereitgestellt werden.
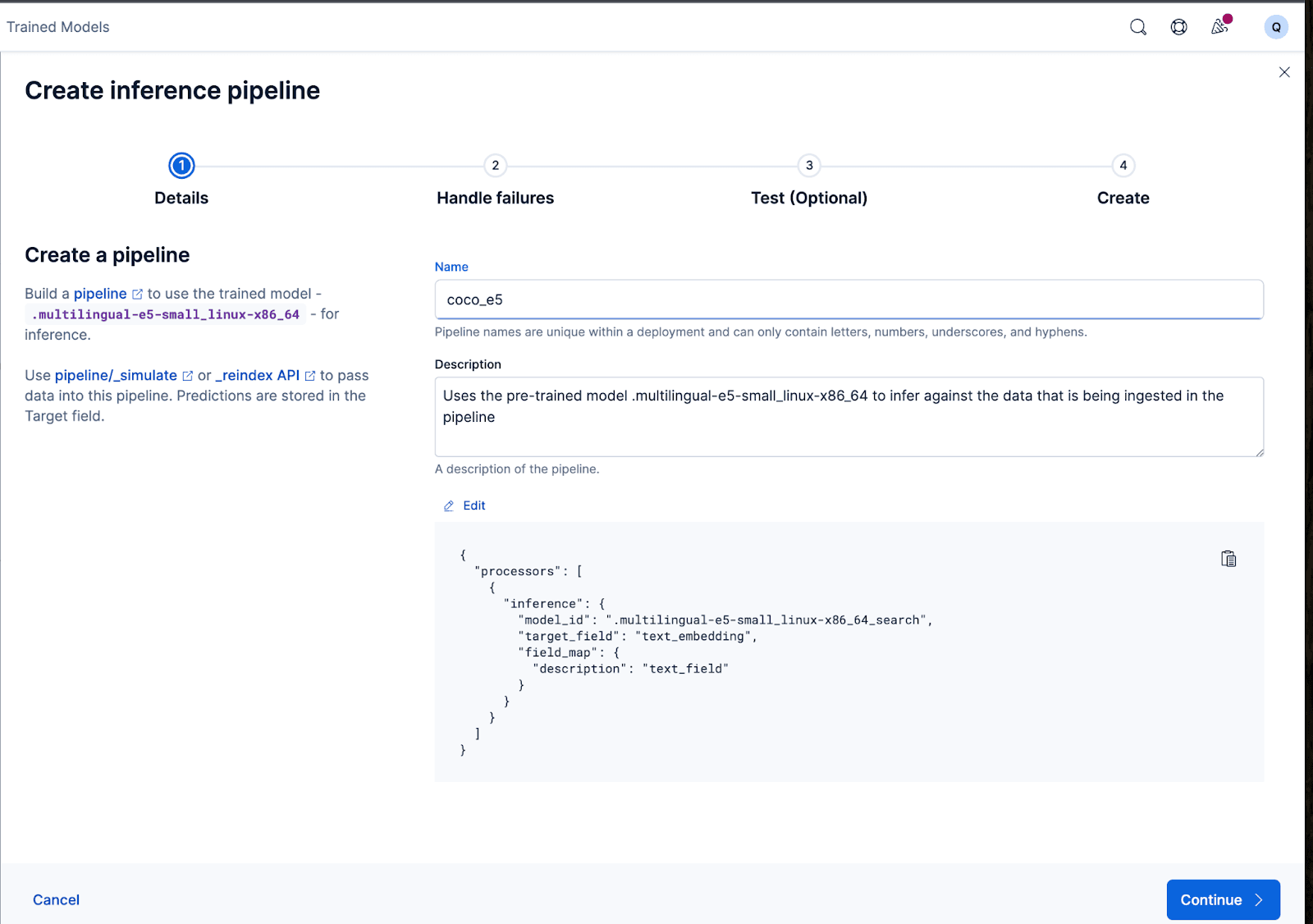
Der Assistent kann außerdem automatisch die Prozessoren eintragen, die zur Fehlerbehebung während der Datenerfassung und -verarbeitung benötigt werden.
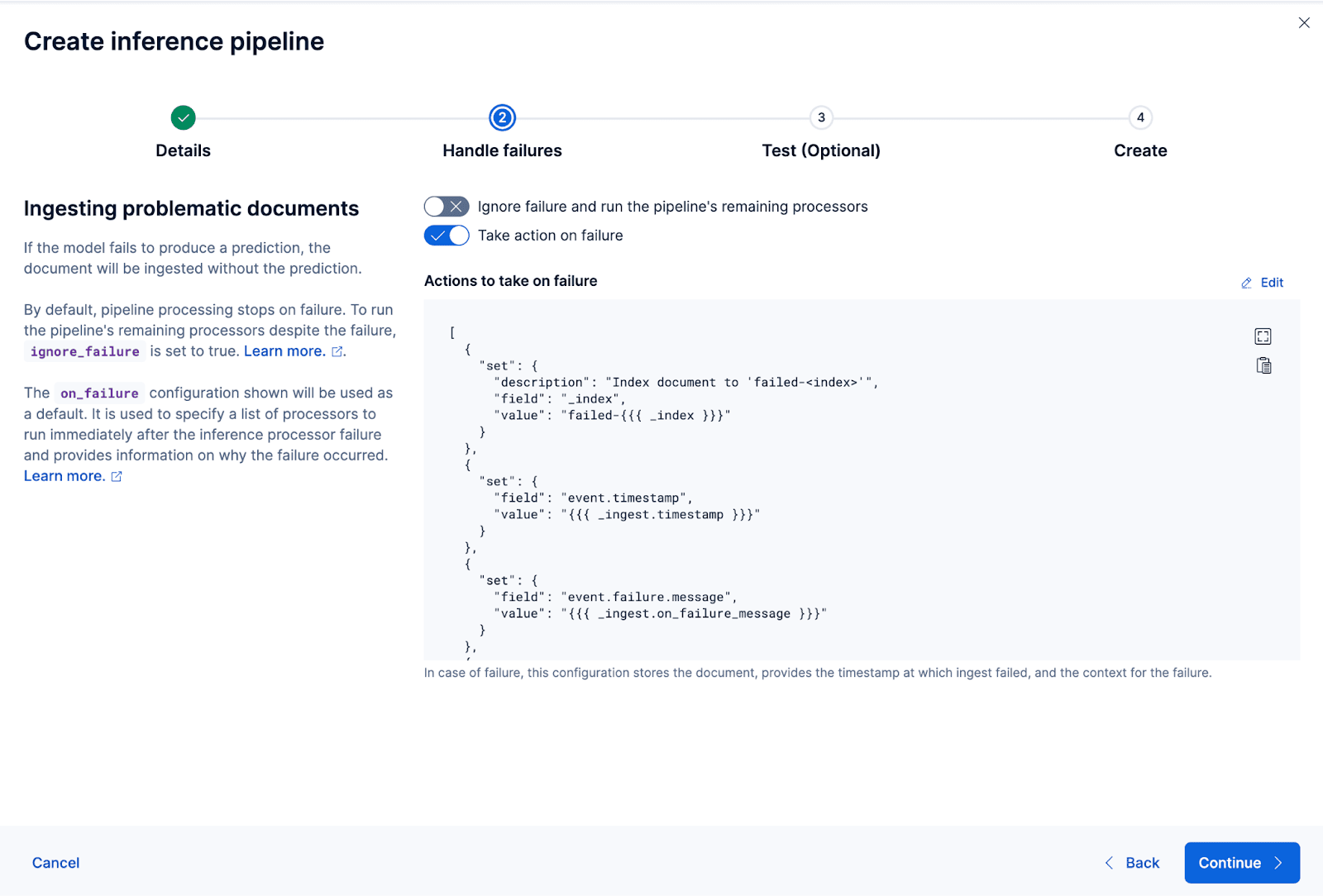
Erstellen wir nun die Ingest-Pipeline. Ich nenne die Pipeline coco_e5. Sobald die Pipeline erfolgreich erstellt wurde, können Sie sie sofort verwenden, um die Einbettungen zu generieren, indem Sie die ursprünglich indizierten Daten im Assistenten in einen neuen Index umindizieren. Klicken Sie auf „Neu indizieren“ , um den Vorgang zu starten.
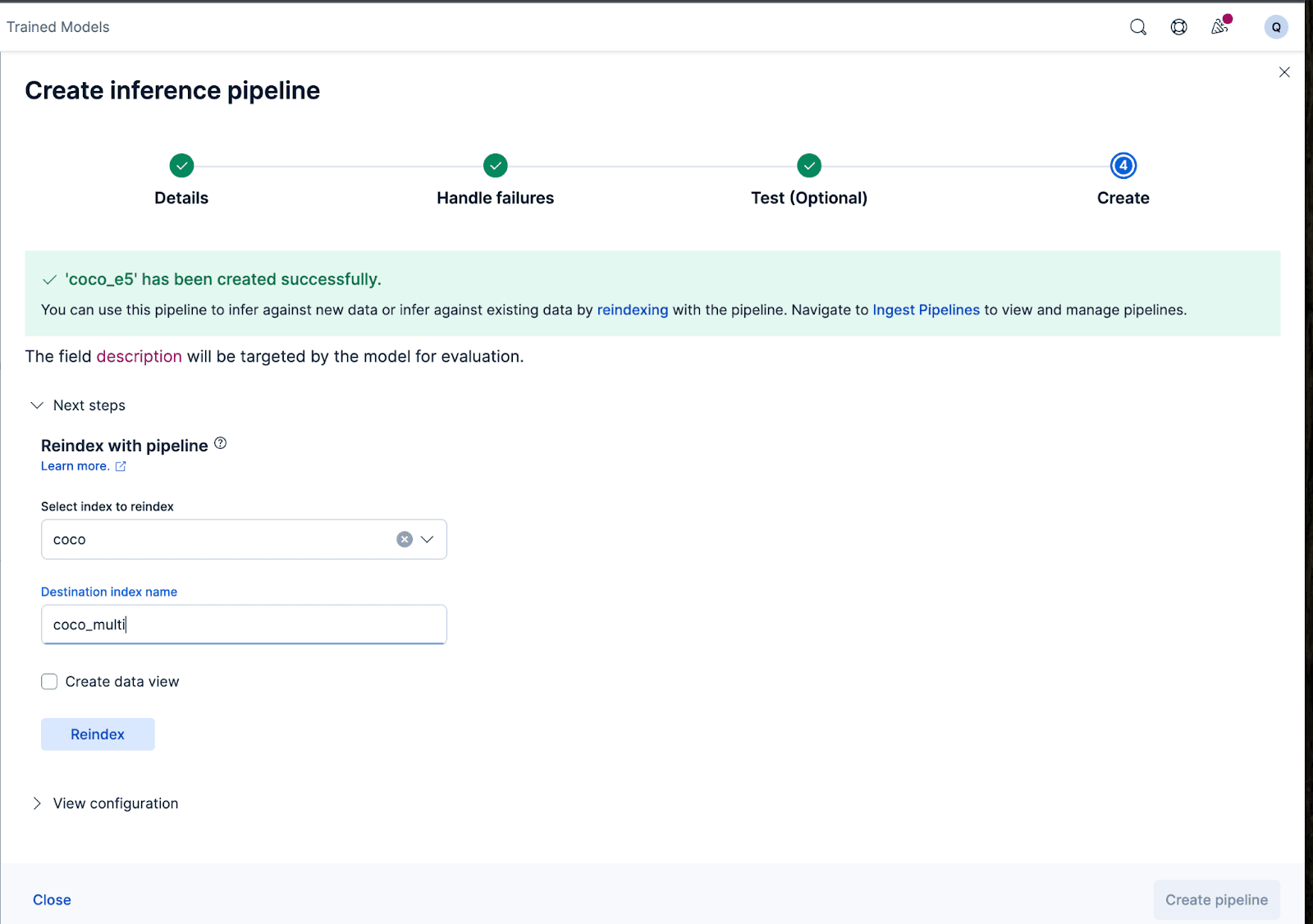
Für komplexere Konfigurationen können wir die Elasticsearch-API verwenden.
Bei einigen Modellen kann es aufgrund der Art und Weise, wie die Modelle trainiert wurden, erforderlich sein, bestimmte Texte vor oder nach dem eigentlichen Input einzufügen, bevor die Einbettungen generiert werden; andernfalls kommt es zu einer Leistungsverschlechterung.
Beim Modell e5 erwartet man beispielsweise, dass der Eingabetext dem Format „passage: {content of passage}“ folgt. Um das zu erreichen, nutzen wir die Ingest-Pipelines: Wir erstellen eine neue Ingest-Pipeline vectorize_descriptions. In dieser Pipeline erstellen wir ein neues temporäres Feld temp_desc , fügen dem Text description „passage: “ voran, führen temp_desc das Modell aus, um Text-Embeddings zu generieren, und löschen dann temp_desc.
Darüber hinaus möchten wir möglicherweise festlegen, welche Art der Quantisierung wir für den generierten Vektor verwenden möchten. Standardmäßig verwendet Elasticsearch int8_hnsw, aber hier möchte ich Better Binary Quantization (oder bqq_hnsw), wodurch jede Dimension auf eine Einzelbitgenauigkeit reduziert wird. Dadurch wird der Speicherbedarf um 96 % (oder um das 32-Fache) reduziert, allerdings auf Kosten der Genauigkeit. Ich entscheide mich für diese Quantisierungsart, weil ich weiß, dass ich später einen Reranker verwenden werde, um den Genauigkeitsverlust zu verbessern.
Dazu erstellen wir einen neuen Index mit dem Namen coco_multi und legen die Zuordnungen fest. Die Magie liegt hier im Feld vector_description, wo wir den Typ von index_optionsauf bbq_hnsw festlegen.
Nun können wir die Originaldokumente in einem neuen Index neu indizieren, wobei unsere Ingest-Pipeline das Beschreibungsfeld „vektorisiert“ oder Einbettungen erstellt.
Und das war's! Wir haben erfolgreich ein mehrsprachiges Modell mit Elasticsearch und Kibana implementiert und Schritt für Schritt gelernt, wie man mit Elastic Vektoreinbettungen für seine Daten erstellt, entweder über die Kibana-Benutzeroberfläche oder mit der Elasticsearch-API. Im zweiten Teil dieser Reihe werden wir die Ergebnisse und die Feinheiten der Verwendung eines mehrsprachigen Modells untersuchen. In der Zwischenzeit können Sie einen eigenen Cloud-Cluster erstellen , um die mehrsprachige semantische Suche mit unserem sofort einsatzbereiten E5-Modell auf der Sprache und dem Datensatz Ihrer Wahl auszuprobieren.
Zugehörige Inhalte

18. Mai 2026
Agentische KI-Suche mit deterministischen Leitplanken in Elasticsearch zur sicheren Ausführung von Abfragen
Agentische KI-Suchsysteme versagen häufig, wenn LLMs Abfragen direkt generieren. Erfahren Sie, wie deterministische Leitplanken und eine Steuerungsebenenarchitektur eine sichere, zuverlässige und kontrollierte Abfrageausführung mit Elasticsearch ermöglichen.

11. Mai 2026
Personalisierung der E-Commerce-Suche: Integration von Kaufverlauf und Nutzerkohorten
Erfahren Sie, wie Sie in Elasticsearch ein personalisiertes E-Commerce-Sucherlebnis schaffen, ohne gegen die Governance-Richtlinien zu verstoßen. In diesem Beitrag erfahren Sie, wie Sie Produkte hervorheben können, die ein Kunde bereits gekauft hat, und wie Sie kohortenspezifische Richtlinien auf der Grundlage von Nutzerprofilen aktivieren können.

4. Mai 2026
Elasticsearch-Perkolator zur Steuerung der Suche im E-Commerce: Übersetzung mehrdeutiger Anfragen in kontrollierte Abrufstrategien
Erfahren Sie, wie Sie den Elasticsearch-Perkolator zur Implementierung der Suchsteuerung verwenden. In diesem Blog skizzieren wir die Muster, die erforderlich sind, um eine geregelte Policy-Engine in der Produktion zu erstellen und eine kontrollierte Abrufstrategie zu entwickeln.

1. Mai 2026
Aufbau einer Steuerungsebene zur Kontrolle der E-Commerce-Suche
Wie Sie eine kontrollierte Steuerungsebene für den elektronischen Handel aufbauen, die widersprüchliche Suchrichtlinien in einem einzigen Ausführungsplan zusammenfasst (ohne Codeänderungen).

24. April 2026
Neuindizierung von Datenströmen aufgrund von Mapping-Konflikten
Erfahren Sie, wie Sie Elasticsearch-Mapping-Konflikte durch Neuindizierung von Datenströmen beheben können. Dieser Blog erklärt den Neuindizierungsprozess und wie Sie sicherstellen, dass neue Daten korrekt zugeordnet werden.