Mit Elastic Open Web Crawler und seiner CLI-gesteuerten Architektur lassen sich versionierte Crawler-Konfigurationen und eine CI/CD-Pipeline mit lokalen Tests jetzt recht einfach realisieren.
Traditionell war die Verwaltung von Webcrawlern ein manueller, fehleranfälliger Prozess. Dabei ging es um das direkte Bearbeiten von Konfigurationen in der Benutzeroberfläche sowie um das Klonen von Crawl-Konfigurationen, das Zurücksetzen von Einstellungen, die Versionsverwaltung und vieles mehr. Die Behandlung von Crawler-Konfigurationen als Code löst dieses Problem, indem sie die gleichen Vorteile bietet, die wir von der Softwareentwicklung erwarten: Wiederholbarkeit, Nachvollziehbarkeit und Automatisierung.
Dieser Workflow erleichtert es, den Open Web Crawler in Ihre CI/CD-Pipeline für Rollbacks, Backups und Migrationen einzubinden – Aufgaben, die mit früheren Elastic Crawlern wie dem Elastic Web Crawler oder dem App Search Crawler wesentlich schwieriger waren.
In diesem Artikel erfahren Sie, wie Sie:
- Verwalten Sie unsere Crawl-Konfigurationen mit GitHub.
- Eine lokale Testumgebung für Pipelines vor der Bereitstellung einrichten
- Wir erstellen eine Produktionsumgebung, um den Webcrawler jedes Mal mit neuen Einstellungen auszuführen, wenn wir Änderungen an unseren Hauptzweig übertragen.
Das Projekt-Repository finden Sie hier. Zum Zeitpunkt der Erstellung dieses Dokuments verwende ich Elasticsearch 9.1.3 und Open Web Crawler 0.4.2.
Voraussetzungen
- Docker Desktop
- Elasticsearch-Instanz
- Virtuelle Maschine mit SSH-Zugriff (z. B. AWS EC2) und installiertem Docker
Schritte
- Ordnerstruktur
- Raupenkonfiguration
- Docker-Compose-Datei (lokale Umgebung)
- GitHub Actions
- Lokale Tests
- Bereitstellung in der Produktionsumgebung
- Änderungen vornehmen und erneut bereitstellen
Ordnerstruktur
Für dieses Projekt werden wir folgende Dateistruktur verwenden:
Raupenkonfiguration
Unter crawler-config.yml, wird Folgendes eingetragen:
Dies führt einen Crawl von https://web-scraping.dev/products durch, einer simulierten Website für Produkte. Wir werden nur die ersten drei Produktseiten durchsuchen. Die Einstellung max_crawl_depth verhindert, dass der Crawler mehr Seiten als die als seed_urls definierten Seiten entdeckt, indem er die darin enthaltenen Links nicht öffnet.
Elasticsearch host und api_key werden dynamisch befüllt, abhängig von der Umgebung, in der das Skript ausgeführt wird.
Docker-Compose-Datei (lokale Umgebung)
Für die lokale Umgebung docker-compose.yml, werden wir den Crawler und einen einzelnen Elasticsearch-Cluster + Kibana bereitstellen, damit wir unsere Crawling-Ergebnisse vor der Bereitstellung in der Produktionsumgebung einfach visualisieren können.
Beachten Sie, wie der Crawler wartet, bis Elasticsearch bereit ist, ausgeführt zu werden.
GitHub Actions
Nun müssen wir eine GitHub-Aktion erstellen, die die neuen Einstellungen kopiert und den Crawler bei jedem Push auf den Hauptzweig in unserer virtuellen Maschine ausführt. Dadurch wird sichergestellt, dass wir immer die aktuellste Konfiguration im Einsatz haben, ohne manuell in die virtuelle Maschine eingreifen zu müssen, um Dateien zu aktualisieren und den Crawler auszuführen. Wir werden AWS EC2 als Anbieter virtueller Maschinen verwenden.
Der erste Schritt besteht darin, den Host (VM_HOST), den Maschinenbenutzer (VM_USER), den SSH-RSA-Schlüssel (VM_KEY), den Elasticsearch-Host (ES_HOST) und den Elasticsearch-API-Schlüssel (ES_API_KEY) zu den GitHub Action Secrets hinzuzufügen:
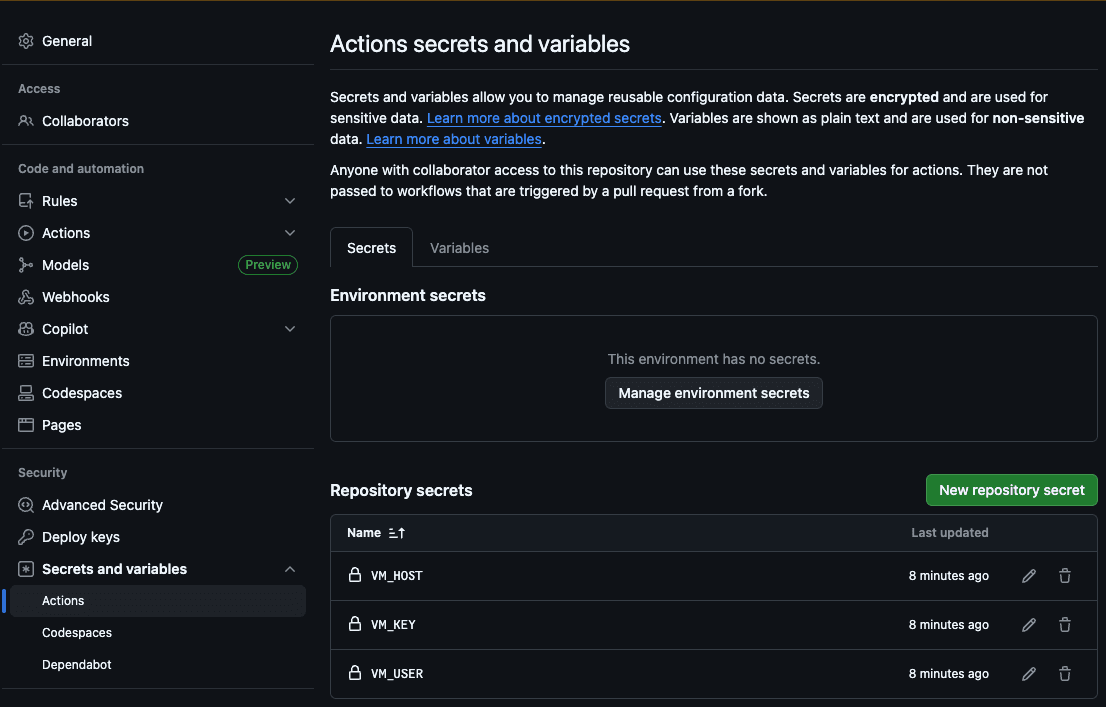
Auf diese Weise kann die Aktion auf unseren Server zugreifen, um die neuen Dateien zu kopieren und den Crawl auszuführen.
Nun erstellen wir unsere .github/workflows/deploy.yml -Datei:
Diese Aktion führt jedes Mal die folgenden Schritte aus, wenn wir Änderungen an der Crawler-Konfigurationsdatei vornehmen:
- Tragen Sie den Elasticsearch-Host und den API-Schlüssel in die YAML-Konfiguration ein.
- Kopieren Sie den Konfigurationsordner auf unsere VM
- Stellen Sie über SSH eine Verbindung zu unserer VM her.
- Führen Sie den Crawl mit der Konfiguration aus, die wir gerade aus dem Repository kopiert haben.
Lokale Tests
Um unseren Crawler lokal zu testen, haben wir ein Bash-Skript erstellt, das den Elasticsearch-Host mit dem lokalen Docker-Repository befüllt und einen Crawl startet. Sie können ./local.sh eingeben, um es auszuführen.
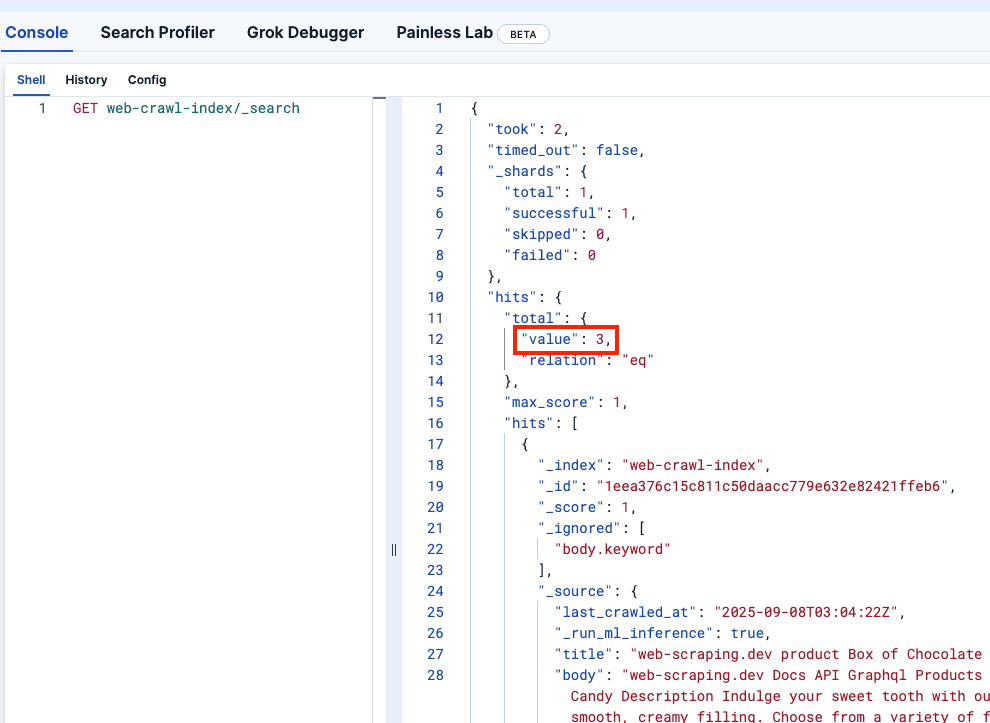
Schauen wir uns die Kibana DevTools an, um zu bestätigen, dass web-crawler-index korrekt befüllt wurde:
Bereitstellung in der Produktionsumgebung
Jetzt sind wir bereit, die Änderungen auf den Hauptzweig zu übertragen. Dadurch wird der Crawler in Ihrer virtuellen Maschine bereitgestellt und beginnt, Protokolle an Ihre Serverless Elasticsearch-Instanz zu senden.
Dadurch wird die GitHub-Aktion ausgelöst, die das Bereitstellungsskript innerhalb der virtuellen Maschine ausführt und mit dem Crawling beginnt.
Sie können die Ausführung der Aktion überprüfen, indem Sie zum GitHub-Repository gehen und den Tab „Aktionen“ aufrufen:

Änderungen vornehmen und erneut bereitstellen
Vielleicht ist Ihnen aufgefallen, dass die price jedes Produkts Teil des Body-Felds des Dokuments ist. Ideal wäre es, den Preis in einem separaten Feld zu speichern, damit wir Filter darauf anwenden können.
Fügen wir diese Änderung zur Datei crawler.yml hinzu, um Extraktionsregeln zu verwenden, mit denen der Preis aus der CSS-Klasse product-price extrahiert werden kann:
Wir sehen auch, dass der Preis ein Dollarzeichen ($) enthält, das wir entfernen müssen, wenn wir Bereichsabfragen ausführen wollen. Dafür können wir eine Ingest-Pipeline verwenden. Beachten Sie, dass wir in unserer neuen Crawler-Konfigurationsdatei oben darauf verweisen:
Wir können diesen Befehl in unserem Elasticsearch-Produktionscluster ausführen. Da die Entwicklungsversion ephemer ist, können wir die Pipeline-Erstellung in die docker-compose.yml -Datei integrieren, indem wir den folgenden Dienst hinzufügen. Beachten Sie, dass wir dem Crawler-Dienst auch eine depends_on hinzugefügt haben, damit er erst startet, nachdem die Pipeline erfolgreich erstellt wurde.
Führen wir nun `./local.sh` aus, um die Änderung lokal zu sehen:

Großartig! Jetzt lasst uns die Veränderung vorantreiben:
Um sicherzustellen, dass alles funktioniert, können Sie Ihre Produktions-Kibana-Datei überprüfen. Dort sollten die Änderungen sichtbar sein und der Preis als neues Feld ohne Dollarzeichen angezeigt werden.
Fazit
Mit dem Elastic Open Web Crawler können Sie Ihren Crawler als Code verwalten. Das bedeutet, dass Sie die gesamte Pipeline – von der Entwicklung bis zur Bereitstellung – automatisieren und beispielsweise ephemere lokale Umgebungen und Tests anhand der gecrawlten Daten programmatisch hinzufügen können.
Sie sind eingeladen, das offizielle Repository zu klonen und mit der Indizierung Ihrer eigenen Daten mithilfe dieses Workflows zu beginnen. In diesem Artikel erfahren Sie auch, wie Sie eine semantische Suche auf den vom Crawler erzeugten Indizes durchführen.
Zugehörige Inhalte

18. Mai 2026
Agentische KI-Suche mit deterministischen Leitplanken in Elasticsearch zur sicheren Ausführung von Abfragen
Agentische KI-Suchsysteme versagen häufig, wenn LLMs Abfragen direkt generieren. Erfahren Sie, wie deterministische Leitplanken und eine Steuerungsebenenarchitektur eine sichere, zuverlässige und kontrollierte Abfrageausführung mit Elasticsearch ermöglichen.

11. Mai 2026
Personalisierung der E-Commerce-Suche: Integration von Kaufverlauf und Nutzerkohorten
Erfahren Sie, wie Sie in Elasticsearch ein personalisiertes E-Commerce-Sucherlebnis schaffen, ohne gegen die Governance-Richtlinien zu verstoßen. In diesem Beitrag erfahren Sie, wie Sie Produkte hervorheben können, die ein Kunde bereits gekauft hat, und wie Sie kohortenspezifische Richtlinien auf der Grundlage von Nutzerprofilen aktivieren können.

4. Mai 2026
Elasticsearch-Perkolator zur Steuerung der Suche im E-Commerce: Übersetzung mehrdeutiger Anfragen in kontrollierte Abrufstrategien
Erfahren Sie, wie Sie den Elasticsearch-Perkolator zur Implementierung der Suchsteuerung verwenden. In diesem Blog skizzieren wir die Muster, die erforderlich sind, um eine geregelte Policy-Engine in der Produktion zu erstellen und eine kontrollierte Abrufstrategie zu entwickeln.

1. Mai 2026
Aufbau einer Steuerungsebene zur Kontrolle der E-Commerce-Suche
Wie Sie eine kontrollierte Steuerungsebene für den elektronischen Handel aufbauen, die widersprüchliche Suchrichtlinien in einem einzigen Ausführungsplan zusammenfasst (ohne Codeänderungen).

24. April 2026
Neuindizierung von Datenströmen aufgrund von Mapping-Konflikten
Erfahren Sie, wie Sie Elasticsearch-Mapping-Konflikte durch Neuindizierung von Datenströmen beheben können. Dieser Blog erklärt den Neuindizierungsprozess und wie Sie sicherstellen, dass neue Daten korrekt zugeordnet werden.