Anfang dieses Jahres kündigte Elastic die Zusammenarbeit mit NVIDIA an, um die GPU-Beschleunigung für Elasticsearch zu realisieren und sie in NVIDIA cuVS zu integrieren – wie in einer Session auf der NVIDIA GTC und in verschiedenen Blogs detailliert beschrieben. Dieser Beitrag ist ein Update zum gemeinsamen Entwicklungsprojekt mit dem NVIDIA-Vektorsuchteam.
Zusammenfassung
Zunächst einmal ein kurzer Überblick. Elasticsearch hat sich als leistungsstarke Vektordatenbank etabliert und bietet eine Vielzahl von Funktionen sowie eine hohe Leistungsfähigkeit für die Ähnlichkeitssuche im großen Maßstab. Mit Funktionen wie Skalarquantisierung, Better Binary Quantization (BBQ), SIMD- Vektoroperationen und speichereffizienteren Algorithmen wie DiskBBQ bietet es bereits effiziente und flexible Optionen für die Verwaltung von Vektor-Workloads.
Durch die Integration von NVIDIA cuVS als aufrufbares Modul für Vektorsuchaufgaben wollen wir signifikante Verbesserungen bei der Vektorindizierungsleistung und -effizienz erzielen, um große Vektor-Workloads besser zu unterstützen.
Die Herausforderung
Eine der größten Herausforderungen beim Aufbau einer leistungsstarken Vektordatenbank ist die Konstruktion des Vektorindexes – des HNSW-Graphen. Die Indexbildung wird schnell von Millionen oder sogar Milliarden arithmetischer Operationen dominiert, da jeder Vektor mit vielen anderen verglichen wird. Darüber hinaus können Index-Lebenszyklusoperationen wie Komprimierung und Zusammenführungen den gesamten Rechenaufwand für die Indizierung weiter erhöhen. Da Datenmengen und die damit verbundenen Vektoreinbettungen exponentiell wachsen, sind beschleunigte Rechen-GPUs, die für massive Parallelität und mathematische Berechnungen mit hohem Durchsatz ausgelegt sind, ideal für die Bewältigung dieser Arbeitslasten geeignet.
Öffnen Sie das Elasticsearch-GPU-Plugin.
NVIDIA cuVS ist eine Open-Source-CUDA-X-Bibliothek für GPU-beschleunigte Vektorsuche und Datenclustering, die schnelles Indexieren und Einbetten für KI- und Empfehlungs-Workloads ermöglicht.
Elasticsearch nutzt cuVS über cuvs-java, eine Open-Source-Bibliothek, die von der Community entwickelt und von NVIDIA gepflegt wird. Die cuvs-java Bibliothek ist leichtgewichtig und baut auf der cuVS C API auf, indem sie Panama Foreign Function verwendet, um cuVS-Funktionen auf idiomatische Java-Art bereitzustellen und dabei modern und leistungsstark zu bleiben.
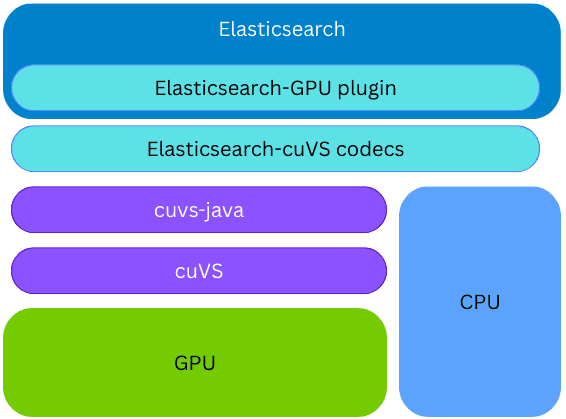
Die cuvs-java-Bibliothek ist in ein neues Elasticsearch-Plugin integriert; daher kann die Vektorindizierung auf der GPU auf demselben Elasticsearch-Knoten und -Prozess erfolgen, ohne dass externer Code oder Hardware bereitgestellt werden muss. Während des Indexaufbaus nutzt Elasticsearch die GPU, um den Vektorindexierungsprozess zu beschleunigen, sofern die cuVS-Bibliothek installiert und eine GPU vorhanden und konfiguriert ist. Die Vektoren werden der GPU übergeben, die daraus einen CAGRA-Graphen erstellt. Dieser Graph wird dann in das HNSW-Format umgewandelt, wodurch er sofort für die Vektorsuche auf der CPU verfügbar ist. Das endgültige Format des erstellten Graphen ist identisch mit dem, das auf der CPU erstellt würde; dadurch kann Elasticsearch GPUs für die Vektorindizierung mit hohem Durchsatz nutzen, wenn die zugrunde liegende Hardware dies unterstützt, während gleichzeitig CPU-Leistung für andere Aufgaben (gleichzeitige Suche, Datenverarbeitung usw.) frei bleibt.
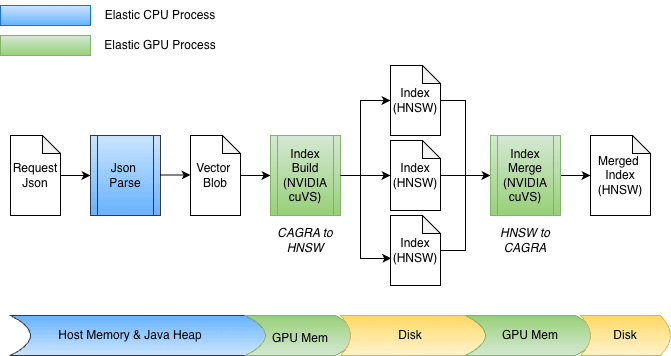
Beschleunigung des Indexaufbaus
Im Rahmen der Integration der GPU-Beschleunigung in Elasticsearch wurden mehrere Verbesserungen an cuvs-java vorgenommen, die sich auf einen effizienten Dateneingang/-ausgang und Funktionsaufruf konzentrieren. Eine wichtige Verbesserung ist die Verwendung von cuVSMatrix zur transparenten Modellierung von Vektoren, unabhängig davon, ob sie sich auf dem Java-Heap, außerhalb des Heaps oder im GPU-Speicher befinden. Dadurch können Daten effizient zwischen Arbeitsspeicher und GPU übertragen werden, wodurch unnötige Kopien von potenziell Milliarden von Vektoren vermieden werden.
Dank dieser zugrundeliegenden Zero-Copy-Abstraktion können sowohl die Übertragung in den GPU-Speicher als auch der Abruf des Graphen direkt erfolgen. Beim Indizieren werden die Vektoren zunächst im Speicher auf dem Java-Heap zwischengespeichert und dann an die GPU gesendet, um den CAGRA-Graphen zu erstellen. Der Graph wird anschließend von der GPU abgerufen, in das HNSW-Format konvertiert und auf der Festplatte gespeichert.
Beim Zusammenführen sind die Vektoren bereits auf der Festplatte gespeichert, wodurch der Java-Heap vollständig umgangen wird. Indexdateien sind speicherabgebildet und die Daten werden direkt in den GPU-Speicher übertragen. Das Design unterstützt zudem problemlos unterschiedliche Bitbreiten, z. B. float32 oder int8, und lässt sich natürlich auf andere Quantisierungsschemata erweitern.
Trommelwirbel ... wie gut funktioniert es?
Bevor wir zu den Zahlen kommen, ist ein bisschen Kontext hilfreich. Die Segmentzusammenführung in Elasticsearch läuft in der Regel automatisch im Hintergrund während der Indizierung, was ein isoliertes Benchmarking schwierig macht. Um reproduzierbare Ergebnisse zu erzielen, haben wir in einem kontrollierten Experiment die Segmentzusammenführung explizit mit der Funktion Force-Merge ausgelöst. Da Force-Merge die gleichen zugrunde liegenden Zusammenführungsoperationen wie das Zusammenführen im Hintergrund durchführt, dient seine Leistung als nützlicher Indikator für erwartete Verbesserungen, auch wenn die genauen Gewinne in realen Indexierungs-Workloads abweichen können.
Schauen wir uns nun die Zahlen an.
Unsere ersten Benchmark-Ergebnisse sind sehr vielversprechend. Wir haben den Benchmark auf einer AWS g6.4xlarge Instanz mit lokal angeschlossenem NVMe-Speicher ausgeführt. Ein einzelner Knoten von Elasticsearch wurde so konfiguriert, dass er die standardmäßige, optimale Anzahl von Indizierungs-Threads (8 – einer für jeden physischen Kern) verwendet und Merge Throttling deaktiviert (was bei schnellen NVMe-Festplatten weniger relevant ist).
Für den Datensatz verwendeten wir 2,6 Millionen Vektoren mit 1.536 Dimensionen aus der OpenAI Rally-Vektorstrecke, kodiert als Base64-Zeichenfolgen und indexiert als float32 hnsw. In allen Szenarien erreichen die konstruierten Graphen Recall-Werte von bis zu 95 %. Hier sind unsere Ergebnisse:
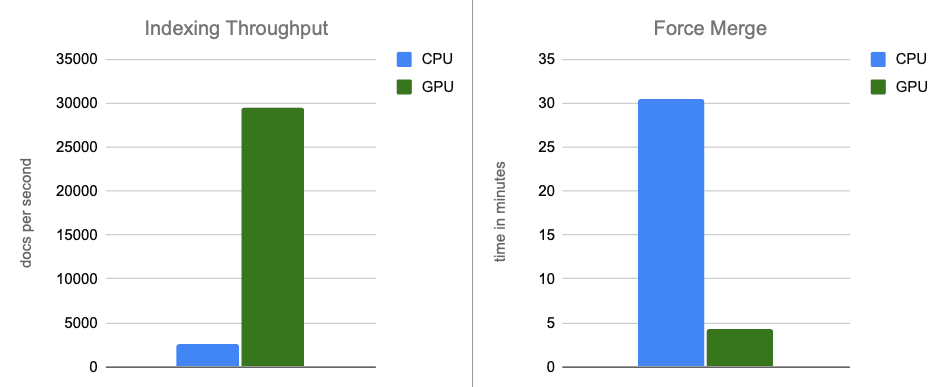
- Indizierungsdurchsatz: Durch die Verlagerung der Graphenkonstruktion auf die GPU während des Speicherpuffer-Flushs steigern wir den Durchsatz um das 12-fache.
- Force-Merge: Nach Abschluss der Indizierung beschleunigt die GPU weiterhin die Segmentzusammenführung und beschleunigt die Force-Merge-Phase um das ~7-fache.
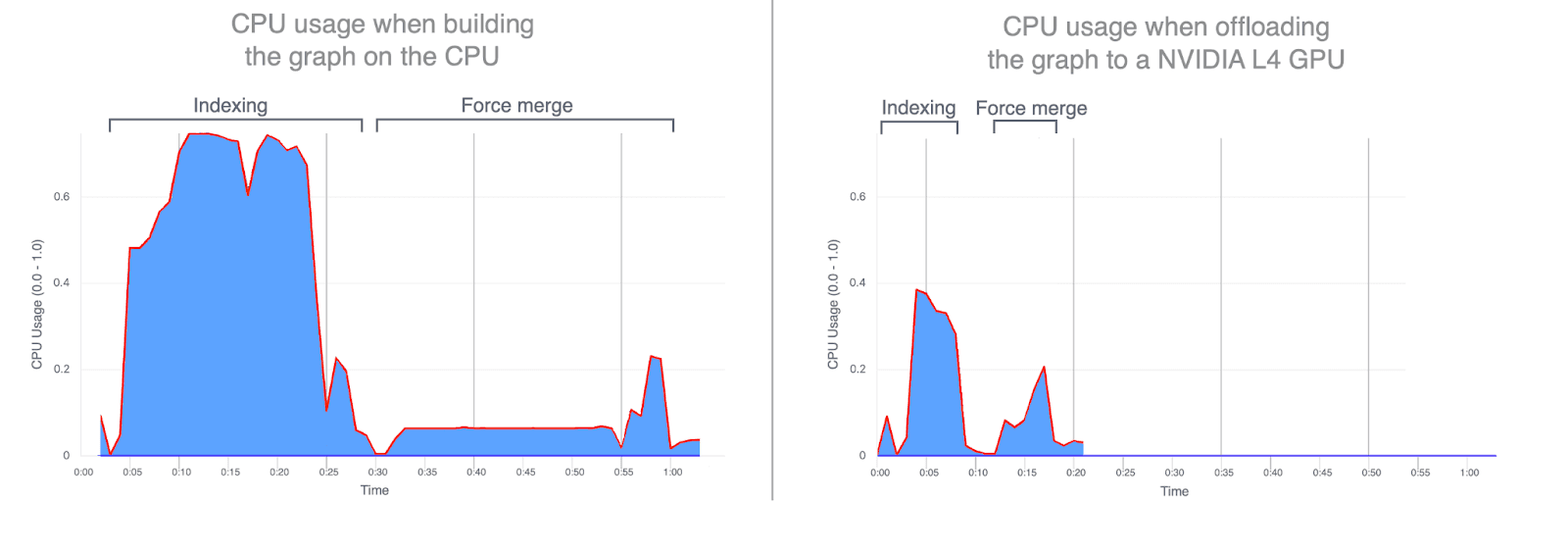
- CPU-Auslastung: Durch die Auslagerung der Graph-Konstruktion auf die GPU werden sowohl die durchschnittliche als auch die maximale CPU-Auslastung deutlich reduziert. Die folgenden Graphen veranschaulichen die CPU-Auslastung während der Indizierung und Zusammenführung und zeigen, wie viel geringer sie ist, wenn diese Vorgänge auf der GPU ausgeführt werden. Eine geringere CPU-Auslastung während der GPU-Indexierung setzt CPU-Zyklen frei, die zur Verbesserung der Suchleistung umgeleitet werden können.
- Recall: Die Genauigkeit bleibt zwischen CPU- und GPU-Läufen praktisch gleich, wobei der mit der GPU erstellte Graph einen geringfügig höheren Recall erreicht.
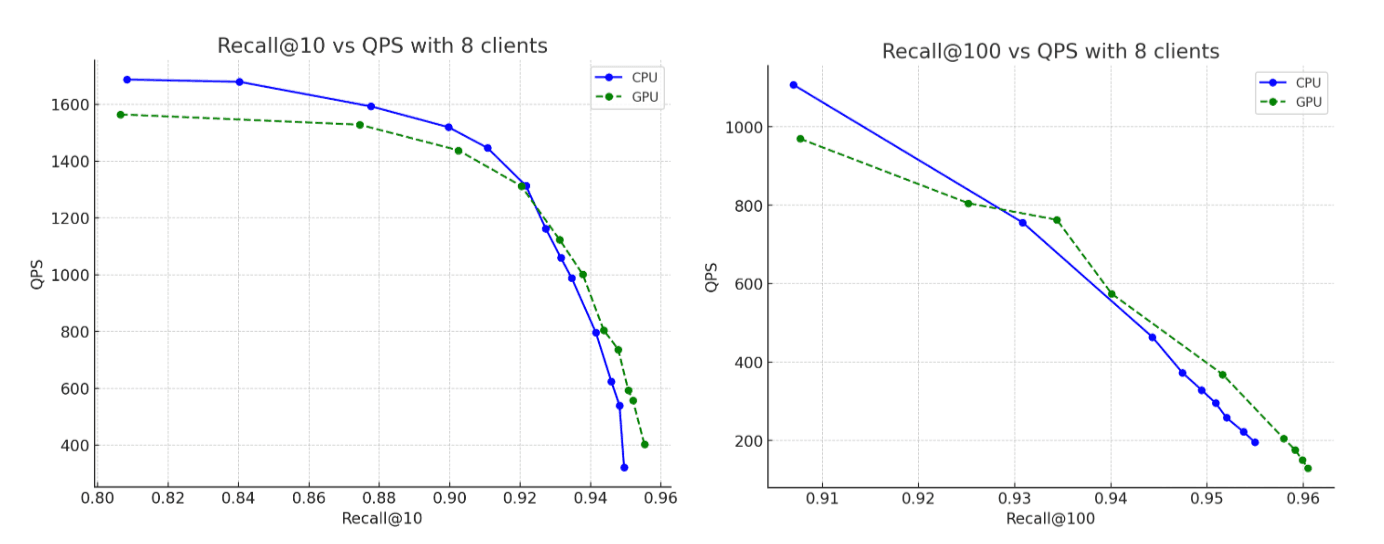
Vergleich anhand einer weiteren Dimension: Preis
Beim vorherigen Vergleich wurde absichtlich identische Hardware verwendet; der einzige Unterschied bestand darin, ob die GPU während der Indizierung verwendet wurde. Diese Konfiguration ist nützlich, um die Auswirkungen der reinen Rechenleistung zu isolieren, aber wir können den Vergleich auch aus einer Kostenperspektive betrachten.
Bei etwa demselben Stundenpreis wie die GPU-beschleunigte Konfiguration kann man ein CPU-reines Setup mit etwa doppelt so vielen vergleichbaren CPU- und Speicherressourcen bereitstellen: 32 vCPUs (AMD EPYC) und 64 GB RAM, wodurch die Anzahl der Indexierungs-Threads auf 16 verdoppelt werden kann.
Um den Vergleich fair und konsistent zu halten, haben wir dieses reine CPU Experiment auf einer AWS g6.8xlarge Instanz ausgeführt, wobei die GPU explizit deaktiviert war. Dadurch konnten wir alle anderen Hardwareeigenschaften konstant halten und gleichzeitig den Kosten-Leistungs-Kompromiss zwischen GPU-Beschleunigung und reiner CPU-Indexierung evaluieren.
Die leistungsstärkere CPU-Instanz zeigt erwartungsgemäß eine verbesserte Performance im Vergleich zu den Benchmarks im obigen Abschnitt. Wenn wir jedoch diese leistungsstärkere CPU-Instanz mit den ursprünglichen GPU-beschleunigten Ergebnissen vergleichen, liefert die GPU immer noch erhebliche Leistungssteigerungen: ~5-fache Verbesserung des Indizierungsdurchsatzes und ~6-fache Verbesserung beim Force Merge, während gleichzeitig Graphen erstellt werden, die Recall-Werte von bis zu 95 % erreichen.
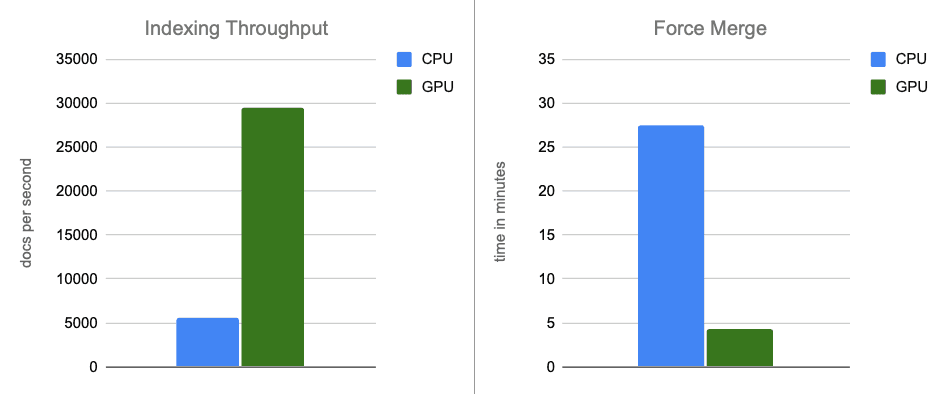
Fazit
In End-to-End-Szenarien bietet die GPU-Beschleunigung mit NVIDIA cuVS eine nahezu 12-fache Verbesserung des Indexierungsdurchsatzes und eine 7-fache Verringerung der Force-Merge-Latenz bei deutlich geringerer CPU-Auslastung. Dies zeigt, dass Vektorindizierungs- und Merge-Workloads erheblich von der GPU-Beschleunigung profitieren. Im Kostenvergleich bietet die GPU-Beschleunigung weiterhin deutliche Leistungssteigerungen, mit einem etwa 5-fach höheren Indexierungsdurchsatz und 6-fach schnelleren Force-Merge-Operationen.
Die GPU-beschleunigte Vektorindizierung ist derzeit für die Tech Preview in Elasticsearch 9.3 geplant, deren Veröffentlichung für Anfang 2026 vorgesehen ist.
Mehr dazu in Kürze.
Zugehörige Inhalte

23. April 2026
Wie wir Elasticsearch simdvec entwickelten, um die Vektorsuche zu einer der schnellsten weltweit zu machen
Wie wir Elasticsearch simdvec entwickelten, die von Hand optimierte SIMD-Kernel-Bibliothek hinter jeder Vektorsuchanfrage in Elasticsearch.

4. Mai 2026
So messen und verbessern Sie den Elasticsearch-Suchabruf: von 0,43 auf 0,75 mit Hybridsuche
Erfahren Sie, wie Sie den Suchabruf in Elasticsearch messen und verbessern können, indem Sie die lexikalische BM25-Suche mit Jina AI-Vektoreinbettungen kombinieren und dabei die rank_eval-API nutzen, um die Verbesserung mit realen Zahlen zu validieren.

2. April 2026
Wenn TSDS auf ILM trifft: Gestaltung von Zeitreihendatenströmen, die verspätete Daten nicht ablehnen
Interaktion zwischen den Zeitgrenzen von TSDS und den ILM-Phasen und Erstellung von Richtlinien, die verspätet eintreffende Metriken tolerieren.

1. April 2026
LINQ to Elasticsearch ES|QL: C# schreiben, Elasticsearch abfragen
Erkundung des neuen LINQ to Elasticsearch ES|QL-Providers im Elasticsearch .NET-Client, mit dem Sie C#-Code schreiben können, der automatisch in ES|QL-Abfragen übersetzt wird.

20. März 2026
Schnell vs. genau: Messung der Recall-Rate bei der quantisierten Vektorsuche
Eine Erklärung, wie der Recall für die Vektorsuche in Elasticsearch mit minimalem Aufwand gemessen werden kann.