Eine Vektorsuche reicht nicht aus, um relevante Ergebnisse zu finden. Es ist sehr üblich, Filterkriterien zu verwenden, die dabei helfen, die Suchergebnisse einzugrenzen und irrelevante Ergebnisse herauszufiltern.
Das Verständnis der Funktionsweise von Filtern bei der Vektorsuche hilft Ihnen, die Kompromisse zwischen Leistung und Trefferquote auszubalancieren und einige der Optimierungen zu entdecken, die verwendet werden, um die Vektorsuche bei Verwendung von Filtern leistungsfähig zu gestalten.
Warum filtern?
Die Vektorsuche hat die Art und Weise, wie wir relevante Informationen in großen Datensätzen finden, revolutioniert und ermöglicht es uns, Elemente zu entdecken, die einer Suchanfrage semantisch ähnlich sind.
Es genügt jedoch nicht, einfach nur ähnliche Artikel zu finden. Oftmals müssen wir die Suchergebnisse anhand spezifischer Kriterien oder Attribute eingrenzen.
Stellen Sie sich vor, Sie suchen in einem Online-Shop nach einem Produkt. Eine reine Vektorsuche zeigt Ihnen möglicherweise visuell ähnliche Artikel an, aber Sie möchten vielleicht auch nach Preisspanne, Marke, Verfügbarkeit oder Kundenbewertungen filtern. Ohne Filterfunktion würden Ihnen unzählige ähnliche Produkte präsentiert, was es schwierig macht, genau das zu finden, was Sie suchen.
Durch die Filterung wird eine präzise Kontrolle über die Suchergebnisse ermöglicht, sodass sichergestellt wird, dass die abgerufenen Elemente nicht nur semantisch übereinstimmen, sondern auch alle notwendigen Anforderungen erfüllen. Dies führt zu einem wesentlich genaueren, effizienteren und benutzerfreundlicheren Sucherlebnis.
Hier liegt die Stärke von Elasticsearch und Apache Lucene – die effektive Filterung über verschiedene Datentypen hinweg ist einer der Hauptunterschiede zu anderen Vektordatenbanken.
Filterung für exakte Vektorsuche
Es gibt zwei Hauptmethoden zur Durchführung exakter Vektorsuchen:
- Verwendung des Indextyps
flatfür Ihr dense_vector-Feld. Dies bewirkt, dassknn-Suchen eine exakte Suche anstelle einer approximativen Suche verwenden. - Die Punktzahl wird mithilfe einer script_score-Abfrage berechnet, die Vektorfunktionen verwendet. Dies kann mit jedem Indextyp verwendet werden.
Bei der Ausführung einer exakten Vektorsuche werden alle Vektoren mit der Suchanfrage verglichen. In diesem Szenario verbessert das Filtern die Leistung, da nur die Vektoren verglichen werden müssen, die den Filter passieren.
Dies hat keinen Einfluss auf die Ergebnisqualität, da ohnehin alle Vektoren berücksichtigt werden. Wir filtern bereits im Voraus die Ergebnisse heraus, die nicht interessant sind, um die Anzahl der Operationen zu reduzieren.
Dies ist sehr wichtig, da eine exakte Suche gegenüber einer approximativen Suche performanter sein kann, wenn die angewendeten Filter zu einer geringen Anzahl von Dokumenten führen.
Als Faustregel gilt: Verwenden Sie die exakte Suche, wenn weniger als 10.000 Dokumente den Filter passieren. BBQ -Indizes sind für Vergleiche wesentlich schneller, daher ist es sinnvoll, bei weniger als 100.000 Einträgen für die Basisindizes die exakte Suche zu verwenden. Weitere Details finden Sie in diesem Blogbeitrag .
Falls Ihre Filter immer sehr restriktiv sind, könnten Sie erwägen, die Indizierung auf die exakte Suche anstatt auf die ungefähre Suche auszurichten, indem Sie einen flat -Indextyp anstelle eines HNSW-basierten Index verwenden. Weitere Details finden Sie in den Eigenschaften von index_options.
Filterung für die approximative Vektorsuche
Bei der Durchführung einer approximativen Vektorsuche tauschen wir Ergebnisgenauigkeit gegen Leistung ein. Vektorsuchdatenstrukturen wie HNSW suchen effizient nach ungefähren nächsten Nachbarn in Millionen von Vektoren. Sie konzentrieren sich darauf, die ähnlichsten Vektoren zu finden, indem sie die geringste Anzahl an Vektorvergleichen durchführen, deren Berechnung aufwändig ist.
Dies bedeutet, dass andere Filterattribute nicht Teil der Vektordaten sind. Verschiedene Datentypen verfügen über eigene Indexierungsstrukturen, die effizient zum Auffinden und Filtern dieser Daten sind, wie beispielsweise Termwörterbücher, Beitragslisten und Dokumentwerte.
Da diese Datenstrukturen vom Vektorsuchmechanismus getrennt sind, wie wenden wir Filter auf die Vektorsuche an? Es gibt zwei Möglichkeiten: Filter nach der Vektorsuche (Nachfilterung) oder vor der Vektorsuche (Vorfilterung) anwenden.
Jede dieser Optionen hat Vor- und Nachteile. Lasst uns tiefer in diese Materie eintauchen!
Nachfilterung
Die Nachfilterung wendet Filter an, nachdem die Vektorsuche durchgeführt wurde. Dies bedeutet, dass die Filter angewendet werden, nachdem die k ähnlichsten Vektorergebnisse gefunden wurden.
Offensichtlich können wir nach Anwendung der Filter auf die Ergebnisse unter Umständen weniger als k Ergebnisse erhalten. Wir könnten natürlich mehr Ergebnisse durch eine Vektorsuche erhalten (höherer k-Wert), aber wir können nicht sicher sein, dass wir nach Anwendung der Filter k oder mehr Ergebnisse erhalten.
Der Vorteil der Nachfilterung besteht darin, dass sie das Laufzeitverhalten der Vektorsuche nicht verändert – die Vektorsuche ist sich der Filterung nicht bewusst. Dies ändert jedoch die endgültige Anzahl der abgerufenen Ergebnisse.
Nachfolgend ein Beispiel für die Nachfilterung mithilfe der knn-Abfrage. Prüfen Sie, ob die Filterklausel von der knn-Abfrage getrennt ist:
Für die KNN-Suche ist auch eine Nachfilterung mit dem Postfilter möglich:
Beachten Sie, dass Sie bei der knn-Suche einen expliziten Post-Filter-Abschnitt verwenden müssen. Wenn Sie keinen Nachfilter verwenden, kombiniert die kNN-Suche die Ergebnisse der nächsten Nachbarn mit anderen Abfragen oder Filtern, anstatt einen Nachfilter anzuwenden.
Vorfilterung
Durch das Anwenden von Filtern vor der Vektorsuche werden zunächst die Dokumente abgerufen, die den Filtern entsprechen, und diese Informationen werden dann an die Vektorsuche weitergegeben.
Lucene verwendet BitSets , um die Dokumente, die die Filterbedingung erfüllen, effizient zu speichern. Anschließend durchläuft die Vektorsuche den HNSW-Graphen und berücksichtigt dabei die Dokumente, die die Bedingung erfüllen. Bevor ein Kandidat zu den Ergebnissen hinzugefügt wird, wird geprüft, ob er im BitSet gültiger Dokumente enthalten ist.
Allerdings muss der Kandidat untersucht und mit der Anfrage verglichen werden, selbst wenn es sich nicht um ein gültiges Dokument handelt. Die Effektivität von HNSW beruht auf der Verbindung zwischen den Vektoren im Graphen – wenn wir die Untersuchung eines Kandidaten abbrechen würden, hieße das, dass wir möglicherweise auch seine Nachbarn überspringen würden.
Stellen Sie es sich so vor, als würden Sie zu einer Tankstelle fahren. Wenn Sie alle Straßen ausschließen, auf denen sich keine Tankstelle befindet, ist es unwahrscheinlich, dass Sie Ihr Ziel erreichen. Andere Straßen sind vielleicht nicht das, was Sie brauchen, aber sie verbinden Sie mit Ihrem Ziel. Gleiches gilt für Vektoren in einem HNSW-Diagramm!
Daraus folgt, dass die Anwendung von Vorfiltern weniger effizient ist als der Verzicht auf Filter. Wir müssen die Arbeit an allen Vektoren durchführen, die wir bei unserer Suche besuchen, und diejenigen verwerfen, die nicht dem Filter entsprechen. Wir investieren mehr Arbeit und nehmen uns mehr Zeit, um unsere Top-K-Ergebnisse zu erzielen.
Nachfolgend ein Beispiel für Vorfilterung in der Elasticsearch Query DSL. Prüfen Sie, ob die Filterklausel nun Teil des knn-Abschnitts ist:
Eine Vorfilterung ist sowohl für die KNN-Suche als auch für die KNN-Abfrage verfügbar:
Vorfilteroptimierungen
Es gibt einige Optimierungen, die wir anwenden können, um eine effiziente Vorfilterung zu gewährleisten.
Wir können auf die exakte Suche umschalten, wenn der Filter sehr restriktiv ist. Wenn nur wenige Vektoren zu vergleichen sind, ist es schneller, eine exakte Suche in den wenigen Dokumenten durchzuführen, die dem Filter entsprechen.
Dies ist eine Optimierung, die in Lucene und Elasticsearch automatisch angewendet wird.
Eine weitere Optimierungsmethode besteht darin, die Vektoren zu ignorieren, die den Filter nicht erfüllen. Stattdessen prüft diese Methode die Nachbarn der gefilterten Vektoren, die den Filter passieren. Dieser Ansatz reduziert effektiv die Anzahl der Vergleiche, da die gefilterten Vektoren nicht berücksichtigt werden, und untersucht weiterhin Vektoren, die mit dem aktuellen Pfad verbunden sind.
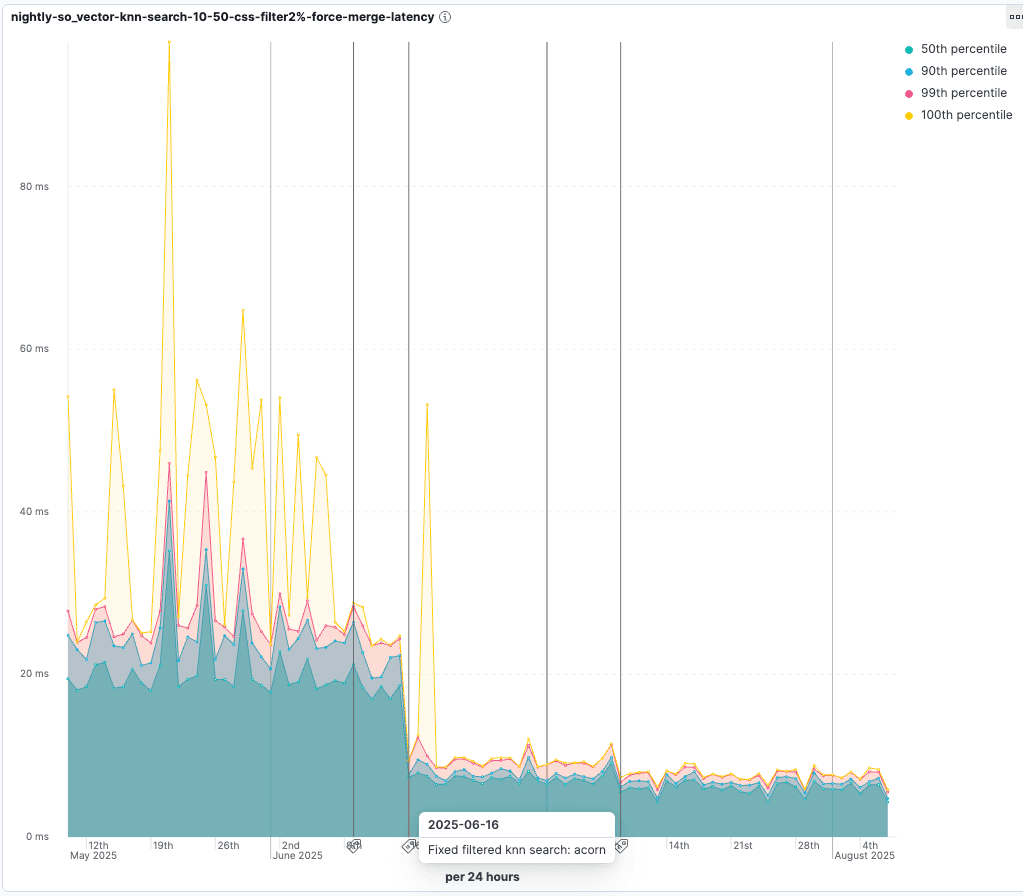
Dieser Algorithmus heißt ACORN-1, und der Prozess wird in diesem Blogbeitrag ausführlich beschrieben.
Filtern mithilfe der Dokumentensicherheit
Document Level Security (DLS) ist eine Elasticsearch-Funktion, die festlegt, welche Dokumente Benutzerrollen abrufen können.
DLS wird mittels Abfragen durchgeführt. Einer Rolle kann eine Abfrage zugeordnet sein, die die Dokumente einschränkt, die ein Benutzer dieser Rolle aus den Indizes abrufen kann.
Die Rollenabfrage dient als Filter, um die Dokumente abzurufen, die ihr entsprechen, und wird als BitSet zwischengespeichert. Dieses BitSet wird dann verwendet, um den zugrunde liegenden Lucene-Reader zu umschließen, sodass nur die Dokumente, die von der Abfrage zurückgegeben wurden, als aktivgelten – das heißt, sie existieren im Index und wurden nicht gelöscht.
Da die Live-Dokumente vom Reader abgerufen werden, um die kNN-Abfrage durchzuführen, werden nur die dem Benutzer zur Verfügung stehenden Dokumente berücksichtigt. Falls ein Vorfilter vorhanden ist, werden die DLS-Dokumente diesem hinzugefügt.
Dies bedeutet, dass die DLS-Filterung als Vorfilter für die approximative Vektorsuche fungiert, mit denselben Auswirkungen auf die Leistung und den gleichen Optimierungen.
Die DLS-Suche mit exakter Suche bietet die gleichen Vorteile wie die Anwendung eines beliebigen Filters – je weniger Dokumente aus der DLS abgerufen werden, desto effizienter ist die exakte Suche. Berücksichtigen Sie auch die Anzahl der von DLS zurückgegebenen Dokumente – wenn die DLS-Rollen sehr restriktiv sind, sollten Sie die Verwendung einer exakten Suche anstelle einer ungefähren Suche in Betracht ziehen.
Benchmarking
Wir bei Elasticsearch möchten sicherstellen, dass die Vektorsuchfilterung effizient ist. Wir haben einen speziellen Benchmark für die Vektorfilterung , der approximative Vektorsuchen mit unterschiedlichen Filtern durchführt, um sicherzustellen, dass die Vektorsuche relevante Ergebnisse so schnell wie möglich liefert.
Prüfen Sie die Verbesserungen, die mit der Einführung von ACORN-1 einhergingen. Bei Tests, bei denen nur 2 % der Vektoren den Filter passieren, reduziert sich die Abfragelatenz auf 55 % der ursprünglichen Dauer:
Fazit
Filtern ist ein integraler Bestandteil der Suche. Die Gewährleistung einer leistungsfähigen Filterung bei der Vektorsuche sowie das Verständnis der damit verbundenen Kompromisse und Optimierungsmöglichkeiten entscheiden darüber, ob eine effiziente und genaue Suche gelingt oder scheitert.
Die Filterung beeinflusst die Leistung bei der Vektorsuche:
- Die exakte Suche ist schneller, wenn Filter verwendet werden. Sie sollten die Verwendung einer exakten Suche anstelle einer ungefähren Suche in Betracht ziehen, wenn Ihre Filterkriterien ausreichend restriktiv sind. Dies ist eine automatische Optimierung in Elasticsearch.
- Die ungefähre Suche ist langsamer, wenn Vorfilter verwendet werden. Durch die Vorfilterung erhalten wir die ersten k Ergebnisse, die dem Filter entsprechen, allerdings auf Kosten einer langsameren Suche.
- Die Nachfilterung liefert nicht unbedingt die obersten k Ergebnisse, da diese bereits beim Anwenden des Filters herausgefiltert worden sein können.
Viel Spaß beim Filtern!
Zugehörige Inhalte

23. April 2026
Wie wir Elasticsearch simdvec entwickelten, um die Vektorsuche zu einer der schnellsten weltweit zu machen
Wie wir Elasticsearch simdvec entwickelten, die von Hand optimierte SIMD-Kernel-Bibliothek hinter jeder Vektorsuchanfrage in Elasticsearch.

4. Mai 2026
So messen und verbessern Sie den Elasticsearch-Suchabruf: von 0,43 auf 0,75 mit Hybridsuche
Erfahren Sie, wie Sie den Suchabruf in Elasticsearch messen und verbessern können, indem Sie die lexikalische BM25-Suche mit Jina AI-Vektoreinbettungen kombinieren und dabei die rank_eval-API nutzen, um die Verbesserung mit realen Zahlen zu validieren.

2. April 2026
Wenn TSDS auf ILM trifft: Gestaltung von Zeitreihendatenströmen, die verspätete Daten nicht ablehnen
Interaktion zwischen den Zeitgrenzen von TSDS und den ILM-Phasen und Erstellung von Richtlinien, die verspätet eintreffende Metriken tolerieren.

1. April 2026
LINQ to Elasticsearch ES|QL: C# schreiben, Elasticsearch abfragen
Erkundung des neuen LINQ to Elasticsearch ES|QL-Providers im Elasticsearch .NET-Client, mit dem Sie C#-Code schreiben können, der automatisch in ES|QL-Abfragen übersetzt wird.

26. März 2026
Ankündigung von Leseberechtigungen für Kibana-Dashboards
Einführung von schreibgeschützten Dashboards in Kibana, die den Erstellern von Dashboards granulare Freigabekontrollen bieten, um die Ergebnisse korrekt zu halten und vor unerwünschten Änderungen zu schützen.