Seit Version 8.16 können Benutzer die Chunking-Strategie konfigurieren, die beim Importieren langer Dokumente in semantische Textfelder verwendet wird. Ab Version 9.1 / 8.19 haben wir eine neue konfigurierbare rekursive Chunking-Strategie eingeführt, die eine Liste regulärer Ausdrücke verwendet, um das Dokument in Abschnitte zu unterteilen. Das Ziel des Chunking ist es, ein langes Dokument in Abschnitte zu unterteilen, die zusammengehörige Inhalte enthalten. Unsere bisherigen Strategien zerlegen Texte auf der Ebene einzelner Wörter/Sätze, aber Dokumente, die in strukturierten Formaten geschrieben sind (z. B. Markdown-Dateien enthalten oft zusammengehörige Inhalte innerhalb von Abschnitten, die durch Trennzeichen definiert sind (z. B. Überschriften). Für diese Art von Dokumenten führen wir die rekursive Chunking-Strategie ein, um das Format strukturierter Dokumente zu nutzen und bessere Chunks zu erstellen!
Was ist rekursives Chunking?
Bei der rekursiven Segmentierung wird eine Liste von vorgegebenen Abschnittstrennungsmustern durchlaufen, um ein Dokument schrittweise in kleinere Segmente zu unterteilen, bis eine gewünschte maximale Segmentgröße erreicht ist.
Wie konfiguriere ich rekursives Chunking?
Folgende Werte können vom Benutzer für die rekursive Segmentierung konfiguriert werden:
- (erforderlich)
max_chunk_size: Die maximale Anzahl von Wörtern in einem Chunk. - Entweder eines von beiden:
separatorsEine Liste von regulären Ausdrücken, die verwendet werden, um das Dokument in Abschnitte zu unterteilen.separator_groupEine Zeichenkette, die einer von Elastic definierten Standardliste von Trennzeichen zugeordnet wird, die für bestimmte Dokumenttypen verwendet werden. Aktuell sindmarkdownundplaintextverfügbar.
Wie funktioniert rekursives Chunking?
Der Prozess des rekursiven Chunkings bei gegebenem Eingabedokument, einem max_chunk_size (gemessen in Wörtern) und einer Liste von Trennzeichenketten verläuft wie folgt:
- Wenn das Eingabedokument bereits innerhalb der maximalen Chunk-Größe liegt, wird ein einzelner Chunk zurückgegeben, der die gesamte Eingabe umfasst.
- Teile den Text anhand des Vorkommens des Trennzeichens in mögliche Abschnitte auf. Für jeden potenziellen Teil:
- Wenn der potenzielle Datenblock innerhalb der maximalen Datenblockgröße liegt, fügen Sie ihn der Liste der an den Benutzer zurückzugebenden Datenblöcke hinzu.
- Andernfalls wiederholen Sie ab Schritt 2, wobei Sie nur den Text aus dem potenziellen Chunk verwenden und diesen anhand des nächsten Trennzeichens in der Liste aufteilen. Wenn keine weiteren Trennzeichen mehr übrig sind, sollte man auf satzbasierte Segmentierung zurückgreifen.
Beispiele für die Konfiguration von rekursivem Chunking
Abgesehen von der Chunk-Größe besteht die wichtigste Konfiguration für rekursives Chunking in der Auswahl der Trennzeichen, die zum Aufteilen der Dokumente verwendet werden sollen. Wenn Sie nicht sicher sind, wo Sie anfangen sollen, bietet Elasticsearch einige Standardtrennzeichengruppen an, die für gängige Anwendungsfälle verwendet werden können.
Verwendung von Trenngruppen
Um eine Trenngruppe zu verwenden, geben Sie einfach den Namen der Gruppe an, die Sie bei der Konfiguration der Chunking-Einstellungen verwenden möchten. Zum Beispiel:
Dies führt zu einer rekursiven Chunking-Strategie, die die Trennzeichenliste ["(?<!\\n)\\n\\n(?!\\n)", "(?<!\\n)\\n(?!\\n)")] verwendet. Dies funktioniert gut für allgemeine Klartextanwendungen, wobei der Text an zwei Zeilenumbruchzeichen, gefolgt von einem weiteren Zeilenumbruchzeichen, geteilt wird.
Wir bieten außerdem eine Trennzeichengruppe markdown an, die die Trennzeichenliste verwendet:
Diese Trennzeichenliste eignet sich gut für allgemeine Markdown-Anwendungsfälle, da sie an jeder der 6 Überschriftenebenen und den Abschnittsumbruchzeichen aufteilt.
Beim Erstellen einer Ressource (Inferenzendpunkt/semantisches Textfeld) wird die Liste der Trennzeichen, die der Trennzeichengruppe zu diesem Zeitpunkt entsprechen, in Ihren Konfigurationen gespeichert. Wenn die Trenngruppe zu einem späteren Zeitpunkt aktualisiert wird, ändert sich dadurch das Verhalten Ihrer bereits erstellten Ressourcen nicht.
Verwendung einer benutzerdefinierten Trennliste
Falls eine der vordefinierten Trennzeichengruppen für Ihren Anwendungsfall nicht geeignet ist, können Sie eine benutzerdefinierte Liste von Trennzeichen definieren, die Ihren Anforderungen entspricht. Beachten Sie, dass reguläre Ausdrücke innerhalb der Trennzeichenliste angegeben werden können. Nachfolgend ein Beispiel für Chunking-Einstellungen mit benutzerdefinierten Trennzeichen:
Die oben beschriebene Chunking-Strategie teilt an zwei Zeilenumbruchzeichen, gefolgt von einem Zeilenumbruchzeichen und schließlich an der Zeichenkette “<my-custom-separator>” auf.
Ein Beispiel für rekursives Chunking in der Praxis
Schauen wir uns ein Beispiel für rekursives Chunking in der Praxis an. In diesem Beispiel verwenden wir die folgenden Chunking-Einstellungen mit einer benutzerdefinierten Liste von Trennzeichen, die ein Markdown-Dokument anhand der beiden obersten Header-Ebenen aufteilen:
Werfen wir einen Blick auf ein einfaches, unstrukturiertes Markdown-Dokument:

Nun verwenden wir die oben definierten Chunking-Einstellungen, um das Dokument in Chunking-Elemente zu unterteilen:
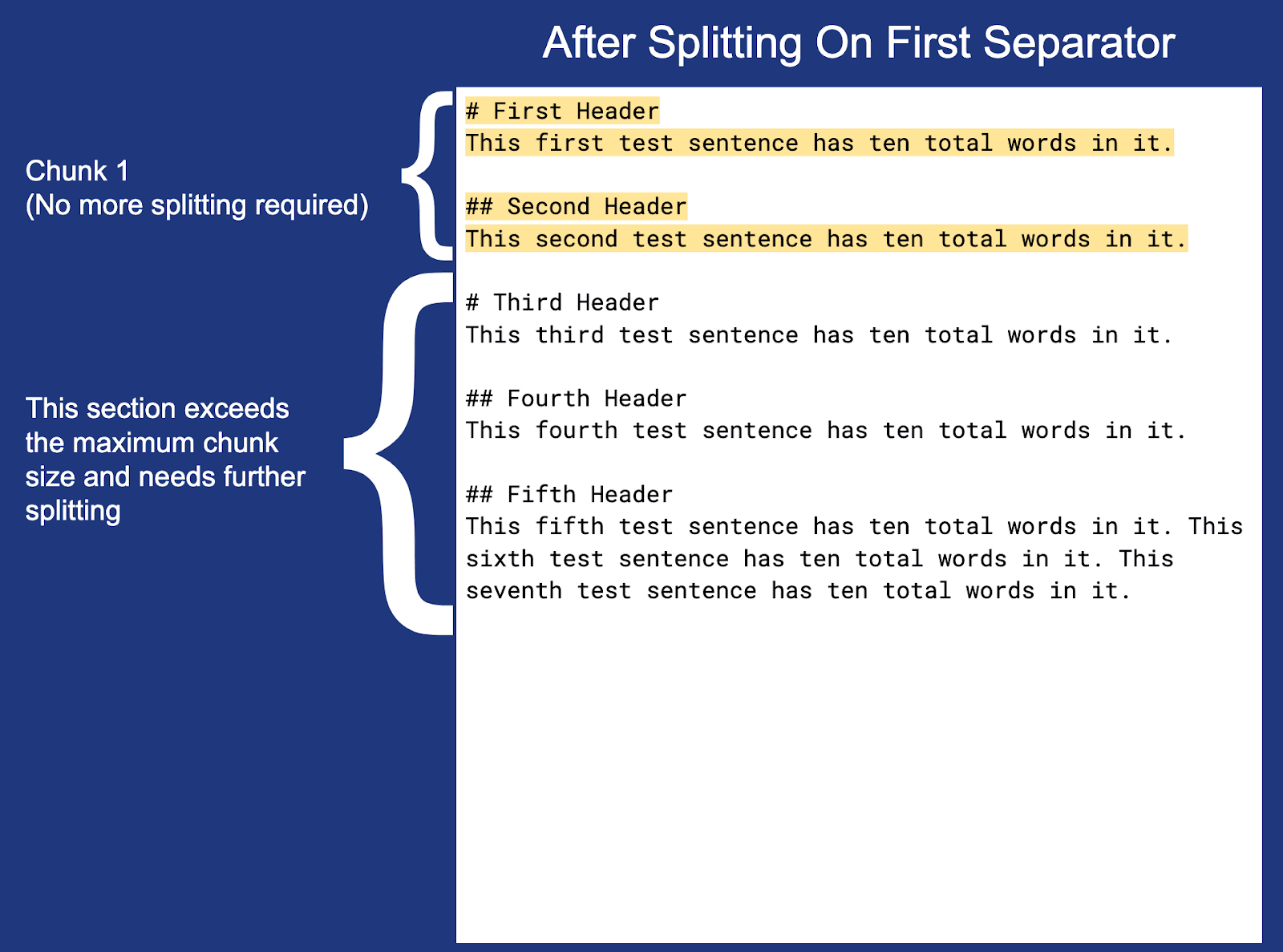

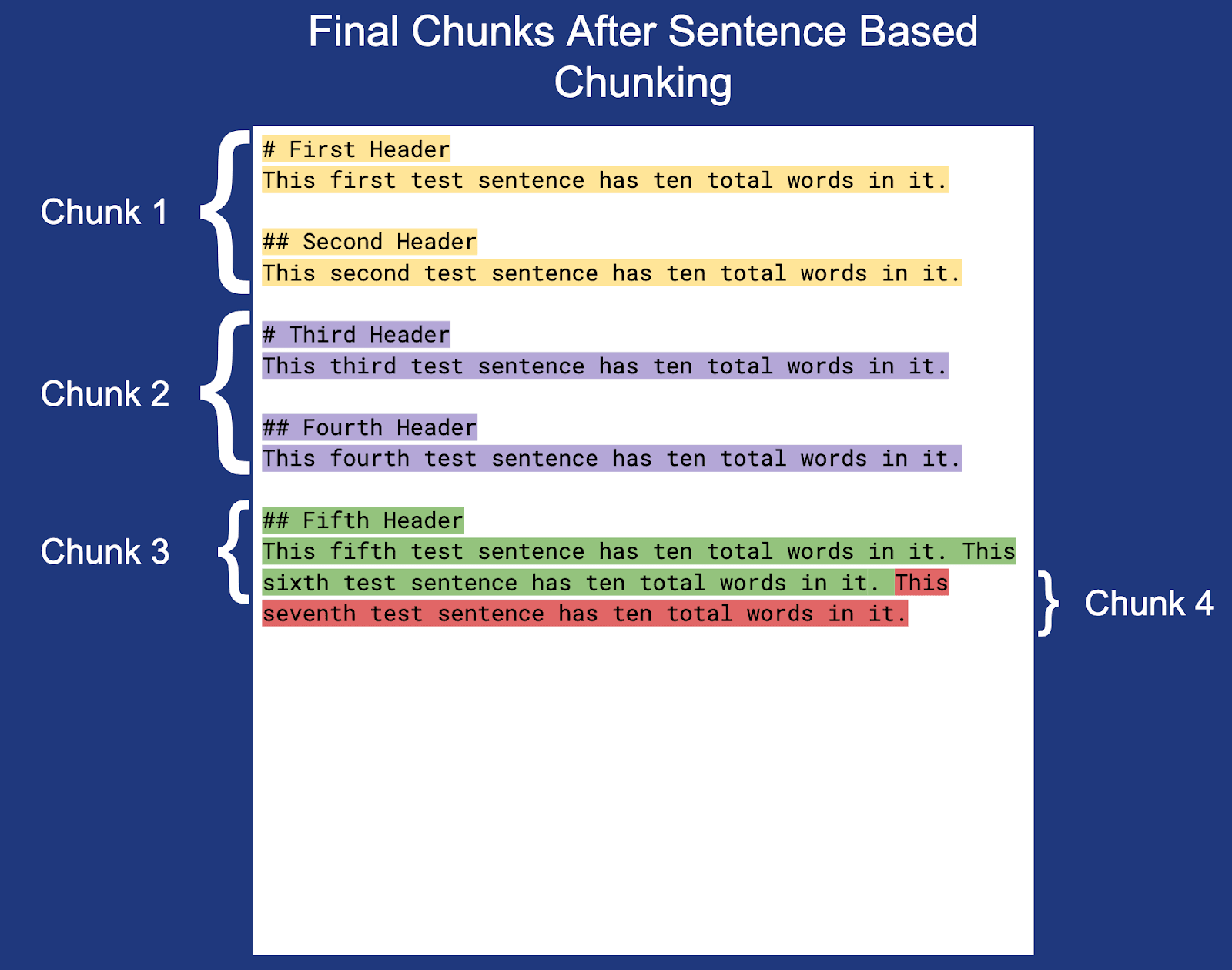
Hinweis: Der Zeilenumbruch am Ende jedes Abschnitts (außer Abschnitt 3) ist nicht hervorgehoben, befindet sich aber innerhalb der eigentlichen Abschnittsgrenzen.
Legen Sie noch heute mit rekursivem Chunking los!
Weitere Informationen zur Nutzung dieser Funktion finden Sie in der Dokumentation zur Konfiguration der Chunking-Einstellungen.
Zugehörige Inhalte

Beschreiben statt zeichnen: KI-native Kibana-Dashboards über MCP und ES|QL
Vom Prompt zum Dashboard. Erfahren Sie, wie Sie Kibana-Dashboards in natürlicher Sprache mit example-mcp-dashbuilder erstellen: eine Open-Source-MCP-Anwendung, die ES|QL-Abfragen schreibt, interaktive Diagramme erstellt und voll funktionsfähige Dashboards direkt in Kibana exportiert.

23. April 2026
Wie wir Elasticsearch simdvec entwickelten, um die Vektorsuche zu einer der schnellsten weltweit zu machen
Wie wir Elasticsearch simdvec entwickelten, die von Hand optimierte SIMD-Kernel-Bibliothek hinter jeder Vektorsuchanfrage in Elasticsearch.

26. März 2026
Ankündigung von Leseberechtigungen für Kibana-Dashboards
Einführung von schreibgeschützten Dashboards in Kibana, die den Erstellern von Dashboards granulare Freigabekontrollen bieten, um die Ergebnisse korrekt zu halten und vor unerwünschten Änderungen zu schützen.

13. März 2026
Entitätsauflösung mit Elasticsearch, Teil 4: Die ultimative Herausforderung
Lösung und Bewertung von Herausforderungen bei der Entitätsauflösung in einem äußerst vielfältigen Datensatz zur „ultimativen Herausforderung“, der entwickelt wurde, um Abkürzungen zu verhindern.
2. März 2026
Adaptive vorzeitige Beendigung für HNSW in Elasticsearch
Einführung einer neuen adaptiven Strategie zur vorzeitigen Beendigung von HNSW in Elasticsearch.