In modernen Beobachtbarkeits-Stacks bleibt es eine Herausforderung, unstrukturierte Logs von verschiedenen Datenanbietern in Plattformen wie Elasticsearch zu Ingestieren. Die Abhängigkeit von manuell erstellten Parsing-Regeln führt zu fehleranfälligen Daten-Pipelines, bei denen selbst geringfügige Aktualisierungen des vorgelagerten Codes zu Parsing-Fehlern und nicht indizierten Daten führen. Diese Fragilität wird durch die Herausforderung der Skalierbarkeit noch verstärkt: In dynamischen Microservices-Umgebungen macht die kontinuierliche Hinzufügung neuer Services die manuelle Regelwartung zu einem operativen Albtraum.
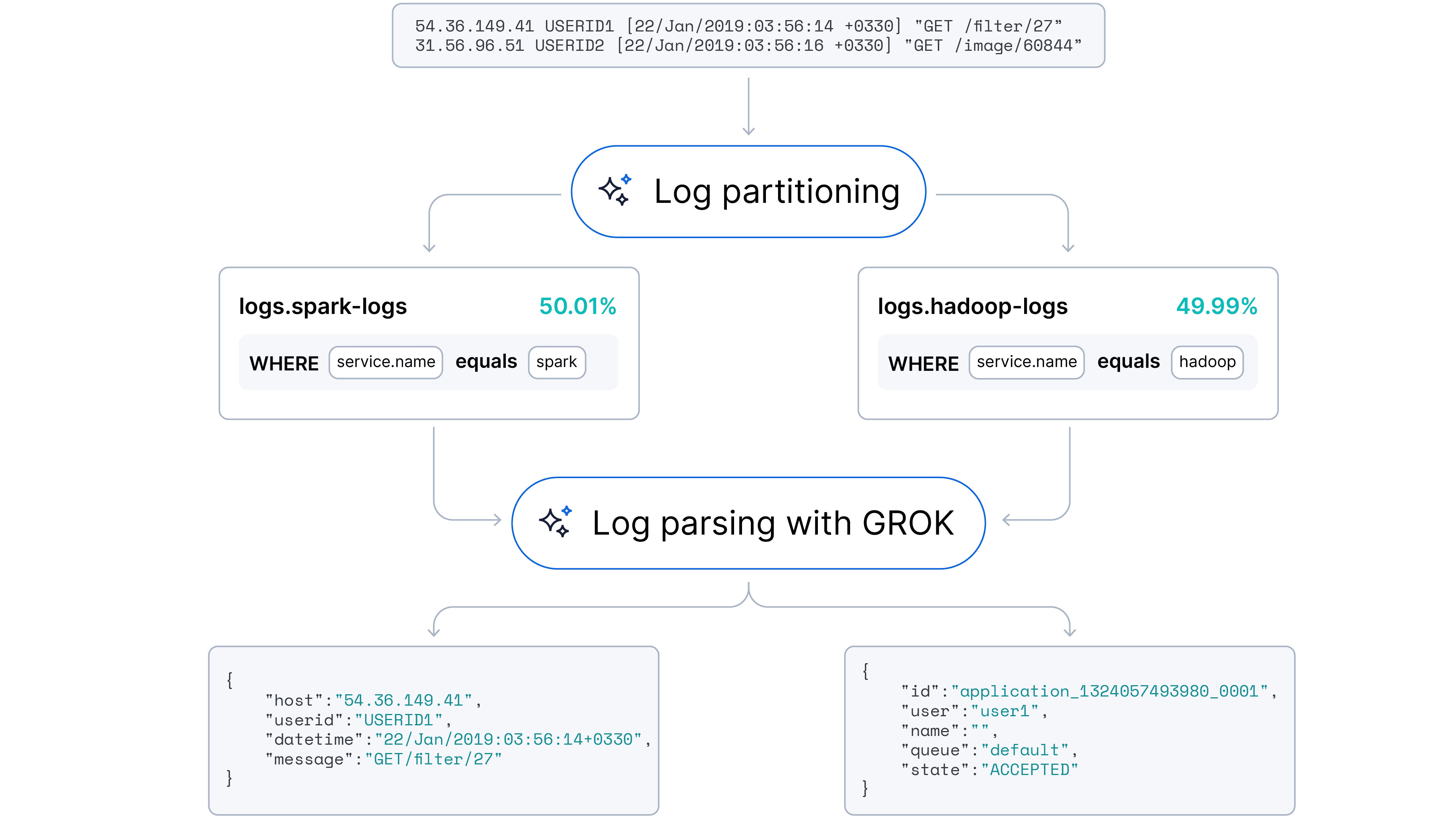
Unser Ziel war es, zu einem automatisierten, adaptiven Ansatz überzugehen, der sowohl Log-Parsing (Feldextraktion) als auch Log-Partitionierung (Quellenidentifikation) bewältigen kann. Wir vermuteten, dass Large Language Models (LLMs) mit ihrem inhärenten Verständnis von Codesyntax und semantischen Mustern diese Aufgaben mit minimalem menschlichem Eingreifen automatisieren könnten.
Wir freuen uns, Ihnen mitteilen zu können, dass dieses Feature bereits in Streams verfügbar ist!
Beschreibung des Datensatzes
Wir haben für PoC-Zwecke eine Loghub-Sammlung von Logs gewählt. Für unsere Untersuchung wählten wir repräsentative Stichproben aus den folgenden Schlüsselbereichen aus:
- Verteilte Systeme: Wir verwendeten die HDFS- (Hadoop Distributed File System) und Spark-Datensätze. Diese enthalten eine Mischung aus Info-, Fehlerbehebungs- und Fehlermeldungen, die für Big Data-Plattformen typisch sind.
- Server- und Webanwendungen: Logs von Apache-Webservern und OpenSSH boten eine wertvolle Quelle für Zugriffs-, Fehler- und sicherheitsrelevante Ereignisse. Diese sind entscheidend für die Überwachung des Webverkehrs und die Erkennung potenzieller Bedrohungen.
- Betriebssysteme: Wir haben Protokolle von Linux und Windows aufgenommen. Diese Datensätze repräsentieren die üblichen, semistrukturierten Ereignisse auf Systemebene, denen Betriebsteams täglich begegnen.
- Mobile Systeme: Um sicherzustellen, dass unser Modell auch Logs aus mobilen Umgebungen verarbeiten kann, haben wir den Android-Datensatz mit einbezogen. Diese Logs sind oft ausführlich und erfassen eine Vielzahl von Aktivitäten auf Anwendungs- und Systemebene auf Mobilgeräten.
- Supercomputer: Um die Leistung in Hochleistungs-Computing-Umgebungen (HPC) zu testen, haben wir den BGL-Datensatz (Blue Gene/L) integriert, der hochstrukturierte Logs mit spezifischer Domänenterminologie enthält.
Ein entscheidender Vorteil der Loghub-Sammlung ist, dass die Logs größtenteils unsaniert und unbeschriftet sind, was eine geräuschvolle Live-Produktionsumgebung mit Microservice-Architektur widerspiegelt.
Log-Beispiele:
Zusätzlich haben wir einen Kubernetes-Cluster mit einer typischen Webanwendung und Datenbank erstellt, die zusätzliche Logs in der gängigsten Domäne sammelt.
Beispiel für gängige Logfelder: Zeitstempel, Log-Ebene (INFO, WARN, FEHLER), Quelle, Nachricht.
Few-Shot-Log-Parsing mit einem LLM
Unsere erste Reihe von Experimenten konzentrierte sich auf eine grundlegende Frage: Kann ein LLM zuverlässig Schlüsselfelder identifizieren und konsistente Parsing-Regeln erzeugen, um sie zu extrahieren?
Wir haben ein Modell gebeten, rohe Log-Stichproben zu analysieren und Log-Parsing-Regeln im regulären Ausdruck (Regex) und im Grok-Format zu generieren. Unsere Ergebnisse zeigten, dass dieser Ansatz großes Potenzial hat, aber auch erhebliche Herausforderungen bei der Implementierung.
Hohe Zuverlässigkeit und Kontextbewusstsein
Die ersten Ergebnisse waren vielversprechend. Das LLM zeigte eine starke Fähigkeit, Parsing-Regeln zu generieren, die mit hoher Wahrscheinlichkeit zu den bereitgestellten Beispielen passten. Neben der einfachen Mustererkennung zeigte das Modell die Fähigkeit zum Log-Verständnis – es konnte die Log-Quelle (z. B. Gesundheits-Tracking-App, Nginx-Web-App, Mongo-Datenbank) korrekt identifizieren und benennen.
Das „Goldlöckchen“-Dilemma der Eingabestichproben
Unsere Experimente zeigten schnell einen erheblichen Mangel an Robustheit aufgrund der extremen Empfindlichkeit gegenüber der Eingabestichprobe. Die Leistung des Modells schwankt stark in Abhängigkeit von den spezifischen Log-Beispielen, die im Prompt enthalten sind. Wir haben ein Log-Ähnlichkeitsproblem beobachtet, bei dem die Log-Stichprobe gerade ausreichend unterschiedliche Logs enthalten muss:
- Zu homogen (Overfitting): Wenn die Eingabe-Logs zu ähnlich sind, neigt das LLM dazu, zu überspezifizieren. Es behandelt variable Daten – wie spezifische Java-Klassennamen in einem Stack-Trace – als statische Teile der Vorlage. Das Ergebnis sind spröde Regeln, die nur einen winzigen Teil der Logs abdecken und unbrauchbare Felder extrahieren.
- Zu heterogen (Verwirrung): Umgekehrt, wenn die Stichprobe erhebliche Formatierungsunterschiede enthält – oder schlimmer noch, „Müll-Logs“ wie Fortschrittsbalken, Speichertabellen oder ASCII-Art – kämpft das Modell damit, einen gemeinsamen Nenner zu finden. Oftmals greift man dabei auf die Generierung komplexer, fehlerhafter regulärer Ausdrücke zurück oder verallgemeinert die gesamte Zeile vorschnell zu einem einzigen Nachrichten-Feld.
Die Einschränkung des Kontextfensters
Wir sind außerdem auf einen Engpass im Kontextfenster gestoßen. Wenn die Eingabe-Logs lang, heterogen oder reich an extrahierbaren Feldern waren, verschlechterte sich oft die Ausgabe des Modells und wurde „unübersichtlich“ oder zu lang, um in das Ausgabekontextfenster zu passen. Natürlich hilft Chunking in diesem Fall. Durch das Aufteilen von Protokollen mithilfe zeichenbasierter und entitätsbasierter Trennzeichen könnten wir dem Modell helfen, sich auf das Extrahieren der Hauptfelder zu konzentrieren, ohne von Rauschen überwältigt zu werden.
Die Konsistenz- und Standardisierungslücke
Selbst wenn das Modell erfolgreich Regeln generierte, stellten wir leichte Inkonsistenzen fest:
- Namensvariationen für Dienste: Das Modell schlägt unterschiedliche Namen für dieselbe Entität vor (z. B. wird die Quelle in verschiedenen Ausführungen als „Spark“, „Apache Spark“ und „Spark log Analytics“ bezeichnet).
- Variationen bei der Feldbenennung: Es fehlte an Standardisierung bei den Feldnamen (z. B.
idvs.service.idvs.device.id). Wir haben Namen mithilfe einer standardisierten Elastic-Feldbenennung normalisiert. - Auflösungsvarianz: Die Auflösung der Feldextraktion variierte je nachdem, wie ähnlich die Eingabe-Logs einander waren.
Log-Format-Fingerprint
Um die Herausforderung der Log-Ähnlichkeit anzugehen, führen wir eine leistungsstarke Heuristik ein: Log-Format-Fingerprint (LFF).
Anstatt rohe, verrauschte Logs direkt in ein LLM einzuspeisen, wenden wir zunächst eine deterministische Transformation an, um die zugrundeliegende Struktur jeder Nachricht zu enthüllen. Dieser Vorverarbeitungsschritt abstrahiert variable Daten und generiert einen vereinfachten „Fingerabdruck“, der es uns ermöglicht, verwandte Logs zu gruppieren.
Die Mapping-Logik ist einfach, um Geschwindigkeit und Konsistenz zu gewährleisten:
- Ziffernabstraktion: Jede Ziffernfolge (0–9) wird durch eine einzelne „0“ ersetzt.
- Textabstraktion: Jede Folge von alphabetischen Zeichen mit Leerzeichen wird durch ein einzelnes „a“ ersetzt.
- Normalisierung von Leerzeichen: Alle Sequenzen von Leerzeichen (Leerzeichen, Tabulatoren, Zeilenumbrüche) werden zu einem einzigen Leerzeichen zusammengefasst.
- Symbolerhaltung: Zeichensetzung und Sonderzeichen (z. B. :, [, ], /) werden beibehalten, da sie oft die stärksten Indikatoren für die Log-Struktur sind.
Wir stellen den Log-Mapping-Ansatz vor. Die grundlegenden Mapping-Muster umfassen Folgendes:
- Ziffern 0–9 von beliebiger Länge -> auf „0“.
- Text (alphabetische Zeichen mit Leerzeichen) von beliebiger Länge -> auf „a“.
- Leerzeichen, Tabulatoren und neue Zeilen -> auf ein einzelnes Leerzeichen.
Schauen wir uns ein Beispiel an, wie uns dieses Mapping die Transformation der Logs ermöglicht.

Dadurch erhalten wir folgende Log-Masken:

Beachten Sie die Fingerabdrücke der ersten beiden Logs. Trotz unterschiedlicher Zeitstempel, Quellklassen und Nachrichteninhalte sind ihre Präfixe (0/0/0 0:0:0 a a.a:) identisch. Durch diese strukturelle Ausrichtung können wir diese Logs automatisch in denselben Cluster einordnen.
Das dritte Log erzeugt jedoch einen völlig abweichenden Fingerabdruck (0-0-0...). Dies ermöglicht es uns, es algorithmisch von der ersten Gruppe zu trennen, bevor wir überhaupt ein LLM aufrufen.
Bonus: Sofortige Implementierung mit ES|QL
Es ist so einfach wie das Übergeben dieser Abfrage in Discover.
Abfrage-Aufschlüsselung:
FROM LogHub: Zielt auf unseren Index mit den Rohprotokolldaten ab.
EVAL Muster = …: Die Kern-Mapping-Logik. Wir verketten REPLACE-Funktionen, um die Abstraktion durchzuführen (z. B. Ziffern zu '0', Text zu 'a' usw.) und speichern das Ergebnis in einem „Muster“-Feld.
STATS [column1 =] expression1, … BY SUBSTRING(pattern, 0, 15):
Dies ist ein Clustering-Schritt. Wir gruppieren Protokolle, die die ersten 15 Zeichen ihres Musters gemeinsam haben, und erstellen aggregierte Felder wie die Gesamtzahl der Protokolle pro Gruppe, eine Liste der Protokoll-Datenquellen, das Musterpräfix und 3 Protokollbeispiele.
SORT total_count DESC | LIMIT 100 : Zeigt die 100 häufigsten Log-Muster an
Die Abfrageergebnisse auf LogHub werden unten angezeigt:


Wie in der Visualisierung gezeigt, partitioniert dieser „LLM-freie“ Ansatz Protokolle mit hoher Genauigkeit. Es gelang ihm, 10 von 16 Datenquellen (basierend auf LogHub-Labels) vollständig zu clustern (>90 %), und er erreichte ein Mehrheits-Clustering in 13 von 16 Quellen (>60 %) – alles ohne zusätzliche Reinigung, Vorverarbeitung oder Feinabstimmung.
Log-Format-Fingerprinting bietet eine pragmatische, wirkungsvolle Alternative und Ergänzung zu ausgefeilten ML-Lösungen wie der Log-Pattern-Analyse. Es bietet sofortige Einblicke in die Zusammenhänge der Logs und verwaltet große Log-Cluster effektiv.
- Vielseitigkeit als Grundform
Dank ES|QL-Implementierung dient LFF sowohl als eigenständiges Werkzeug für schnelle Datendiagnostik/-visualisierungen als auch als Baustein in Loganalyse-Pipelines für Anwendungsfälle mit hohem Volumen.
- Flexibilität
LFF lässt sich leicht anpassen und erweitern, um spezifische Muster zu erfassen, z. B. hexadezimale Zahlen und IP-Adressen.
- Deterministische Stabilität
Im Gegensatz zu ML-basierten Clustering-Algorithmen ist die LFF-Logik geradlinig und deterministisch. Neue eingehende Logs wirken sich nicht rückwirkend auf bestehende Log-Cluster aus.
- Leistung und mMemory
Es benötigt nur minimalen Speicher, kein Training und keine GPU und ist daher ideal für Echtzeit-Umgebungen mit hohem Durchsatz geeignet.
Kombination des Log-Format-Fingerprints mit einem LLM
Zur Validierung der vorgeschlagenen hybriden Architektur enthielt jedes Experiment eine zufällige 20%ige Teilmenge der Logs aus jeder Datenquelle. Diese Einschränkung simuliert eine reale Produktionsumgebung, in der Logs in Batches und nicht als monolithischer historischer Dump verarbeitet werden.
Das Ziel war zu demonstrieren, dass LFF als effektive Kompressionsschicht fungiert. Wir wollten beweisen, dass Parsing-Regeln mit hoher Abdeckung aus kleinen, kuratierten Stichproben generiert und erfolgreich auf den gesamten Datensatz verallgemeinert werden können.
Ausführungspipeline
Wir haben eine mehrstufige Pipeline implementiert, die die Daten filtert, gruppiert und stratifizierte Stichproben auf sie anwendet, bevor sie das LLM erreichen.
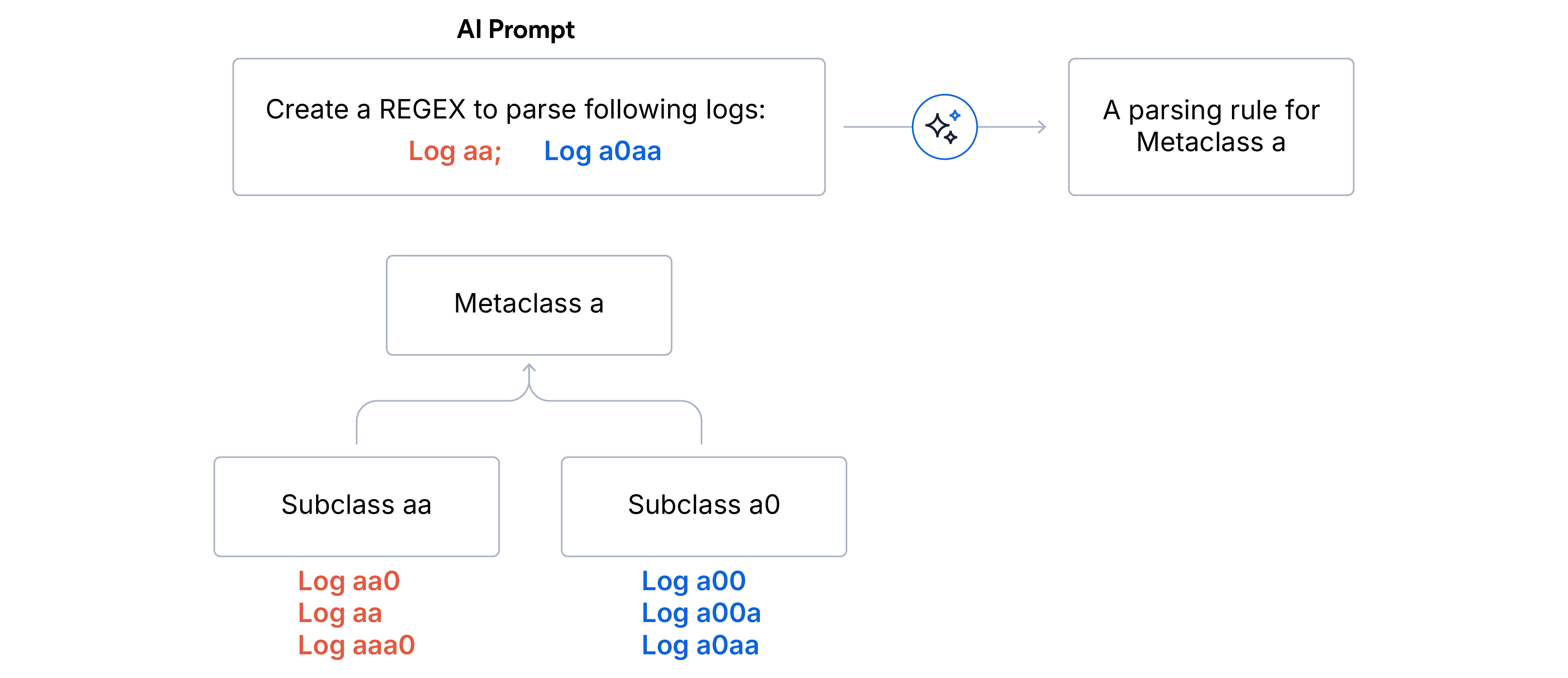
1. Zweistufiges hierarchisches Clustering
- Unterklassen (exakte Übereinstimmung): Logs werden anhand identischer Fingerabdrücke aggregiert. Alle Logs einer Unterklasse haben exakt die gleiche Formatstruktur.
- Ausreißerbereinigung. Wir verwerfen alle Unterklassen, die weniger als 5 % des gesamten Logvolumens ausmachen. Dadurch wird sichergestellt, dass sich das LLM auf das dominante Signal konzentriert und nicht durch Rauschen oder fehlerhafte Logs abgelenkt wird.
- Metaklassen (Präfixübereinstimmung): Verbleibende Unterklassen werden in Metaklassen nach den ersten N Zeichen der Format-Fingerabdruckübereinstimmung gruppiert. Wir haben N=5 für das Log-Parsing und N=15 für die Log-Partitionierung gewählt, wenn die Datenquellen unbekannt sind.
2. Stratifiziertes Sampling. Sobald der hierarchische Baum erstellt ist, erstellen wir die Log-Stichprobe für das LLM. Das strategische Ziel ist es, die Varianzabdeckung zu maximieren und gleichzeitig die Verwendung von Token zu minimieren.
- Wir wählen repräsentative Logs aus jeder gültigen Unterklasse innerhalb der breiteren Metaklasse aus.
- Um einen Randfall mit zu vielen Unterklassen zu managen, wenden wir zufälliges Downsampling an, um die Zielfenstergröße anzupassen.
3. Regelgenerierung. Abschließend fordern wir das LLM auf, eine Regex-Parsing-Regel zu generieren, die auf alle Logs in der bereitgestellten Stichprobe für jede Metaklasse zutrifft. Für unseren PoC haben wir das Modell GPT-4o Mini verwendet.
Experimentelle Ergebnisse und Beobachtungen
Wir haben auf dem Loghub-Datensätze eine Parsing-Genauigkeit von 94 % und eine Partitionierungs-Genauigkeit von 91 % erreicht.

Die obige Konfusionsmatrix veranschaulicht die Ergebnisse der Log-Partitionierung. Die vertikale Achse stellt die tatsächlichen Datenquellen dar, die horizontale Achse die vorhergesagten Datenquellen. Die Intensität der Heatmap entspricht dem Log-Volumen, wobei leichtere Kacheln auf eine höhere Anzahl hinweisen. Die diagonale Ausrichtung zeigt die hohe Genauigkeit des Modells bei der Quellenzuweisung mit minimaler Streuung.
Einblicke aus unseren Leistungsvergleichsanalysen:
- Optimale Ausgangsbasis: Ein Kontextfenster von 30 bis 40 Log-Stichproben pro Kategorie erwies sich als der „Sweet Spot“, der sowohl mit Regex- als auch mit Grok-Mustern durchweg ein robustes Parsing ermöglichte.
- Eingabeminimierung: Wir haben die Eingabegröße für Regex-Muster auf 10 Logs pro Kategorie erhöht und nur einen 2%igen Rückgang der Parsing-Leistung festgestellt, was bestätigt, dass diversitätsbasierte Stichproben kritischer sind als das rohe Volumen.
Zugehörige Inhalte

Beschreiben statt zeichnen: KI-native Kibana-Dashboards über MCP und ES|QL
Vom Prompt zum Dashboard. Erfahren Sie, wie Sie Kibana-Dashboards in natürlicher Sprache mit example-mcp-dashbuilder erstellen: eine Open-Source-MCP-Anwendung, die ES|QL-Abfragen schreibt, interaktive Diagramme erstellt und voll funktionsfähige Dashboards direkt in Kibana exportiert.

13. März 2026
Entitätsauflösung mit Elasticsearch, Teil 4: Die ultimative Herausforderung
Lösung und Bewertung von Herausforderungen bei der Entitätsauflösung in einem äußerst vielfältigen Datensatz zur „ultimativen Herausforderung“, der entwickelt wurde, um Abkürzungen zu verhindern.

26. Februar 2026
Entitätsauflösung mit Elasticsearch & LLMs, Teil 2: Abgleich von Entitäten mit LLM-Bewertung und semantischer Suche
Verwendung semantischer Suche und transparenter LLM-Bewertung zur Entitätsauflösung in Elasticsearch.

5. Januar 2026
Erstellung von Human-in-the-Loop-Agenten mit LangGraph und Elasticsearch
Erfahren Sie, wie Sie mit LangGraph und Elasticsearch Human-in-the-Loop-Agenten erstellen, die Menschen in den Entscheidungsprozess einbeziehen, um kontextuelle Lücken zu schließen und Tool-Aufrufe vor ihrer Ausführung zu überprüfen.

15. Dezember 2025
Erste Schritte mit Elastic Agent Builder und Strands Agents SDK
Lernen Sie, wie Sie mit Elastic Agent Builder einen Agenten erstellen, und erkunden Sie anschließend, wie Sie den Agenten über das A2A-Protokoll nutzen, das mit dem Strands Agents SDK orchestriert wird.