Beim Erstellen von KI-Suchanwendungen müssen häufig mehrere Aufgaben, der Datenabruf und die Datenextraktion zu einem nahtlosen Workflow koordiniert werden. LangGraph vereinfacht diesen Prozess, indem es Entwicklern ermöglicht, KI-Agenten mithilfe einer node-basierten Struktur zu orchestrieren. In diesem Artikel werden wir eine Finanzlösung mit LangGraph.js erstellen.
Was ist LangGraph?
LangGraph ist ein Framework zum Erstellen von KI-Agenten und deren Orchestrierung in einem Workflow, um KI-unterstützte Anwendungen zu entwickeln. LangGraph verfügt über eine Knotenarchitektur, in der wir Funktionen deklarieren können, die Aufgaben darstellen, und diese als Knoten des Workflows zuweisen können. Das Ergebnis der Interaktion mehrerer Knoten ist ein Graph. LangGraph ist Teil des umfassenderen LangChain-Ökosystems, das Tools für die Erstellung modularer und zusammensetzbarer KI-Systeme bereitstellt.
Zur Veranschaulichung dessen, warum LangGraph nützlich ist, werden wir eine problematische Situation damit lösen.
Überblick über die Lösung
In einem Risikokapitalunternehmen haben Investoren Zugriff auf eine umfangreiche Datenbank mit zahlreichen Filteroptionen, aber wenn man Kriterien kombinieren möchte, wird es schwierig und langsam. Dies kann dazu führen, dass einige relevante Start-ups für Investitionen nicht entdeckt werden. Das Ergebnis: Man verbringt viele Stunden damit, die besten Kandidaten zu identifizieren, oder verpasst sogar Chancen.
Mit LangGraph und Elasticsearch können wir gefilterte Suchen in natürlicher Sprache durchführen, sodass Nutzer komplexe Anfragen mit Dutzenden von Filtern nicht manuell erstellen müssen. Um die Flexibilität zu erhöhen, entscheidet der Workflow anhand der Nutzereingaben automatisch zwischen zwei Abfragetypen.
- Investitionsorientierte Anfragen: Diese zielen auf finanzielle und finanzierungsbezogene Aspekte von Start-ups ab, wie Finanzierungsrunden, Bewertung oder Umsatz. Beispiel: „Suche Start-ups mit einer Series-A- oder Series-B-Finanzierung zwischen 8 und 25 Mio. Dollar und einem monatlichen Umsatz von über 500.000 Dollar.“
- Marktorientierte Anfragen: Diese konzentrieren sich auf Branchensegmente, geografische Märkte oder Geschäftsmodelle und helfen dabei, Chancen in bestimmten Sektoren oder Regionen zu identifizieren. Beispiel: „Suche Fintech- und Healthcare-Start-ups in San Francisco, New York oder Boston.“
Um die Abfragen robust zu halten, werden wir das LLM dazu bringen, Suchvorlagen anstelle vollständiger DSL-Abfragen zu erstellen. Auf diese Weise erhalten Sie immer die gewünschte Abfrage, und der LLM muss lediglich die Lücken ausfüllen und trägt nicht die Verantwortung, die benötigte Abfrage jedes Mal neu zu erstellen.
Was Sie brauchen, um loszulegen
- Elasticsearch API-Schlüssel
- OpenAPI-API-Schlüssel
- Node 18 oder neuer
Schritt-für-Schritt-Anweisungen
In diesem Abschnitt schauen wir uns an, wie die App aussehen wird. Dafür verwenden wir TypeScript, ein Superset von JavaScript, das statische Typen hinzufügt, um den Code zuverlässiger, leichter zu pflegen und sicherer zu machen, indem Fehler frühzeitig erkannt werden, während er vollständig kompatibel mit bestehendem JavaScript bleibt.
Der Knotenfluss sieht wie folgt aus:
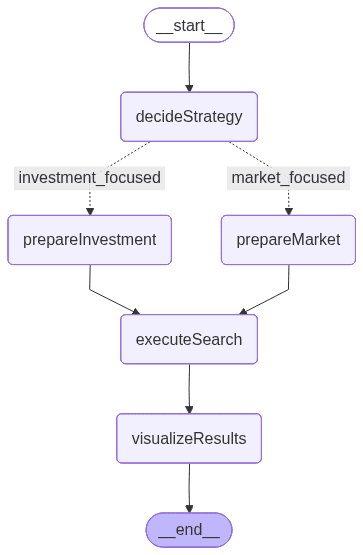
Das obige Bild wird von LangGraph generiert und stellt den Workflow dar, der die Ausführungsreihenfolge und die bedingte Logik zwischen den Knoten definiert:
- decideStrategy: Verwendet ein LLM, um die Anfrage des Nutzers zu analysieren und zwischen zwei spezialisierten Suchstrategien zu entscheiden – investitionsorientiert oder marktorientiert.
- prepareInvestmentSearch: Extrahiert Filterwerte aus der Abfrage und erstellt eine vordefinierte Vorlage, die finanzielle und finanzierungsbezogene Parameter hervorhebt.
- prepareMarketSearch: Extrahiert ebenfalls Filterwerte, baut jedoch dynamisch Parameter auf, die den Markt-, Branchen- und geografischen Kontext betonen.
- executeSearch: Sendet die konstruierte Abfrage mit einer Suchvorlage an Elasticsearch und ruft die entsprechenden Start-up-Dokumente ab.
- VisualizeResults: Formatiert die Endergebnisse in einer klaren, lesbaren Zusammenfassung, die die wichtigsten Startup-Attribute wie Finanzierung, Branche und Umsatz aufzeigt.
Dieser Fluss umfasst eine bedingte Verzweigung, die als „if“-Anweisung fungiert und basierend auf der Eingabe des Nutzers bestimmt, ob der Investitions- oder Marktsuchpfad verwendet wird. Diese vom LLM gesteuerte Entscheidungslogik macht den Workflow adaptiv und kontextsensitiv – ein Mechanismus, den wir in den nächsten Abschnitten genauer untersuchen werden.
LangGraph-Status
Bevor wir jeden Knoten einzeln betrachten, müssen wir verstehen, wie die Knoten kommunizieren und Daten austauschen. Dafür ermöglicht uns LangGraph, den Workflow-Status zu definieren. Dies definiert den gemeinsamen Status, der zwischen Knoten weitergegeben wird.
Der Zustand fungiert als gemeinsamer Container, der während des gesamten Workflows Zwischendaten speichert: Er beginnt mit der natürlichsprachlichen Anfrage des Nutzers, speichert dann die ausgewählte Suchstrategie, die vorbereiteten Parameter für Elasticsearch, die abgerufenen Suchergebnisse und schließlich den formatierten Ausgang.
Diese Struktur ermöglicht es jedem Knoten, den Status zu lesen und zu aktualisieren, wodurch ein konsistenter Informationsfluss vom Nutzer-Eingang bis zur endgültigen Visualisierung gewährleistet wird.
Einrichten der Anwendung
Der gesamte Code in diesem Abschnitt ist im elasticsearch-labs-Repository zu finden.
Öffnen Sie ein Terminal in dem Ordner, in dem sich die App befindet, und initialisieren Sie eine Node.js-Anwendung mit folgendem Befehl:
Nun können wir die notwendigen Abhängigkeiten für dieses Projekt installieren:
@elastic/elasticsearch: Hilft uns bei der Bearbeitung von Elasticsearch-Anfragen, z. B. bei der Daten-Ingestion und dem Abrufen von Daten.@langchain/langgraph: JS-Abhängigkeit zur Bereitstellung aller LangGraph-Tools.@langchain/openai: LLM-Client von OpenAI für LangChain.- @langchain/core: Bietet die grundlegenden Bausteine für LangChain-Apps, einschließlich Prompt-Vorlagen.
dotenv: Notwendige Abhängigkeit zur Verwendung von Umgebungsvariablen in JavaScript.zod: Abhängigkeit von Typdaten.
@types/node tsx typescript ermöglicht es uns, TypeScript-Code zu schreiben und auszuführen.
Erstellen Sie nun die folgenden Dateien:
elasticsearchSetup.ts: Erstellt die Index-Mappings, lädt die Daten aus einer JSON-Datei und führt den Ingest der Daten in Elasticsearch durch.main.ts: Wird die LangGraph-Anwendung enthalten..envDatei zum Speichern der Umgebungsvariablen
In der .env-Datei fügen wir die folgenden Umgebungsvariablen hinzu:
Der OpenAPI-APIKey wird nicht direkt im Code verwendet; stattdessen wird er intern von der Bibliothek @langchain/openai verwendet.
Die gesamte Logik bezüglich der Erstellung von Mappings, der Erstellung von Suchvorlagen und der Datensatz-Ingestion kann in der Datei elasticsearchSetup.ts gefunden werden. In den nächsten Schritten konzentrieren wir uns auf die main.ts-Datei. Sie können den Datensatz auch überprüfen, um besser zu verstehen, wie die Daten in dataset.json aussehen.
LangGraph-App
In der main.ts-Datei importieren wir einige notwendige Abhängigkeiten, um die LangGraph-Anwendung zu konsolidieren. In dieser Datei müssen Sie auch die Knotenfunktionen und die Zustandsdeklaration angeben. Die Graphdeklaration erfolgt in den nächsten Schritten anhand einermain-Methode. Die elasticsearchSetup.ts-Datei wird Elasticsearch-Helfer enthalten, die wir in den nächsten Schritten in den Knoten verwenden werden.
Wie bereits erwähnt, wird der LLM-Client verwendet, um die Elasticsearch-Suchvorlagenparameter basierend auf der Frage des Nutzers zu generieren.
Die oben dargelegte Methode erzeugt das Graphbild im PNG-Format und verwendet hinter den Kulissen die Mermaid.INK-API. Dies ist nützlich, wenn Sie sehen möchten, wie die App-Knoten mit einer gestylten Visualisierung zusammenwirken.
LangGraph-Knoten
Sehen wir uns nun die einzelnen Knoten im Detail an:
decideSearchStrategy-Knoten
Der decideSearchStrategy-Knoten analysiert die Eingabe und entscheidet, ob eine investitions- oder marktorientierte Suche durchgeführt werden soll. Er verwendet ein LLM mit einem strukturierten Ausgang (definiert mit Zod), um den Abfragetyp zu klassifizieren. Bevor die Entscheidung getroffen wird, werden mithilfe einer Aggregation die verfügbaren Filter aus dem Index abgerufen, um sicherzustellen, dass das Modell über einen aktuellen Kontext zu Branchen, Standorten und Finanzierungsdaten verfügt.
Um die möglichen Filterwerte zu extrahieren und an das LLM zu senden, verwenden wir eine Aggregation, um sie direkt aus dem Elasticsearch-Index abzurufen. Diese Logik wird in einer Methode namens getAvailableFilterszugeordnet:
Mit der obigen Aggregationsanfrage erhalten wir die folgenden Ergebnisse:
Alle Ergebnisse finden Sie hier.
Für beide Strategien verwenden wir eine hybride Suche, um sowohl den strukturierten Teil der Frage (Filter) als auch die subjektiveren Teile (Semantik) zu erkennen. Hier ist ein Beispiel für beide Abfragen unter Verwendung von Suchvorlagen:
Sehen Sie sich die Abfragen an, die in derelasticsearchSetup.ts-Datei detailliert beschrieben sind. Im folgenden Knoten wird entschieden, welche der beiden Abfragen verwendet wird:
prepareInvestmentSearch- und prepareMarketSearch-Knoten
Beide Knoten verwenden eine gemeinsame Hilfsfunktion, extractFilterValues, die das LLM nutzt, um relevante Filter zu identifizieren, die in den Nutzereingaben erwähnt werden, wie z. B. Branche, Standort, Finanzierungsphase, Geschäftsmodell usw. Wir verwenden dieses Schema, um unsere Suchvorlage zu erstellen.
Je nach erkannter Absicht wählt der Workflow einen von zwei Pfaden:
prepareInvestmentSearch: Erstellt finanzorientierte Suchparameter, einschließlich Finanzierungsphase, Finanzierungsbetrag, Investor und Erneuerungsinformationen. Die gesamte Abfragevorlage finden Sie in der elasticsearchSetup.ts-Datei:
prepareMarketSearch: erstellt marktorientierte Parameter, die sich auf Branchen, Geografien und Geschäftsmodelle konzentrieren. Die vollständige Abfrage finden Sie in der Datei elasticsearchSetup.ts:
executeSearch-Knoten
Dieser Knoten nimmt die gesuchten Parameter aus dem Zustand und sendet sie zuerst an Elasticsearch, wobei er die _render-API verwendet, um die Abfrage für Debugging-Zwecke zu visualisieren, und sendet dann eine Anfrage zur Abrufung der Ergebnisse.
visualizeResults-Knoten
Dieser Knoten zeigt schließlich die Elasticsearch-Ergebnisse an.
Programmatisch sieht der gesamte Graph so aus:
Wie Sie sehen können, haben wir eine bedingte Kante, bei der die App entscheidet, welcher „Pfad“ oder Knoten als Nächstes ausführen wird. Dieses Feature ist nützlich, wenn Workflows Verzweigungslogik benötigen, etwa die Wahl zwischen mehreren Tools oder das Einfügen eines Human-in-the-Loop-Schrittes.
Nachdem wir die Kern-Features von LangGraph verstanden haben, können wir die Anwendung einrichten, in der der Code ausgeführt werden soll:
Alles wird in einer main-Methode zusammengefasst. Hier deklarieren wir den Graphen mit allen Elementen unter der Variablen „Workflow“:
Die Abfragevariable simuliert die in einer hypothetischen Suchleiste eingegebenen Nutzereingaben:

Aus der natürlichsprachlichen Formulierung „Suche Start-ups mit Series-A- oder Series-B-Finanzierung zwischen 8 und 25 Millionen US-Dollar und einem monatlichen Umsatz von über 500.000 US-Dollar“ werden alle Filter extrahiert.
Rufen Sie abschließend die Hauptmethode auf:
Ergebnisse
Für die gesendete Eingabe wählt die Anwendung den investitionsorientierten Pfad, wodurch wir die Elasticsearch-Abfrage sehen, die vom Workflow generiert wird und die Werte und Bereiche aus dem Eingang des Nutzers extrahiert. Wir können auch die an Elasticsearch gesendete Anfrage mit den extrahierten Werten sehen, und schließlich die vom visualizeResults-Knoten formatierten Ergebnisse.
Testen wir nun den marktorientierten Knoten mit der Abfrage „Suche Fintech- und Healthcare-Start-ups in San Francisco, New York oder Boston.“:
Erkenntnisse
Während des Schreibprozesses habe ich Folgendes gelernt:
- Wir müssen dem LLM die exakten Werte der Filter zeigen, sonst sind wir darauf angewiesen, dass der Nutzer die präzisen Werte eingibt. Bei niedriger Kardinalität ist dieser Ansatz akzeptabel, aber wenn die Kardinalität hoch ist, benötigen wir einen Mechanismus zum Herausfiltern der Ergebnisse.
- Die Verwendung von Suchvorlagen führt zu deutlich konsistenteren Ergebnissen als die automatische Generierung der Elasticsearch-Abfrage durch das LLM und ist zudem schneller.
- Bedingte Kanten sind ein leistungsstarker Mechanismus, um Anwendungen mit mehreren Varianten und verzweigten Pfaden zu erstellen.
- Strukturierte Ausgaben sind bei der Informationsgenerierung mit LLMs äußerst nützlich, da sie vorhersehbare, typsichere Antworten erzwingen. Dies verbessert die Zuverlässigkeit und reduziert Fehlinterpretationen von Prompts.
Die Kombination von semantischem und strukturiertem Suchen durch hybriden Abruf führt zu besseren und relevanteren Ergebnissen, wobei Präzision und Kontextverständnis in Einklang gebracht werden.
Fazit
In diesem Beispiel kombinieren wir LangGraph.js mit Elasticsearch, um einen dynamischen Workflow zu schaffen, der natürliche Sprachanfragen interpretieren und zwischen finanz- oder marktorientierten Suchstrategien entscheiden kann. Dieser Ansatz reduziert die Komplexität manueller Abfragen und verbessert gleichzeitig die Flexibilität und Genauigkeit für Risikokapitalanalysten.
Zugehörige Inhalte

Beschreiben statt zeichnen: KI-native Kibana-Dashboards über MCP und ES|QL
Vom Prompt zum Dashboard. Erfahren Sie, wie Sie Kibana-Dashboards in natürlicher Sprache mit example-mcp-dashbuilder erstellen: eine Open-Source-MCP-Anwendung, die ES|QL-Abfragen schreibt, interaktive Diagramme erstellt und voll funktionsfähige Dashboards direkt in Kibana exportiert.

8. April 2026
So erstellen Sie agentische KI-Anwendungen mit Mastra und Elasticsearch
Lernen Sie anhand eines praktischen Beispiels, wie Sie agentische KI-Anwendungen mit Mastra und Elasticsearch erstellen.

25. März 2026
Das Shell-Tool ist kein Allheilmittel für Kontext-Engineering
Erfahren Sie, welche Tools zur Kontextsuche für das Kontext-Engineering existieren, wie sie funktionieren und welche Nachteile sie mit sich bringen.

23. März 2026
Die Verwendung der Elasticsearch Inference API zusammen mit Hugging Face-Modellen
Erfahren Sie, wie Sie Elasticsearch mithilfe von Inferenz-Endpoints mit Hugging Face Modellen verbinden und ein mehrsprachiges Blog-Empfehlungssystem mit semantischer Suche und Chat-Abschlüssen erstellen.

27. März 2026
Erstellung eines Elasticsearch MCP-Servers mit TypeScript
Erfahren Sie, wie Sie mit TypeScript und Claude Desktop einen Elasticsearch MCP-Server erstellen.