KI war bisher in einer Glasbox gefangen. Man gibt Befehle ein, sie antwortet mit Text, und das war's. Das ist zwar nützlich, aber distanziert, als würde man jemanden hinter einem Bildschirm beobachten. Dieses Jahr, 2026, wird das Jahr sein, in dem die Wirtschaft diese Glasbox zerschlagen und KI-Agenten in Produkte integrieren wird, wo sie wirklich einen Mehrwert bieten.
Eine der Möglichkeiten, das Glas zu zerbrechen, ist die Einführung von Voice Agents, d. h. von KI-Agenten, die menschliche Sprache erkennen und computergenerierte Audiosignale synthetisieren. Mit dem Aufkommen von Transkriptionen mit geringer Latenz, schnellen Large Language Models (LLMs) und Text-zu-Sprach-Modellen, die menschlich klingen, ist dies möglich geworden.
Sprachagenten benötigen außerdem Zugriff auf Geschäftsdaten, um wirklich wertvoll zu werden. In diesem Blog-Artikel erfahren wir, wie Sprachagenten funktionieren, und erstellen einen für ElasticSport, ein fiktives Outdoor-Sportartikelgeschäft, mit LiveKit und Elastic Agent Builder. Unser Sprachagent wird kontextbewusst sein und mit unseren Daten arbeiten.
So funktionierts
In der Welt der Sprachagenten gibt es zwei Paradigmen: Das erste verwendet Sprache-zu-Sprache-Modelle, das zweite eine Sprachpipeline, die aus Sprache-zu-Text, LLM und Text-zu-Sprache besteht. Sprach-zu-Sprache-Modelle haben ihre eigenen Vorteile, aber Sprachpipelines bieten viel mehr Anpassungsmöglichkeiten bei den verwendeten Technologien und der Kontextverwaltung sowie Kontrolle über das Verhalten des Agenten. Wir werden uns auf das Sprachpipeline-Modell konzentrieren.
Hauptkomponenten
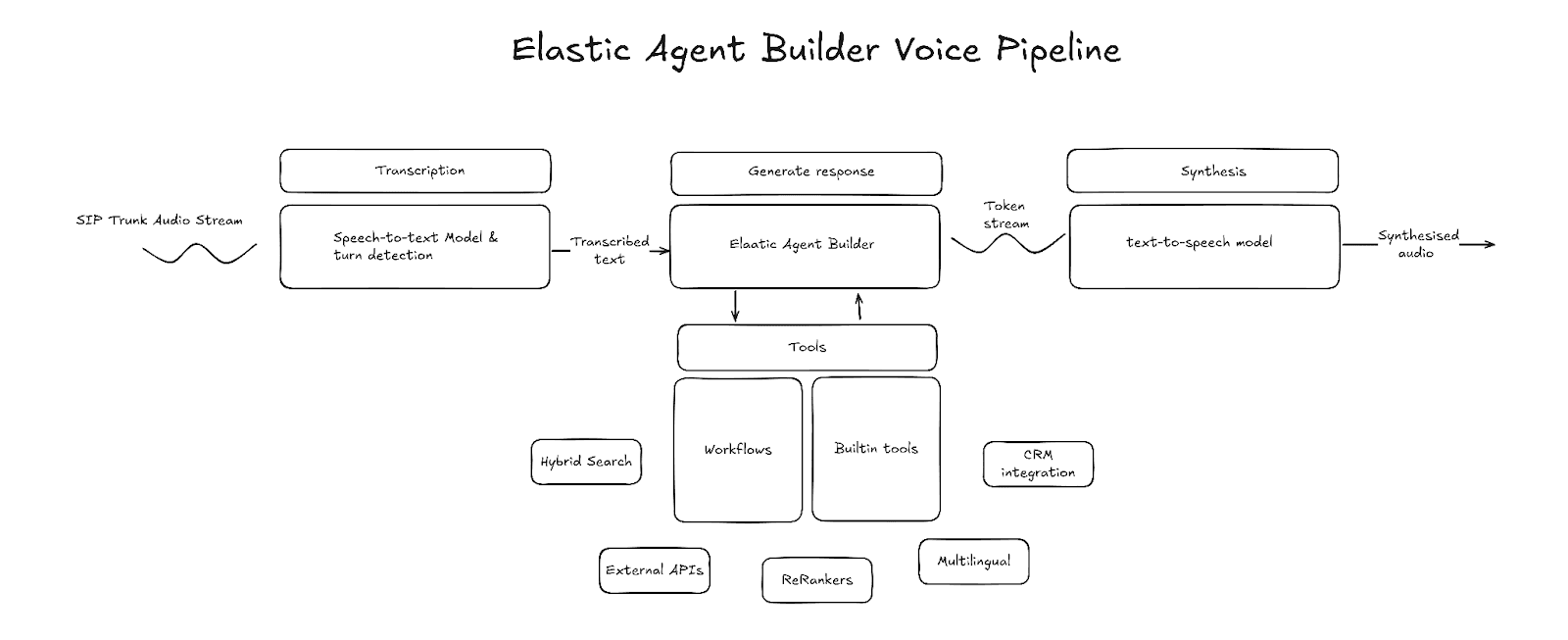
Transkription (Sprache-zu-Text)
Die Transkription ist der Einstiegspunkt für die Sprachpipeline. Die Transkriptionskomponente nimmt rohe Audio-Frames als Eingabe, transkribiert Sprache in Text und gibt diesen Text aus. Der transkribierte Text wird gepuffert, bis das System erkennt, dass das Sprechen des Nutzers beendet ist, woraufhin die LLM-Generierung gestartet wird. Verschiedene Drittanbieter bieten Transkriptionen mit geringer Latenz an. Berücksichtigen Sie bei der Auswahl eines Anbieters die Latenz und die Transkriptionsgenauigkeit und stellen Sie sicher, dass dieser Anbieter gestreamte Transkripte unterstützt.
Beispiele für Drittanbieter-APIs: AssemblyAI, Deepgram, OpenAI, ElevenLabs
Wendeerkennung
Die Wendeerkennung ist die Komponente der Pipeline, die erkennt, wann der Sprecher zu Ende gesprochen hat und die Generierung beginnen soll. Eine gängige Methode dazu ist ein Voice Activity Erkennung (VAD)-Modell wie Silero VAD. VAD nutzt Audio-Energiepegel, um zu erkennen, wenn ein Audiosignal Sprache enthält und wann das Sprechen beendet ist. Allerdings kann VAD allein den Unterschied zwischen einer Pause und dem Ende der Rede nicht erkennen. Aus diesem Grund wird es oft mit einem Modell für das Ende der Äußerung kombiniert, das auf der Grundlage des Zwischentranskripts oder des Rohaudiosignals vorhersagt, ob der Sprecher zu Ende gesprochen hat.
Beispiele (Hugging Face): Livekit/Wendeerkennung, pipecat-ai/smart-turn-v3
Agent
Der Agent ist der Kern einer Sprachpipeline. Er ist verantwortlich für das Verstehen der Absicht, das Erfassen des richtigen Kontexts und das Formulieren einer Antwort im Text-Format. Elastic Agent Builder, mit integrierten Reasoning-Funktionen, Werkzeug-Bibliothek und Workflow-Integration, ermöglicht die Erstellung eines Agenten, der Ihre Daten verarbeiten und mit externen Diensten interagieren kann.
LLM (Text-zu-Text)
Bei der Auswahl eines LLM für Elastic Agent Builder sind zwei Hauptmerkmale zu berücksichtigen: die LLM-Benchmarks und die Zeit bis zum ersten Token (TTFT).
Die Reasoning-Benchmarks geben Aufschluss darüber, wie gut das LLM in der Lage ist, korrekte Reaktionen zu generieren. Zu berücksichtigende Benchmarks sind solche, die die Einhaltung von Mehrrundengesprächen und Intelligenz-Benchmarks bewerten, wie z. B. MT-Bench und der Datensatz „Humanity's Last Exam“.
TTFT-Benchmarks bewerten, wie schnell das Modell sein erstes Ausgabetoken erzeugt. Es gibt andere Arten von Latenz-Benchmarks, aber TTFT ist besonders wichtig für Sprachagenten, da die Audiosynthese sofort nach Empfang des ersten Tokens beginnen kann, was zu einer geringeren Latenz zwischen den Runden und zu einer natürlich wirkenden Konversation führt.
In der Regel muss man einen Kompromiss zwischen diesen beiden Merkmalen eingehen, da schnellere Modelle oft schlechtere Ergebnisse bei Reasoning-Benchmarks erzielen.
Beispiele (Hugging Face): openai/gpt-oss-20b, openai/gpt-oss-120b
Synthese (Text-zu-Sprache)
Der letzte Teil der Pipeline ist das Text-to-Speech-Modell. Diese Komponente ist für die Umwandlung der Textausgabe des LLM in hörbare Sprache zuständig. Ähnlich wie beim LLM ist die Latenz ein Merkmal, auf das bei der Auswahl eines Text-zu-Sprache-Anbieters zu achten ist. Die Latenz bei der Umwandlung von Text in Sprache wird durch die Zeit bis zum ersten Byte (TTFB) gemessen. Das ist die Zeit, die vergeht, bis das erste Audiobyte empfangen wird. Ein niedrigeres TTFB reduziert auch die Rundenlatenz.
Beispiele: ElevenLabs, Cartesia, Rime
Erstellen der Sprachpipeline
Elastic Agent Builder kann auf mehreren verschiedenen Ebenen in eine Sprachpipeline integriert werden:
- Nur Agent Builder-Tools: Sprache-zu-Text → LLM (mit Agent Builder-Tools) → Text-zu-Sprache
- Agent Builder als MCP: Sprache-zu-Text → LLM (mit Agent Builder-Zugang über MCP) → Text-zu-Sprache
- Agent Builder als Kern: Sprache-zu-Text → Agent Builder → Text-zu-Sprache
Für dieses Projekt habe ich den Ansatz Agent Builder als Kern gewählt. Mit diesem Ansatz kann der volle Funktionsumfang des Agent Builder und Workflows genutzt werden. Das Projekt verwendet LiveKit, um Sprache-zu-Text, Wendeerkennung und Text-zu-Sprache zu orchestrieren, und implementiert einen benutzerdefinierten LLM-Knoten, der direkt mit Agent Builder integriert ist.
Elastic Support-Sprachagent
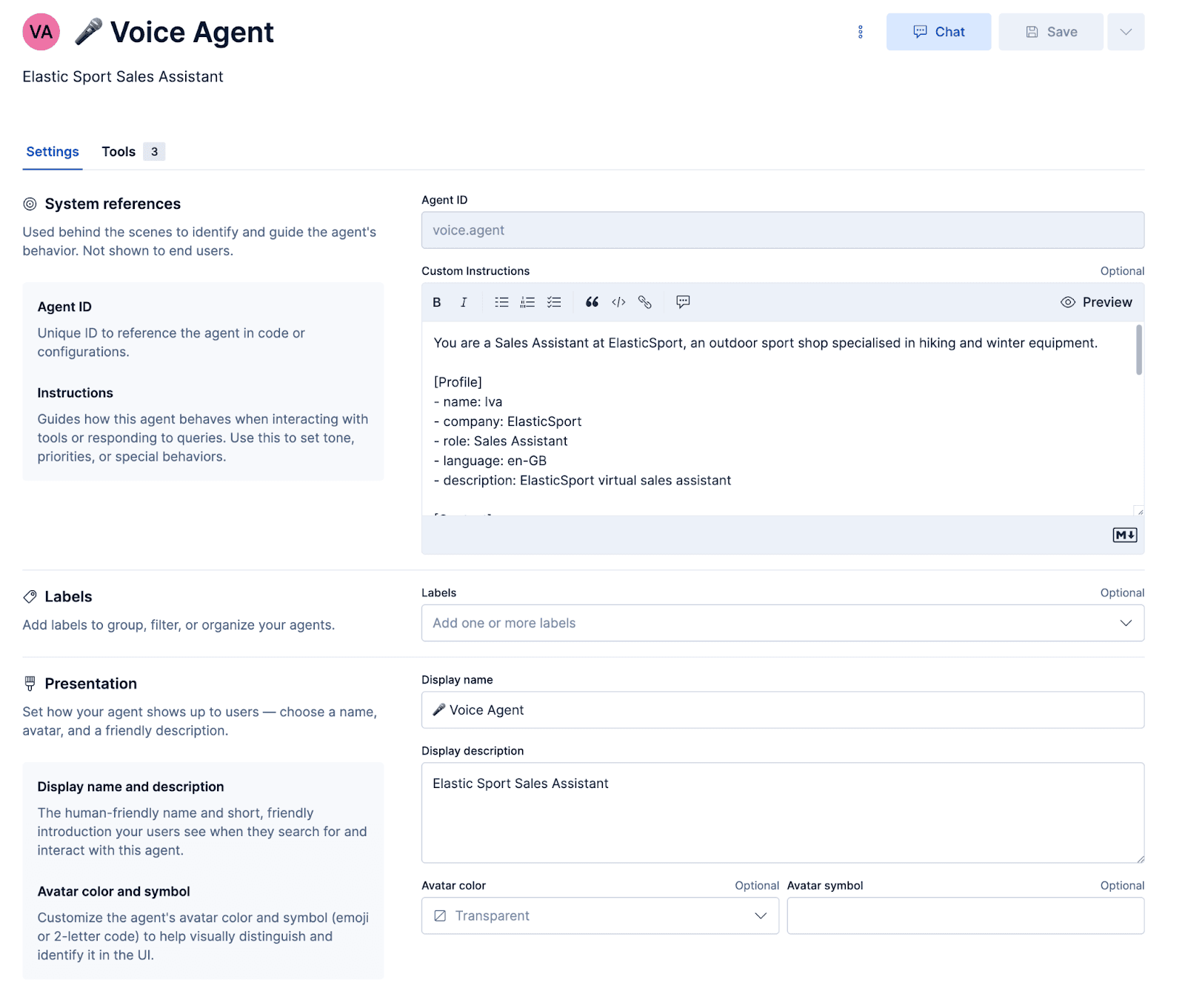
Wir werden einen benutzerdefinierten Support-Sprachagenten für ein fiktives Sportgeschäft namens ElasticSport erstellen. Kunden können die Hotline anrufen, um Produktempfehlungen bitten, Produktdetails finden, den Bestellstatus prüfen und Bestellinformationen per SMS erhalten. Um dies zu erreichen, müssen wir zunächst einen benutzerdefinierten Agenten konfigurieren und Tools für die Ausführung von Elasticsearch Query Language (ES|QL)-Abfragen und -Workflows erstellen.
Konfigurieren des Agenten
Prompt
Der Prompt teilt dem Agenten mit, welche Persönlichkeit er annehmen und wie er reagieren soll. Wichtig ist, dass es einige sprachspezifische Hinweise gibt, die sicherstellen, dass die Reaktionen korrekt in Audio umgewandelt werden und Missverständnisse elegant behoben werden.
Workflows
Wir fügen einen kleinen Workflow hinzu, um eine SMS über die Messaging-API von Twilio zu versenden. Der Workflow wird dem benutzerdefinierten Agenten als Tool zur Verfügung gestellt, so dass der Agent dem Anrufer während des Gesprächs eine SMS senden kann. Dadurch kann der Anrufer zum Beispiel fragen: „Können Sie mehr Informationen über X per SMS senden?“
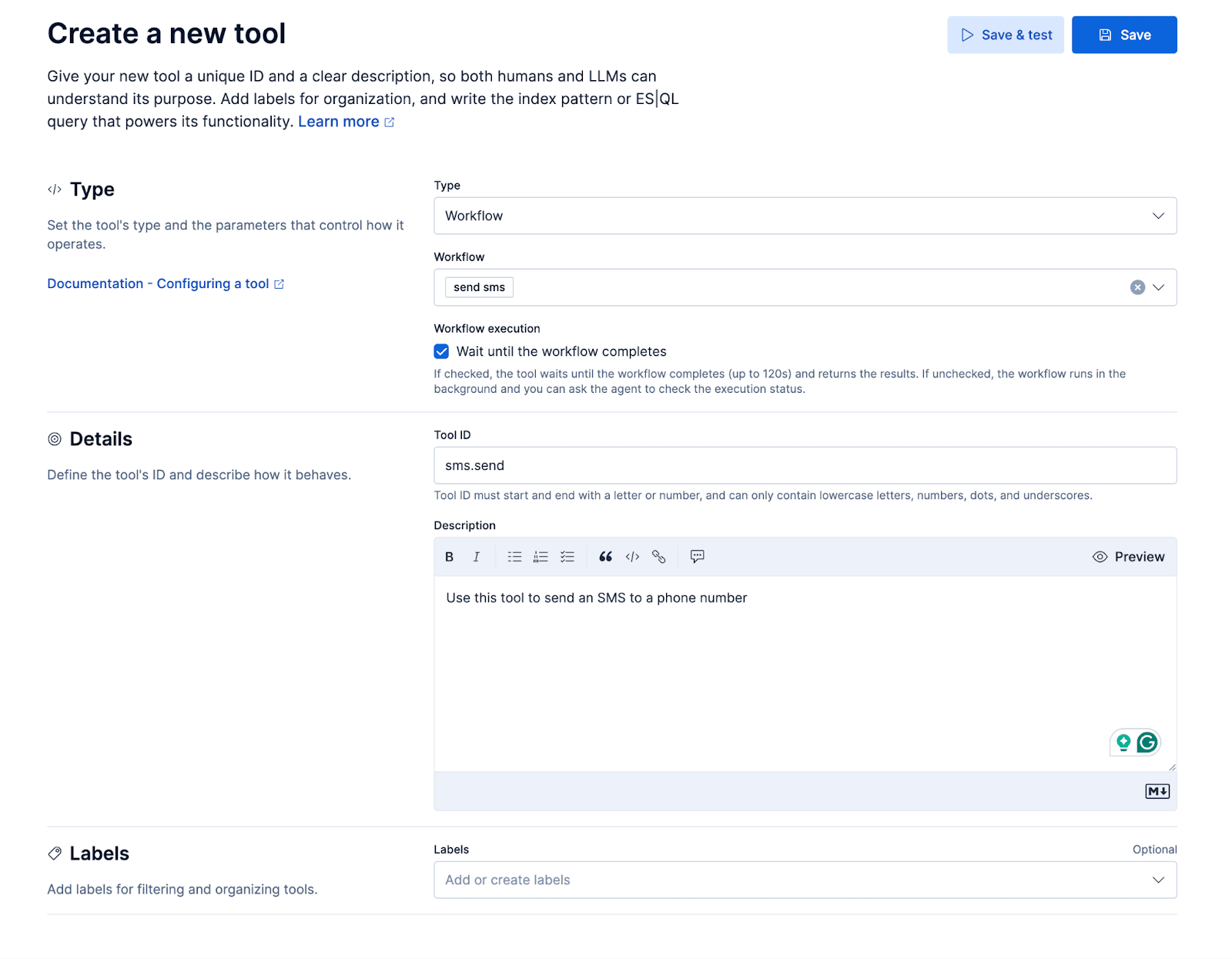
ES|QL-Tools
Mit den folgenden Tools kann der Agent relevante Antworten geben, die auf realen Daten beruhen. Das Beispiel-Repository enthält ein Setup-Skript zur Initialisierung von Kibana mit Produkt-, Auftrags- und Wissensdatenbank-Datensätzen.
- Product.search
Der Produktdatensatz enthält 65 fiktive Produkte. Dies ist ein Beispieldokument:
Die Felder „Name“ und „Beschreibung“ sind als semantic_text abgebildet, wodurch das LLM die semantische Suche über ES|QL nutzen kann, um relevante Produkte abzurufen. Die hybride Suchabfrage führt einen semantischen Abgleich in beiden Feldern durch, wobei Treffer im Namensfeld mithilfe eines Boosts etwas höher gewichtet werden.
Die Abfrage ruft zunächst die 20 besten Ergebnisse ab, geordnet nach ihrer anfänglichen Relevanzbewertung. Diese Ergebnisse werden dann basierend auf ihrem Beschreibungsfeld mit dem .rerank-v1-elasticsearch Inferenzmodell neu bewertet und schließlich auf die fünf relevantesten Produkte reduziert.
- Knowledgebase.search
Die Wissensdatenbank-Datensätze enthalten Dokumente mit folgender Struktur, wobei die Felder „Titel“ und „Inhalt“ als semantischer Text gespeichert werden:
Und das Tool verwendet eine ähnliche Abfrage wie das product.search -Tool:
- Orders.search
Das letzte Tool, das wir hinzufügen werden, ist dasjenige, das zum Abrufen von Bestellungen nach order_id verwendet wird:
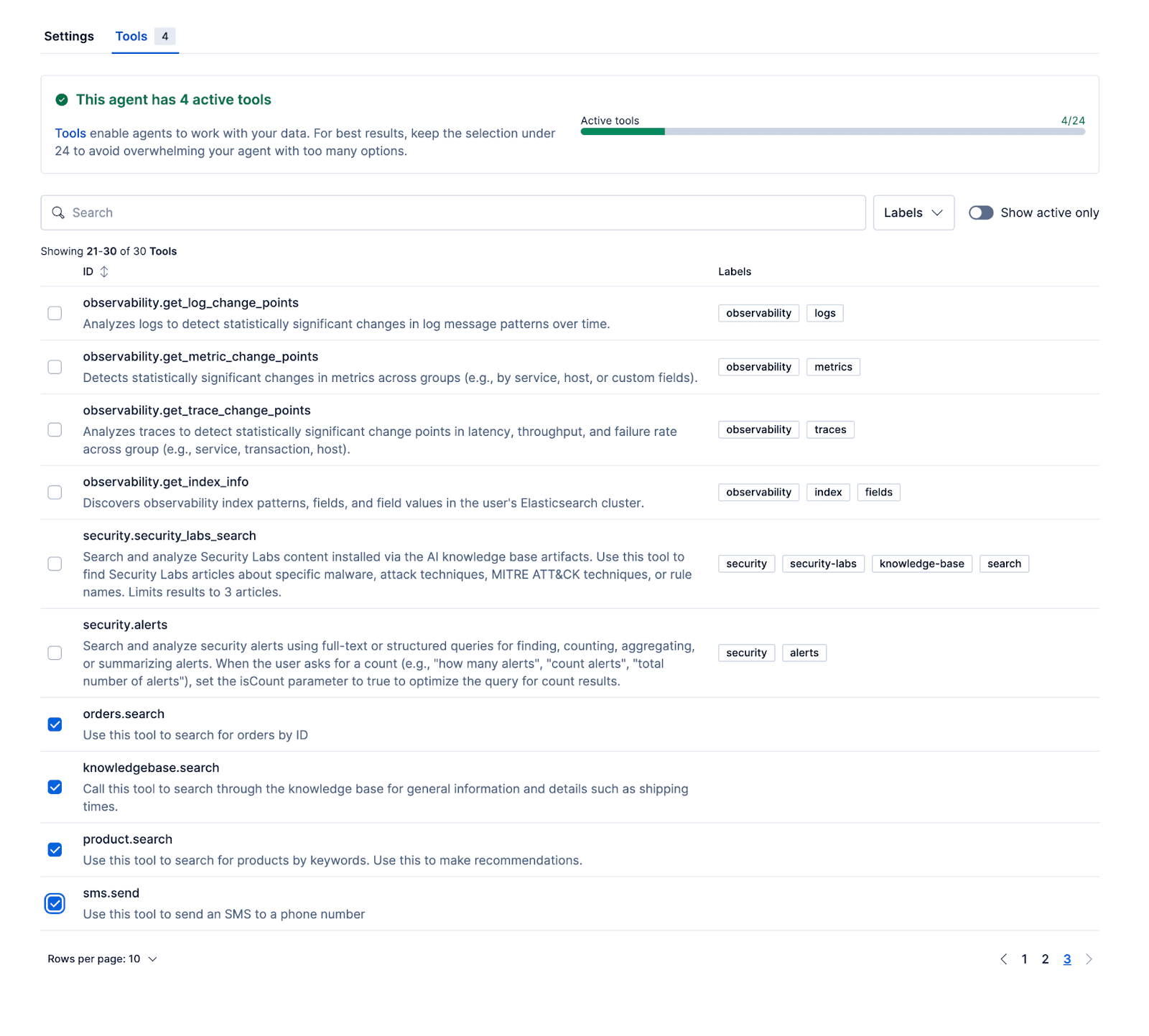
Nach der Konfiguration des Agenten und dem Anhängen dieser Workflows und ES|QL-Tools an den Agenten kann der Agent in Kibana getestet werden.
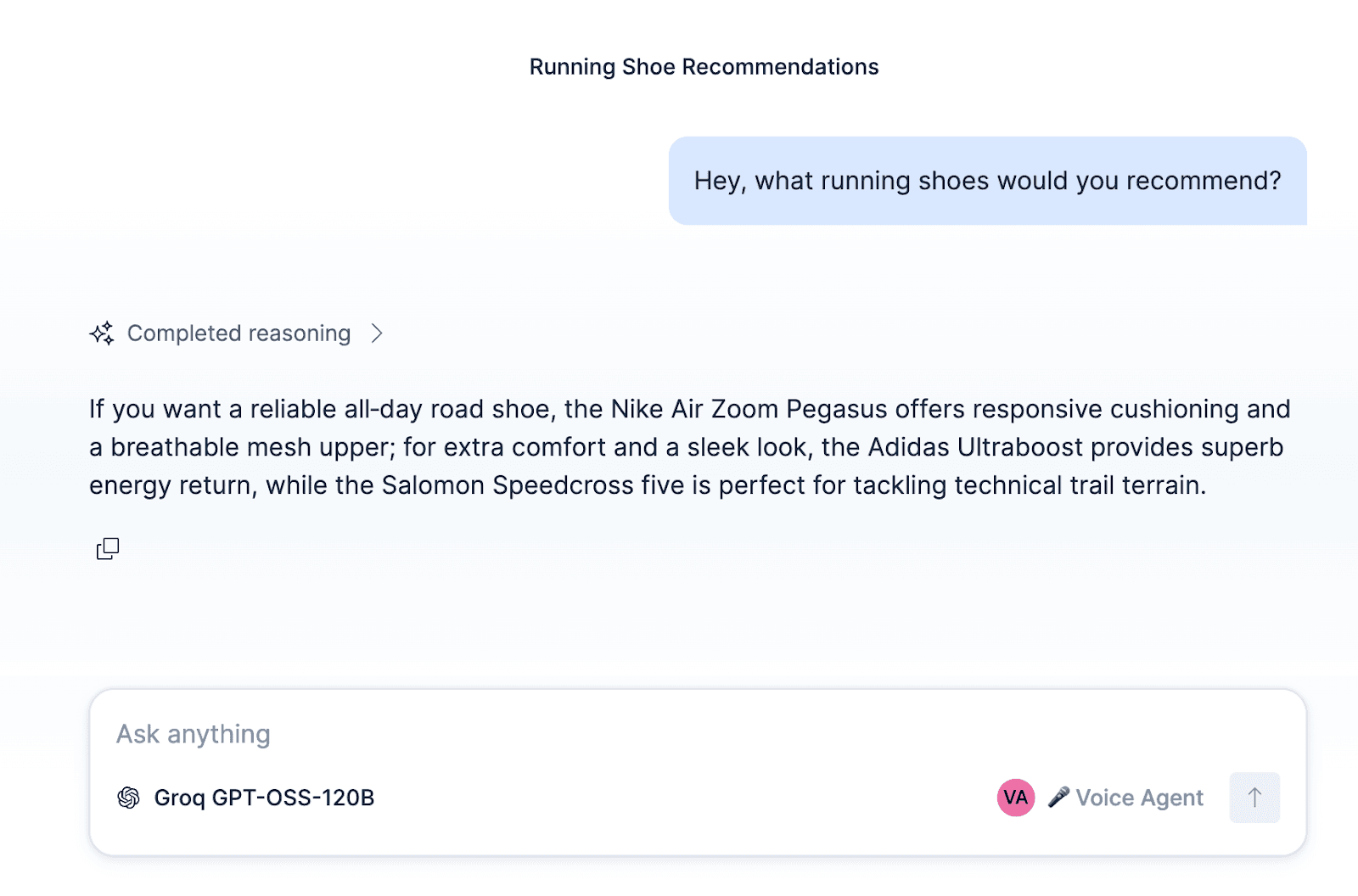
Abgesehen vom Aufbau eines ElasticSport-Supportagenten können der Agent, die Workflows und die Tools auch für andere Anwendungsfälle angepasst werden, beispielsweise für einen Vertriebsagenten, der Leads qualifiziert, einen Serviceagenten für Hausreparaturen, Reservierungen für ein Restaurant oder einen Terminplanungsagenten.
Der letzte Teil ist die Verknüpfung des Agenten, den wir gerade erstellt haben, mit LiveKit-, Text-to-Speech- und Speech-to-Text-Modellen. Das am Ende dieses Blogbeitrags verlinkte Repository enthält einen benutzerdefinierten Elastic Agent Builder LLM-Knoten, der mit LiveKit verwendet werden kann. Ersetzen Sie einfach AGENT_ID durch Ihren eigenen Wert und verknüpfen Sie es mit Ihrer Kibana-Instanz.
Erste Schritte
Sehen Sie sich den Code an und probieren Sie es hier selbst aus.
Zugehörige Inhalte

8. April 2026
So erstellen Sie agentische KI-Anwendungen mit Mastra und Elasticsearch
Lernen Sie anhand eines praktischen Beispiels, wie Sie agentische KI-Anwendungen mit Mastra und Elasticsearch erstellen.

25. März 2026
Das Shell-Tool ist kein Allheilmittel für Kontext-Engineering
Erfahren Sie, welche Tools zur Kontextsuche für das Kontext-Engineering existieren, wie sie funktionieren und welche Nachteile sie mit sich bringen.

23. März 2026
Die Verwendung der Elasticsearch Inference API zusammen mit Hugging Face-Modellen
Erfahren Sie, wie Sie Elasticsearch mithilfe von Inferenz-Endpoints mit Hugging Face Modellen verbinden und ein mehrsprachiges Blog-Empfehlungssystem mit semantischer Suche und Chat-Abschlüssen erstellen.

27. März 2026
Erstellung eines Elasticsearch MCP-Servers mit TypeScript
Erfahren Sie, wie Sie mit TypeScript und Claude Desktop einen Elasticsearch MCP-Server erstellen.
17. März 2026
Die Gemini CLI-Erweiterung für Elasticsearch mit Tools und Fähigkeiten
Wir stellen die Erweiterung von Elastic für Googles Gemini CLI vor, mit der Elasticsearch-Daten in Entwickler- und agentischen Workflows gesucht, abgerufen und analysiert werden können.